目标检测知识总结
目录
- 写在前面
- 1、卷积神经网络中的特征图(feature map)
-
- 1.1、参考博客
- 2、感受野
-
- 2.1、感受野的定义
- 2.2、感受野的例子
- 2.3、感受野的计算
- 2.4、参考博客
- 3、图像的上采样和下采样
- 4、隐藏层
-
- 4.1、什么是隐藏层
- 5、前向传播和反向传播
-
- 5.1、前向传播
- 5.2、反向传播
-
- 5.2.1、反向传播公式推导
- 5.2.2、反向传播公式推导
- 参考
- 6、卷积网络的基本计算
-
- 6.1、Padding
- 6.2、Strided convolution(卷积步长)
- 7、各种性能指标
-
- 参考
- 8、mini batch
-
- 8.1、什么是mini batch
- 8.2、mini batch的效果
- 8.3、经验公式
- 参考
- 9、Anchor Boxes
- 10、BN、CBN、CmBN
-
- 10.1、BN
-
- 10.1.1、什么是BN
- 10.1.2、为什么要用BN
- 10.1.3、如何使用BN
- 10.2、CBN
- 10.3、CmBN
- 参考
- 11、SPP
-
- 参考
- 12、池化层
-
- 12.1、最大池化
写在前面
这篇博客用以记录我在学习目标检测过程中看到的各种知识点。大多数是看别人的博客摘过来的,参考博客已标出,如有错误,还请指出。
1、卷积神经网络中的特征图(feature map)
在每个卷积层,数据都是以三维形式存在的。你可以把它看成多个二维图片叠在一起,其中每一个称为一个feature map。在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)。层与层之间会有若干个卷积核(kernel),上一层中每个feature map跟每个卷积核做卷积,都会产生下一层的一个feature map。 feature map(下图红线标出) 即:该层卷积核的个数,有多少个卷积核,经过卷积就会产生多少个feature map,也就是下图中 豆腐皮儿的层数、同时也是下图豆腐块的深度(宽度)!!这个宽度可以手动指定,一般网络越深的地方这个值越大,因为随着网络的加深,feature map的长宽尺寸缩小,本卷积层的每个map提取的特征越具有代表性(精华部分),所以后一层卷积层需要增加feature map的数量,才能更充分的提取出前一层的特征,一般是成倍增加(不过具体论文会根据实验情况具体设置)!
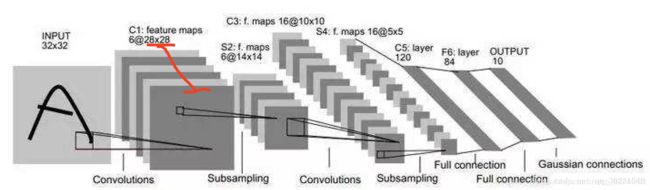

卷积网络在学习过程中保持了图像的空间结构,也就是说最后一层的激活值(feature map)总和原始图像具有空间上的对应关系,具体对应的位置以及大小,可以用感受野来度量。利用这点性质可以做很多事情:
1、前向计算。我们直接可视化网络每层的 feature map,然后观察feature map 的数值变化. 一个训练成功的CNN 网络,其feature map 的值伴随网络深度的增加,会越来越稀疏。这可以理解网络取精去噪。
2、反向计算。根据网络最后一层最强的激活值,利用感受野求出原始输入图像的区域。可以观察输入图像的那些区域激活了网络,利用这个思路可以做一些物体定位。
CNN可以通过感受野和权值共享减少了神经网络需要训练的参数的个数。卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
如果我们有一个1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话(每个隐层神经元都连接图像的每一个像素点),就有1000x1000x1000000=1012个连接,也就是1012个权值参数。然而图像的空间联系是局部的,就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样,我们就可以减少连接的数目,也就是减少神经网络需要训练的权值参数的个数了。
假如局部感受野是10x10,隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来减少了四个0(数量级)。
隐含层的每一个神经元都连接10x10个图像区域,也就是说每一个神经元存在10x10=100个连接权值参数。那如果我们每个神经元这100个参数是相同的呢?也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有多少个参数??只有100个参数啊!不管你隐层的神经元个数有多少,两层间的连接我只有100个参数啊!这就是权值共享。
假如一种滤波器,也就是一种卷积核提取图像的一种特征,例如某个方向的边缘。那么我们需要提取不同的特征,只需要加多加几种滤波器就可以了。所以假设我们加到100种滤波器,每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。这一层有多少个参数了?100种卷积核x每种卷积核共享100个参数=100x100=10K,也就是1万个参数。才1万个参数。
隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。隐层的神经元个数怎么确定呢?它和原图像,也就是输入的大小(神经元个数)、滤波器的大小和滤波器在图像中的滑动步长都有关!例如,我的图像是1000x1000像素,而滤波器大小是10x10,假设滤波器没有重叠,也就是步长为10,这样隐层的神经元个数就是(1000x1000 )/ (10x10)=100x100个神经元了。注意了,这只是一种滤波器,也就是一个Feature Map的神经元个数哦,如果100个Feature Map就是100倍了。由此可见,图像越大,神经元个数和需要训练的权值参数个数的贫富差距就越大。
1.1、参考博客
- https://blog.csdn.net/boon_228/article/details/81238091
2、感受野
2.1、感受野的定义
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图所示。

2.2、感受野的例子
(1)两层33的卷积核卷积操作之后的感受野是55,其中卷积核(filter)的步长(stride)为1、padding为0,如图
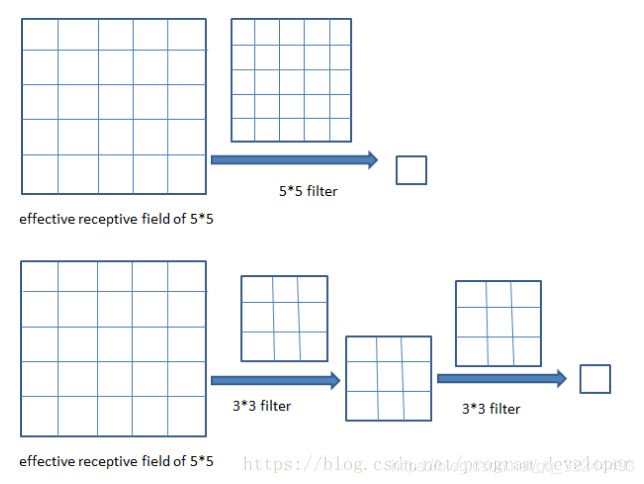
(2)三层33卷积核操作之后的感受野是77,其中卷积核的步长为1,padding为0,如图

