NNDL 实验六 卷积神经网络(4)ResNet18实现MNIST
目录
5.4 基于残差网络的手写体数字识别实验
5.4.1 模型构建
5.4.1.1 残差单元
5.4.1.2 残差网络的整体结构
5.4.2 没有残差连接的ResNet18
5.4.2.1 模型训练
5.4.2.2 模型评价
5.4.3 带残差连接的ResNet18
5.4.3.1 模型训练
5.4.3.2 模型评价
5.4.4 与高层API实现版本的对比实验
总结
5.4 基于残差网络的手写体数字识别实验
残差网络(Residual Network,ResNet)是在神经网络模型中给非线性层增加直连边的方式来缓解梯度消失问题,从而使训练深度神经网络变得更加容易。
在残差网络中,最基本的单位为残差单元。
假设f(x;θ)为一个或多个神经层,残差单元在f()的输入和输出之间加上一个直连边。
不同于传统网络结构中让网络f(x;θ)去逼近一个目标函数h(x),在残差网络中,将目标函数h(x)h(x)拆为了两个部分:恒等函数x和残差函数h(x)−x
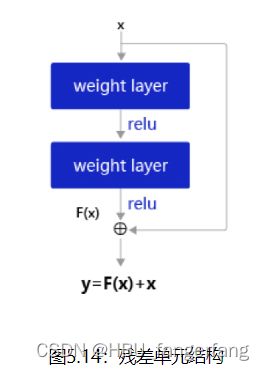
一个残差网络通常有很多个残差单元堆叠而成。下面我们来构建一个在计算机视觉中非常典型的残差网络:ResNet18,并重复上一节中的手写体数字识别任务。
5.4.1 模型构建
在本节中,我们先构建ResNet18的残差单元,然后在组建完整的网络。
5.4.1.1 残差单元
这里,我们实现一个算子ResBlock来构建残差单元,其中定义了use_residual参数,用于在后续实验中控制是否使用残差连接。
残差单元包裹的非线性层的输入和输出形状大小应该一致。如果一个卷积层的输入特征图和输出特征图的通道数不一致,则其输出与输入特征图无法直接相加。为了解决上述问题,我们可以使用1×1大小的卷积将输入特征图的通道数映射为与级联卷积输出特征图的一致通道数。
1×1卷积:与标准卷积完全一样,唯一的特殊点在于卷积核的尺寸是1×1,也就是不去考虑输入数据局部信息之间的关系,而把关注点放在不同通道间。通过使用1×1卷积,可以起到如下作用:
- 实现信息的跨通道交互与整合。考虑到卷积运算的输入输出都是3个维度(宽、高、多通道),所以1×1卷积实际上就是对每个像素点,在不同的通道上进行线性组合,从而整合不同通道的信息;
- 对卷积核通道数进行降维和升维,减少参数量。经过1×1卷积后的输出保留了输入数据的原有平面结构,通过调控通道数,从而完成升维或降维的作用;
- 利用1×1卷积后的非线性激活函数,在保持特征图尺寸不变的前提下,大幅增加非线性。
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, use_residual=True):
"""
残差单元
输入:
- in_channels:输入通道数
- out_channels:输出通道数
- stride:残差单元的步长,通过调整残差单元中第一个卷积层的步长来控制
- use_residual:用于控制是否使用残差连接
"""
super(ResBlock, self).__init__()
self.stride = stride
self.use_residual = use_residual
# 第一个卷积层,卷积核大小为3×3,可以设置不同输出通道数以及步长
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, padding=1, stride=self.stride, bias=False)
# 第二个卷积层,卷积核大小为3×3,不改变输入特征图的形状,步长为1
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False)
# 如果conv2的输出和此残差块的输入数据形状不一致,则use_1x1conv = True
# 当use_1x1conv = True,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致
if in_channels != out_channels or stride != 1:
self.use_1x1conv = True
else:
self.use_1x1conv = False
# 当残差单元包裹的非线性层输入和输出通道数不一致时,需要用1×1卷积调整通道数后再进行相加运算
if self.use_1x1conv:
self.shortcut = nn.Conv2d(in_channels, out_channels, 1, stride=self.stride, bias=False)
# 每个卷积层后会接一个批量规范化层,批量规范化的内容在7.5.1中会进行详细介绍
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
if self.use_1x1conv:
self.bn3 = nn.BatchNorm2d(out_channels)
def forward(self, inputs):
y = F.relu(self.bn1(self.conv1(inputs)))
y = self.bn2(self.conv2(y))
if self.use_residual:
if self.use_1x1conv: # 如果为真,对inputs进行1×1卷积,将形状调整成跟conv2的输出y一致
