点云3d检测SA-SSD
C. He, H. Zeng, J. Huang, X. -S. Hua and L. Zhang, “Structure Aware Single-Stage 3D Object Detection From Point Cloud,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11870-11879, doi: 10.1109/CVPR42600.2020.01189.
源码:https://github.com/skyhehe123/SA-SSD
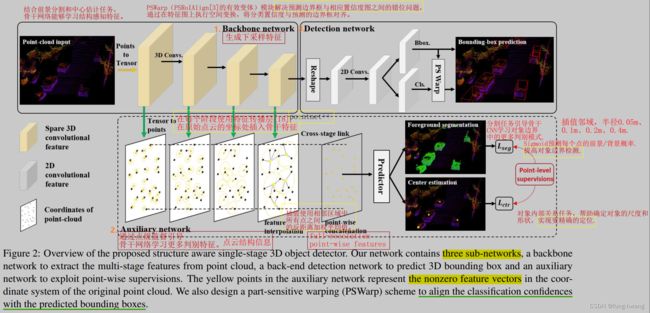
论文解读
创新点:辅助网络auxiliary net和检测头部分PS Warp(part-sensitive warping)
auxiliary net
点级监督辅助网络,引导骨干 CNN 不同阶段的中间特征学习点云细粒度结构特征。仅应用于训练阶段,不会额外增加推理成本。
○ 目的:协助 backbone提取的特征了解三维点云的结构信息。
○ 提出原因:backbone 从点云提取的下采样卷积特征丢失了结构细节,而这些细节对生成准确的对象定位至关重要。
-
前景分割
引导 backbone CNN 在对象边界学习更多的判别模式表示。特别地,利用 sigmoid 函数预测每个点前景/背景概率。focal loss 优化分割任务。从而更精确检测对象边界.然而,即使边界点被正确检测出,由于特征图的稀疏性,边界框的尺度和形状仍存在歧义。故而,为进一步提高定位精度,作者采用另一个辅助任务学习每个对象点相对对象中心的相对位置。
-
中心点预测
对象点和对象中心的相对位置关系。帮助尺度和形状确定,实现更精确的定位。
PSWarp
通过特征映射上的空间转换操作,解决预测边界框和置信度映射之间的非对齐,减少NMS后处理中预测边界框和相应置信度不一致问题。
mmdet
mmdetection是面向目标检测的代码集成库,也是一个工程性很强的开源框架,对调参和搭建网络都非常友好。SA-SSD代码是在mmdetection平台上开发。
mmdetection初认识:https://www.dazhuanlan.com/disen123/topics/1078289
github主页
编译mmdet某些库
points_op、 iou3d、pointnet2 编译C++/CUDA模块链接库points_op_cpu.so、iou3d_cuda.so、pointnet2_cuda.so:
python setup.py build_ext --inplace
遇见错误:
-
FAILED: /home/hf/program/SA-SSD-master/mmdet/ops/points_op/build/temp.linux-x86_64-3.7/src/points_op.o
-
/home/hf/program/SA-SSD-master/mmdet/ops/points_op/src/points_op.cpp:15:29: error: ‘AT_CHECK’ was not declared in this scope; did you mean ‘CHECK’?
参考方法:修改源文件points_op.cpp、interpolate.cpp、iou3d.cpp.