2.3、感受野的计算
感受野计算时有下面几个知识点需要知道:
- 最后一层(卷积层或池化层)输出特征图感受野的大小等于卷积核的大小。
- 第i层卷积层的感受野大小和第i层的卷积核大小和步长有关系,同时也与第(i+1)层感受野大小有关。
- 计算感受野的大小时忽略了图像边缘的影响,即不考虑padding的大小。
关于感受野大小的计算方式可以采用从最后一层往前计算的方法,即先计算最深层在前一层上的感受野,然后逐层传递到第一层,使用的公式可以表示如下:

其中,RFi是第i层卷积层的感受野,RFi+1是(i+1)层上的感受野,stride是卷积的步长,Ksize是本层卷积核的大小。
2.4、参考博客
- https://blog.csdn.net/program_developer/article/details/80958716
3、图像的上采样和下采样
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个
- 使得图像符合显示区域的大小
- 生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
4、隐藏层
4.1、什么是隐藏层

卷积神经网络除了输入层和输出层之外,还有四个基本的神经元层,在三层神经网络中,这些层被称为隐藏层。
- 卷积层(Convolution)
- 激活层(Activation)
- 池化层(Pooling)
- 完全连接层(Fully connected)
有的神经网络可以没有隐藏层,而只有输入层和输出层,其实这就是一个逻辑回归,一个线性的或者非线性的回归模型。
5、前向传播和反向传播
前向传递输入的信号直至输出产生误差,反向传播误差信息更新权重矩阵,权重在信息双向流动中得到优化。这句话概括了前向传播和反向传播。
5.1、前向传播
5.2、反向传播
输出层得到误差,输出层将误差反向传播到隐藏层,然后应用梯度下降。其中将误差从末层往前传递的过程需要链式法则(Chain Rule),因此反向传播算法可以说是梯度下降在链式法则中的应用。
5.2.1、反向传播公式推导
这里的公式推导是学习的B站上的学习视频,点击链接, 写的不完整,留给我自己参考回忆。
5.2.2、反向传播公式推导
首先明确各种符号的表示含义,弄明白了这些,就等于明白了一半。
-
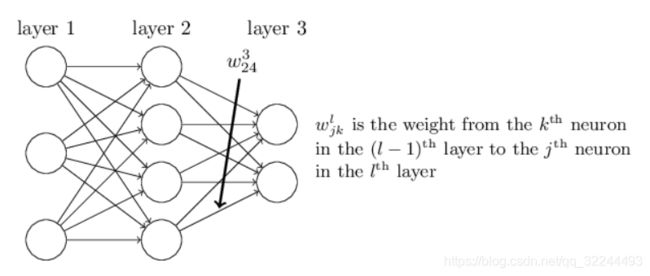
权重的表示
W j k l W^l_{jk} Wjkl: l − 1 l-1 l−1层的第 k k k个神经元到 l l l层第 j j j个神经元中间的权重。
-
偏置和激活值的表示
b j l b^l_j bjl:第 l l l层中的第 j j j个神经元的偏置
a j l a^l_j ajl:第 l l l层中的第 j j j个神经元的激活值

