pytorch进阶训练技巧之:探索如何更优雅地训练PyTorch模型
Pytorch学习第四部分:pytorch进阶训练技巧
- Let's go !
- 一、U-Net模块回顾
-
- 1.1 模块代码
- 2.2 搭建过程
- 二、Carvana数据集,实现一个基本的U-Net训练过程
- 三、优雅地训练模型
-
- 3.1 自定义损失函数
-
- 3.1.1 使用torch.nn自带的损失函数
- 3.1.2 使用自定义的损失函数
- 3.2 动态调整学习率
- 3.3 模型微调
- 3.4 半精度训练
-
- 3.4.1 pytorch精度测试
- 3.4.2 半精度训练
- 3.5 数据增强-imgaug
-
- 3.5.1 imgaug简介和安装
- 3.5.2 imgaug处理单张图片
-
- 1)图片读取
- 2)图片旋转
- 3)对一张图片进行多种增强操作
- 3.5.3 imgaug处理批次图片
-
- 1)对批次的图片以同一种方式处理
- 2)对批次的图片分部分处理
- 3.5.4 对不同大小的图片进行处理
- 3.5.5 imgaug在PyTorch的应用
- 3.6 使用argparse进行调参
-
- 3.6.1 argparse简介
- 3.6.2 argparse的使用
- 3.6.3 更加高效使用argparse修改超参数(脚本)
- 3.6.4 关于__name__ == '__main__'
Let’s go !
在经过了前三部分的学习之后我们已经对于pytorch的基础知识、主要组成模块、模型定义有了系统的了解,此外还通过FashionMNIST时装分类实战和U-Net模块搭建对神经网络有了较深的认识。如果你觉得那一部分知识还没有掌握的太透彻可以点击对应的链接跳转复习一下:
- pytorch基础知识之:张量-自动求导-并行计算
- pytorch主要组成模块之:动手完成简单的深度学习模型搭建
- pytorch模型定义之:模型定义三种方式以及U-Net模块搭建笔记
如果你觉得以上知识已经掌握的差不多了那么我们就开始本节内容分析–如何优雅地训练pytorch模型,让我们一起学起来吧!
一、U-Net模块回顾
首先开始本次优雅地训练pytorch模型之前,我们先回顾以下上一节我们自己定义的U-Net模块,回顾的目的是为了在后续进行代码演示的时候不至于对一些函数的定义感觉陌生。
先给出U-Net模型的结构图:
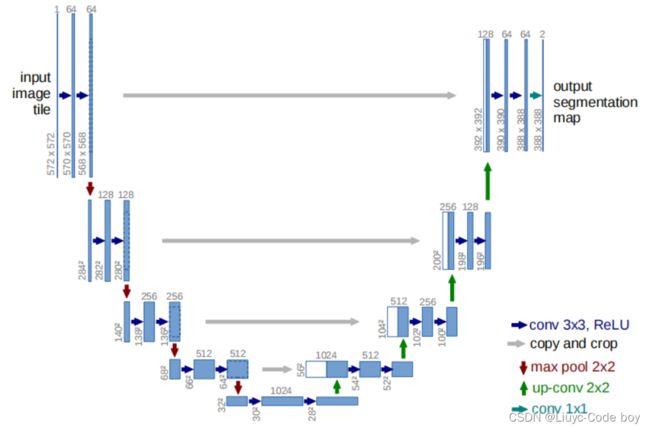
组成U-Net的模型块主要有如下几个部分:
1)每个子块内部的两次卷积(Double Convolution)
2)左侧模型块之间的下采样连接,即最大池化(Max pooling)
3)右侧模型块之间的上采样连接(Up sampling)
4)输出层的处理
除模型块外,还有模型块之间的横向连接,输入和U-Net底部的连接等计算,这些单独的操作可以通过forward函数来实现。
(参考:https://github.com/milesial/Pytorch-UNet )
1.1 模块代码
2.2 搭建过程
首先导入一些必要的pytorch包
import os
import numpy as np
import collections
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
搭建两次卷积模块:
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""##双次卷积
def __init__(self, in_channels, out_channels, mid_channels=None):#因为是两次卷积所以在输入通道数,输出通道数直接还要有一个中间通道数(第一次卷积输出=第二次卷积输入)
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),#第一次卷积从输入通道到中间通道
nn.BatchNorm2d(mid_channels),# 执行一次BatchNorm2d和激活
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),#第二次卷积从中间通道到输出通道
nn.BatchNorm2d(out_channels),# 再执行一次BatchNorm2d和激活
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)#因为是Sequention的定义方式所以forward直接把sequention给他forward就好了
搭建下采样模块:
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""#下采样模块
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),#先把尺寸降低
