论文导读 | Recurrent Event Network: Global Structure Inference over Temporal Knowledge Graph
作者:北京大学 李荆
编者按
本文介绍一篇ICLR-RLGM 2019的文章,由Woojeong Jin, He Jiang, Meng Qu, Tong Chen, Changlin Zhang, Pedro Szekely, Xiang Ren. 所著。该工作主要聚焦于时序性的,多关系的图数据结构(e.g. 时序知识图谱)。本文提出RE-NET模型,对时序知识图谱进行序列性的全局结构推理,以此来预测未来时刻的事件发生。RE-NET能有效的提取时序知识图谱中的时序性和结构性的信息,从而在事件预测中展示出强大的能力。
源码:
https://github.com/INK-USC/re-net
相关背景
动态图上的表示学习在近两年受到越来越多研究者的关注,得益于其在多个应用领域表现出的重要价值,例如社交网络分析,知识图谱推理,事件预测,推荐系统等等。
以往对于动态图表示学习的研究多是关注于单关系图中的时序性结构信息,解决诸如节点分类,链接预测等的任务,然而随着越来越多异构的事件数据的出现,对于动态图的研究也出现了新的挑战——对于时序知识图谱(Temporal Knowledge Graph, TKG)中实体间动态性的,复杂关系的建模,并解决TKG中对未来某些时刻的事件进行预测的任务。
所谓事件,也即时序知识图谱中的一个带时间戳的边,是实体间的关系,例如下图中"
对于TKG这类异构数据的事件预测,有如下几点思考:
预测未来时刻的事件可以看作实体间multi-step,multi-relation的交互作用
时间上相邻的事件可能带有相关的语义和信息模式
多个事件可能在同一个时间窗口内发生,而当他们之间有共享实体时,能表现出结构依赖性(也即局部结构信息)
相关工作
01 时序知识图谱推理和链接预测
Know-Evolve[2]将时序知识图谱中的事实的发生建模为时序点过程,然而此方法对于并发事件的建模公式存在一定的问题。另外,还有一些基于向量嵌入的方法进行时间信息的提取,例如通过RNN进行时间文本上的关系嵌入[3],时间嵌入[4],时序超平面[4]等等。但是这些方法没有获取到时序上的依赖关系,不能推广到未观察到的时间步上。
02 静态知识图谱的补全和嵌入
一些方法将知识图谱中的实体和关系映射到低维向量空间中,其中Relational Graph Convolutional Networks (RGCN)将GCN[5]的工作推广到有向多关系图(例如知识图谱)中。这些方法对于静态知识图谱的推理学习能达到较高的准确率,但是他们缺乏了对于时序性动态性的知识图谱的建模。
03 递归图神经网络模型
这类动态图上基于递归图神经网络的表示学习方法,主要是采取一些信息传递的框架来聚合节点的邻居信息。GN[6]等通过一个信息传递模块来更新不同时间步之间的节点表示。EvolveGCN[7]等通过RNN的结构来更新不同时间步的参数或者节点表示。不同的是,本文的RE-NET模型通过一个消息传递过程来增强RNN的建模能力,从而学习到事件(即实体间关系)的时序依赖性,而不是用RNN来记忆节点表示相关的历史信息。
RE-NET模型
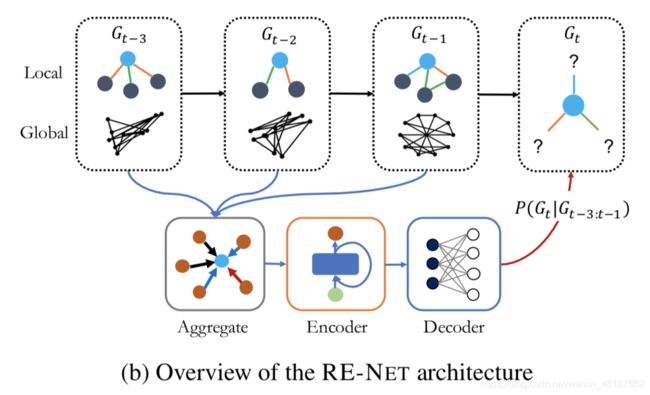
一个TKG被看作一个multi-relation的有向图,图中节点(实体)间的边(关系)带有时间戳信息。一个事件(event)即是一条带时间戳的边(主语,关系,宾语,时间),被表示为一个四元组(s, r, o, t)或者三元组(st,rt,ot)。在t时刻发生的事件集合表示为Gt,一个TKG是建立在一系列的按时间顺序排列的事件四元组上。学习事件的生成模型的目标也就是基于TKG上的一组已观察到的事件集合{G1,…,GT}来学习到概率分布P(G)。