通过上面的表示手法,我们有公式表达 a j l a^l_j ajl:
a j l = σ ( ∑ k w j k l a k l − 1 + b j l ) , ( 23 ) a^l_j=\sigma\big(\sum_kw^l_{jk}a^{l-1}_k+b^l_j\big), (23) ajl=σ(k∑wjklakl−1+bjl),(23)
这个公式用来表达第 l l l层第 j j j个神经元的激活值。
其中的和是在 l − 1 l-1 l−1层上所有的神经元 k k k上。
- 通过矩阵的方式表示
- 为了将公式(23)以矩阵的方式表达出来,我们为每一个 l l l层定义一个权重矩阵: w l w^l wl。权重矩阵 w l w^l wl的各个条目(entries )用来表示连接第 l l l层各个神经元的权重。也就是说,在 j j j行 k k k列的条目(entry)就是 w j k l w^l_{jk} wjkl。
- 同理,对于每一个 l l l层,我们定义一个偏差向量: b l b^l bl。偏差矢量的组成部分就是 l l l层中每一个神经元的偏差 b j l b^l_j bjl,
- 最后,我们定义激活值向量: a l a^l al,它由 a j l a^l_j ajl组成。
- 用 σ \sigma σ来表示矢量 v v v中的每一个元素: σ ( v ) \sigma(v) σ(v)。其中 σ ( v ) \sigma(v) σ(v)就是 σ ( v ) j = σ ( v j ) \sigma(v)_j=\sigma(v_j) σ(v)j=σ(vj)。举个例子: f ( x ) = x 2 → f ( [ 2 3 ] ) = [ f ( 2 ) f ( 3 ) ] = [ 4 9 ] , ( 24 ) f(x)=x^2\to f(\begin{bmatrix}2\\3\end{bmatrix})=\begin{bmatrix}f(2)\\f(3)\end{bmatrix}=\begin{bmatrix}4\\9\end{bmatrix}, (24) f(x)=x2→f([23])=[f(2)f(3)]=[49],(24)
- 通过这些符号表示,公式(23)可以表示为 a l = σ ( w l a l − 1 + b l ) , ( 25 ) a^l=\sigma(w^la^{l-1}+b^l), (25) al=σ(wlal−1+bl),(25)
从上,我们可以看出每一层的激活值与上面一层的激活值有关。
令 z l ≡ w l a l − 1 + b l z^l\equiv w^la^{l-1}+b^l zl≡wlal−1+bl,我们称 z l z^l zl是 l l l层神经元的加权输入。因此,公式(25)可以表示为 a l = σ ( z l ) a^l=\sigma(z^l) al=σ(zl)。 其中 z l z^l zl表示为: z j l = ∑ k w j k l a k l − 1 + b j l z^l_j=\sum_kw^l_{jk}a^{l-1}_k+b^l_j zjl=∑kwjklakl−1+bjl,所以 z j l z^l_j zjl就是第 l l l层第 j j j个神经元的激活函数的加权输入。
反向传播的目标就是计算网络中成本函数对任意权重或偏差的偏导数 ∂ C / ∂ w , ∂ C / ∂ b \partial C/\partial w, \partial C/\partial b ∂C/∂w,∂C/∂b。为了使反向传播,我们需要对成本函数做出两条假设,在作出假设之前,我们知道二次方成本函数: C = 1 2 n ∑ x ∥ y ( x ) − a L ( x ) ∥ 2 , ( 26 ) C=\cfrac{1}{2n}\sum_{x}\begin{Vmatrix}y(x)-a^L(x)\end{Vmatrix}^2, (26) C=2n1x∑∥∥y(x)−aL(x)∥∥2,(26)
其中, n n n表示训练样本的总数;式中的和涵盖了各个训练样本 x x x; y = y ( x ) y=y(x) y=y(x)相当于输出, L L L表示网络中的层数; a L = a L ( x ) a^L=a^L(x) aL=aL(x)表示当 x x x为网络输入时的激活向量。
两个假设是:
- 函数可以写成 C = 1 n ∑ x C x C=\cfrac{1}{n}\sum_xC_x C=n1∑xCx, x x x是每一个训练样本。其中单个成本函数是 C x = 1 2 ∥ y − a L ∥ 2 C_x=\cfrac{1}{2}\begin{Vmatrix}y-a^L\end{Vmatrix}^2 Cx=21∥∥y−aL∥∥2
- 上面的式子可以作为神经网络的输出函数。
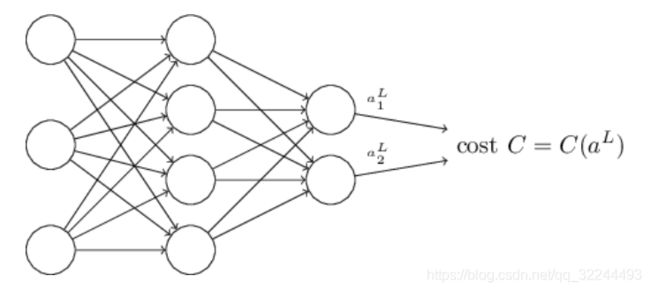
如果二次方成本函数满足此要求,单个训练样本的二次方成本函数可以写成: C = 1 2 ∥ y − a L ∥ 2 = 1 2 ∑ j ( y j − a j L ) 2 , ( 27 ) C=\cfrac{1}{2}\begin{Vmatrix}y-a^L\end{Vmatrix}^2=\cfrac{1}{2}\sum_{j}(y_j-a^L_j)^2, (27) C=21∥∥y−aL∥∥2=21j∑(yj−ajL)2,(27)这是一个关于输出激活值 a L a^L aL的函数,他也取决于输出值 y y y。那他为什么不能说是关于 y y y的函数呢?这是因为训练样本的输入值 x x x是固定的,所以输出 y y y也是固定参数,他不是我们可以通过修改偏差或者权重可以修改的参数,也不是神经网络可以学习的东西。
假设 s s s和 t t t是两个相同维度的矢量,我们用 s ⨀ t s\bigodot t s⨀t表示两个向量元素的乘积。 s ⨀ t s\bigodot t s⨀t的组成部分是 ( s ⨀ t ) j = s j t j (s\bigodot t)_j=s_jt_j (s⨀t)j=sjtj。如下例子: [ 1 2 ] ⨀ [ 3 4 ] = [ 1 ∗ 3 2 ∗ 4 ] = [ 3 8 ] , ( 28 ) \begin{bmatrix}1\\2\end{bmatrix}\bigodot \begin{bmatrix}3\\4\end{bmatrix}=\begin{bmatrix}1*3\\2*4\end{bmatrix}=\begin{bmatrix}3\\8\end{bmatrix}, (28) [12]⨀[34]=[1∗32∗4]=[38],(28)
反向传播需要用到的四个基本公式
反向传播是计算 ∂ C / ∂ w j k l \partial C/\partial w^l_{jk} ∂C/∂wjkl和 ∂ C / ∂ b j l \partial C/\partial b^l_j ∂C/∂bjl,要计算这些,我们先引入一个中间变量: δ j l \delta^l_j δjl,我们称之为第 l l l层第 j j j个神经元的误差。现在我们来理解一下神经网络中的误差。
 图中,恶魔坐在第 l l l层的第 j j j个神经元上。随着输入信号进入该神经元,这个恶魔会扰乱神经元的操作。它给神经元的加权输入添加了一点变化 Δ z j l \Delta z^l_j Δzjl。所以输出不是 σ ( z j l ) \sigma(z^l_j) σ(zjl),而是 σ ( z j l + Δ z j l ) \sigma(z^l_j+\Delta z^l_j) σ(zjl+Δzjl),这些变化会在网络中的后面层中传播,最终导致总体成本函数发生变化: ∂ C ∂ z j l Δ z j l \cfrac{\partial C}{\partial z^l_j}\Delta z^l_j ∂zjl∂CΔzjl。
图中,恶魔坐在第 l l l层的第 j j j个神经元上。随着输入信号进入该神经元,这个恶魔会扰乱神经元的操作。它给神经元的加权输入添加了一点变化 Δ z j l \Delta z^l_j Δzjl。所以输出不是 σ ( z j l ) \sigma(z^l_j) σ(zjl),而是 σ ( z j l + Δ z j l ) \sigma(z^l_j+\Delta z^l_j) σ(zjl+Δzjl),这些变化会在网络中的后面层中传播,最终导致总体成本函数发生变化: ∂ C ∂ z j l Δ z j l \cfrac{\partial C}{\partial z^l_j}\Delta z^l_j ∂zjl∂CΔzjl。
现在,这个恶魔是一个好恶魔,并试图帮助你改变成本。他们试图寻找一个 Δ z j l \Delta z^l_j Δzjl可以使成本变小。假设 ∂ C ∂ z j l \cfrac{\partial C}{\partial z^l_j} ∂zjl∂C有一个很大的值(不管是正数还是负数)。恶魔可以通过选择一个与 ∂ C ∂ z j l \cfrac{\partial C}{\partial z^l_j} ∂zjl∂C有相反迹象的 Δ z j l \Delta z^l_j Δzjl,从而有效的降低成本函数。假设 ∂ C ∂ z j l \cfrac{\partial C}{\partial z^l_j} ∂zjl∂C接近于0,那么恶魔就无法通过扰乱加权输入 z j l z^l_j zjl来提高成本。所以恶魔只可以降低成本到最小,而无法上升成本。恶魔会将神经网络调至最佳状态。因此我们可以说 ∂ C ∂ z j l \cfrac{\partial C}{\partial z^l_j} ∂zjl∂C是神经元中衡量误差的标准。通过这个故事,我们定义第 l l l层的第 j j j个神经元的误差 δ j l \delta^l_j δjl: δ j l ≡ ∂ C ∂ z j l , ( 29 ) \delta^l_j \equiv \cfrac{\partial C}{\partial z^l_j}, (29) δjl≡∂zjl∂C,(29)按照惯例,我们用 δ l \delta^l δl来表示与第 l l l层相关的错误向量。
(1)输出层中的误差方程, δ L \delta^L δL: δ j L = ∂ C ∂ a j L σ ′ ( z j L ) → ( B P 1 ) \delta^L_j = \cfrac{\partial C}{\partial a^L_j} \sigma^{\prime}(z^L_j)\to(BP1) δjL=∂ajL∂Cσ′(zjL)→(BP1) ∂ C ∂ a j L \cfrac{\partial C}{\partial a^L_j} ∂ajL∂C用来衡量对第 j j j个输出激活函数,成本函数的变化有多剧烈。
σ ′ ( z j L ) \sigma^{\prime}(z^L_j) σ′(zjL)用来衡量激活函数 σ \sigma σ相对于 z j L z^L_j zjL变化的有多快。
当我们知道了成本函数是啥样的, ∂ C ∂ a j L \cfrac{\partial C}{\partial a^L_j} ∂ajL∂C的计算就没什么难度了。比如我们用二次成本函数 C = 1 2 ∑ j ( y j − a j L ) 2 C = \cfrac{1}{2} \sum_j (y_j-a^L_j)^2 C=21∑j(yj−ajL)2,那么 ∂ C / ∂ a j L = ( a j L − y j ) \partial C/\partial a^L_j = (a^L_j - y_j) ∂C/∂ajL=(ajL−yj)。
公式(BP1)对 δ L \delta^L δL来说是一个离散表达式(componentwise expression),但是对于反向传播来说它不是一个基于矩阵的形式,我们将它转换成基于矩阵形式的公式就是: δ L = ∇ a C ⊙ σ ′ ( z L ) → ( B P 1 a ) \delta^L = \nabla_aC \odot \sigma^{\prime}(z^L)\to(BP1a) δL=∇aC⊙σ′(zL)→(BP1a)这里, Δ a C \Delta aC ΔaC用来表示偏导数 ∂ C / ∂ a j L \partial C/\partial a^L_j ∂C/∂ajL,你可以想象 Δ a C \Delta aC ΔaC是用来表达 C C C相对于输出激活值的变化率。在二次成本函数下,我们有 Δ a C = ( a L − y ) \Delta aC = (a^L - y) ΔaC=(aL−y), 那么最终公式(BP1)基于矩阵的形式将会变成 δ L = ( a L − y ) ⊙ σ ′ ( z L ) → ( 30 ) \delta^L = (a^L - y) \odot \sigma^{\prime}(z^L)\to(30) δL=(aL−y)⊙σ′(zL)→(30)(2)下一层的误差方程, δ l + 1 \delta^{l+1} δl+1: δ l = ( ( w l + 1 ) T δ l + 1 ) ⊙ σ ′ ( z l ) → ( B P 2 ) \delta^l = ((w^{l+1})^T\delta^{l+1})\odot \sigma^{\prime}(z^l)\to (BP2) δl=((wl+1)Tδl+1)⊙σ′(zl)→(BP2)其中 ( w l + 1 ) T (w^{l+1})^T (wl+1)T是第 l + 1 l+1 l+1层 w l + 1 w^{l+1} wl+1的转置。这个公式看起来就像向后传播误差一样。我们使用(BP1)和(BP2)可以计算任意一层中的误差。
