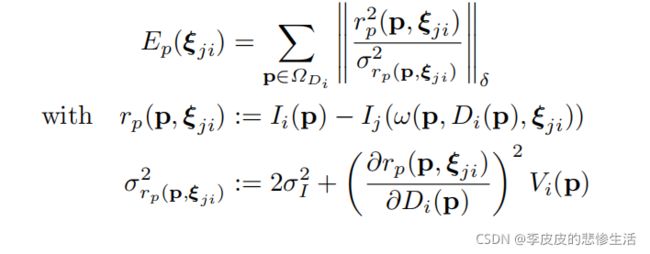阅读笔记-LSD-SLAM: Large-ScaleDirect Monocular SLAM 逐行仔细阅读 lsdsalm论文解读
皮皮原创手打,欢迎交流。
基本情况
标题 :Large-ScaleDirect Monocular SLAM -2014年
作者 : Jakob Engel and Thomas Sch¨ops and Daniel Cremers
论文下载地址 :https://sci-hub.mksa.top/10.1007/978-3-319-10605-2_54
代码地址 : https://github.com/tum-vision/lsd_slam
(已在虚拟机ubutnu14.04+ROS indigo+opencv 2.4.8+eigen3.2.5+cmake3.2+gcc4.8.4成功运行!在ubuntu18折腾了很久放弃了,建议直接另开虚拟机一天就可以配好成功运行)
论文内容:
摘要
提出了一种直接法单目SLAM算法,与目前最已有的效果最好的直接方法相比,优势在于可以构建大规模的、一致的环境地图。在基于直接法,半稠密图像对齐的高精度姿态估计的同时,实时半稠密的重建三维环境。通过过滤大量像素级的小基线立体比较而获得的。显式的尺度漂移感知公式允许该方法在具有挑战性的序列上操作,包括场景规模的大变化。
主要创新:
(1) 是一种新的直接跟踪方法,基于相似变换sim3,从而明确地检测尺度漂移;
(2)是一种高效的概率解决方案,将噪声深度值的影响包括到跟踪中。由此产生的直接单目SLAM系统在CPU上实时运行。
1 简介
单目SLAM和三维重建已成为越来越流行的研究课题。两个主要原因是
(1)它们在机器人中的使用,特别是无人机导航。
(2)单目SLAM的尺度模糊性(也就是单目尺度不确定性,详细可见 https://www.zhihu.com/question/50385799/answer/120902345)
:世界尺度无法观察到,其值可能会随时间而漂移,产生误差来。同时这也是一个优点,这允许相机在不同规模的环境之间无缝切换,如室内桌面环境和大型户外环境。而其他深度或立体声相机,仅仅在有限的探测范围可以提供可靠的测量,因此不具备这种灵活性。(原来单目尺度丢失的问题还是个优点,而且单目还便宜呢)
1.1 相关工作
基于特征的方法。从图像中提取一组特征观察结果,照相机的位置和场景几何形状仅作为这些特征观察的函数进行计算(就是利用不同帧对应的点线特征求解相机运动)。虽然这种解耦简化了整个问题,但它带有一个重要的限制:只能使用符合特性类型的信息。特别是,当使用关键点时,包含在直线或弯曲边中的信息会被丢弃——特别是在人造环境中——构成了图像的很大一部分。过去已经提出了几种方法,通过包括基于边缘的甚至是基于区域的特性来弥补这一点。然而,由于高维特征空间的估计很繁琐,因此在实践中很少使用。为了获得密集的重建,估计的摄像机姿态可以用于随后重建密集的地图,使用多视图立体[2]。(就是说基于稀疏的特征点来跟踪丢掉了很多环境信息,而边缘和面的跟踪太复杂,确实特征点见的多一些)
直接法。直接视觉测速法(VO)方法通过直接优化图像强度上的几何形状来规避这一限制,从而可以使用图像中的所有信息。除了更高的精度和鲁棒性,特别是在关键点很少的环境中,这还提供了更多关于环境几何形状的信息,这对机器人技术或增强现实应用程序非常有价值。虽然RGB-D或立体传感器的直接图像对齐已经很好,但直到最近才提出了单眼直接VO算法(然后列了几个直接法的方案,我就想看你的方案)
位姿图优化。这是一种众所周知的SLAM技术,可以构建一个一致的全局映射:世界被表示为许多由姿态-姿态约束连接的关键帧,可以使用像g2o[18]这样的通用图优化框架进行优化。(后端图优化,可以消除尺度不统一的问题)
1.2 贡献和大纲
提出了一种大规模直接法单目SLAM(LSD-SLAM)方法,该方法不仅局部跟踪摄像机的运动(视觉里程计呗),还允许构建一致的、大规模的环境地图。该方法采用直接图像对齐和中最初提出的基于滤波的半密集深度图的估计(一直挂在嘴边的直接图像对齐法)。全局地图表示为一个姿态图,由关键帧组成的顶点,三维相似性转换为边(典型的图优化的顶点和边结构),优雅地结合了变化规模的环境变化,并允许检测和纠正累积漂移。该方法在CPU上实时运行,甚至在现代智能手机[22]上也可以运行。本文的主要贡献是
(1) 大规模框架,直接单目SLAM,两个关键帧之间图像对齐算法直接估计相似性变换ξ∈sim3。(后面看具体实现)
(2) 概率一致的不确定性的估计深度跟踪。(后面看具体实现)
2 初步工作(公式来了,快跑啊)
首先总结了相关的数学概念和号
R ——矩阵
ξ ——向量
Ω→ ——图片 I
——图片 I
Ω→![]() ——图片像素逆深度图 D
——图片像素逆深度图 D
Ω→![]() ——逆深度方图 V
——逆深度方图 V
d表示一个点深度的倒数 1/z ( why )
2.1三维刚体及相似性变换
看过SLAM十四讲的肯定很熟悉啦,又是坐标转换那一套 G就是变换矩阵SE(3),特殊欧式群。R旋转矩阵,SO(3) 李群 特殊正交群 。 t平移向量。

