Jetson嵌入式系列模型部署-2
目录
-
-
- 前言
- 1. 源码下载
- 2. 环境配置
-
- 2.1 Jtop(option)
-
- 2.1.1 配置pip
- 2.1.2 安装jtop
- 2.1.3 使用jtop
- 2.2 源码配置说明
- 3. 运行
-
- 3.1 .pt转.wts
- 3.2 build
- 3.3 run
- 4. 结语
- 5. 下载链接
- 6. 参考
-
前言
给大家安利的第一个仓库是tensorrtx。该仓库通过
TensorRT的Layer API完成模型的构建工作,自定义权重加载并通过TensorRT序列化生成engine文件,完成高性能推理工作。对模型部署有疑问的可参考上篇文章Jetson嵌入式系列模型部署-1。本文主要是针对tensorrtx项目中的yolov5完成嵌入式模型部署,本文参考自tensorrtx的README.md,具体操作流程作者描述非常详细,这里再简单过一遍,本次训练的模型使用的是yolov5s-6.0,类别数为2,为口罩识别。
1. 源码下载
使用如下指令
$ git clone https://github.com/wang-xinyu/tensorrtx.git
注:不同版本的yolov5使用不同版本的tensorrtx,具体参考here
删除多余的文件,只保留yolov5文件夹
2. 环境配置
需要使用的软件环境有
TensorRT、CUDA、CUDNN、OpenCV。所有软件环境在JetPack镜像中已经安装完成。博主使用的jetpack版本为JetPack4.6.1(PS:关于jetson nano刷机就不再赘述了,需要各位看官自行配置好相关环境,外网访问较慢,这里提供JetPack镜像下载链接Baidu Drive[password:nano]【更新完毕!!!】(PS:提供4.6和4.6.1两个版本,注意4GB和2GB的区别,不要刷错了),关于Jetson Nano 2GB和4GB的区别可参考Jetson NANO是什么?如何选?。(吐槽下这玩意上传忒慢了,超级会员不顶用呀,终于上传完了,折磨!!!)
2.1 Jtop(option)
可使用如下指令查看自己的JetPack版本简单信息
$ cat /etc/nv_tegra_release
使用Jtop可查看JetPack详细信息。Jtop是一个由第三方开发,用于显示Jetson开发板信息的包,可以查询当前板子CPU,GPU使用率,实时功耗,Jetpack软件包信息等,参考自Jetson nano安装jtop,Jetson nano安装pip并换源
2.1.1 配置pip
$ sudo apt install python-pip python3-pip
$ pip3 install --upgrade pip
$ pip install --upgrade pip
pip换源,指令如下
$ sudo mkdir .pip && cd .pip
$ sudo touch pip.conf
$ sudo vim pip.conf
添加如下内容
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
2.1.2 安装jtop
$ sudo pip3 install -U jetson-stats
2.1.3 使用jtop
$ sudo jtop