-
编译iou3d。Cuda version和GPU compute capability冲突。==》修改 cuda、torch 版本
-
编译pointnet2。
fatal error: THC/THC.h,error: ‘THCState’ does not name a type ==》注释对应语句
error: ‘getCurrentCUDAStream’ is not a member of ‘at::cuda’ ==》添加#include
数据准备
python tools/create_data.py
生成.pkl文件、gt_databse目录、velodyne_reduced目录。
数据解读
-
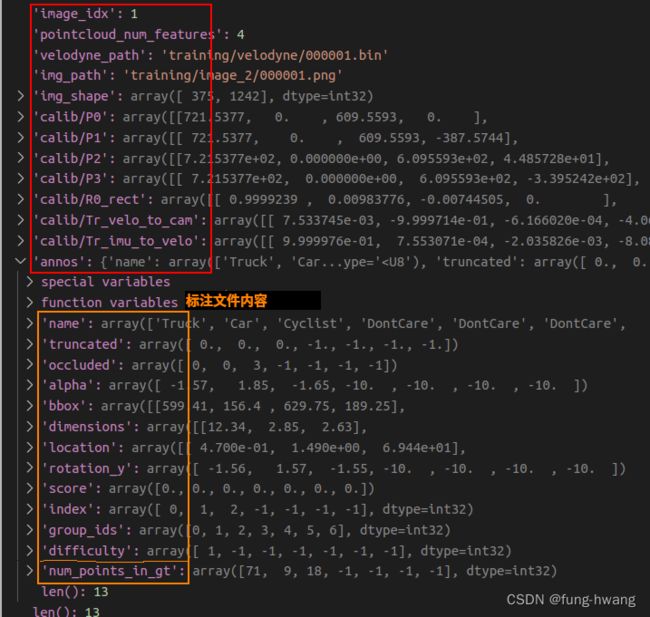
.pkl 文件
pickle.load()读取。list类型存放,每个元素以字典形式存放,内容如下:
-
image_2文件
mmcv.imread读取,颜色类型color格式、通道bgr,返回数据类型array。
transform:(mean, std)标准化,toRGB,size padding to [384, 1248] (32的倍数) -
label_2文件:
.txt 文件,open读取。每行内容如下:
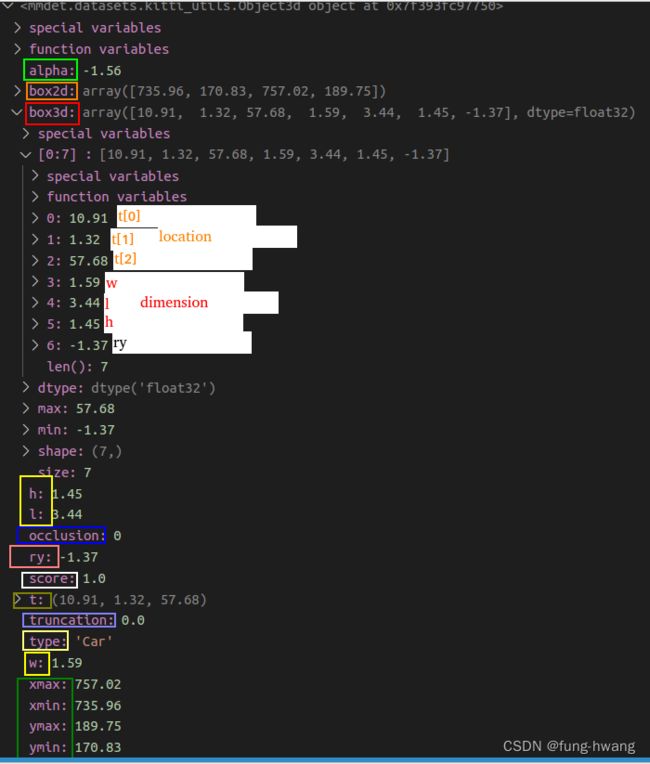
 mmdet.datasets.kitti_utils.Object3d 存取label,格式如下:
mmdet.datasets.kitti_utils.Object3d 存取label,格式如下:
-
calib文件:
mmdet.datasets.kitti_utils.Calibration处理:-
open 读取.txt文件,内容如下:

-
校准矩阵、相机参数
‘’’ Calibration matrices and utils
3d XYZ in label.txt are in rect camera coord.