指数映射,映射到李代数,方便变换矩阵求导等各种运算。第一个公式是李群G到李代数ξ 的转换。下面那个式子李群的乘法转化成李代数的 o 运算,多简洁。
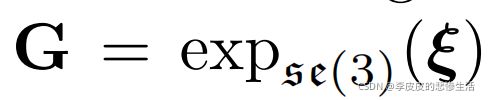
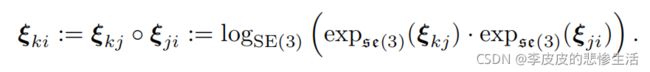
定义了三维射影函数ω,它将一个图像点p及其逆深度d投影到一个由 ξ 转换的相机帧中(这里是老朋友换了套衣服)

![]() 这里其实就是G 变换矩阵,就是直接得到了像素位置P,深度d,和 ξ 李代数三者的关系 。但是这里不应该还有内参矩阵吗?没见过像素坐标不转到图像坐标系就直接乘深度的,有点小疑惑,有没有大佬给我解惑。
这里其实就是G 变换矩阵,就是直接得到了像素位置P,深度d,和 ξ 李代数三者的关系 。但是这里不应该还有内参矩阵吗?没见过像素坐标不转到图像坐标系就直接乘深度的,有点小疑惑,有没有大佬给我解惑。
三维相似性变换。三维相似度变换S∈Sim(3)相似变换群,表示旋转、缩放和平移。的定义为
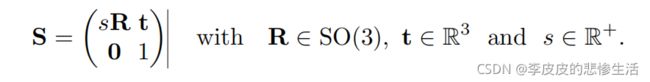
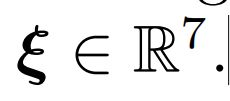 比SE(3)中的 ξ 多一个自由度,及是尺度,目的就是突出单目的尺度不确定性。
比SE(3)中的 ξ 多一个自由度,及是尺度,目的就是突出单目的尺度不确定性。
2.2李代数上的加权高斯-牛顿优化
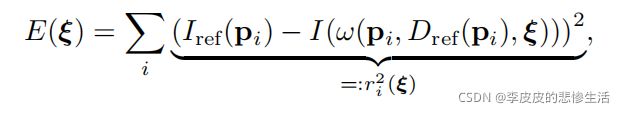
(利用转化到了李代数来写误差函数,后面那个I的公式眼熟吗,就是上那个w公式,这个误差函数简单的说就是参考帧与当前帧的对应的像素差的平方和,用最小化这个误差函数来优化李代数,也就是优化位姿)
(这里是根据这个误差函数来开始迭代梯度下降法,来寻找极值点,也就是找误差最小的变换)J是上面那个r,J雅克比矩阵,JTJ海森矩阵。
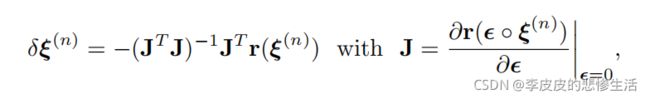
砰的一声,找到了最优解,更新位姿

