《Dynamically Fused Graph Network for Multi-hop Reasoning》 论文笔记
Dynamically Fused Graph Network for Multi-hop Reasoning 论文笔记
2019ACL,SJTU & ByteDance,这是一篇融合了图表示学习来做多跳推理的文章。
Overview
本文作者提出的模型叫做DFGN,作者首先谈到HotpotQA这种类型的数据集带给人们两大挑战:
- 数据集中给出的paragraph并不都是与问题相关的,模型需要过滤掉噪声。针对这一问题,之前的工作提出构建基于paragraph的entity graph,然后通过图神经网络对entity graph进行建模。但是作者认为之前的工作有一个缺点:对于每一个QA pair,之前的工作都是在一个静态的、全局的entity graph上进行推理。相反,作者在本文提出在动态的、局部的entity graph上建模效果更好。
- 之前的工作通常是将document的信息聚合到entity graph中,然后直接在entity graph上推理答案。但是作者认为很多时候答案可能根本不在entity graph当中。因此本文设计出了一个dynamic fusion layer,这个模块不仅包含document到entity的信息传递,还包含经过embedding后的entity到document的信息回传,最终再根据更新后的document得到答案。
总结一下DFGN模型,模型从问题中的实体出发,根据paragraph构建起一张与问题实体相关的动态的entity graph,然后fusion模块会对entity graph进行建模并完成实体与文本之间的信息传递,document的向量表示也随之更新。上述的过程不断的迭代,模型就得到了一条reasoning chain,最终得到答案。
DFGN
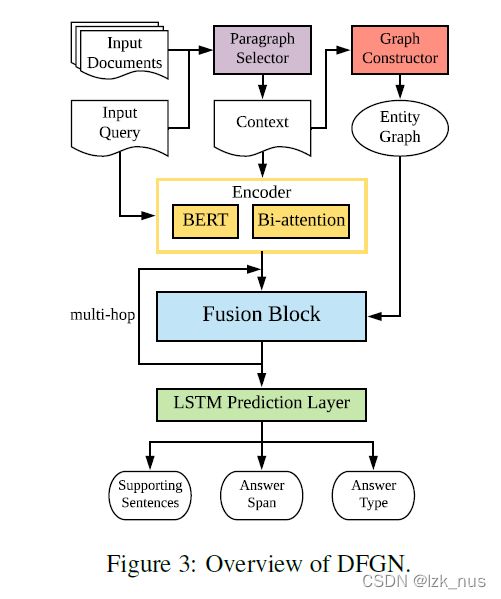
上图就是DFGN模型的整体架构,可以看出模型主要分为五大模块:
- Paragraph Selector
- Entity Graph Constructor
- Context and Query Encoder
- Fusion Block
- Prediction Block
Paragraph Selector
这个模块主要是用于过滤噪声段落,本文之前采用了先前的工作。用BERT来对所有的句子进行编码,做一个句子分类任务。作者把所有包含至少一条supporting fact的段落视为正例。在inference阶段,所有预测得分高于0.1的段落被选取出来,拼接到一起得到 C C C。
Entity Graph Constructor
对于实体图,本文采取的方法是先对 C C C进行NER,提取出所有的候选实体,然后开始连边。边有三种类型:
- 出现在同一个句子中的两个实体(sentence-level link)
- 具有相同mention text的两个实体(context-level link)
- 中心实体与其他出现在同一paragraph中的实体(paragraph-level link)
Context and Query Encoder
对于问题和段落的编码,本文直接采用BERT,然后再经过一层bi-attention,得到 Q 0 ∈ R L × 2 d 2 Q_{0}\in{R^{L\times 2d_{2}}} Q0∈RL×2d2和 C 0 ∈ R M × 2 d 2 C_{0}\in{R{^{M\times 2d_{2}}}} C0∈RM×2d2。
Fusion Block
fusion模块是本文的核心,主要包含三个子模块:
- Document to Graph Flow:根据document的向量表示得到Entity Graph中实体的向量表示
- Dynamic Graph Attention:通过GAT模型对Entity Graph进行建模
- Graph to Document Flow:将更新后的实体信息传递回document,并更新段落信息