2d box xy are in image2 coord
Points in lidar.bin are in Velodyne coord.
y_image2 = P^2_rect * x_rect
y_image2 = P^2_rect * R0_rect * Tr_velo_to_cam * x_velo
x_ref = Tr_velo_to_cam * x_velo
x_rect = R0_rect * x_ref
P^2_rect = [f^2_u, 0, c^2_u, -f^2_u b^2_x;
0, f^2_v, c^2_v, -f^2_v b^2_y;
0, 0, 1, 0]
= K * [1|t]
image2 coord:
----> x-axis (u)
|
|
v y-axis (v)
velodyne coord:
front x, left y, up z
rect/ref camera coord:
right x, down y, front z
Ref (KITTI paper): http://www.cvlibs.net/publications/Geiger2013IJRR.pdf
TODO(rqi): do matrix multiplication only once for each projection.
‘’’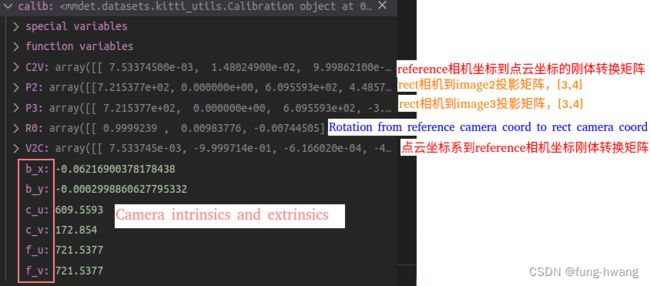
从P2获取rect camera coord到image_2 coord投影矩阵3X4
从P3获取rect camera coord到image_3 coord投影矩阵3X4
从Tr_velo_to_cam获取velodyne coord到 reference camera coord刚性变换3X4
从R0_rect获取reference camera coord到 rect camera coord旋转3X3
gt_bboxes:label文件获取的box3d, [x, y, z, w, l, h, ry]。前三项为相机坐标location,中间三项分别为3d bbox的width、length、height,最后一项为相机坐标系中绕Y轴的角度[-pi, pi]。
-
-
3d bbox,rect相机到点云坐标系转换
更新gt_bboxes[:,:3]:
rect相机坐标系转reference相机坐标系:pts_3d_rect @ np.linalg.inv(calib.R0).T
reference坐标系转点云坐标系:pts_3d_ref @ calib.C2V.T -
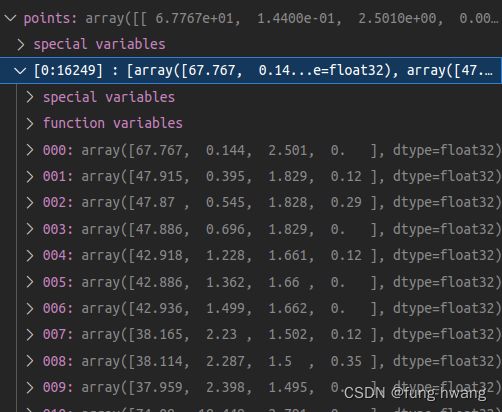
velodyne_reduced文件:
.bin文件,存储点云(正视图)。numpy加载文件,并reshape(-1, 4). 数据如下:
-
PointAugmentor
gt_database文件.bin 中读取box3d_lidar。训练集:
self.augmentor.noise_per_object_(gt_bboxes, points, num_try=100) # 随机噪声,gt_bboxes增强
gt_bboxes, points = self.augmentor.random_flip(gt_bboxes, points) # 点随机翻转
gt_bboxes, points = self.augmentor.global_rotation(gt_bboxes, points) # 点随机旋转
gt_bboxes, points = self.augmentor.global_scaling(gt_bboxes, points) # 点随机缩放
- Point2Voxel
点转体素。
voxels, coordinates, num_points = self.generator.generate(points)
训练数据元素:

训练train
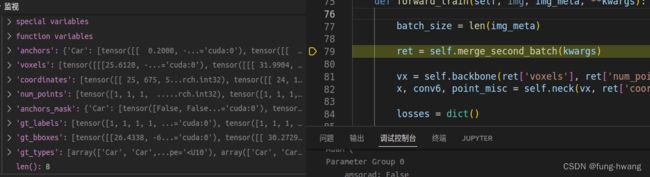
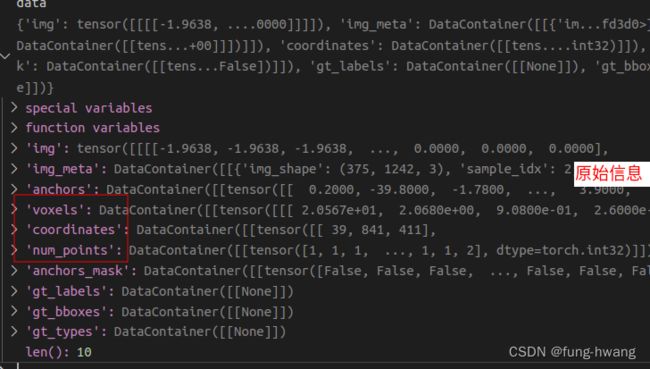
def forward_train(self, img, img_meta, **kwargs):
batch_size = len(img_meta)