DoubleConv(in_channels, out_channels)#再做一次DoubleConv(复用),还是得到一个sequention的模块
)
def forward(self, x):
return self.maxpool_conv(x)
搭建上采样模块:
class Up(nn.Module):
"""Upscaling then double conv"""#上采样模块
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:#因为上采样需要差值,bilinear就是一个差值方式
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)#Upsample是pytorch内置的一个函数进行上采样操作
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)#上采样之后在进行一次卷积
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)#精髓点,将x2和x1叠加在一起
return self.conv(x)
搭建输出模块:
class OutConv(nn.Module):# 输出的时候再进行一次卷积,这个卷积目的是使得channel数达到最后的channel数量,如果是二分类问题channel可能是1,多分类可能是5,6,7...
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
各模块组装:
## 组装
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)# 参数都是连续的64...128...256...512
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1#,factor取决于差值的选取方式,如果是linear的话factor就是2
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)#上采样的时候是通道数是逐渐减少的
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):#用forward连接起来,是一个很优美的数据流
x1 = self.inc(x)#数据输进来,先过inc进行第一次DoubleConv
x2 = self.down1(x1)#下采样的时候其实也有DoubleConv操作,但是直接down就好了,因为Down函数里面有复用的DouleConv
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)#上采样有两个输入因为up是接收了另一个输入的
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)#最后把x4得到的结果输出到output得到的logits,logitis其实就是做sigmoid之前的一个数。
return logits
二、Carvana数据集,实现一个基本的U-Net训练过程
Carvana是一个汽车的自然图像的数据集有汽车的位置的分割。
我们选择的数据集中图片格式为1000*1000像素。
下面我们看一下用U-Net模块训练Carvana数据集:
首先导入一些必要的包:
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import torch.optim as optim
import matplotlib.pyplot as plt
import PIL
from sklearn.model_selection import train_test_split
import os #我没有gpu所以自己加上了这一个包导入
#os.environ['CUDA_VISIBLE_DEVICES'] = '2,3' #我没有gpu所以就把这个注释了
定义一个CarvanaDataset类,其中包含三个函数,其含义分别是:
- init: 用于向类中传入外部参数,同时定义样本集。
- getitem: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据。
- len: 用于返回数据集的样本数 。
其中最重要的部分就是**getitem**部分,直接决定函数的构建。
代码依旧使用Dataset+DataLoader的方式进行数据读入
代码如下:
class CarvanaDataset(Dataset):
def __init__(self, base_dir, idx_list, mode="train_images", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir+"train_images")
self.masks = os.listdir(base_dir+"train_masks")