The jetson_stats.service is not active. Please run:
sudo systemctl restart jetson_stats.service
需要启动相关服务,指令如下
$ sudo systemctl restart jetson_stats.service
$ jtop
博主Jtop显示的jetson nano软件包信息页面如下
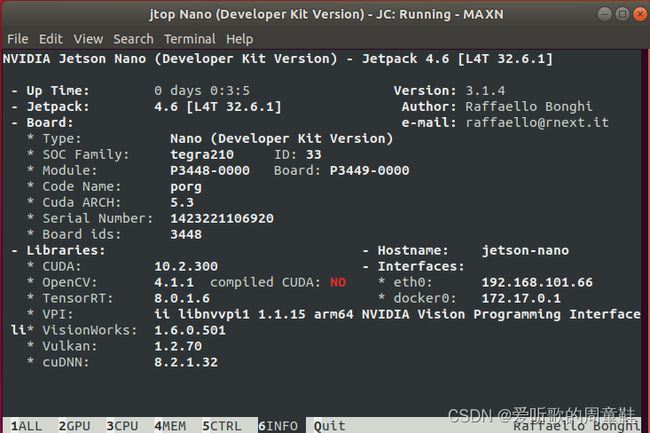
2.2 源码配置说明
-
在命令行参数选择模型
n/s/m/l/x/n6/ns/s6/m6/l6/x6 -
输入尺寸的定义在
yololayer.h -
类别数的定义在
yololayer.h中,如果是自定义模型,不要忘记修改 -
INT8/FP16/FP32可以通过yolov5.cpp中的宏进行选择 -
GPU ID可以通过yolov5.cpp中的宏指定 -
NMS阈值的设置在
yolov5.cpp中 -
BBox置信度阈值的设置在
yolov5.cpp中 -
Batch size的设置在
yolov5.cpp中
3. 运行
3.1 .pt转.wts
tensorrtx项目通过tensorRT的Layer API一层层搭建模型,模型权重的加载则通过自定义方式实现,通过get_wts.py文件将yolov5模型的权重即yolov5.pt保存成yolov5.wts,生成的yolov5.wts文件即作者自定义的权重文件方便后续加载使用。给出相关权重文件的下载链接地址Baidu Drive[password:yolo]
权重的生成在本地完成即可,将转换生成的yolov5.wts文件拷贝回到yolov5文件夹下
yolov5s.wts文件生成指令如下:
$ python gen_wts.py -w weights/yolov5s.pt yolov5s.wts
错误如下:
Traceback (most recent call last):
File "gen_wts.py", line 6, in <module>
from utils.torch_utils import select_device
ModuleNotFoundError: No module named 'utils.torch_utils'
解决方案如下:
get_wts.py文件依赖于yolov5官方源码,需要下载yolov5官方源码并进行如下操作
$ git clone -b v6.0 https://github.com/ultralytics/yolov5.git // 下载yolov5-6.0源码
$ cp tensorrtx/yolov5/gen_wts.py yolov5-6.0 // 将get_wts.py文件和权重文件拷贝到yolov5源码中
$ python gen_wts.py -w yolov5s.pt -o yolov5s.wts // 生成wts文件
生成的wts权重文件部分内容如下图所示
.wts文件为纯文本文件350为模型所有键对应的数目即表示它有多少行(不包括自身)- 每一行形式是 [权重名称] [value count = N] [value1] [value2] … [valueN]
model.0.conv.weight为模型权重保存的第一个键的名称3456为模型权重保存的第一个键对应值的总长度- 后面的数字为模型权重保存的第一个键对应的值,以十六进制的形式进行保存
