CIFAR-100数据集 卷积神经网络训练
目录
1. CIFAR-10数据集介绍
2. 问题说明
3. 模型训练过程
4. 结果可视化
1. CIFAR-100数据集介绍
这个数据集就像CIFAR-10,除了它有100个类,每个类包含600个图像。,每类各有500个训练图像和100个测试图像。CIFAR-100中的100个类被分成20个超类。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)以下是CIFAR-100中的类别列表:
 Cifar10
Cifar10
| Superclass | Classes |
|---|---|
| aquatic | mammals beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food | containers bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television |
| household | furniture bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
CIFAR-100标签
参考
2. 问题说明
- 自由选择算法完成 cifar-100 数据集解析分类
- 要求准确率至少大于60%
3. 模型训练过程
1.初步准备
采用ResNet模型

两种残差网络块定义
'''
不带瓶颈段的残差块
'''
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.network = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, stride=1),
nn.MaxPool2d(3, stride=1, padding=1)
)
self.downSample = nn.Sequential()
if in_channels != out_channels:
self.downSample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.network(x) + self.downSample(x)
return out'''
带瓶颈段的残差块
in channel = [inChannel1,inChannel2,inChannel3]
in channel = [outChannel1,outChannel2,outChannel3]
stride = 1 长宽不变
stride = 2 长宽减半
'''
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(BasicBlock, self).__init__()
self.network = nn.Sequential(
nn.Conv2d(in_channels, out_channels[0], kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(out_channels[0]),
nn.ReLU(),
nn.Conv2d(out_channels[0], out_channels[1], kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(out_channels[1]),
nn.ReLU(),
nn.Conv2d(out_channels[1], out_channels[2], kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(out_channels[2]),
)
self.downSample = nn.Sequential(
nn.Conv2d(in_channels, out_channels[2], kernel_size=1, padding=0, stride=stride),
nn.BatchNorm2d(out_channels[2])
)训练,测试函数定义如下
def train():
net.train()
acc = 0.0
sum = 0.0
loss_sum = 0
for batch, (data, target) in enumerate(trainLoader):
data, target = data.to(device), target.to(device)
net.optimizer.zero_grad()
output = net(data)
loss = net.lossFunc(output, target)
loss.backward()
net.optimizer.step()
acc += torch.sum(torch.argmax(output, dim=1) == target).item()
sum += len(target)
loss_sum += loss.item()
writer.add_scalar('Cifar100_model_log/trainAccuracy', 100 * acc / sum, epoch + 1)
writer.add_scalar('Cifar100_model_log/trainLoss', loss_sum / (batch + 1), epoch + 1)
print('train accuracy: %.2f%%, loss: %.4f' % (100 * acc / sum, loss_sum / (batch + 1)))
def test():
net.eval()
acc = 0.0
sum = 0.0
loss_sum = 0
step = 0
for batch, (data, target) in enumerate(testLoader):
initData = data
data = testTransform2(data)
data, target = data.to(device), target.to(device)
output = net(data)
'''
用于通过tensorboard可视化训练结果,使用时要注意将epoch设置为1
for i in range(len(output)):
writer.add_image(fineLabelList[torch.argmax(output, dim=1)[i]], initData[i], step)
step = step + 1
'''
loss = net.lossFunc(output, target)
acc += torch.sum(torch.argmax(output, dim=1) == target).item()
sum += len(target)
loss_sum += loss.item()
writer.add_scalar('Cifar100_model_log/testAccuracy', 100 * acc / sum, epoch + 1)
writer.add_scalar('Cifar100_model_log/trainLoss', loss_sum / (batch + 1), epoch + 1)
print('test accuracy: %.2f%%, loss: %.4f' % (100 * acc / sum, loss_sum / (batch + 1)))准备数据
'''
采用GPU加速训练,没有则用cpu
'''
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
trainTransform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
'''
数据集扩充采用
trainTransform = transforms.Compose([
transforms.ToTensor(),
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=(0,1), contrast=(0,1), saturation=(0,1), hue=0),
transforms.RandomVerticalFlip(p=0.5),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
'''
testTransform1 = transforms.Compose([
transforms.ToTensor(),
])
testTransform2 = transforms.Compose([
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
trainDataset = datasets.cifar.CIFAR100(root='cifar100', train=True, transform=trainTransform, download=False)
testDataset = datasets.cifar.CIFAR100(root='cifar100', train=False, transform=testTransform1, download=False)
trainLoader = DataLoader(trainDataset, batch_size=200, shuffle=True)
testLoader = DataLoader(testDataset, batch_size=200, shuffle=False)
2.模型训练及改进思路
训练过程中发现网络的过拟合问题情况严重,训练集正确率可达90%,测试集正确率卡在45%上下。
解决方案
(1)使用L1、L2正则化
(2)增加Dropout
(3)扩充数据集
(4)删除部分残差块,缩减网络
(5)迁移学习
经过测试,发现采用了缩减网络,扩充数据集,增加Dropout的网络可以使正确率从45%提升到了61.79%(迁移学习作用也比较明显,实验中的一种迁移学习方式在原训练基础上将正确率提升至63.13%)而相较于Dropout,L2正则化可以更好地防止过拟合,但是正确率上升缓慢且出现停滞。
最后网络定义如下,剩余残差块和卷积层可进行迁移训练
进行的部分迁移学习思路过程如下:
第一次迁移学习: 冻结block1~4 增加 block5:BasicBlock(128, 128) block6:BasicBlock(128, 512, 2) 重设全连接层 正确率浮动变化不大 第二次迁移学习: 第一次的基础上冻结所有层 补充cov1单层卷积2*2*512 (如果增加至三层则会下降严重) 正确率提升至58% 第三次迁移学习 冻结block1~4 原版基础上重设全连接层单层 目的为了训练卷积层 第四次迁移学习(较为成功) 冻结block1~4 在原版基础上增加 block5:BasicBlock(128, 1024) block6:BasicBlock(1024, 128) 进行一次放大将正确率提升至63.13% 经测试若采用缩小,正确率提高幅度不大