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4]+"_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train_images", image_file))
if self.mode=="train_images":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask!=0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "./data/data/"#不管是训练集还是测试集文件都要访问的起始位置
transform = transforms.Compose([transforms.Resize((256,256)), transforms.ToTensor()])#将图片缩小到256*256
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir+"train_masks"))), test_size=0.3)
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, num_workers=0, shuffle=True)
val_loader = DataLoader(train_data, batch_size=32, num_workers=0, shuffle=False)
实例化执行;
image, mask = next(iter(train_loader))
plt.subplot(121)
plt.imshow(image[0,0])#从数据集选一个RGB三通道的图像输出
plt.subplot(122)
plt.imshow(mask[0,0], cmap="gray")#把图像变成白色为前景,黑色为背景的一个,mask分割输出
结果展示:

下面我们开始对模型进行一些处理使得训练更加优雅。
三、优雅地训练模型
主要包括四个部分:自定义损失函数、动态调整学习率、模型微调、半精度训练。
3.1 自定义损失函数
3.1.1 使用torch.nn自带的损失函数
我们先用torch.nn中自带的Binary Cross Entropy Loss作为损失函数,之后我们会尝试替换为自定义的损失函数。
优化器使用提供的optim.Adam优化器。
代码如下:
# 使用Binary Cross Entropy Loss,之后我们会尝试替换为自定义的loss
criterion = nn.BCEWithLogitsLoss()#损失函数先用基础的BCEWithLogitsLoss,之后可以自己定义损失函数
optimizer = optim.Adam(unet.parameters(), lr=1e-3, weight_decay=1e-8)#优化器就用提供的optim.Adam
#unet = nn.DataParallel(unet).cuda() # 我没有gpu就不用这个了
unet = nn.DataParallel(unet)
定义训练和测试的代码:
def dice_coeff(pred, target):# 评价指标,用来衡量分割的好坏,能够更好的反应对于前景的评估能力
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
def train(epoch):#训练
unet.train()
train_loss = 0
for data, mask in train_loader:
#data, mask = data.cuda(), mask.cuda() # 我没有gpu就注释了
optimizer.zero_grad()
output = unet(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch): #测试(验证)
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])# 打印学习率,当前没有强制学习率变化,所以默认是不变的
unet.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
#data, mask = data.cuda(), mask.cuda() # 我没有gpu就注释了
output = unet(data)
loss = criterion(output, mask)
val_loss += loss.item()*data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu())*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
与之前训练FashionMNIST模型不同的是,Carvana模型中没有输出准确率,但是我们输出了学习率,由于当前没有强制学习率变化,所以默认是不变的。