shortcut = self.shortcut(inputs)
shortcut = self.bn3(shortcut)
else: # 否则直接将inputs和conv2的输出y相加
shortcut = inputs
y = torch.add(shortcut, y)
out = F.relu(y)
return out5.4.1.2 残差网络的整体结构
残差网络就是将很多个残差单元串联起来构成的一个非常深的网络。ResNet18 的网络结构如图5.16所示。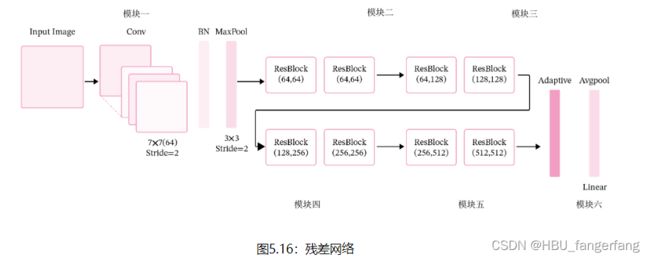
其中为了便于理解,可以将ResNet18网络划分为6个模块:
- 第一模块:包含了一个步长为2,大小为7×77×7的卷积层,卷积层的输出通道数为64,卷积层的输出经过批量归一化、ReLU激活函数的处理后,接了一个步长为2的3×33×3的最大汇聚层;
- 第二模块:包含了两个残差单元,经过运算后,输出通道数为64,特征图的尺寸保持不变;
- 第三模块:包含了两个残差单元,经过运算后,输出通道数为128,特征图的尺寸缩小一半;
- 第四模块:包含了两个残差单元,经过运算后,输出通道数为256,特征图的尺寸缩小一半;
- 第五模块:包含了两个残差单元,经过运算后,输出通道数为512,特征图的尺寸缩小一半;
- 第六模块:包含了一个全局平均汇聚层,将特征图变为1×1的大小,最终经过全连接层计算出最后的输出。
ResNet18模型的代码实现如下:
定义模块一。
def make_first_module(in_channels):
# 模块一:7*7卷积、批量规范化、汇聚
m1 = nn.Sequential(nn.Conv2d(in_channels, 64, 7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
return m1定义模块二到模块五。
def resnet_module(input_channels, out_channels, num_res_blocks, stride=1, use_residual=True):
blk = []
# 根据num_res_blocks,循环生成残差单元
for i in range(num_res_blocks):
if i == 0: # 创建模块中的第一个残差单元
blk.append(ResBlock(input_channels, out_channels,
stride=stride, use_residual=use_residual))
else: # 创建模块中的其他残差单元
blk.append(ResBlock(out_channels, out_channels, use_residual=use_residual))
return blk封装模块二到模块五。
def make_modules(use_residual):
# 模块二:包含两个残差单元,输入通道数为64,输出通道数为64,步长为1,特征图大小保持不变
m2 = nn.Sequential(*resnet_module(64, 64, 2, stride=1, use_residual=use_residual))
# 模块三:包含两个残差单元,输入通道数为64,输出通道数为128,步长为2,特征图大小缩小一半。
m3 = nn.Sequential(*resnet_module(64, 128, 2, stride=2, use_residual=use_residual))
# 模块四:包含两个残差单元,输入通道数为128,输出通道数为256,步长为2,特征图大小缩小一半。
m4 = nn.Sequential(*resnet_module(128, 256, 2, stride=2, use_residual=use_residual))
# 模块五:包含两个残差单元,输入通道数为256,输出通道数为512,步长为2,特征图大小缩小一半。
m5 = nn.Sequential(*resnet_module(256, 512, 2, stride=2, use_residual=use_residual))
return m2, m3, m4, m5定义完整网络。
# 定义完整网络
class Model_ResNet18(nn.Module):
def __init__(self, in_channels=3, num_classes=10, use_residual=True):
super(Model_ResNet18, self).__init__()
m1 = make_first_module(in_channels)
m2, m3, m4, m5 = make_modules(use_residual)
# 封装模块一到模块6
self.net = nn.Sequential(m1, m2, m3, m4, m5,
# 模块六:汇聚层、全连接层
nn.AdaptiveAvgPool2d(1), nn.Flatten(), nn.Linear(512, num_classes))
def forward(self, x):
return self.net(x)
这里同样可以使用torchsummary.summary统计模型的参数量。
import torchsummary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Model_ResNet18(in_channels=1, num_classes=10, use_residual=True).to(device)