class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.block1 = BasicBlock(3, 16)
self.block2 = BasicBlock(16, 64, 2)
self.block3 = BasicBlock(64, 64)
self.block4 = BasicBlock(64, 128, 2)
self.block5 = nn.Sequential()
self.block6 = nn.Sequential()
self.block7 = nn.Sequential()
self.block8 = nn.Sequential()
self.block9 = nn.Sequential()
self.cov1 = nn.Sequential()
self.linear = nn.Sequential(
nn.Flatten(),
nn.Linear(8 * 8 * 128, 2048),
nn.Dropout(0.1),
nn.BatchNorm1d(2048),
nn.Linear(2048, 1024),
nn.Dropout(0.1),
nn.ReLU(),
nn.Linear(1024, 100)
)
self.optimizer = torch.optim.SGD(self.parameters(), lr=0.08)
self.lossFunc = torch.nn.CrossEntropyLoss()训练结果(可以发现还是过拟合严重)
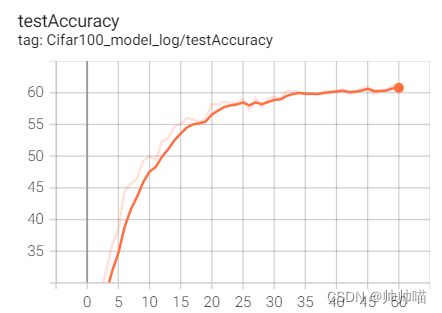

4. 结果可视化
受版面限制,部分展示如下
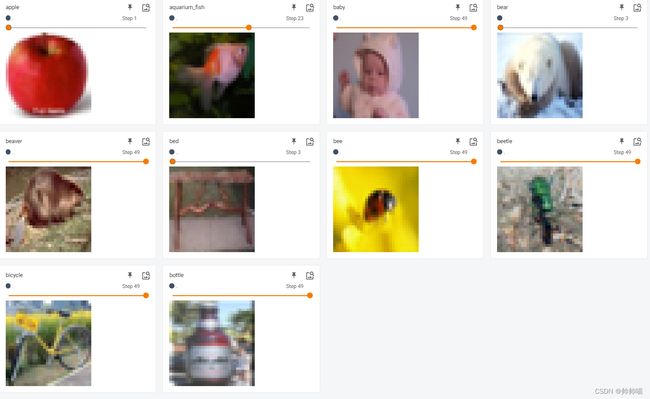
通过拖动发现,在bed标签下出现一只错误识别的兔子