01 循环事件网络
a. TKG中的序列结构推断
RE-NET中的一个关键点在于以自回归的方式对所有事件的联合分布概率进行定义。RE-NET将联合概率分布分解为一系列的条件概率分布,并且假设t时刻的事件发生的概率只取决于之前的m个时间步发生的事件,即Gt-m:t-1。对于每个条件概率P(Gt|Gt-m:t-1),进一步假设Gt中的事件在Gt-m:t-1发生的情况下是相互独立的。所有事件的联合分布概率可以写作:
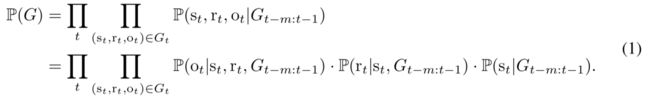
为了建模每个事件(st,rt,ot)的产生过程,给定过去的事件Gt-m:t-1,首先根据分布P(st|Gt-m:t-1)产生一个subject实体st,然后进一步根据条件概率P(rt|st,Gt-m:t-1)产生一个关系rt,最后object实体ot通过P(ot|st,rt,Gt-m:t-1)产生。在RE-NET模型中,作者假设P(st|Gt-m:t-1 )和P(ot|st,rt,Gt-m:t-1) 只依赖于与实体s有关的事件,因此联合概率分布修改为:
其中Gt变为了Nt(s),也即那些在时间t与实体s有事件交互的邻居节点的集合。而对于公式中第三部分仍保留Gt-m:t-1因为s实体未知,因此事件集合都要加入考虑。
b. 循环事件编码器
RE-NET将分布P(ot|s,r,Gt-m:t-1)参数化为:
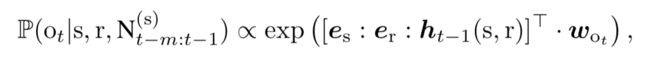
其中es,er是与实体s和关系r相关的可学习的嵌入向量。ht-1(s,r)表示历史向量,其中编码了s过去的邻居信息以及图结构Gt-1:t-m中的全局信息。[es:er:ht-1(s,r)]是对于过去所有信息的一个编码,此编码被输入一个线性softmax分类器中计算不同的ot出现的概率,其中wot是分类器的参数。
对于关系r和实体s的概率也类似:
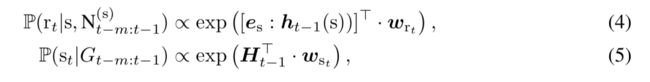
其中ht-1(s)建模了过去时刻s的所有局部信息,Ht-1则建模了Gt-1:t-m的图结构中的全局信息。
对于每个时间t,ht-1(s),ht-1(s,r)和Ht-1保留了过去发生的事件的信息,RE-NET采用循环网络的方式对它们进行更新:
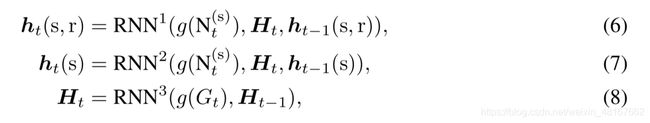
其中g是一个聚合函数,Nt(s)则表示在当前时刻t与s实体相关的事件。对于每个主语实体s,它可能在多个关系下和多个实体在同一个时刻t都发生作用,产生事件,也即Nt(s)中包含了多个事件,因此需要定义高效的聚合函数g来对Nt(s)的信息进行聚合。接下来则介绍RE-NET中的聚合函数g。
02 ( Multi-Relational Graph ) RGCN聚合
聚合函数g的设计和选择是多样的,RE-NET的工作中介绍了三种聚合函数。
a. Mean Pooling Aggregator
一个最基本的信息聚合方式也就是对所有与该实体有交互的实体的向量取均值。但是均值聚合对于所有邻居同等看待而忽略了不同邻居在重要性上的不同体现。
b. Attentive Pooling Aggregator
进一步的,为了区分不同邻居重要性的不同,引入了注意力机制,通过学习到s和r的注意力,决定一个实体o在实体s和关系r下的重要性权重。
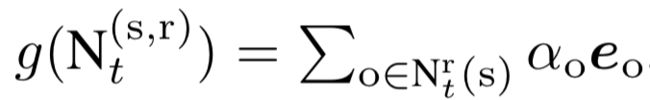