torchsummary.summary(model, (1, 32, 32))得到以下结果:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 16, 16] 3,200
BatchNorm2d-2 [-1, 64, 16, 16] 128
ReLU-3 [-1, 64, 16, 16] 0
MaxPool2d-4 [-1, 64, 8, 8] 0
Conv2d-5 [-1, 64, 8, 8] 36,864
BatchNorm2d-6 [-1, 64, 8, 8] 128
Conv2d-7 [-1, 64, 8, 8] 36,864
BatchNorm2d-8 [-1, 64, 8, 8] 128
ResBlock-9 [-1, 64, 8, 8] 0
Conv2d-10 [-1, 64, 8, 8] 36,864
BatchNorm2d-11 [-1, 64, 8, 8] 128
Conv2d-12 [-1, 64, 8, 8] 36,864
BatchNorm2d-13 [-1, 64, 8, 8] 128
ResBlock-14 [-1, 64, 8, 8] 0
Conv2d-15 [-1, 128, 4, 4] 73,728
BatchNorm2d-16 [-1, 128, 4, 4] 256
Conv2d-17 [-1, 128, 4, 4] 147,456
BatchNorm2d-18 [-1, 128, 4, 4] 256
Conv2d-19 [-1, 128, 4, 4] 8,192
BatchNorm2d-20 [-1, 128, 4, 4] 256
ResBlock-21 [-1, 128, 4, 4] 0
Conv2d-22 [-1, 128, 4, 4] 147,456
BatchNorm2d-23 [-1, 128, 4, 4] 256
Conv2d-24 [-1, 128, 4, 4] 147,456
BatchNorm2d-25 [-1, 128, 4, 4] 256
ResBlock-26 [-1, 128, 4, 4] 0
Conv2d-27 [-1, 256, 2, 2] 294,912
BatchNorm2d-28 [-1, 256, 2, 2] 512
Conv2d-29 [-1, 256, 2, 2] 589,824
BatchNorm2d-30 [-1, 256, 2, 2] 512
Conv2d-31 [-1, 256, 2, 2] 32,768
BatchNorm2d-32 [-1, 256, 2, 2] 512
ResBlock-33 [-1, 256, 2, 2] 0
Conv2d-34 [-1, 256, 2, 2] 589,824
BatchNorm2d-35 [-1, 256, 2, 2] 512
Conv2d-36 [-1, 256, 2, 2] 589,824
BatchNorm2d-37 [-1, 256, 2, 2] 512
ResBlock-38 [-1, 256, 2, 2] 0
Conv2d-39 [-1, 512, 1, 1] 1,179,648
BatchNorm2d-40 [-1, 512, 1, 1] 1,024
Conv2d-41 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-42 [-1, 512, 1, 1] 1,024
Conv2d-43 [-1, 512, 1, 1] 131,072
BatchNorm2d-44 [-1, 512, 1, 1] 1,024
ResBlock-45 [-1, 512, 1, 1] 0
Conv2d-46 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-47 [-1, 512, 1, 1] 1,024
Conv2d-48 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-49 [-1, 512, 1, 1] 1,024
ResBlock-50 [-1, 512, 1, 1] 0
AdaptiveAvgPool2d-51 [-1, 512, 1, 1] 0
Flatten-52 [-1, 512] 0
Linear-53 [-1, 10] 5,130
================================================================
Total params: 11,175,434
Trainable params: 11,175,434
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 1.05
Params size (MB): 42.63
Estimated Total Size (MB): 43.69
----------------------------------------------------------------
进程已结束,退出代码为 0
使用torchstat统计模型的计算量。
[MAdd]: AdaptiveAvgPool2d is not supported!
[Flops]: AdaptiveAvgPool2d is not supported!