(3)网络中成本函数相对于所有偏差的变化率公式: ∂ C ∂ b j l = δ j l → ( B P 3 ) \cfrac{\partial C}{\partial b^l_j} = \delta^l_j \to (BP3) ∂bjl∂C=δjl→(BP3)我们可以重写公式(BP3): ∂ C ∂ b = δ → ( 31 ) \cfrac{\partial C}{\partial b} = \delta \to (31) ∂b∂C=δ→(31)这个可以理解为“在同一神经元用偏差 b b b来评估 δ \delta δ”
(4)网络中成本函数相对于任意权重的变化率: ∂ C ∂ w j k l = a k l − 1 δ j l → ( B P 4 ) \cfrac{\partial C}{\partial w^l_{jk}} = a^{l-1}_k\delta^l_j \to (BP4) ∂wjkl∂C=akl−1δjl→(BP4)通过(BP4),我们可以使用 δ l \delta^l δl和 a l − 1 a^{l-1} al−1来计算 ∂ C ∂ w j k l \cfrac{\partial C}{\partial w^l_{jk}} ∂wjkl∂C。这个公式可以重写成 ∂ C ∂ w = a i n δ o u t → ( 32 ) \cfrac{\partial C}{\partial w} = a_{in}\delta_{out}\to(32) ∂w∂C=ainδout→(32)这个公式可以理解为 a i n a_{in} ain是传向权重 w w w的输入神经元的激活值, δ o u t \delta_{out} δout是从权重 w w w传出来的神经元误差。两个神经元通过权重 w w w连接,可以描绘成: ∂ C ∂ w = \cfrac{\tiny \partial C}{\tiny \partial w}\tiny= ∂w∂C= ◯ → a i n ∗ δ o u t ◯ \bigcirc \xrightarrow{a_{in}*\delta_{out}}\bigcirc ◯ain∗δout◯当 a i n a_{in} ain趋近于0时,梯度项 ∂ C ∂ w \cfrac{\partial C}{\partial w} ∂w∂C也趋近于更小,我们称这种情况是权重学习的很缓慢,表示梯度下降期间变化不大。
四个方程的总结 δ L = ∇ a C ⊙ σ ′ ( z L ) → ( B P 1 a ) \delta^L = \nabla_aC \odot \sigma^{\prime}(z^L)\to(BP1a) δL=∇aC⊙σ′(zL)→(BP1a) δ l = ( ( w l + 1 ) T δ l + 1 ) ⊙ σ ′ ( z l ) → ( B P 2 ) \delta^l = ((w^{l+1})^T\delta^{l+1})\odot \sigma^{\prime}(z^l)\to (BP2) δl=((wl+1)Tδl+1)⊙σ′(zl)→(BP2) ∂ C ∂ b j l = δ j l → ( B P 3 ) \cfrac{\partial C}{\partial b^l_j} = \delta^l_j \to (BP3) ∂bjl∂C=δjl→(BP3) ∂ C ∂ w j k l = a k l − 1 δ j l → ( B P 4 ) \cfrac{\partial C}{\partial w^l_{jk}} = a^{l-1}_k\delta^l_j \to (BP4) ∂wjkl∂C=akl−1δjl→(BP4)
参考
- https://www.techbrood.com/zh/news/ai/用人话解释神经网络里面的前向传播和反向传播.html
- https://www.bilibili.com/video/BV16x411V7Qg?p=2
- http://neuralnetworksanddeeplearning.com/chap2.html
6、卷积网络的基本计算
6.1、Padding
假设我们有一个 n ∗ n n*n n∗n的图像,还有一个 f ∗ f f*f f∗f的过滤器,那么每次计算得到的输出就是: ( n − f + 1 ) ∗ ( n − f + 1 ) (n-f+1)*(n-f+1) (n−f+1)∗(n−f+1)普通卷积操作会有两个缺点:
- 输出图像会越来越小。如输入图像是 6 ∗ 6 6*6 6∗6,输出可能是 4 ∗ 4 4*4 4∗4。
- 处在角落或边缘区域的像素点,在输出中被采用的较少,意味着会丢掉图像的边缘位置。因为处在图像中间的像素点会被重复利用,而处在边缘或者角落的像素点只会被利用一次或者几次。
解决这类问题的办法就是填充(Padding)。
原本 6 ∗ 6 6*6 6∗6大小的图像,卷积之后输出 4 ∗ 4 4*4 4∗4。填充之后,使 6 ∗ 6 6*6 6∗6变成 8 ∗ 8 8*8 8∗8大小,再次卷积,输出就是 6 ∗ 6 6*6 6∗6,和原来的图一样大小。
我们用 P P P表示填充的数量,上面的 P = 1 P=1 P=1。输出的维数就是: n + 2 P − f + 1 n+2P-f+1 n+2P−f+1根据填充的数量多少,可以分为两种卷积:
- V a l i d Valid Valid:意思为“不填充”。输出维数是 n − f + 1 n-f+1 n−f+1。
- S a m e Same Same:输出维数是 n + 2 P − f + 1 n+2P-f+1 n+2P−f+1。
6.2、Strided convolution(卷积步长)
输出维数: n + 2 P − f S + 1 \cfrac{n+2P-f}{S}+1 Sn+2P−f+1
- 输入大小: n ∗ n n*n n∗n
- 卷积核大小: f ∗ f f*f f∗f
- 填充(Padding): P P P
- 步长(Stride): S S S
加上步长之后会遇到一个问题,如果输出维数不是整数怎么办?方法就是向下取整,取当前数值下面最接近的整数: ⌊ n + 2 P − f S + 1 ⌋ \lfloor\cfrac{n+2P-f}{S}+1\rfloor ⌊Sn+2P−f+1⌋
7、各种性能指标
- mAP
首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,记为正例(positive)和负例(negtive)分别是:
- True positives(TP):被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
- False positives(FP):被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
- False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
- True negatives(TN):被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
- P
代表precision,即准确率,计算公式为:预测样本中实际正样本数 / 所有的正样本数,即: p r e c i s i o n = T P / ( T P + F P ) ; precision=TP/(TP+FP); precision=TP/(TP+FP);
- R
代表recall,即召回率,计算公式为:预测样本中实际正样本数 / 预测的样本数,即 R e c a l l = T P / ( T P + F N ) = T P / P Recall=TP/(TP+FN)=TP/P Recall=TP/(TP+FN)=TP/P
一般来说,precision和recall是鱼与熊掌的关系,往往召回率越高,准确率越低。
- AP
AP 即Average Precision,即平均精确度。
A P = ∫ 1 2 p ( r ) d r AP =\int_1^2 p(r)dr AP=∫12p(r)dr
- mAP
mAP 即 Mean Average Precision,即平均AP值,是对多个验证集个体求平均AP值,作为 object dection中衡量检测精度的指标。
m A P = ∑ i = 1 C A P ( i ) C mAP = \cfrac{\displaystyle\sum_{i=1}^CAP(i)}{C} mAP=Ci=1∑CAP(i)
mAP@[.5:.95] :表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP
- P-R曲线
P-R曲线以 precision 和 recall 作为纵、横轴坐标的二维曲线。通过选取不同阈值时对应的精度和召回率画出。
总体趋势:精度越高,召回越低,当召回达到1时,对应概率分数最低的正样本,这个时候正样本数量除以所有大于等于该阈值的样本数量就是最低的精度值。
另外,P-R曲线围起来的面积就是AP值,通常来说一个越好的分类器,AP值越高。 在目标检测中,每一类都可以根据 recall 和 precision绘制P-R曲线,AP就是该曲线下的面积,mAP就是所有类AP的平均值。
- IOU(交并比)
IOU, 即 Intersection-over-Union,是目标检测中使用的一个概念,是一种测量在特定数据集中检测相应物体准确度的一个标准。
IOU表示了产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1。 I o U = a r e a ( C ) ∩ a r e a ( G ) a r e a ( C ) ∪ a r e a ( G ) IoU=\cfrac{area(C)\cap area(G)}{area(C)\cup area(G)} IoU=area(C)∪area(G)area(C)∩area(G)
-
NMS(非极大抑制)
NMS即non maximum suppression即非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值。
在物体检测中,NMS 应用十分广泛,其目的是为了清除多余的框,找到最佳的物体检测的位置。 -
FPS(速度 )
除了检测准确度,目标检测算法的另外一个重要性能指标是速度,只有速度快,才能实现实时检测,这对一些应用场景极其重要。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。当然要对比FPS,你需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。 -
F1-Score
F1-Score又称F1分数,是分类问题的一个衡量指标,常作为多分类问题的最终指标,它是精度和召回率的调和平均数。对于单个类别的F1分数,可使用如下公式计算
f 1 k = 2 R e c a l l k ∗ P r e c i s i o n k R e c a l l k + P r e c i s i o n k f1_k=2 \cfrac{Recall_k * Precision_k}{Recall_k + Precision_k} f1k=2Recallk+PrecisionkRecallk∗Precisionk
而后计算所有类别的平均值,记为F1,公式为
F 1 = ( 1 n ∑ f 1 k ) 2 F1=(\cfrac{1}{n} \sum f1 _k)^2 F1=(n1∑f1k)2
参考
- https://blog.csdn.net/qq_29893385/article/details/81213377
- 理解目标检测中的mAP与F1 Score
8、mini batch
8.1、什么是mini batch
我们已知在梯度下降中需要对所有样本进行处理过后然后走一步,那么如果我们的样本规模特别大的话效率就会比较低。假如样本有500万,甚至5000万个样本(在我们的业务场景中,一般有几千万行,有些大数据有10亿行)的话走一轮迭代就会非常的耗时。这个时候的梯度下降叫做full batch。 所以为了提高效率,我们可以把样本分成等量的子集。 例如我们把100万样本分成1000份, 每份1000个样本, 这些子集就称为mini batch。然后我们分别用一个for循环遍历这1000个子集。 针对每一个子集做一次梯度下降。 然后更新参数w和b的值。接着到下一个子集中继续进行梯度下降。 这样在遍历完所有的mini batch之后我们相当于在梯度下降中做了1000次迭代。 我们将遍历一次所有样本的行为叫做一个 epoch,也就是一个世代。 在mini batch下的梯度下降中做的事情其实跟full batch一样,只不过我们训练的数据不再是所有的样本,而是一个个的子集。 这样在mini batch我们在一个epoch中就能进行1000次的梯度下降,而在full batch中只有一次。 这样就大大的提高了我们算法的运行速度。
一个epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程。
8.2、mini batch的效果

