机器学习笔记
梳理了一下机器学习的重要概念和常用算法。主要是想用尽量少的字来列出机器学习的提纲,帮助读者快速搭建知识体系以及回顾复习。
一、机器学习算法类型
有监督学习
用有标签的训练数据训练。用于解决:
分类问题
推测出离散的输出值,如是否是肿瘤(是为1,不是为0)。
回归问题
推测出一个连续值的结果,比如房子的价格(1-1000元)。
无监督学习
用没有相应标签的训练数据训练。用于解决:
聚类问题
把不同的个体归为不同类,且预先不知道类别。
维度约减
即将高维数据将为低维数据,且不丢失有意义的信息。
强化学习
不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数 。通过反复试验来学习最优的动作。
二、机器学习经典算法介绍
有监督学习
1.线性回归算法
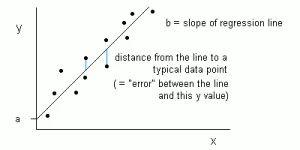
Y = a + bX
目标是去拟合一条最接近所有点的直线。
(如给定身高预测体重)
2.逻辑回归算法
也称广义线性回归模型。
主要用于解决二分类问题。
用一个超平面把数据分成两部分。
(如给定身高体重,输出“胖”或“瘦”)
一般用最大似然估计求解。
线性回归主要功能是拟合数据。
逻辑回归主要功能是区分数据,找到决策边界。
线性回归的代价函数常用平方误差函数。
逻辑回归的代价函数常用交叉熵。
参数优化的方法都是常用梯度下降。
3.分类回归树(决策树)
分类回归树是诸多决策树模型的一种实现。
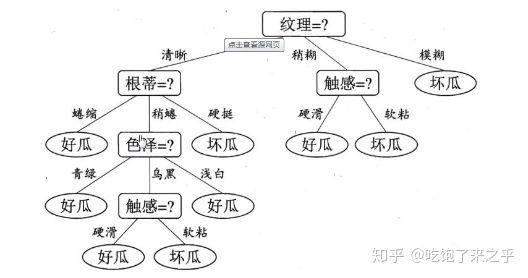
4.朴素贝叶斯
之所以称之为朴素是因为该算法假定所有的变量都是相互独立的。
在给定一个事件发生的前提下,计算另外一个事件发生的概率(用贝叶斯公式)。
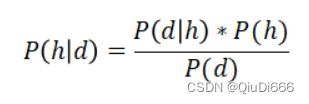
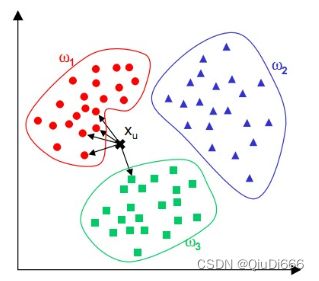
5.KNN(K近邻)
如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
无监督学习算法
6.关联规则算法
目的在于在一个数据集中找出项之间的关系,也称之为购物篮分析 (market basket analysis)。例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。
置信度:表示这条规则有多大程度上值得可信。
支持度:计算在所有的交易集中,既有A又有B的概率,用于检验项目集是否频繁。
频繁集:支持度大于预先定好的最小支持度的项集。
关联规则:令项集I={i1,i2,...in},且有一个数据集合D,它其中的每一条记录T,都是I的子集。那么关联规则是形如A->B的表达式,A、B均为I的子集,且A与B的交集为空。这条关联规则的支持度:support = P(A并B)。这条关联规则的置信度:confidence = support(A并B)/suport(A)。
强关联规则:支持度和置信度都大于预先定义好的最小支持度与置信度的强关联规则。
7.K-means算法
一种迭代求解的聚类分析算法。
k-means初始化:
a) 选择一个k值。如图6,k=3。
b) 随机分配每一个数据点到三个簇中的任意一个。
c) 计算每一个簇的中心点。如图6,红色,蓝色,绿色分别代表三个簇的中心点。
将每一个观察结果与当前簇比较:
a) 重新分配每一个点到距中心点最近的簇中。如图6,上方5个点被分配给蓝色中心点的簇。
重新计算中心点:
a) 为新分配好的簇计算中心点。如图六,中心点改变。
迭代,不再改变则停止:
a) 重复步骤2-3,直到所有点所属簇不再改变。
8.PCA主成分分析(Principal Component Analysis)
主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。
基本的思路将数据中最大方差的部分反映在一个新的坐标系中,这个新的坐标系则被称为“主要成分”。其中每一个成分,都是原来成分的线性组合,并且每一成分之间相互正交。正交性保证了成分之间是相互独立的。