[Memory]: AdaptiveAvgPool2d is not supported!
[MAdd]: Flatten is not supported!
[Flops]: Flatten is not supported!
[Memory]: Flatten is not supported!
df = df.append(total_df)
module name input shape output shape params memory(MB) MAdd Flops MemRead(B) MemWrite(B) duration[%] MemR+W(B)
0 net.0.0 1 32 32 64 16 16 3200.0 0.06 1,605,632.0 819,200.0 16896.0 65536.0 11.11% 82432.0
1 net.0.1 64 16 16 64 16 16 128.0 0.06 65,536.0 32,768.0 66048.0 65536.0 11.11% 131584.0
2 net.0.2 64 16 16 64 16 16 0.0 0.06 16,384.0 16,384.0 65536.0 65536.0 0.00% 131072.0
3 net.0.3 64 16 16 64 8 8 0.0 0.02 32,768.0 16,384.0 65536.0 16384.0 0.00% 81920.0
4 net.1.0.conv1 64 8 8 64 8 8 36864.0 0.02 4,714,496.0 2,359,296.0 163840.0 16384.0 11.11% 180224.0
5 net.1.0.conv2 64 8 8 64 8 8 36864.0 0.02 4,714,496.0 2,359,296.0 163840.0 16384.0 0.00% 180224.0
6 net.1.0.bn1 64 8 8 64 8 8 128.0 0.02 16,384.0 8,192.0 16896.0 16384.0 0.00% 33280.0
7 net.1.0.bn2 64 8 8 64 8 8 128.0 0.02 16,384.0 8,192.0 16896.0 16384.0 0.00% 33280.0
8 net.1.1.conv1 64 8 8 64 8 8 36864.0 0.02 4,714,496.0 2,359,296.0 163840.0 16384.0 11.11% 180224.0
9 net.1.1.conv2 64 8 8 64 8 8 36864.0 0.02 4,714,496.0 2,359,296.0 163840.0 16384.0 0.00% 180224.0
10 net.1.1.bn1 64 8 8 64 8 8 128.0 0.02 16,384.0 8,192.0 16896.0 16384.0 0.00% 33280.0
11 net.1.1.bn2 64 8 8 64 8 8 128.0 0.02 16,384.0 8,192.0 16896.0 16384.0 0.00% 33280.0
12 net.2.0.conv1 64 8 8 128 4 4 73728.0 0.01 2,357,248.0 1,179,648.0 311296.0 8192.0 0.00% 319488.0
13 net.2.0.conv2 128 4 4 128 4 4 147456.0 0.01 4,716,544.0 2,359,296.0 598016.0 8192.0 0.00% 606208.0
14 net.2.0.shortcut 64 8 8 128 4 4 8192.0 0.01 260,096.0 131,072.0 49152.0 8192.0 0.00% 57344.0
15 net.2.0.bn1 128 4 4 128 4 4 256.0 0.01 8,192.0 4,096.0 9216.0 8192.0 11.11% 17408.0
16 net.2.0.bn2 128 4 4 128 4 4 256.0 0.01 8,192.0 4,096.0 9216.0 8192.0 0.00% 17408.0
17 net.2.0.bn3 128 4 4 128 4 4 256.0 0.01 8,192.0 4,096.0 9216.0 8192.0 0.00% 17408.0
18 net.2.1.conv1 128 4 4 128 4 4 147456.0 0.01 4,716,544.0 2,359,296.0 598016.0 8192.0 11.11% 606208.0
19 net.2.1.conv2 128 4 4 128 4 4 147456.0 0.01 4,716,544.0 2,359,296.0 598016.0 8192.0 0.00% 606208.0
20 net.2.1.bn1 128 4 4 128 4 4 256.0 0.01 8,192.0 4,096.0 9216.0 8192.0 0.00% 17408.0
21 net.2.1.bn2 128 4 4 128 4 4 256.0 0.01 8,192.0 4,096.0 9216.0 8192.0 0.00% 17408.0
22 net.3.0.conv1 128 4 4 256 2 2 294912.0 0.00 2,358,272.0 1,179,648.0 1187840.0 4096.0 0.00% 1191936.0
23 net.3.0.conv2 256 2 2 256 2 2 589824.0 0.00 4,717,568.0 2,359,296.0 2363392.0 4096.0 0.00% 2367488.0
24 net.3.0.shortcut 128 4 4 256 2 2 32768.0 0.00 261,120.0 131,072.0 139264.0 4096.0 0.00% 143360.0
25 net.3.0.bn1 256 2 2 256 2 2 512.0 0.00 4,096.0 2,048.0 6144.0 4096.0 0.00% 10240.0
26 net.3.0.bn2 256 2 2 256 2 2 512.0 0.00 4,096.0 2,048.0 6144.0 4096.0 0.00% 10240.0
27 net.3.0.bn3 256 2 2 256 2 2 512.0 0.00 4,096.0 2,048.0 6144.0 4096.0 0.00% 10240.0
28 net.3.1.conv1 256 2 2 256 2 2 589824.0 0.00 4,717,568.0 2,359,296.0 2363392.0 4096.0 0.00% 2367488.0