如上图,左边是full batch的梯度下降效果。 可以看到每一次迭代成本函数都呈现下降趋势,这是好的现象,说明我们w和b的设定一直再减少误差。 这样一直迭代下去我们就可以找到最优解。 右边是mini batch的梯度下降效果,可以看到它是上下波动的,成本函数的值有时高有时低,但总体还是呈现下降的趋势。 这个也是正常的,因为我们每一次梯度下降都是在min batch上跑的而不是在整个数据集上。 数据的差异可能会导致这样的效果(可能某段数据效果特别好,某段数据效果不好)。但没关系,因为他整体的是呈下降趋势的。

把上面的图看做是梯度下降空间。 下面的蓝色的部分是full batch的而上面是mini batch。 就像上面说的mini batch不是每次迭代损失函数都会减少,所以看上去好像走了很多弯路。 不过整体还是朝着最优解迭代的。 而且由于mini batch一个epoch就走了5000步,而full batch一个epoch只有一步。所以虽然mini batch走了弯路但还是会快很多。
8.3、经验公式
既然有了mini batch那就会有一个batch size的超参数,也就是块大小。代表着每一个mini batch中有多少个样本。 我们一般设置为2的n次方。 例如64,128,512,1024. 一般不会超过这个范围。不能太大,因为太大了会无限接近full batch的行为,速度会慢。 也不能太小,太小了以后可能算法永远不会收敛。 当然如果我们的数据比较小, 但也用不着mini batch了, full batch的效果是最好的。
参考
- https://testerhome.com/topics/10877
9、Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,就要使用anchor box这个概念。