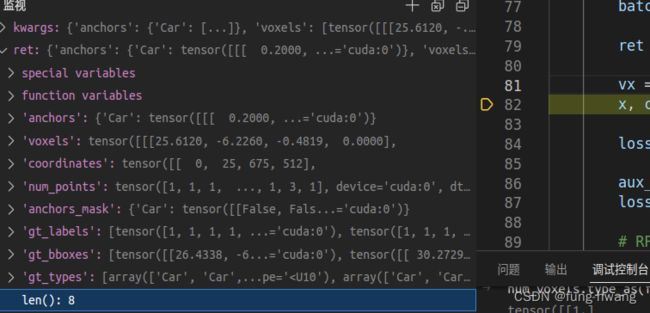
ret = self.merge_second_batch(kwargs)
vx = self.backbone(ret['voxels'], ret['num_points'])
x, conv6, point_misc = self.neck(vx, ret['coordinates'], batch_size, is_test=False)
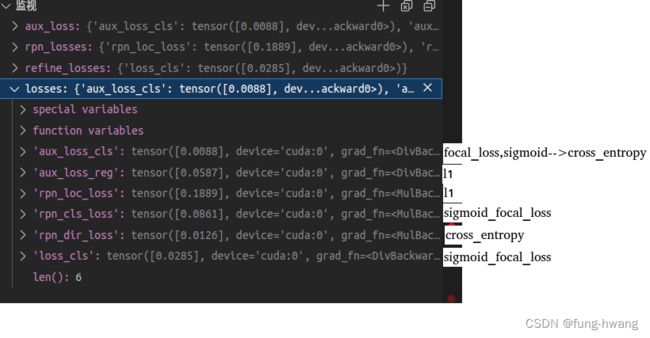
losses = dict()
aux_loss = self.neck.aux_loss(*point_misc, gt_bboxes=ret['gt_bboxes'])
losses.update(aux_loss)
# RPN forward and loss
if self.with_rpn:
rpn_outs = self.rpn_head(x)
rpn_loss_inputs = rpn_outs + (ret['gt_bboxes'], ret['gt_labels'], ret['gt_types'],\
ret['anchors'], ret['anchors_mask'], self.train_cfg.rpn)
rpn_losses = self.rpn_head.loss(*rpn_loss_inputs)
losses.update(rpn_losses)
guided_anchors, _ = self.rpn_head.get_guided_anchors(*rpn_outs, ret['anchors'],\
ret['anchors_mask'], ret['gt_bboxes'], ret['gt_labels'], thr=self.train_cfg.rpn.anchor_thr)
else:
raise NotImplementedError
# bbox head forward and loss
if self.extra_head:
bbox_score = self.extra_head(conv6, guided_anchors)
refine_loss_inputs = (bbox_score, ret['gt_bboxes'], ret['gt_labels'], guided_anchors, self.train_cfg.extra)
refine_losses = self.extra_head.loss(*refine_loss_inputs)
losses.update(refine_losses)
return losses
输入数据kwargs:
 批次单个数据合并批数据ret:
批次单个数据合并批数据ret:
backbone
处理体素数据ret[‘voxels’],size:[n, 5, 4],调用SimpleVoxel简化体素,返回points_mean,size:[n,4]。sum+mean:
points_mean = features[:, :, :self.num_input_features].sum(dim=1, keepdim=False)
/ num_voxels.type_as(features).view(-1, 1)
neck
处理backbone体素(均值)、坐标点,调用SpMiddleFHD。
其中主干网络为VxNet,体素特征维度变化:[70142, 4]–>[70142, 16]–>[106542,32]–>[63797,64]–>[27599,64],提取深层特征out、和中间层多尺度特征middle(3种尺度);
全卷积网络部分采用BEVNet(8个conv2d+bn+relu)处理深层特征out,其维度变化为:[4, 320, 200, 176]–>[4, 256, 200, 176],返回处理后特征x、和第7层特征conv6。
辅助网络:依次处理中间多尺度层middle,并返回每个尺度在backbone体素上的特征 p 0 p_0 p0、 p 1 p_1 p1、 p 2 p_2 p2。
其大小如下:
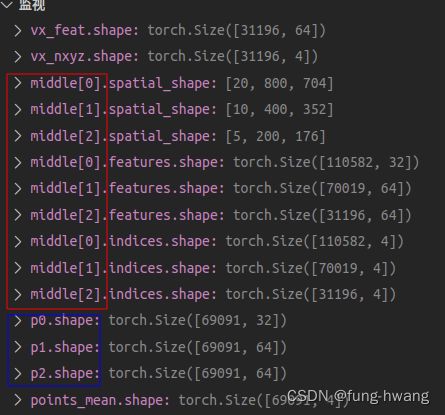