29 net.3.1.conv2 256 2 2 256 2 2 589824.0 0.00 4,717,568.0 2,359,296.0 2363392.0 4096.0 11.11% 2367488.0
30 net.3.1.bn1 256 2 2 256 2 2 512.0 0.00 4,096.0 2,048.0 6144.0 4096.0 0.00% 10240.0
31 net.3.1.bn2 256 2 2 256 2 2 512.0 0.00 4,096.0 2,048.0 6144.0 4096.0 0.00% 10240.0
32 net.4.0.conv1 256 2 2 512 1 1 1179648.0 0.00 2,358,784.0 1,179,648.0 4722688.0 2048.0 11.11% 4724736.0
33 net.4.0.conv2 512 1 1 512 1 1 2359296.0 0.00 4,718,080.0 2,359,296.0 9439232.0 2048.0 0.00% 9441280.0
34 net.4.0.shortcut 256 2 2 512 1 1 131072.0 0.00 261,632.0 131,072.0 528384.0 2048.0 0.00% 530432.0
35 net.4.0.bn1 512 1 1 512 1 1 1024.0 0.00 2,048.0 1,024.0 6144.0 2048.0 0.00% 8192.0
36 net.4.0.bn2 512 1 1 512 1 1 1024.0 0.00 2,048.0 1,024.0 6144.0 2048.0 0.00% 8192.0
37 net.4.0.bn3 512 1 1 512 1 1 1024.0 0.00 2,048.0 1,024.0 6144.0 2048.0 0.00% 8192.0
38 net.4.1.conv1 512 1 1 512 1 1 2359296.0 0.00 4,718,080.0 2,359,296.0 9439232.0 2048.0 0.00% 9441280.0
39 net.4.1.conv2 512 1 1 512 1 1 2359296.0 0.00 4,718,080.0 2,359,296.0 9439232.0 2048.0 0.00% 9441280.0
40 net.4.1.bn1 512 1 1 512 1 1 1024.0 0.00 2,048.0 1,024.0 6144.0 2048.0 0.00% 8192.0
41 net.4.1.bn2 512 1 1 512 1 1 1024.0 0.00 2,048.0 1,024.0 6144.0 2048.0 0.00% 8192.0
42 net.5 512 1 1 512 1 1 0.0 0.00 0.0 0.0 0.0 0.0 11.11% 0.0
43 net.6 512 1 1 512 0.0 0.00 0.0 0.0 0.0 0.0 0.00% 0.0
44 net.7 512 10 5130.0 0.00 10,230.0 5,120.0 22568.0 40.0 0.00% 22608.0
total 11175434.0 0.47 71,039,478.0 35,561,472.0 22568.0 40.0 100.00% 45695056.0
=====================================================================================================================================================
Total params: 11,175,434
-----------------------------------------------------------------------------------------------------------------------------------------------------
Total memory: 0.47MB
Total MAdd: 71.04MMAdd
Total Flops: 35.56MFlops
Total MemR+W: 43.58MB
进程已结束,退出代码为 0为了验证残差连接对深层卷积神经网络的训练可以起到促进作用,接下来先使用ResNet18(use_residual设置为False)进行手写数字识别实验,再添加残差连接(use_residual设置为True),观察实验对比效果。
5.4.2 没有残差连接的ResNet18
为了验证残差连接的效果,先使用没有残差连接的ResNet18进行实验。
5.4.2.1 模型训练
使用训练集和验证集进行模型训练,共训练5个epoch。在实验中,保存准确率最高的模型作为最佳模型。代码实现如下
with open('mnist.json','r',encoding='utf-8') as f :
train_set, dev_set, test_set = json.load(f)
train_images, train_labels = train_set[0][:1000], train_set[1][:1000]
dev_images, dev_labels = dev_set[0][:200], dev_set[1][:200]
test_images, test_labels = test_set[0][:200], test_set[1][:200]
train_set, dev_set, test_set = [train_images, train_labels], [dev_images, dev_labels], [test_images, test_labels]
# 数据预处理
transforms = transforms.Compose(
[transforms.Resize(32), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5])])
class MNIST_dataset(Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms = transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = np.reshape(image, [28, 28])
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.dataset[0])
# 加载 mnist 数据集
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
# 学习率大小
lr = 0.005