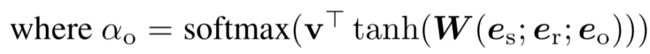
c. Multi-Relational Aggregator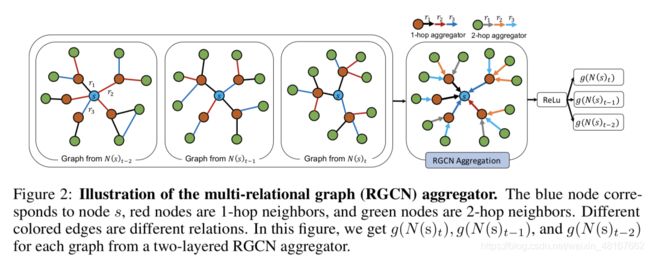
此聚合方法可以聚合来自多关系(multi-relation)邻居和多跳(multi-hop)邻居的信息。对于每个实体的每种关系都可以得到一个局部的图结构,而对于多关系图中,一个实体的信息来源于他的所有类型关系下的聚合信息的聚合。而聚合函数g则进一步将过去时间步的这些信息进行结合。
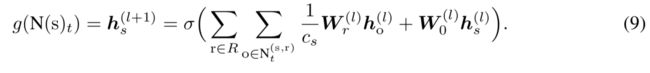
不同的权重矩阵{Wr(l)}区分了不同的关系类型r。聚合器对不同hop邻居的选择则通过设置不同的聚合层数来完成。同时考虑到随着关系数目的增加,模型的参数量也大量增加,容易产生过拟合。模型中的Wr(l)参数通过块对角分解(block-diagonal decomposition)分解为更低维度的矩阵,从而减小了模型的参数量,也避免了过拟合。
03 模型训练
给定(s,r),预测实体o,可以看作一个多分类任务,而每一个分类类别则代表一个o实体。相似的,给定s和o和情况下预测关系r,也可以看作多分类任务。模型的学习采用多分类的交叉熵损失函数: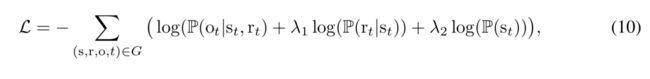 其中G是事件的集合,而λ1, λ2则是控制重要性的超参数,参数设置根据任务的不同而设置不同。如果一个任务更关注于在给定(s,r)下预测o,则λ1 和λ2的值相应设置的更小。
其中G是事件的集合,而λ1, λ2则是控制重要性的超参数,参数设置根据任务的不同而设置不同。如果一个任务更关注于在给定(s,r)下预测o,则λ1 和λ2的值相应设置的更小。
模型的算法流程如下:

实验
对于模型性能的评估,采用了TKG中的链接预测任务,即基于已观察到的事件预测某链接(s,r,?,t)的obeject实体o或链接(?,r,o,t)的subject实体s。
1. 数据集
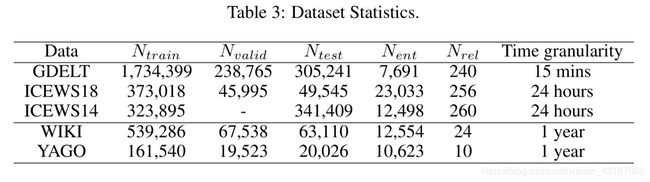
实验采用了五个数据集,其中三个基于事件的时序知识图谱(ICEWS18:集成危机预警系统,ICEWS14,GDELT:全球事件、语言和语气数据集)和两个知识图谱(WIKI,YAGO),数据集详细信息如下:
2. 对比模型
静态方法:将时间戳信息忽略,将所有事件形成一张静态图,采用的静态方法包括TransE, DistMult, ComplEx, R-GCN, ConvE, RotatE
动态方法:包括Know-Evolve, TA-DistMult, HyTE, TTransE。为了更好的对比RE-NET中循环事件编码器的性能,将其中的decoder都替换为与RE-NET所用的相同的MLP decoder。从而形成了更有效的对比baseline: Know-Evolve+MLP, DyRep+MLP, R-GCRN+MLP。
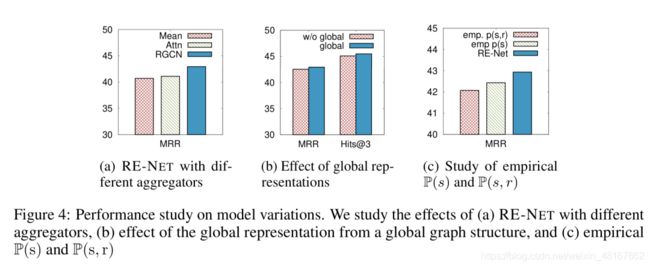
RE-NET的变体:为了验证RE-NET中不同结构的重要作用,实验中通过替换RE-NET的不同结构,形成了几个变体。
RE-NET w/o multi-step:去掉了历史信息的更新阶段。RE-NET w/o agg:去掉了信息聚合的结构。RE-NET w. mean agg:有均值聚合的RE-NET。RE-NET w. GT(s,r):RE-NET加上所有ground truth的历史和节点交互信息。
3. 实验结果
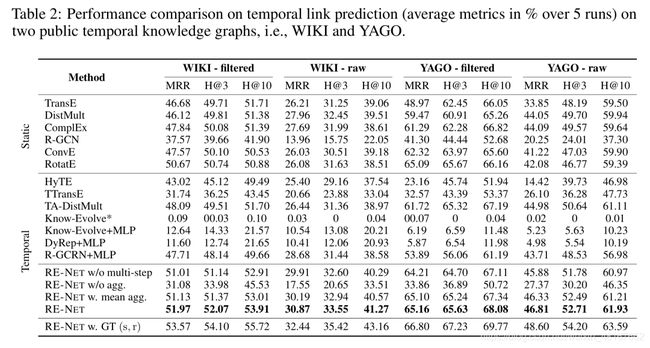