然后呢,作者又运用了一下小脑瓜,添加了一个权重,对应小标题嘛,加权,就是对于那些残差,也就是误差大的像素点减权,就是怕噪声。这个加权方法好像又是别的论文来的,具体可能要看原论文,不深究了,学海无涯,珍惜头发。

2.3不确定性的传播
(中间是输入x协方差矩阵,通过两边是Fx的雅克比,也就是一阶偏导矩阵,得到输出f的协方差矩阵,简单的理解就是输入的不确定性对应的输出的不确定性)

3 大规模直接单目SLAM(终于要到正题了吗)
3.1完整的方法
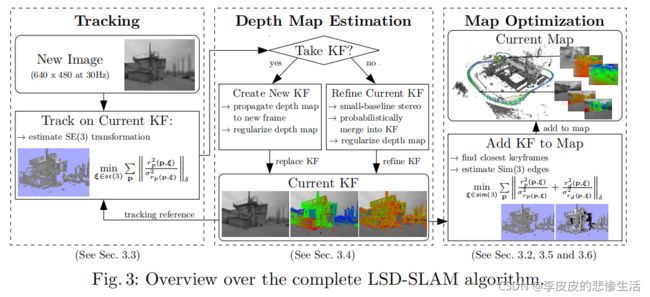
(粗略讲了一通算法流程,其实看图就行了,很像ORB的多线程思路)
-跟踪组件不断跟踪新的相机图像。也就是说,它估计它们与当前关键帧初始化的刚体姿态,使用前一帧的姿态作为初始化(里程计部分)。
-深度图估计组件使用被跟踪的帧来细化或替换当前的关键帧。通过过滤许多每个像素的小基线立体比较,以及在[9]中最初提出的交叉空间正则化来细化深度。如果相机移动得太远,则通过从现有的近距离关键帧中投影点来将新的关键帧初始化。
-一旦一个关键帧被替换为跟踪参考,因此其深度地图将不会被进一步细化,它将被地图优化组件合并到全局地图中。为了检测循环闭包和尺度漂移,使用尺度感知的、直接的sim(3)图像对齐估计了相似度转换到现有关键帧(包括其直接前身的关键帧)。
初始化。要引导LSD-SLAM系统,用随机深度映射和大差异初始化(我理解是先有一个预估深度,做之前的误差函数梯度下降,然后优化得到正确深度)第一个关键帧就足够了。给定在前几秒钟内有足够的平移摄像机移动(和ORB一样初始化需要平移),算法“锁定”到某个图像信息,并在几次关键帧传播后收敛到一个正确的深度配置。附示视频中显示了一些例子。对这种在没有专用初始引导的情况下收敛能力的更全面的评估超出了本文的范围,并仍用于未来的工作。
3.2地图表示
该地图表示为一个关键帧的姿态图:每个关键帧Ki由一个相机图像Ii:Ωi→R、一个逆深度地图Di:ΩDi→R+和一个逆深度Vi:ΩDi→R+的方差组成。请注意,深度图和方差仅定义为像素ΩDi⊂Ωi的一个子集,包含在足够大的强度梯度附近的所有图像区域,因此是半密集的。关键帧之间的边缘Eji包含了它们作为相似性变换ξji∈sim(3)的相对对齐,以及相应的协方差矩阵Σji。(只有关键帧有深度图,用来构建地图,然后关键帧有个对齐操作的sim3,包含着他们之间的位姿尺度关系,好做融合。)
3.3跟踪新帧:直接使用(3)图像对齐
从现有的关键帧Ki=(Ii,Di,Vi)(相机图像,半稠密像素的逆深度,逆深度的方差)开始,通过最小化方差归一化光度误差,计算出一个新图像Ij的相对三维姿态ξji∈se(3)(最小化光度误差求解位姿sim3)