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 定义网络,不使用残差结构的深层网络
model = Model_ResNet18(in_channels=1, num_classes=10, use_residual=False)
# 定义优化器
optimizer = opt.SGD(model.parameters(), lr)
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy()
# 实例化RunnerV3
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader, num_epochs=5, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
# 可视化观察训练集与验证集的Loss变化情况
tools.plot_training_loss_acc(runner, 'cnn-loss2.pdf')
[Train] epoch: 0/5, step: 0/80, loss: 2.48766
[Train] epoch: 0/5, step: 15/80, loss: 0.87648
[Evaluate] dev score: 0.14500, dev loss: 2.30618
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.14500
[Train] epoch: 1/5, step: 30/80, loss: 0.63824
[Evaluate] dev score: 0.09000, dev loss: 2.31573
[Train] epoch: 2/5, step: 45/80, loss: 0.24605
[Evaluate] dev score: 0.68000, dev loss: 1.33565
[Evaluate] best accuracy performence has been updated: 0.14500 --> 0.68000
[Train] epoch: 3/5, step: 60/80, loss: 0.10985
[Evaluate] dev score: 0.92500, dev loss: 0.42161
[Evaluate] best accuracy performence has been updated: 0.68000 --> 0.92500
[Train] epoch: 4/5, step: 75/80, loss: 0.07589
[Evaluate] dev score: 0.93500, dev loss: 0.29027
[Evaluate] best accuracy performence has been updated: 0.92500 --> 0.93500
[Evaluate] dev score: 0.92500, dev loss: 0.28957
[Train] Training done!
5.4.2.2 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))[Test] accuracy/loss: 0.9100/0.3502从输出结果看,对比LeNet-5模型评价实验结果,网络层级加深后,训练效果有所提高。
5.4.3 带残差连接的ResNet18
5.4.3.1 模型训练
使用带残差连接的ResNet18重复上面的实验,代码实现如下:
# 定义网络,使用残差结构的深层网络
model = Model_ResNet18(in_channels=1, num_classes=10, use_residual=True)[Train] epoch: 0/5, step: 0/80, loss: 2.26826
[Train] epoch: 0/5, step: 15/80, loss: 1.43595
[Evaluate] dev score: 0.10000, dev loss: 2.30691
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.10000
[Train] epoch: 1/5, step: 30/80, loss: 0.58626
[Evaluate] dev score: 0.11500, dev loss: 2.32619
[Evaluate] best accuracy performence has been updated: 0.10000 --> 0.11500
[Train] epoch: 2/5, step: 45/80, loss: 0.19654
[Evaluate] dev score: 0.74000, dev loss: 1.33591
[Evaluate] best accuracy performence has been updated: 0.11500 --> 0.74000
[Train] epoch: 3/5, step: 60/80, loss: 0.11636
[Evaluate] dev score: 0.87000, dev loss: 0.44253
[Evaluate] best accuracy performence has been updated: 0.74000 --> 0.87000
[Train] epoch: 4/5, step: 75/80, loss: 0.07835
[Evaluate] dev score: 0.91500, dev loss: 0.33653
[Evaluate] best accuracy performence has been updated: 0.87000 --> 0.91500
[Evaluate] dev score: 0.90000, dev loss: 0.31524
[Train] Training done!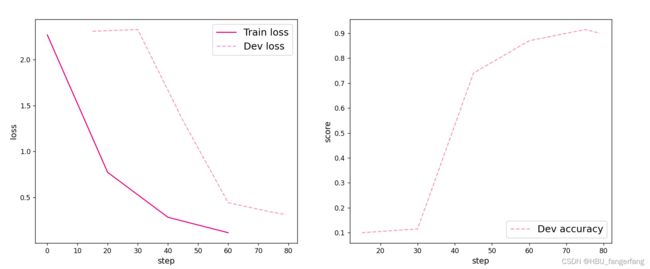
5.4.3.2 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))得到以下结果:
[Test] accuracy/loss: 0.9050/0.3552
5.4.4 与高层API实现版本的对比实验
Pytorch 提供 torchvision.models 接口,里面包含了一些常用用的网络结构,并提供了预训练模型,可以通过简单调用来读取网络结构和预训练模型。
官方文档地址:https://pytorch.org/docs/master/torchvision/models.html#
PyTorch定义了几个常用模型,并且提供了预训练版本:
AlexNet: AlexNet variant from the “One weird trick” paper.