- tensor2points 结合offset和voxel_size分别处理中间层多尺度特征middle[i]的坐标,返回特征vx_feat和坐标vx_nxyz.
def tensor2points(tensor, offset=(0., -40., -3.), voxel_size=(.05, .05, .1)):
indices = tensor.indices.float()
offset = torch.Tensor(offset).to(indices.device)
voxel_size = torch.Tensor(voxel_size).to(indices.device)
indices[:, 1:] = indices[:, [3, 2, 1]] * voxel_size + offset + .5 * voxel_size
return tensor.features, indices
- nearest_neighbor_interpolate 处理backbone简化的体素points_mean(unknown)和上一步的vx_nxyz(known)、vx_feat(known_feats),返回输入体素3邻域的特征p。
def nearest_neighbor_interpolate(unknown, known, known_feats):
"""
:param pts: (n, 4) tensor of the bxyz positions of the unknown features
:param ctr: (m, 4) tensor of the bxyz positions of the known features
:param ctr_feats: (m, C) tensor of features to be propigated
:return:
new_features: (n, C) tensor of the features of the unknown features
"""
dist, idx = pointnet2_utils.three_nn(unknown, known) # find the three nearest neighbors of unknown in known,compute l2-distance, and return idx
dist_recip = 1.0 / (dist + 1e-8)
norm = torch.sum(dist_recip, dim=1, keepdim=True) # [n,3], do sum(col), return [n,1]
weight = dist_recip / norm
interpolated_feats = pointnet2_utils.three_interpolate(known_feats, idx, weight) # [unknown.shape[0], known_feats.shape[1]]
return interpolated_feats
- Linear(in_features=160, out_features=64, bias=False)全连接点云体素3邻域多尺度特征torch.cat([p0, p1, p2], dim=-1),返回pointwise
- Linear(in_features=64, out_features=1, bias=False)分类,返回point_cls
- Linear(in_features=64, out_features=3, bias=False)回归,返回point_reg
neck 部分返回:x, conv6, point_misc。分别表示BEVNet深层特征x和第7层卷积特征conv6,(points_mean, point_cls, point_reg).
loss
gt_bboxes: (M, 7) , [x, y, z, h, w, l, ry]。从label_2文件获取,依次表示相机坐标(x, y, z),目标维度(h, w, l),目标在相机坐标系中绕Y轴角度ry。
测试test
1. data
VoxelGenerator:
point_cloud_range:x:[0, 70.4],y:[-40, 40],z:[-3, 1] .
