safety-gym环境搭建
Anaconda 安装
1、去官网下载exe,安装,完成
2、设置环境变量: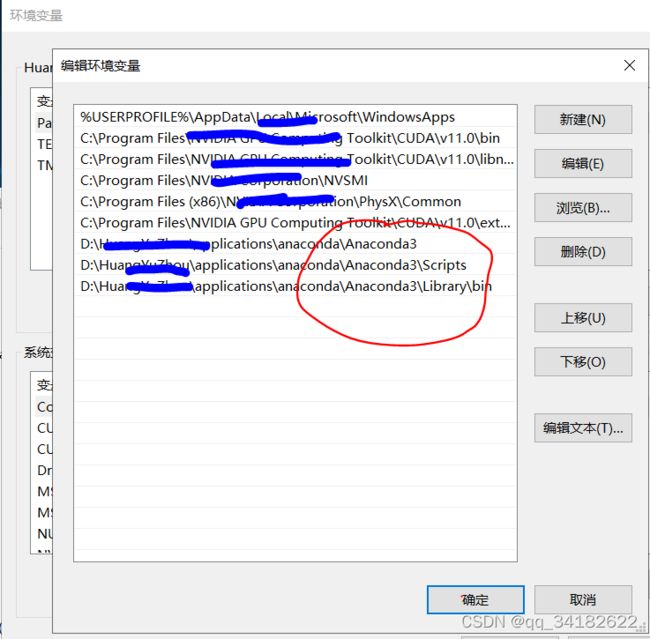
3、测试conda:


4、测试conda自带的python:

可以看到有python,上图还说,该python是一个conda环境的解释器,需要激活该环境才能完全使用所有的库,接着看官网:
![]()
可以看出,其实说的就是base环境;
5、激活base环境:

激活成功;
开启(激活)和关闭环境:

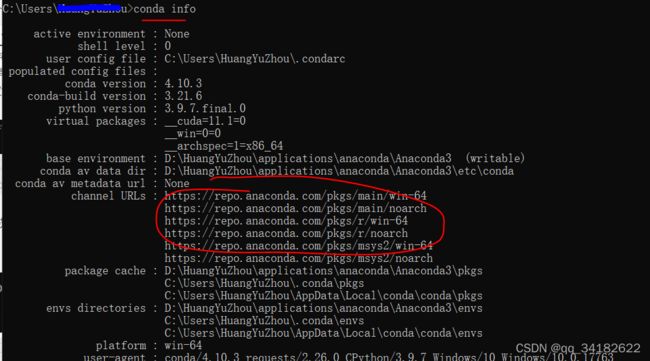
6、查看anaconda安装其他包的镜像源以及修改镜像源:
强烈建议使用阿里云,不要使用学校的镜像
参考链接:阿里anaconda镜像源
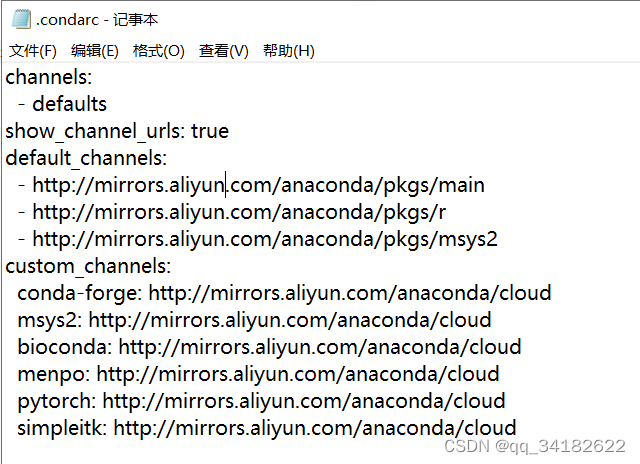
更换源:
Windows 用户无法直接创建名为 .condarc 的文件,可先执行 conda config --set show_channel_urls yes 生成该文件之后再修改。
编辑生成的.condarc文件:
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.aliyun.com/anaconda/pkgs/main
- http://mirrors.aliyun.com/anaconda/pkgs/r
- http://mirrors.aliyun.com/anaconda/pkgs/msys2
custom_channels:
conda-forge: http://mirrors.aliyun.com/anaconda/cloud
msys2: http://mirrors.aliyun.com/anaconda/cloud
bioconda: http://mirrors.aliyun.com/anaconda/cloud
menpo: http://mirrors.aliyun.com/anaconda/cloud
pytorch: http://mirrors.aliyun.com/anaconda/cloud
simpleitk: http://mirrors.aliyun.com/anaconda/cloud
也可以在命令行手动配置:
conda config --add channels 链接 #添加源
conda config --remove channels 链接 #删掉源
conda config --remove-key channels #还原默认源
注意:手动配还需要先删掉所有默认源
查看结果:

7、创建一个自己的conda环境,这里我命名为safetygym37:
conda create -n safetygym37 python=3.7 #创建环境
conda activate safetygym37 #激活环境

简单输入几条命令:
python
conda list

8、至此,我们conda环境就创建好了,可以安装相应的包了。
创建PyCharm项目,使用新建的环境:
1、创建项目,使用已存在的interpreter:

2、选择我们创建的conda环境的python.exe,且conda使用我们下载的conda.exe:

3、选择好正确的interpreter,创建项目:

4、完成:

安装Gym环境
1、我由于实验需求,安装的是gym==0.15.3:
pip install gym==0.15.3
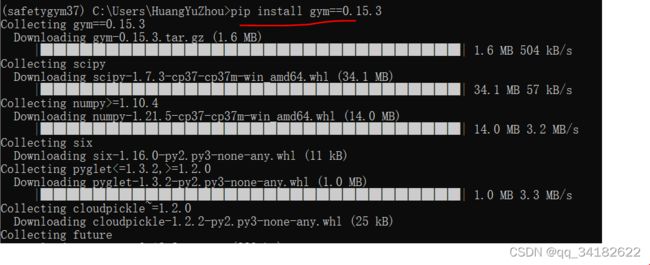
这里我是很完美地安装好了gym;
2、运行一个简单的gym环境:
import gym
env = gym.make("CartPole-v1")
observation = env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample() # your agent here (this takes random actions)
observation, reward, done, info = env.step(action)
if done:
observation = env.reset()
env.close()
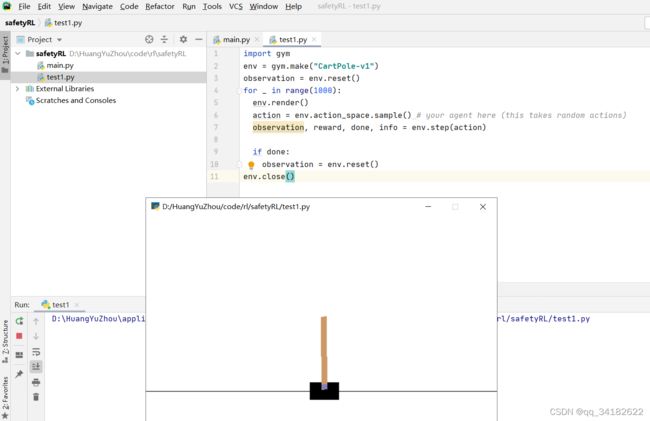
完美运行。
tensorflow-gpu安装
传统的安装方法如下1-4点,我建议对照着这个链接,我写的内容主要是流程,细节的就看这个blog;
1、首先确定好要安装的tensorflow版本,选择合适的cuda版本
版本对应
通过上面的链接可以了解到你需要安装cuda版本;
这里就要问,我们安装这些是为了啥?这就要搞清楚一些事情:
(1)cuda和cudnn是啥
简单说,cuda是nvidia显卡的并行计算框架;cudnn是深度神经网络 加速库;所以要使用gpu,就需要安装好这两个;
(2)查看cuda和cudnn版本
这个链接说的是有点问题的,他没有搞清楚什么是runtime-cuda什么是driver-cuda,将两者混为一谈了;runtime-cuda其实就是我们官网安装的cuda,是通过nvcc命令查看版本信息;dirver-cuda则是显卡驱动带有的cuda,通过nvidia-smi命令查看信息;具体内容看如下链接:
nvcc和nvidia-smi区别
完整版相关信息
(3)显卡驱动更新:
在安装cuda前,先查看gpu型号,然后需要先更新好驱动;
2、安装cuda:
去官网下载cuda并安装即可;然后需要配置cuda的环境变量;
3、安装cudnn:
需要注册,然后查看旧版本的cudnn;