VGG: VGG-11, VGG-13, VGG-16, VGG-19 (with and without batch normalization)
ResNet: ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152
SqueezeNet: SqueezeNet 1.0, and SqueezeNet 1.1
下面以resnet18进行测试:
from collections import OrderedDict
import warnings
warnings.filterwarnings("ignore")
# 使用飞桨HAPI中实现的resnet18模型,该模型默认输入通道数为3,输出类别数1000
hapi_model = resnet18()
# 自定义的resnet18模型
model = Model_ResNet18(in_channels=3, num_classes=1000, use_residual=True)
# 获取网络的权重
params = hapi_model.state_dict()
# 用来保存参数名映射后的网络权重
new_params = {}
# 将参数名进行映射
for key in params:
if 'layer' in key:
if 'downsample.0' in key:
new_params['net.' + key[5:8] + '.shortcut' + key[-7:]] = params[key]
elif 'downsample.1' in key:
new_params['net.' + key[5:8] + '.bn3.' + key[22:]] = params[key]
else:
new_params['net.' + key[5:]] = params[key]
elif 'conv1.weight' == key:
new_params['net.0.0.weight'] = params[key]
elif 'conv1.bias' == key:
new_params['net.0.0.bias'] = params[key]
elif 'bn1' in key:
new_params['net.0.1' + key[3:]] = params[key]
elif 'fc' in key:
new_params['net.7' + key[2:]] = params[key]
new_params['net.0.0.bias'] = torch.zeros([64])
# 将飞桨HAPI中实现的resnet18模型的权重参数赋予自定义的resnet18模型,保持两者一致
model.load_state_dict(OrderedDict(new_params))
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[3, 3, 32, 32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
output = model(x)
hapi_out = hapi_model(x)
# 计算两个模型输出的差异
diff = output - hapi_out
# 取差异最大的值
max_diff = torch.max(diff)
print(max_diff)得到以下结果:
tensor(0., grad_fn=)
可以看到,高层API版本的resnet18模型和自定义的resnet18模型输出结果是一致的,也就说明两个模型的实现完全一样。
总结
这个实验收获最大的就是这个ResNet18网络模型了,首先看到这个名字的第一眼就知道是ResNet网络,18应该就是权重层的数量。
然后看了ResNet18网络的论文和一些资料,总结出来ResNet18的基本含义是,网络的基本架构是ResNet,网络的深度是18层。但是这里的网络深度指的是网络的权重层,也就是包括池化,激活,线性层。而不包括批量化归一层,池化层。
然后就是为什么要用ResNet18,用别的不行吗?比如VGG串联起来。
随着网络越来越深,训练变得原来越难,网络的优化变得越来越难。理论上,越深的网络,效果应该更好;但实际上,由于训练难度,过深的网络会产生退化问题,效果反而不如相对较浅的网络(随着层数的增多,训练集上的效果变差,这被称为退化问题)
随着网络越来越深,当堆叠到一定网络深度时,就会出现梯度消失或梯度爆炸问题
所以不是不能用而是没必要用而且串联起来效果还不好
(20条消息) 图像识别-ResNet-18网络结构图示及解读_AI研习图书馆的博客-CSDN博客_resnet-18
(20条消息) 经典CNN网络:Resnet18网络结构输入和输出_呆呆珝的博客-CSDN博客_resnet18