Pytorch学习记录(二)常用函数整理
文章内容整理自网络,方便自己日后查阅学习
关于pytorch中对标签的转换
如果使用了交叉熵损失函数,并不需要我们单独进行one-hot编码,因为该函数已经替我们执行了这一操作,我们只需要出入longtensor类型的label就可以
torch.max(input, dim)函数
output = torch.max(input, dim)
输入:
input参数是softmax函数输出的一个tensor
dim是max函数索引的维度(0/1),0求每列最大值,1求每行最大值
输出:
函数会返回两个tensor,第一个tensor为每行的最大值;第二个tensor是每行最大值的索引
分类问题中标签匹配问题
直接对标签tensor使用 == 操作即可对张量中每个元素进行比较
返回值是一个一维张量值相同为True,反之为False
a = torch.tensor([1,2,3,4,5,6,7,8,9])
b = torch.tensor([2,1,5,4,5,6,7,8,9])
c = (a == b)
print(c)结果
![]()
而对list进行 == 操作得到是一个bool 代表两个list是否相等
因为Python中True与False是完全相等的,因此对该张量调用.sum()方法就可以求出预测正确的个数
# 由示例可知True和1 以及False与0的相同性
>>> print(True == 1)
>>> print(True == 2)
>>> print(False == 0)
>>> print(False == 2)
True
False
True
False
通过.sum()方法求预测正确的个数
a = torch.tensor([1,2,3,4,5,6,7,8,9])
b = torch.tensor([2,1,5,4,5,6,7,8,9])
c = (a == b)
print(c)
print(c.sum())![]()
关于with torch.no_grad():
在使用pytorch时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。而对于tensor的计算操作,默认是要进行计算图的构建的,在这种情况下,可以使用 with torch.no_grad():,强制之后的内容不进行计算图构建。
zip()函数
zip([iterable, ...])函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象
例子:

Pytorch里面的X.view(-1)操作
X.view(-1)中的-1本意是根据另外一个数来自动调整维度,但是这里只有一个维度,因此就会将X里面的所有维度数据转化成一维的,并且按先后顺序排列。
import torch
a = torch.randn(3,5,2)
print(a)
print(a.view(-1))
tensor([[[-0.6887, 0.2203],
[-1.6103, -0.7423],
[ 0.3097, -2.9694],
[ 1.2073, -0.3370],
[-0.5506, 0.4753]],
[[-1.3605, 1.9303],
[-1.5382, -1.0865],
[-0.9208, -0.1754],
[ 0.1476, -0.8866],
[ 0.4519, 0.2771]],
[[ 0.6662, 1.1027],
[-0.0912, -0.6284],
[-1.0253, -0.3542],
[ 0.6909, -1.3905],
[-2.1140, 1.3426]]])
tensor([-0.6887, 0.2203, -1.6103, -0.7423, 0.3097, -2.9694, 1.2073, -0.3370,
-0.5506, 0.4753, -1.3605, 1.9303, -1.5382, -1.0865, -0.9208, -0.1754,
0.1476, -0.8866, 0.4519, 0.2771, 0.6662, 1.1027, -0.0912, -0.6284,
-1.0253, -0.3542, 0.6909, -1.3905, -2.1140, 1.3426])
PyTorch生成随机数
1. 均匀分布
torch.rand(*sizes, out=None)
返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
参数:
- sizes (int…) - 整数序列,定义了输出张量的形状
- out (Tensor, optinal) - 结果张量
2. 标准正态分布
torch.randn(*sizes, out=None)
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
参数:
- sizes (int…) - 整数序列,定义了输出张量的形状
- out (Tensor, optinal) - 结果张量
3. 离散正态分布
torch.normal(means, std, out=None)
返回一个张量,包含了从指定均值means和标准差std的离散正态分布中抽取的一组随机数。
标准差std是一个张量,包含每个输出元素相关的正态分布标准差。
参数:
- means (float, optional) - 均值
- std (Tensor) - 标准差
- out (Tensor) - 输出张量
torch.sum()
对输入的tensor数据的某一维度求和
a = torch.ones((2, 3))
print(a):
tensor([[1, 1, 1],
[1, 1, 1]])
a1 = torch.sum(a)
a2 = torch.sum(a, dim=0)
a3 = torch.sum(a, dim=1)
tensor(6.)
tensor([2., 2., 2.])
tensor([3., 3.])如果加上keepdim=True, 则会保持dim的维度不被squeeze
torch.eq()与torch.equal()
torch.eq(input, other, out=None) → Tensor
torch.equal(tensor1, tensor2) → booltorch.equal()要求整个tensor完全相同才是True,否则为False。
torch.eq()相同位置值相同则返回对应的True,返回的是一个列表
示例:

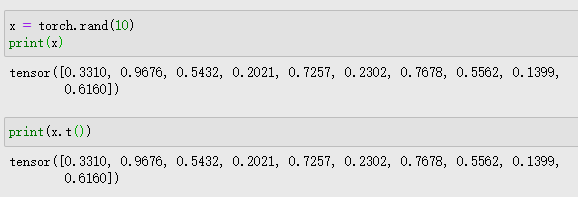
tensor.t()函数
tensor.t()函数返回tensor的转置
示例:

但t()函数对于一维tensor没有转置效果
torch.topk()函数
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor)沿给定dim维度返回输入张量input中 k 个最大值。
如果不指定dim,则默认为input的最后一维。
如果为largest为 False ,则返回最小的 k 个值。
返回一个元组 (values,indices),其中indices是原始输入张量input中测元素下标。
如果设定布尔值sorted 为_True_,将会确保返回的 k 个值被排序。
参数:
- input (Tensor) – 输入张量
- k (int) – “top-k”中的
k - dim (int, optional) – 排序的维
- largest (bool, optional) – 布尔值,控制返回最大或最小值
- sorted (bool, optional) – 布尔值,控制返回值是否排序
- out (tuple, optional) – 可选输出张量 (Tensor, LongTensor) output buffer
示例:
import torch
output = torch.tensor([[-5.4783, 0.2298],
[-4.2573, -0.4794],
[-0.1070, -5.1511],
[-0.1785, -4.3339]])
_, pred = output.topk(1, 1, True, True)
print(_)
tensor([[ 0.2298],
[-0.4794],
[-0.1070],
[-0.1785]])
print(pred)
tensor([[1],
[1],
[0],
[0]])_是top1的值,pred是最大值的索引(size=4*1),一般会进行转置处理同真实值对比
pytorch中的expand()和expand_as()函数
1.expand()函数:
(1)函数功能:
expand()函数的功能是用来扩展张量中某维数据的尺寸,它返回输入张量在某维扩展为更大尺寸后的张量。
expand()函数括号中的输入参数为指定经过维度尺寸扩展后的张量的size。
(2)应用举例:
1)
import torch
a = torch.tensor([1, 2, 3])
c = a.expand(2, 3)
print(a)
print(c)
# 输出信息:
tensor([1, 2, 3])
tensor([[1, 2, 3],
[1, 2, 3]]
2)
import torch
a = torch.tensor([1, 2, 3])
c = a.expand(3, 3)
print(a)
print(c)
# 输出信息:
tensor([1, 2, 3])
tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
3)
import torch
a = torch.tensor([[1], [2], [3]])
print(a.size())
c = a.expand(3, 3)
print(a)
print(c)
# 输出信息:
torch.Size([3, 1])
tensor([[1],
[2],
[3]])
tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
4)
import torch
a = torch.tensor([[1], [2], [3]])
print(a.size())
c = a.expand(3, 4)
print(a)
print(c)
# 输出信息:
torch.Size([3, 1])
tensor([[1],
[2],
[3]])
tensor([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]])(3)注意事项:
expand()函数只能将size=1的维度扩展到更大的尺寸,如果扩展其他size()的维度会报错。
2.expand_as()函数:
(1)函数功能:
expand_as()函数与expand()函数类似,功能都是用来扩展张量中某维数据的尺寸,区别是它括号内的输入参数是另一个张量,作用是将输入tensor的维度扩展为与指定tensor相同的size。
(2)示例:
1)
import torch
a = torch.tensor([[2], [3], [4]])
print(a)
b = torch.tensor([[2, 2], [3, 3], [5, 5]])
print(b.size())
c = a.expand_as(b)
print(c)
print(c.size())
# 输出信息:
tensor([[2],
[3],
[4]])
torch.Size([3, 2])
tensor([[2, 2],
[3, 3],
[4, 4]])
torch.Size([3, 2])
2)
import torch
a = torch.tensor([1, 2, 3])
print(a)
b = torch.tensor([[2, 2, 2], [3, 3, 3]])
print(b.size())
c = a.expand_as(b)
print(c)
print(c.size())
# 输出信息:
tensor([1, 2, 3])
torch.Size([2, 3])
tensor([[1, 2, 3],
[1, 2, 3]])
torch.Size([2, 3])