对于上图,行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。所以对于那个格子,输出向量y可以表示为:
[ P c b x b y b h b w c 1 c 2 c 3 ] → ( 1 ) \begin{bmatrix} P_c \\ b_x \\ b_y \\ b_h \\ b_w \\ c1 \\ c2 \\ c3 \end{bmatrix} \to (1) ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡Pcbxbybhbwc1c2c3⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤→(1)
若同时检测这三个类别:行人、汽车和摩托车,它将无法输出检测结果,所以我必须从三个检测结果中选一个。
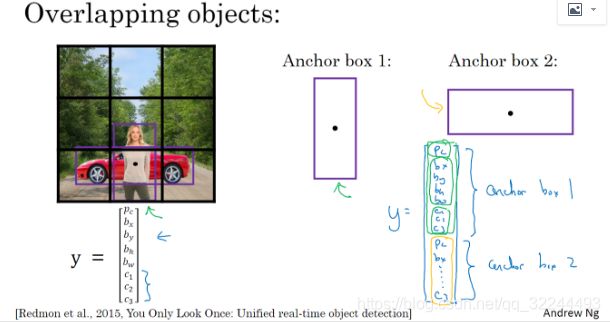
anchor box的思路是:预先定义两个不同形状的anchor box,你要做的是把预测结果和这两个anchor box关联起来。一般来说,你可能会用更多的anchor box,可能要5个甚至更多,但对于这个笔记中,我们就用两个anchor box,这样介绍起来简单一些。你要做的是定义类别标签,用的向量不再是上面的(1),而是:

前面的 p c , b x , b y , b h , b w , c 1 , c 2 , c 3 p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3 pc,bx,by,bh,bw,c1,c2,c3(绿色方框标记的参数)是和anchor box 1关联的8个参数,后面的8个参数(橙色方框标记的元素)是和anchor box 2相关联。
因为行人的形状更类似于anchor box 1的形状,而不是anchor box 2的形状,所以你可以用前8个数值,这么编码 p c = 1 p_c=1 pc=1,代表有个行人,用 b x , b y , b h b_x,b_y,b_h bx,by,bh和 b w b_w bw来编码包住行人的边界框,然后用 c 1 , c 2 , c 3 ( c 1 = 1 , c 2 = 0 , c 3 = 0 ) c_1,c_2,c_3(c_1=1,c_2=0,c_3=0) c1,c2,c3(c1=1,c2=0,c3=0)来说明这个对象是个行人。
然后是车子,因为车子的边界框比起anchor box 1更像anchor box 2的形状,你就可以这么编码: ( p c = 1 , b x , b y , b h , b w , c 1 = 0 , c 2 = 1 , c 3 = 0 ) (p_c=1,b_x,b_y,b_h,b_w,c_1=0,c_2=1,c_3=0) (pc=1,bx,by,bh,bw,c1=0,c2=1,c3=0)。
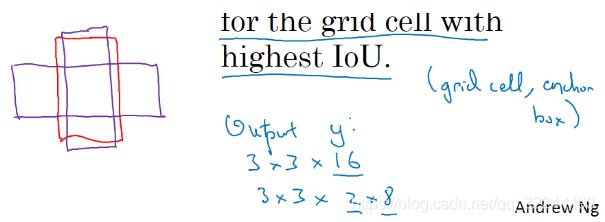
如上图,现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的anchor box中。所以这里有两个anchor box,如果你的对象形状是红色框,anchor box 1形状是竖着紫色框,anchor box 2形状是横着紫色框,然后你观察哪一个anchor box和实际边界框(红色框)的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,即(格子,anchor box)对,这就是对象在目标标签中的编码方式。所以现在输出 y 就是3×3×16,上一张幻灯片中你们看到 y 现在是16维的,或者你也可以看成是3×3×2×8,因为现在这里有2个anchor box,而 y 是8维的。y 维度是8,因为我们有3个对象类别,如果你有更多对象,那么y 的维度会更高。
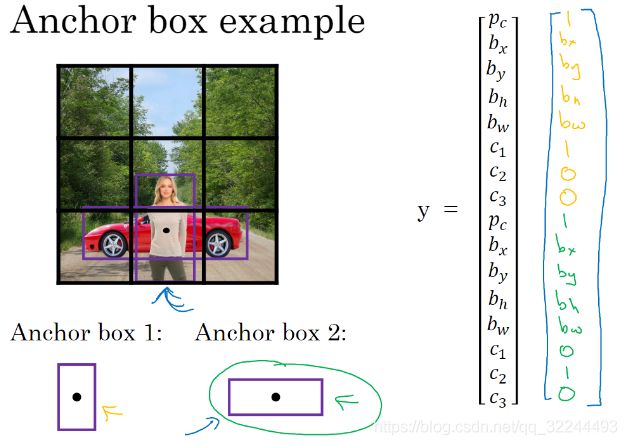
如上图,对于这个格子(黑点处),我们定义一下y,因为行人更类似于anchor box 1的形状,所以对于行人来说,我们将她分配到向量的上半部分。即p_c=1,有一个边界框包住行人,如果行人是类别1,那么 c_1=1,c_2=0,c_3=0(橙色参数)。
车子的形状更像anchor box 2,所以这个向量剩下的部分是 p_c=1,然后和车相关的边界框,然后c_1=0,c_2=1,c_3=0(绿色参数)。所以这就是对应中下格子的标签 y,箭头指向的格子。现在其中一个格子有车,没有行人,如果它里面只有一辆车,那么假设车子的边界框形状更像anchor box 2,如果这里只有一辆车,行人走开了,那么anchor box 2分量还是一样的。如果里面没有任何对象,所以 p_c=0,然后剩下的参数就别管了。
最后,你应该怎么选择anchor box呢?人们一般手工指定anchor box形状,你可以选择5到10个anchor box形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,我就简单说一句,你们如果接触过一些机器学习,可能知道后期YOLO论文中有更好的做法,就是所谓的k-平均算法,可以将两类对象形状聚类,如果我们用它来选择一组anchor box,选择最具有代表性的一组anchor box,可以代表你试图检测的十几个对象类别,但这其实是自动选择anchor box的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做。
10、BN、CBN、CmBN
10.1、BN
Batch Normalization是由google提出的一种训练优化方法。参考论文:Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift。网上对BN解释详细的不多,大多从原理上解释,没有说出实际使用的过程,这里从what, why, how三个角度去解释BN。
10.1.1、什么是BN
Normalization是数据标准化(归一化,规范化),Batch 可以理解为批量,加起来就是批量标准化。
先说Batch是怎么确定的。在CNN中,Batch就是训练网络所设定的图片数量batch_size。
Normalization过程,引用论文中的解释:

输入:输入数据 x 1 … x m x_1…x_m x1…xm(这些数据是准备进入激活函数的数据)
计算过程中可以看到,
- 求数据均值
- 求数据方差
- 数据进行标准化(个人认为称作正态化也可以)
- 训练参数 γ γ γ, β β β
- 输出通过 γ γ γ与 β β β的线性变换得到新的 y y y值
在正向传播的时候,通过可学习的 γ γ γ与 β β β参数求出新的分布值
在反向传播的时候,通过链式求导方式,求出 γ γ γ与 β β β以及相关权值

10.1.2、为什么要用BN
BN要解决的问题是梯度消失与梯度爆炸。
关于梯度消失,以sigmoid函数为例子,sigmoid函数使得输出在[0,1]之间。

事实上 x x x到了一定大小,经过sigmoid函数的输出范围就很小了,参考下图:
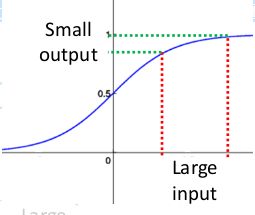
如果输入很大,其对应的斜率就很小。我们知道,其斜率(梯度)在反向传播中是权值学习速率。所以就会出现如下的问题:

在深度网络中,如果网络的激活输出很大,其梯度就很小,学习速率就很慢。假设每层学习梯度都小于最大值0.25,网络有n层,因为链式求导的原因,第一层的梯度小于0.25的n次方,所以学习速率就慢,对于最后一层只需对自身求导1次,梯度就大,学习速率就快。
这会造成的影响是在一个很大的深度网络中,浅层基本不学习,权值变化小,后面几层一直在学习,结果就是,后面几层基本可以表示整个网络,失去了深度的意义。
关于梯度爆炸,根据链式求导法:
第 一 层 偏 移 量 的 梯 度 = 激 活 层 斜 率 1 ∗ 权 值 1 ∗ 激 活 层 斜 率 2 ∗ … 激 活 层 斜 率 ( n − 1 ) ∗ 权 值 ( n − 1 ) ∗ 激 活 层 斜 率 n 第一层偏移量的梯度=激活层斜率1*权值1*激活层斜率2*…激活层斜率(n-1)*权值(n-1)*激活层斜率n 第一层偏移量的梯度=激活层斜率1∗权值1∗激活层斜率2∗…激活层斜率(n−1)∗权值(n−1)∗激活层斜率n
假如激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会指数增加。
BN算法在网络中的作用
BN算法像卷积层,池化层、激活层一样也输入一层。BN层添加在激活函数前,对输入激活函数的输入进行归一化。这样解决了输入数据发生偏移和增大的影响。
- 加快训练速度,能够增大学习率,即使小的学习率也能够有快速的学习速率;
- 不用理会拟合中的droupout、L2 正则化项的参数选择,采用BN算法可以省去这两项或者只需要小的L2正则化约束。原因,BN算法后,参数进行了归一化,原本经过激活函数没有太大影响的神经元,分布变得明显,经过一个激活函数以后,神经元会自动削弱或者去除一些神经元,就不用再对其进行dropout。另外就是L2正则化,由于每次训练都进行了归一化,就很少发生由于数据分布不同导致的参数变动过大,带来的参数不断增大。
- 可以把训练数据集打乱,防止训练发生偏移。
10.1.3、如何使用BN
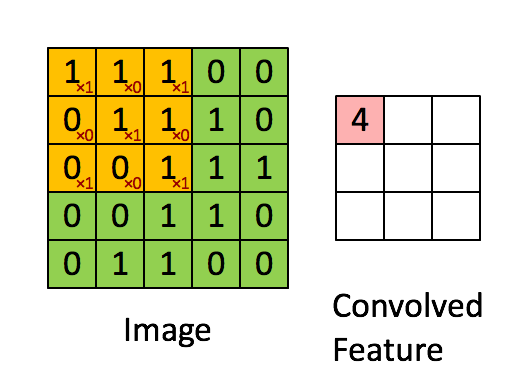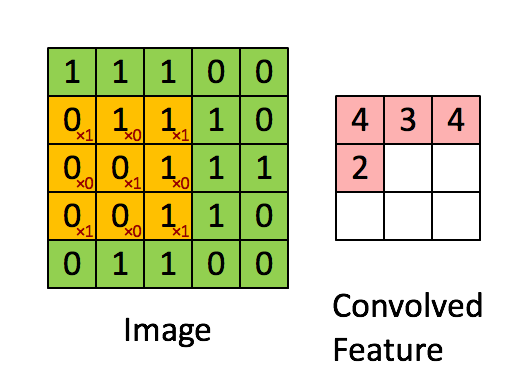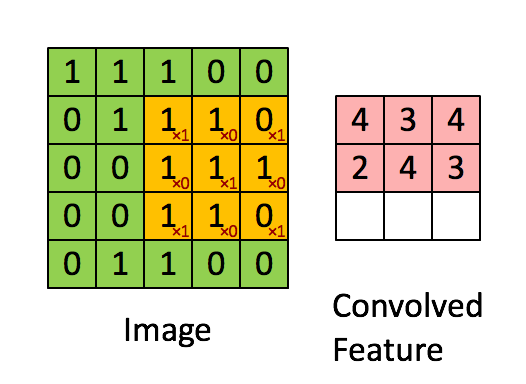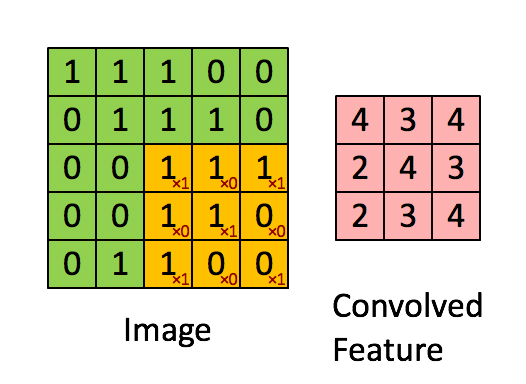
这是论文卷积神经网络CNN中5x5的图片通过valid卷积得到的3x3特征图(粉红色)。这里假设通道数为1,batch为4,即大小为[4,1,3,3] (n,c,h,w)。特征图里的值,作为BN的输入,这里简化输出只有一个channel,也就是这一个4x3x3个数值通过BN计算并保存均值与方差,并通过当前均值与方差计算归一化的值,最后根据 γ γ γ, β β β以及归一化得值计算BN层输出。
这里需要着重说明的细节:
网络训练中以batch_size为最小单位不断迭代,很显然,新的batch_size进入网络,由于每一次的batch有差异,实际是通过变量,以及滑动平均来记录均值与方差。训练完成后,推断阶段时通过 γ γ γ, β β β,以及记录的均值与方差计算bn层输出。
结合论文中给出的使用过程进行解释:

输入:待进入激活函数的变量
输出:
- 对于K个激活函数前的输入,所以需要K个循环。每个循环中按照上面所介绍的方法计算均值与方差。通过 γ γ γ, β β β与输入 x x x的变换求出BN层输出。
- 在反向传播时利用 γ γ γ与 β β β求得梯度从而改变训练权值(变量)。
- 通过不断迭代直到训练结束,得到 γ γ γ与 β β β,以及记录的均值方差。
- 在预测的正向传播时,使用训练时最后得到的 γ γ γ与 β β β,以及均值与方差的无偏估计,通过图中11所表示的公式计算BN层输出。
10.2、CBN
原文链接:Cross-Iteration Batch Normalization
代码链接:https://github.com/Howal/Cross-iterationBatchNorm
随着BN的提出,现有的网络基本都在使用。但是在显存有限或者某些任务不允许大batch(比如检测或者分割任务相比分类任务训练时的batchsize一般会小很多)的情况下,BN效果就会差很多,如下图所示,当batch小于16时分类准确率急剧下降。

为了改善小batch情况下网络性能下降的问题,有各种新的normalize方法被提出来了(LN、IN、GN),详情请看文章GN-Group Normalization。上述不同的normalize方式适用于不同的任务,其中GN就是为检测任务设计的,但是它会降低推断时的速度。
本文的思想其实很简单,既然从空间维度不好做,那么就从时间维度进行,通过以前算好的BN参数用来计算更新新的BN参数,从而改善网络性能。从上图可以看出使用新提出的CBN,即使batch size小也可以获得较好的分类准确率。
通过过去的BN参数来计算新的BN参数有个问题,就是过去的BN参数是根据过去的网络参数计算出的feature来估算的,新的BN参数计算时,参数已经更新过了,如果直接使用之前的参数来计算新的BN参数会使得参数估计不准,网络性能下降,如上图中的Naive CBN。为了改进这种缺陷,文章使用泰勒多项式来估算新的BN参数。
CBN的工作方式如下:
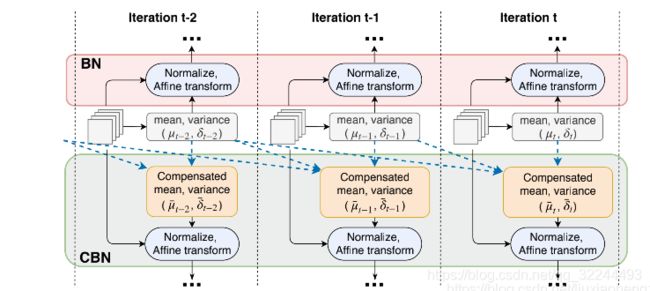
最后要说的是,这篇文章提出来时为了解决小batch训练的情况,yolov4提出有一点就是方便用户使用一个GPU训练,所以yolov4借用了该算法的思想。
10.3、CmBN

CmBN是CBN的修改版本,如上图所示,定义为Cross mini-Batch Normalization (CmBN)。它仅在单批次中的小批次之间收集统计数据。
参考
- https://blog.csdn.net/weixin_43937316/article/details/99573134
- https://blog.csdn.net/qq_37100442/article/details/81776191
- https://blog.csdn.net/liuxiaoheng1992/article/details/108107739
11、SPP
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小,通常的手法就是裁剪(crop)和拉伸(warp),见下图。

这样做总是不好的:图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像。而Kaiming He在这里提出了一个SPP(Spatial Pyramid Pooling)层能很好的解决这样的问题, SPP通常连接在最后一层卷积层,见下图。

SPP 显著特点
- 不管输入尺寸是怎样,SPP 可以产生固定大小的输出
- 使用多个窗口(pooling window)
- SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
其它特点
- 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
- 实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
- SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
- 不仅可以用于图像分类而且可以用来目标检测

使用上图意在说明保留原图片的尺寸对实验的特征提取和结果都很重要
为什么会得固定大小的输出?

上面=使用多个窗口(pooling窗口,上图中蓝色,青绿,银灰的窗口, 然后对feature maps 进行pooling,将分别得到的结果进行合并就会得到固定长度的输出), 这就是得到固定输出的秘密原因。
SPP分类
作者在分类的时候得到如下几个结果
- 多窗口的pooling会提高实验的准确率
- 输入同一图像的不同尺寸,会提高实验准确率(从尺度空间来看,提高了尺度不变性(scale invariance))
- 用了多View(multi-view)来测试,也提高了测试结果
- 图像输入的尺寸对实验的结果是有影响的(因为目标特征区域有大有有小)
- 因为我们替代的是网络的Pooling层,对整个网络结构没有影响,所以可以使得整个网络可以正常训练。
SPP目标检测

整体先对整张图片进行卷积然后,在把其中的目标窗口拿出来Pooling,得到的结果用作全连接层的输入。
参考
- https://blog.csdn.net/yzf0011/article/details/75212513
12、池化层
12.1、最大池化
参考:https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d