可以看到,cuda对应了多个cudnn版本,所以根据cuda版本选择就好;
总的流程就是:tensorflow版本->cuda版本->cudnn版本
下载了cudnn后是需要复制文件到cuda里面的;
4、安装tensorfow:
pip install tensorflow_gpu==1.13.1
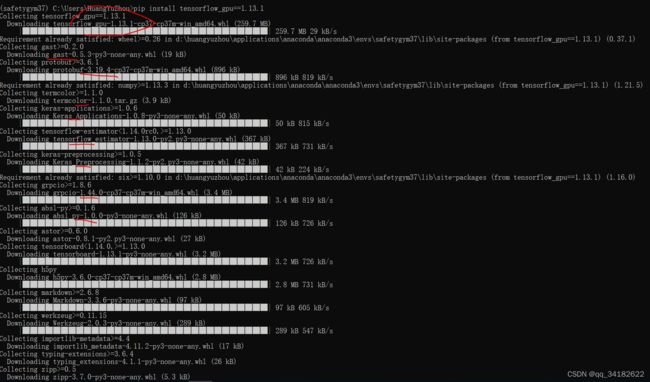
安装完成。
注意:我这里通过pip安装tensorflow,安装的东西仅和tensorflow有关,如果通过conda安装,它会自行下载自己的cuda等;
这里我们查看一下安装了的包:
pip list
conda list


5、简单使用tensorflow:
import tensorflow as tf
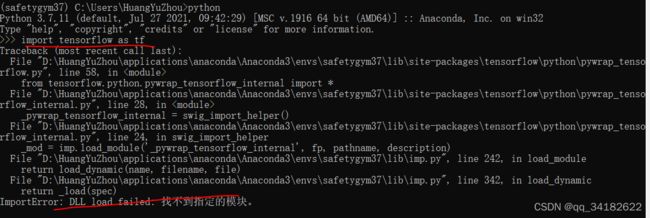
我这里出了问题,找不到模块;看了下这个链接,发现很可能就是cuda问题,我实验的这台机子系统变量的path覆盖了我的用户变量的path,导致系统变量path指向的cuda v11.0代替了我自己的cuda v10.0,然后就如上面看到的那样。
为了验证这个说法,我把上面的tensorflow-gpu卸载了,安装了同版本的tensorflow,即cpu版本,然后再import,结果能运行;运行如下代码(随便找的):
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 生成200个随机点以及噪音
x_data = np.linspace(-0.5, 0.5, 200)[:, np.newaxis]
noise = np.random.normal(0, 0.02, x_data.shape)
y_data = np.square(x_data) + noise
x = tf.placeholder(tf.float32, [None, 1])
y = tf.placeholder(tf.float32, [None, 1])
# 定义神经网络中间层
Weights_L1 = tf.Variable(tf.random.normal([1, 10]))
biases_L1 = tf.Variable(tf.zeros([1, 10]))
Wx_plus_b_L1 = tf.matmul(x, Weights_L1) + biases_L1
L1 = tf.nn.tanh(Wx_plus_b_L1)
# 输出层
Weights_L2 = tf.Variable(tf.random_normal([10, 1]))
biases_L2 = tf.Variable(tf.zeros([1, 1]))
Wx_plus_b_L2 = tf.matmul(L1, Weights_L2) + biases_L2
prediction = tf.nn.tanh(Wx_plus_b_L2)
# 二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
# 梯度下降算法
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(2000):
sess.run(train_step, feed_dict={x: x_data, y: y_data})
prediction_value = sess.run(prediction, feed_dict={x: x_data})
plt.figure()
plt.scatter(x_data, y_data)
plt.plot(x_data, prediction_value, "r-", lw=5)
plt.show()

能行,嘿嘿,至于其他的warning等,那就另外解决,按道理是可以运行的。
6、解决系统path的cuda覆盖用户path的cuda的问题:
看了这个链接,我陷入了沉思,心里马了无数次傻逼管理员给系统变量path加了个cuda路径,简直是乱设置。
看了这篇博客后,我发现可以通过conda来安装tensorflow,然后它自身会安装特定版本的cuda,优先级肯定比系统变量高。于是乎,前面讲的下载cuda、cudnn都作废了,别打我,我也没办法;
pip uninstall tensorflow
conda install tensorflow-gpu==1.13.1

如上图红线部分,就是conda安装tensorflow-gpu自带帮我们装的,版本绝对是和tensorflow版本对应的;
然后就安装成功了,美滋滋,现在开始测试:
import tensorflow as tf
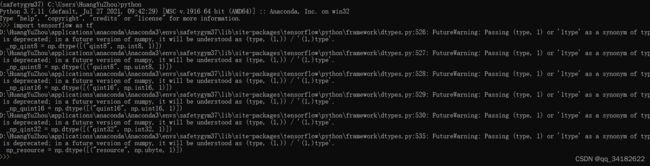
可以看到有些warning,其实是因为numpy版本太高了>=1.7,tensorflow1.13.1使用的应该是小于这个版本,但问题不大,最好不要降numpy,我将了,然后出现error。。。
我们再次运行一下上面的示例代码:

看似不妙,又出了问题,看了这个博客后,发现需要改一下代码:
#把session的声明改为:
gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))

完美,还有gpu的使用信息呢!
安装mujoco 200
参考这篇博客
1、去这个网站下载mujoco200 win64以及mjkey.txt,前者解压,并将里面那个文件夹名改为mujoco200;
2、在用户文件夹创建.mujoco文件夹,将mujoco200拖入其中,并将mjkey.txt复制到.mujoco文件夹里以及.mujoco/mujoco200/bin里面;
3、测试一下mujoco安装成功没:
cd ~/.mujoco/mjpro200/bin
./simulate ../model/humanoid.xml

很完美是不是!
4、安装mujoco_py:
先设置好环境变量:.mujoco/mujoco200和.mujoco/mujoco200/bin;
然后执行命令:
pip install mujoco_py==2.0.2.8
安装成功!
注意:安装mujoco_py==2.0.2.7会出现如下错误:
ERROR: Failed building wheel for mujoco-py Failed to build mujoco-py ERROR: Could not build wheels for mujoco-py which use PEP 517 and cannot be installed directly
别人给的解决方法就是换版本
5、尝试运行:
import mujoco_py

!!!???兄弟们,你们那边的楼高吗?我想一跃解千愁。。
解决这个的方法,就是我得重新创建环境,指定在其他地方,尽量是的该虚拟环境路径短一些,从而不出现这样的error;这总比重装anaconda好,唉。
现在唯一还能让我开心点的,就是这篇博客了,好在我边配环境边记录,原来blog这么有用。!
6、重新创建一个新的环境:
参考这篇blog
conda create --prefix=D:\HuangYuZhou\envs\srl37 python=3.7
然后就把前面的步骤走了一遍,由于我走过一次,下载的东西都有缓存到anaconda里,所以这次特别快,然后就进行mujoco_py测试:
import mujoco_py
import os
mj_path, _ = mujoco_py.utils.discover_mujoco()
xml_path = os.path.join(mj_path, 'model', 'humanoid.xml')
model = mujoco_py.load_model_from_path(xml_path)
sim = mujoco_py.MjSim(model)
print(sim.data.qpos)
sim.step()
print(sim.data.qpos)
上图:

安装safety gym:
1、首先进入官网,按照readme的步骤将仓库clone到本地,进入本地仓库,打开命令行并激活自己的conda环境;
2、开始安装:
pip install -e .
这里我遇到了问题,就是numpy原来的版本删除不了,什么“拒绝访问”啥的,于是我直接跑到我的环境的site-package中把numpy的文件删掉了,然后重新执行上面的命令,然后就可以了,嘿嘿。
3、开始测试:
import safety_gym
import gym
env = gym.make('Safexp-PointGoal1-v0')
一开始运行报了下面的错误:
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
查了百度说是numpy版本太低,于是我就:
pip install --upgrade numpy
升回了1.21.5版本,但有报如下信息:
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
safety-gym 0.0.0 requires numpy~=1.17.4, but you have numpy 1.21.5 which is incompatible.
其实吧,safety gym是别人扩展gym的,它的setup.py说是需要numpy==1.17.4,但我觉得使用更高版本的应该也是可以的,要去到上面的错误,可以直接手动改setup.py版本设置。
然后我再运行测试代码,这次又报了一个错误:

看到就是2*32超过了int的范围了,于是我去改了源码:
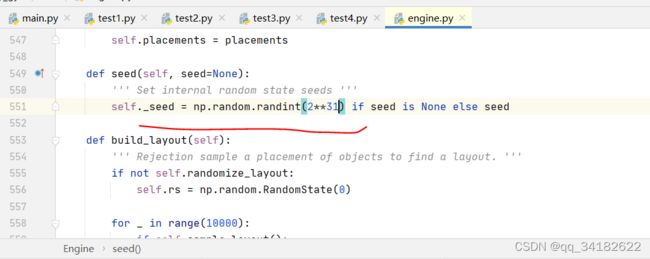
将32改为31,然后运行就正常了。