Document to Graph Flow
这一模块作者也称作是Tok2Ent,实现方法是用一个binary mask M M M, M i j = 1 M_{ij}=1 Mij=1表示文本中的第 i i i个token出现在第 j j j个实体的span里。然后用一个mean-max pooling得到实体的embedding E t − 1 ∈ R 2 d 2 × N E_{t-1}\in{R^{2d_{2}\times N}} Et−1∈R2d2×N。
Dynamic Graph Attention
对于图结构的建模本文采用的是GAT模型。但在这之前,作者先设计了一个soft mask,来得到Entity Graph中所有与query相关的实体,我觉得这个mask也是实现本文Introduction部分提到的dynamic local entity graph的关键。
q ~ ( t − 1 ) = M e a n P o o l i n g ( Q ( t − 1 ) ) γ i ( t ) = q ~ ( t − 1 ) V t e i ( t − 1 ) / d 2 m ( t ) = σ [ γ 1 ( t ) , γ 2 ( t ) , … , γ 1 ( t ) ] E ~ ( t − 1 ) = m ( t ) ⋅ E ( t − 1 ) \widetilde{q}^{(t-1)}\ =\ MeanPooling(Q^{(t-1)})\\ \gamma^{(t)}_{i}\ =\ \widetilde{q}^{(t-1)}V_{t}e^{(t-1)}_{i}/\sqrt{d_{2}}\\ m^{(t)}\ =\ \sigma[\gamma_{1}^{(t)},\ \gamma_{2}^{(t)}, \dots,\ \gamma_{1}^{(t)}] \\ \widetilde{E}^{(t-1)}=m^{(t)} \cdot E^{(t-1)} q (t−1) = MeanPooling(Q(t−1))γi(t) = q (t−1)Vtei(t−1)/d2m(t) = σ[γ1(t), γ2(t),…, γ1(t)]E (t−1)=m(t)⋅E(t−1)
V t V_{t} Vt是一个linear projection,可以看出这个mask的计算是通过attention + sigmoid来实现的。这里的mask是可训练的。
得到了mask后的实体向量表示,接下来套用GAT模型。
h i ( t ) = U e ~ i ( t − 1 ) + b s i , j ( t ) = L e a k y R e L u ( W t T [ h i ( t ) ; h j ( t ) ] ) α i j ( t ) = e x p ( s i , j ( t ) ) ∑ k e x p ( s i , k ( t ) ) h^{(t)}_{i}\ =\ U\widetilde{e}^{(t-1)}_{i}+b\\ s^{(t)}_{i,j}\ =\ LeakyReLu(W^{T}_{t}[h^{(t)}_{i};h^{(t)}_{j}])\\ \alpha^{(t)}_{ij}\ =\ \frac{exp({s^{(t)}_{i,j}})}{\sum_{k}exp(s^{(t)}_{i,k})} hi(t) = Ue i(t−1)+bsi,j(t) = LeakyReLu(WtT[hi(t);hj(t)])αij(t) = ∑kexp(si,k(t))exp(si,j(t))
得到attention weight之后更新实体的向量表示:
e i ( t ) = R e L u ( ∑ j ∈ N i α j , i ( t ) h j ( t ) ) e^{(t)}_{i}\ =\ ReLu(\sum_{j \in N_{i}}\alpha^{(t)}_{j,i}h^{(t)}_{j}) ei(t) = ReLu(j∈Ni∑αj,i(t)hj(t))
Graph to Document Flow
首先,作者对query进行了更新,因为当前时间步所访问到的新实体可能成为下一个时间步的start entity,因此对query的更新是必要的。更新的方式是Bi-Attention。
Q ( t ) = B i − A t t e n t i o n ( Q ( t − 1 ) , E ( t ) ) Q^{(t)}\ =\ Bi-Attention(Q^{(t-1)},E^{(t)}) Q(t) = Bi−Attention(Q(t−1),E(t))
接下来是信息的“反向传播”,即从graph传递到document,因此这一模块也被作者成为Graph2Doc。具体做法是,仍然使用Entity Graph Constructor中的 M M M矩阵来对实体进行过滤,然后用LSTM得到更新后的document
C ( t ) = L S T M ( C ( t − 1 ) , M E ( t ) ) C^{(t)}\ =\ LSTM(C^{(t-1)},\ ME^{(t)}) C(t) = LSTM(C(t−1), ME(t))
Prediction Block
HotpotQA一般有四个预测值:是否为supporting fact、answer start、answer end、question type。而本文的预测模块也是一个创新点,作者使用了级联的LSTM结构,四个LSTM层 F i F_{i} Fi叠在一起
O s u p = F 0 ( [ C ( t ) ] ) O s t a r t = F 1 ( [ C ( t ) , O s u p ] ) O e n d = F 2 ( [ C ( t ) , O s t a r t , O s u p ] ) O t y p e = F 3 ( [ C ( t ) , O e n d , O s u p ] ) O_{sup}\ =\ F_{0}([C^{(t)}])\\ O_{start}\ =\ F_{1}([C^{(t)},\ O_{sup}])\\ O_{end}\ =\ F_{2}([C^{(t)},\ O_{start},\ O_{sup}])\\ O_{type}\ =\ F_{3}([C^{(t)},\ O_{end},\ O_{sup}]) Osup = F0([C(t)])Ostart = F1([C(t), Osup])Oend = F2([C(t), Ostart, Osup])Otype = F3([C(t), Oend, Osup])
而损失函数也是四者相加
L = L s t a r t + L e n d + λ s L s u p + λ t L t y p e L\ =\ L_{start}\ +\ L_{end}\ +\ \lambda_{s}L_{sup}\ +\ \lambda_{t}L_{type} L = Lstart + Lend + λsLsup + λtLtype
Experiment
再HotpotQA上的结果
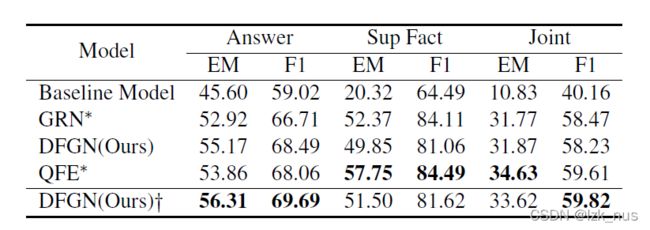
消融实验

作者还做了case study

第二和第三个例子是bad case,可以通过第一个case来看一下DFGN的reasoning chain。首先Mask1,也就是 M M M矩阵将问题中的相关实体提取出来,接着Mask2,也就是soft mask会把与答案实体相关的实体结点突出出来,最终得到答案。