voxel_size:[0.05, 0.05, 0.1].
grid_size:[1408.0, 1600.0, 40.0]
grid_size = (point_cloud_range[3:] - point_cloud_range[:3]) / voxel_size
image–transform:
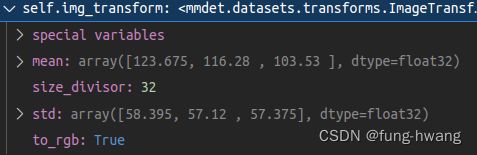
scale=1,不翻转,padding to [384, 1248]
点云points_to_voxel:
def points_to_voxel(points,voxel_size,coors_range,
max_points=35,
reverse_index=True,
max_voxels=20000):
"""convert kitti points(N, >=3) to voxels. This version calculate
everything in one loop. now it takes only 4.2ms(complete point cloud)
with jit and 3.2ghz cpu.(don't calculate other features)
Note: this function in ubuntu seems faster than windows 10.
Args:
points: [N, ndim] float tensor. points[:, :3] contain xyz points and
points[:, 3:] contain other information such as reflectivity.
voxel_size: [3] list/tuple or array, float. xyz, indicate voxel size
coors_range: [6] list/tuple or array, float. indicate voxel range.
format: xyzxyz, minmax
max_points: int. indicate maximum points contained in a voxel.
reverse_index: boolean. indicate whether return reversed coordinates.
if points has xyz format and reverse_index is True, output
coordinates will be zyx format, but points in features always
xyz format.
max_voxels: int. indicate maximum voxels this function create.
for second, 20000 is a good choice. you should shuffle points
before call this function because max_voxels may drop some points.
Returns:
voxels: [M, max_points, ndim] float tensor. only contain points.
coordinates: [M, 3] int32 tensor.
num_points_per_voxel: [M] int32 tensor.
"""
if not isinstance(voxel_size, np.ndarray):
voxel_size = np.array(voxel_size, dtype=points.dtype)
if not isinstance(coors_range, np.ndarray):
coors_range = np.array(coors_range, dtype=points.dtype)
voxelmap_shape = (coors_range[3:] - coors_range[:3]) / voxel_size
voxelmap_shape = tuple(np.round(voxelmap_shape).astype(np.int32).tolist())
if reverse_index:
voxelmap_shape = voxelmap_shape[::-1]
# don't create large array in jit(nopython=True) code.
num_points_per_voxel = np.zeros(shape=(max_voxels, ), dtype=np.int32)
coor_to_voxelidx = -np.ones(shape=voxelmap_shape, dtype=np.int32)
voxels = np.zeros(
shape=(max_voxels, max_points, points.shape[-1]), dtype=points.dtype)
coors = np.zeros(shape=(max_voxels, 3), dtype=np.int32)
if reverse_index:
voxel_num = _points_to_voxel_reverse_kernel(
points, voxel_size, coors_range, num_points_per_voxel,
coor_to_voxelidx, voxels, coors, max_points, max_voxels)
else:
voxel_num = _points_to_voxel_kernel(
points, voxel_size, coors_range, num_points_per_voxel,
coor_to_voxelidx, voxels, coors, max_points, max_voxels)
coors = coors[:voxel_num]
voxels = voxels[:voxel_num]
num_points_per_voxel = num_points_per_voxel[:voxel_num]
return voxels, coors, num_points_per_voxel
2. model预测

dimensions ---- 3d目标的长宽高
location ---- 3d框中心点位置
rotation_y ---- 3d框yaw角度
boxes3d转bev_boxes:
def boxes3d_to_bev_torch(boxes3d):
"""
:param boxes3d: (N, 7) [x, y, z, h, w, l, ry]
:return:
boxes_bev: (N, 5) [x1, y1, x2, y2, ry]
"""
boxes_bev = boxes3d.new(torch.Size((boxes3d.shape[0], 5)))
cu, cv = boxes3d[:, 0], boxes3d[:, 1] # x,y
half_l, half_w = boxes3d[:, 3] / 2, boxes3d[:, 4] / 2 # h/2, w/2
boxes_bev[:, 0], boxes_bev[:, 1] = cu - half_l, cv - half_w
boxes_bev[:, 2], boxes_bev[:, 3] = cu + half_l, cv + half_w
boxes_bev[:, 4] = boxes3d[:, 6]
return boxes_bev
- 部分模块解析
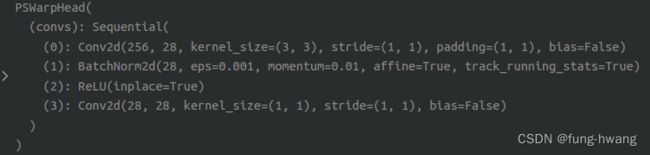
- 测试github提供的预训练模型【epoch_50.pth】,更改模型加载权参代码,其检测结果依然为none。????