3.2 build
加载yolov5s.wts权重文件,并通过tensorRT序列化生成engine引擎文件。注意先修改下yololayer.h中的CLASS_NUM,修改为自训练模型的类别数。如下图所示,本次训练的模型类别数为1,故将CLASS_NUM修改为1。
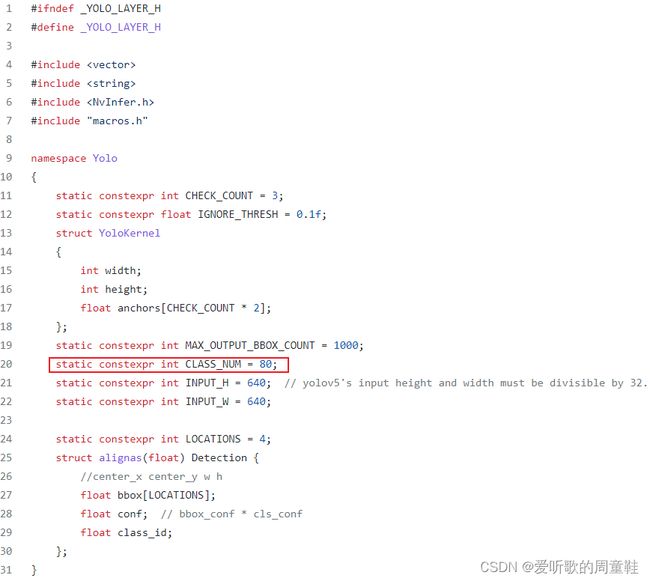
修改完成后便可进行编译生成引擎文件,指令如下
$ cd tensorrtx/yolov5
$ mkdir build && cd build
$ cp ../yolov5s.wts ./
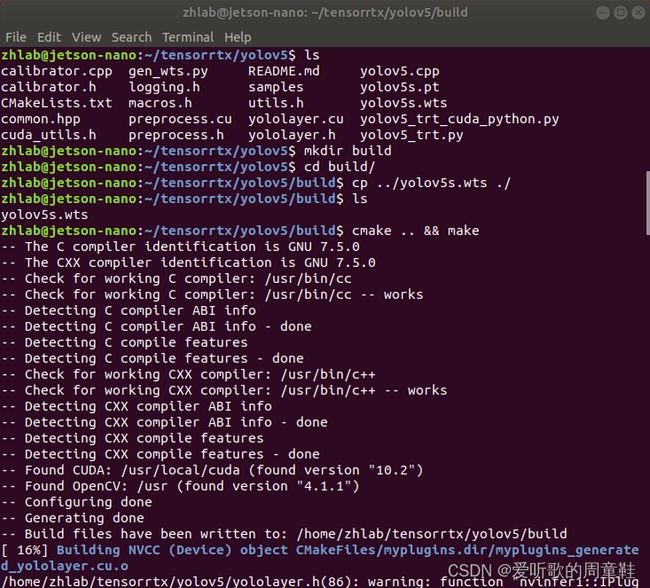
$ cmake .. && make
$ sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
图解如下所示,执行完成之后会在build目录下生成yolov5s.engine引擎文件

3.3 run
通过tensorRT生成的engine文件进行模型推理,指令如下
$ sudo ./yolov5 -d yolov5s.engine ../images/
执行完成后会在build目录下生成推理完成后的图片,图解如下

检测的图片效果如下图所示
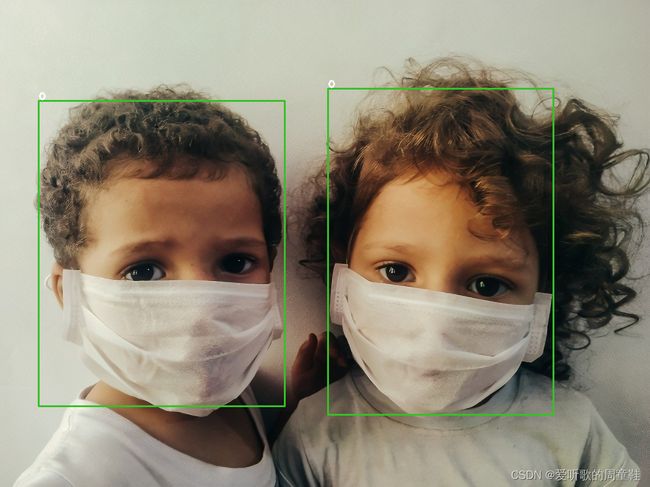

注:关于调用相关摄像头检测可以参考here自行修改
4. 结语
本篇博客只是一个引子,带大家认识到这个项目,并做了最基础的演示,其他模型的部署工作需要各位看官自己去挖掘啦。如果想简单了解下tensorRT部署知识可参考上篇文章Jetson嵌入式系列模型部署-1,下篇文章将会介绍另一个项目即tensorRT_Pro,该项目通过
TensorRT的ONNX parser解析ONNX文件完成模型的构建工作,可参考下篇文章Jetson嵌入式系列模型部署-3。敬请期待!!!
5. 下载链接
- 源码下载链接Baidu Drive[password:yolo],若有改动请参考最新
- 只保留了
yolov5文件夹 yolov5/yololayer.h中的CLASS_NUM已经修改为2(PS:本次模型为口罩识别,仅两个类别)yolov5/images存放着需要推理的图片
- 只保留了
- 权重文件下载链接Baidu Drive[password:yolo]
- weights文件夹下共包含
yolov5s.pt yolov5s.wts两个文件 yolov5s.pt是使用yolov5s-6.0训练的口罩识别模型,共两个个类别yolov5s.wts是通过get_wts.py生成的作者自定义的权重文件,具体生成过程请参考上面
- weights文件夹下共包含
- JetPack镜像下载链接Baidu Drive[password:nano]【更新完毕!!!】,上传忒慢
6. 参考
- tensorrtx
- tensorrtx/yolov5的README.md
- Jetson嵌入式系列模型部署-1
- Jetson嵌入式系列模型部署-3
- Jetson NANO是什么?如何选?
- Jetson nano安装jtop
- Jetson nano安装pip并换源
- Jetson nano+yolov5+TensorRT加速+调用usb摄像头
感谢各位看到最后,若有帮助请帮忙点个