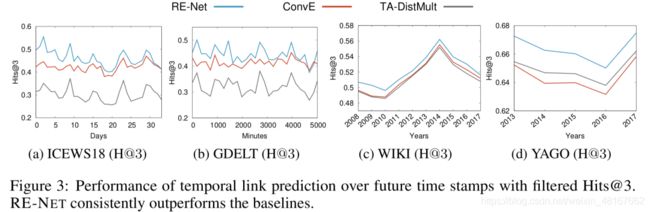
在三个基于事件的数据集上RE-NET展现出了优于其他模型的性能表现。

在公共知识图谱WIKI和YAGO上,RE-NET同样优于其他baseline,这也体现了事件编码器和信息聚合器对于事件预测的有效作用。
下图展示了模型预测性能基于时间的变化,在每个时间步上,RE-NET都有更好的预测表现。
Tabel 1和Table 2 中 RE-NET w/o agg的预测性能下降说明了aggregator的重要性。下图a中展示了不同aggregator的选择,对于预测性能的影响。可以发现RGCN有最优的预测能力。
参考文献
- Recurrent Event Network: Global Structure Inference over Temporal Knowledge Graph. Woojeong Jin, He Jiang, Meng Qu, Tong Chen, Changlin Zhang, Pedro Szekely, Xiang Ren. Short version in ICLR-RLGM 2019.
- Rakshit Trivedi, Hanjun Dai, Yichen Wang, and Le Song. Know-evolve: Deep temporal reasoningfor dynamic knowledge graphs. In ICML, 2017.
- Alberto García-Durán, Sebastijan Dumancic, and Mathias Niepert. Learning sequence encoders fortemporal knowledge graph completion. In EMNLP, 2018.
- Julien Leblay and Melisachew Wudage Chekol. Deriving validity time in knowledge graph. InCompanion of the The Web Conference 2018 on The Web Conference 2018, pp. 1771–1776.International World Wide Web Conferences Steering Committee, 2018.
- Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.CoRR, abs/1609.02907, 2016.
- Alvaro Sanchez-Gonzalez, Nicolas Heess, Jost Tobias Springenberg, Josh Merel, Martin A. Ried-miller, Raia Hadsell, and Peter W. Battaglia. Graph networks as learnable physics engines forinference and control. In ICML, 2018.
- Aldo Pareja, Giacomo Domeniconi, Jie Chen, Tengfei Ma, Toyotaro Suzumura, Hiroki Kanezashi,Tim Kaler, and Charles E. Leisersen. Evolvegcn: Evolving graph convolutional networks fordynamic graphs. CoRR, abs/1902.10191, 2019.