def load_params_from_file(model, filename, to_cpu=False):
if not os.path.isfile(filename):
raise FileNotFoundError
print('==> Loading parameters from checkpoint %s to %s' % (filename, 'CPU' if to_cpu else 'GPU'))
loc_type = torch.device('cpu') if to_cpu else None
checkpoint = torch.load(filename, map_location=loc_type)
model_state_disk = checkpoint['state_dict'] # model_state state_dict
if 'version' in checkpoint:
print('==> Checkpoint trained from version: %s' % checkpoint['version'])
update_model_state = {}
for key, val in model_state_disk.items():
# changed key for pretrained model. @2022.8.2
new_key = 'module.' + key
if new_key in model.state_dict() and model.state_dict()[new_key].shape == model_state_disk[key].shape:
update_model_state[new_key] = val
elif new_key in model.state_dict() and model.state_dict()[new_key].shape != val.shape:
# with different spconv versions, we need to adapt weight shapes for spconv blocks.
# adapt spconv weights from version 1.x to version 2.x if you used weights from spconv 1.x
val_native = val.transpose(-1, -2) # (k1, k2, k3, c_in, c_out) to (k1, k2, k3, c_out, c_in)
if val_native.shape == model.state_dict()[new_key].shape:
val = val_native.contiguous()
else:
assert val.shape.__len__() == 5, 'currently only spconv 3D is supported'
val_implicit = val.permute(4, 0, 1, 2, 3) # (k1, k2, k3, c_in, c_out) to (c_out, k1, k2, k3, c_in)
if val_implicit.shape == model.state_dict()[new_key].shape:
val = val_implicit.contiguous()
update_model_state[new_key] = val
if key in model.state_dict() and model.state_dict()[key].shape == model_state_disk[key].shape:
update_model_state[key] = val
# logger.info('Update weight %s: %s' % (key, str(val.shape)))
update_model_state['module.neck.point_fc.weight'] = model_state_disk['neck.backbone.point_fc.weight'] # [email protected]
update_model_state['module.neck.point_cls.weight'] = model_state_disk['neck.backbone.point_cls.weight'] # [email protected]
update_model_state['module.neck.point_reg.weight'] = model_state_disk['neck.backbone.point_reg.weight'] # [email protected]
state_dict = model.state_dict()
state_dict.update(update_model_state)
model.load_state_dict(state_dict)
for key in state_dict:
if key not in update_model_state:
print('Not updated weight %s: %s' % (key, str(state_dict[key].shape)))
print('==> Done (loaded %d/%d)' % (len(update_model_state), len(model.state_dict())))
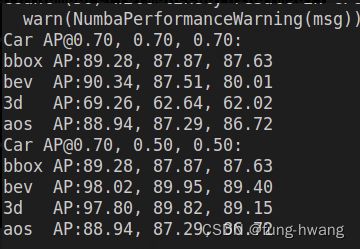
3. 评估
PR曲线定性分析,AP定量分析。从AP_bbox2d、AP_bev、AP_3d、AOS(平均方向相似度–检测目标旋转角度准确率,衡量检测结果与GT方向相似性)