第一主成分反映了数据最大方差的方向。第二主成分反映了数据中剩余的变量的信息,并且这些变量是与第一主成分无关的。同样地,其他主成分反映了与之前成分无关的变量的信息。
集成学习技术(ensemble learning)
集成学习是一种将不同学习模型(比如分类器)的结果组合起来,通过投票或平均来进一步提高准确率。潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。一般,对于分类问题用投票;对于回归问题用平均。
9.Bagging
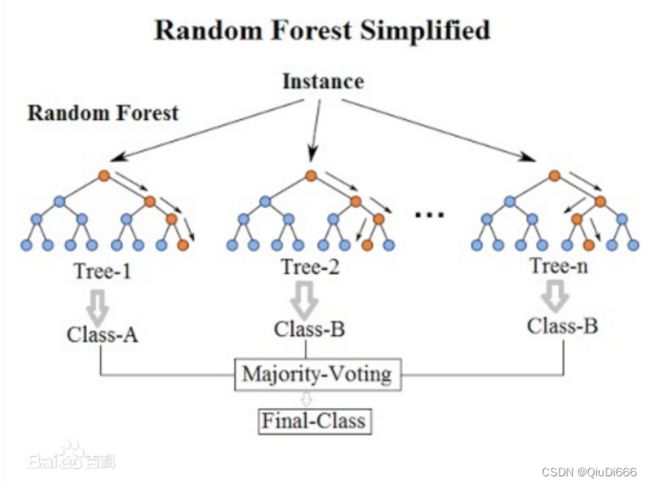
代表算法:随机森林(Random Forest)
Bagging(训练多个分类器取平均):从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果:
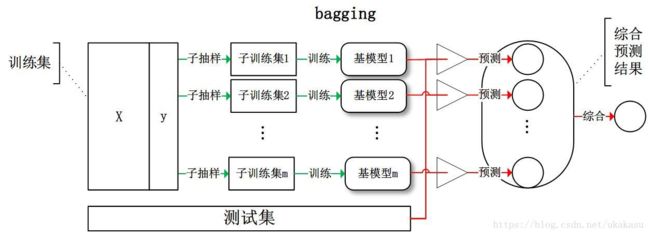
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
10.Adaboost
Boost也被称为增强学习或提升法,是一种重要的集成学习方法,它能够将预测精度仅仅比随机猜测略高的弱学习器增强为预测精度很高的强学习器。
Bagging中采用的是简单的投票,每一个分类器相当于一个投票(节点分裂,相当于进行一次投票),最后的输出是与大多数的投票有关;而在Boosting中,我们对每一个投票赋予权重,最后的输出也与大多数的投票有关——但是它却是线性的,因为赋予了更大的权重给被前一个模型错误分类的实体(拥有更大的权重,则其误差的影响被放大,有助于我们得到使得更小误差的模型)。
Boosting工作机制:
-
首先从训练集用初始权重训练出一个弱学习器1;
-
根据弱学习的学习误差率表现来更新训练样本的权重,使之前弱学习器1学习误差率高的训练样本点的权重变高,即让误差率高的点在后面的弱学习器2中得到更多的重视;
-
然后基于调整权重后的训练集来训练弱学习器2;
-
如此重复进行,直到弱学习器数达到事先指定的数目T;
-
最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
AdaBoost指的是自适应增强(Adaptive Boosting):被前一个基本分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或预先指定的最大迭代次数再确定最后的强分类器。
参考博客:(23条消息) 机器学习知识点全面总结_GoAI的博客-CSDN博客_机器学习笔记
(23条消息) 【机器学习】机器学习笔记(吴恩达)_Bug 挖掘机的博客-CSDN博客_机器学习笔记
机器学习笔记(西瓜书) - 简书 (jianshu.com)
(23条消息) 逻辑回归(Logistic Regression)详解_生信小兔的博客-CSDN博客_逻辑回归
(23条消息) 线性回归(Linear Regression)和逻辑回归(Logistic Regression)_Yemiekai的博客-CSDN博客_逻辑回归
(23条消息) 关联规则算法(The Apriori algorithm)_小小川_的博客-CSDN博客_关联规则算法
(23条消息) 关联规则常用算法_华师数据学院·王嘉宁的博客-CSDN博客_关联规则算法决策树_详解 - 知乎 (zhihu.com)
(8 封私信 / 80 条消息) 如何通俗易懂地讲解什么是 PCA(主成分分析)? - 知乎 (zhihu.com)
(23条消息) 集成学习(ensemble learning)_欧晨eli的博客-CSDN博客_集成学习
随机森林_百度百科 (baidu.com)(23条消息) 逻辑回归(LR)与支持向量机(SVM)之间的异同_yangdeshun888的博客-CSDN博客_逻辑回归和支持向量机的区别