运行100轮:
#这一部分在没有gpu的时候我建议不要执行,我cpu直接占满了,难受...
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
结果展示;

可以发现当前学习率是默认不变的
我们可以查看一下当前的gpu占用情况,后续半精度训练的时候比较的时候会用到。
!nvidia-smi #查看gpu使用情况,当然这不是我的。。。
结果展示: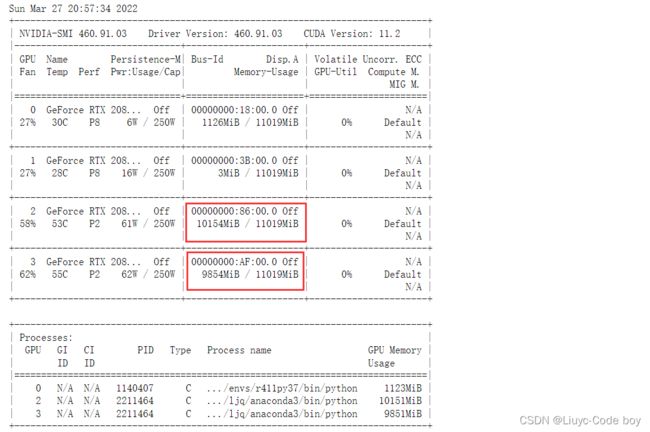
发现我们使用的两个gpu基本上都占满了。
3.1.2 使用自定义的损失函数
如果我们不想使用交叉熵函数,而是想针对分割模型常用的Dice系数设计专门的loss,即DiceLoss,这时就需要我们自定义PyTorch的损失函数。
通常自定义损失函数都是使用如下这种继承nn.Module的网络的方式进行自定义损失函数的。
代码如下:
class DiceLoss(nn.Module):#通常自定义损失函数都是使用如下这种继承nn.Module的网络的方式进行自定义损失函数的。
def __init__(self, weight=None, size_average=True):
super(DiceLoss, self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = torch.sigmoid(inputs) #对输入进行激活函数处理
inputs = inputs.view(-1) #把输入拉直
targets = targets.view(-1) #拉直
intersection = (inputs * targets).sum() #只有input=1,target=1的时候才会把值赋给intersection
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
输出损失函数值则表示自定于的损失函数跑通了:
newcriterion = DiceLoss()
unet.eval()
image, mask = next(iter(val_loader))# iter是一种迭代类似for循环,但是iter只循环一次,next是让iter往下再执行一步
#out_unet = unet(image.cuda()) #我没有gpu
#loss = newcriterion(out_unet, mask.cuda()) #我没有gpu
out_unet = unet(image)
loss = newcriterion(out_unet, mask)
print(loss) # 输出损失函数值则表示自定于的损失函数跑通了,我cpu也卡死了...没有gpu还是别跑了
结果展示:
![]()
3.2 动态调整学习率
随着优化的进行,固定的学习率可能无法满足优化的需求,这时需要调整学习率,降低优化的速度。这里演示使用PyTorch自带的StepLR scheduler动态调整学习率的效果。
代码如下:
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.8)#用pytorch自带的StepLR scheduler动态调整学习率,是每个多少步降低多少倍的学习率
#这里设置的步长是step_size=1,一般都是5,10这样。
#gamma=0.8是每隔一步就会变成原来的0.8,一般与step_size配合使用。例如,如果想下降的平滑一点可以步长短一点gamma大一点。
用pytorch自带的StepLR scheduler动态调整学习率,是每隔多少步降低多少倍的学习率
这里设置的步长是step_size=1,一般都是5,10这样。
gamma=0.8是每隔一步就会变成原来的0.8,一般与step_size配合使用。例如,如果想下降的平滑一点可以步长短一点gamma大一点。
再次运行一下观察学习率的变化:
#休想再卡死我,我直接注释,看一眼学习率变化卡死我cpu是不可能的。
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
scheduler.step()
结果展示:

每一次都变成了上一次的0.8倍。
pytorch的查看功能:?+查询的方法名
?optim.lr_scheduler.StepLR
#notebook专用的查看方法,在其他地方就需要help(...)
结果展示:
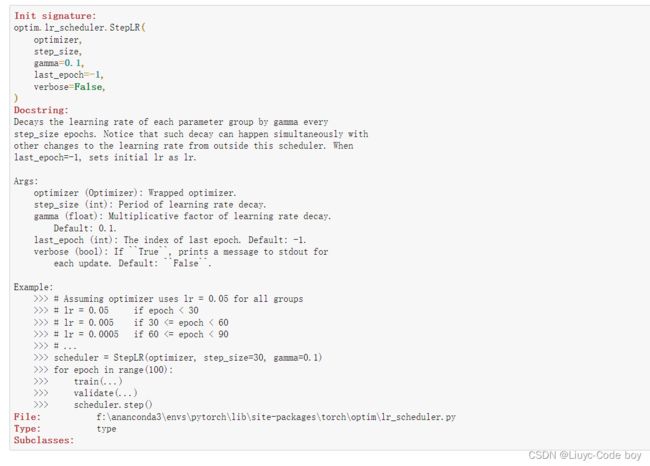
可以看到这个解释解释很详细的,还给出了示例(Example),当步长为30,学习率降低倍数为0.1时的例子。
此外要注意这是notebook专用的查看方法,在其他地方就需要help(…)
3.3 模型微调
模型微调的核心是:需要固定一些层让他不进行参数、梯度的更新。
模型微调是一个比较大的工程,一般是已经有了别人预训练的权重或者从torchversion官网下载的权重,可以微调设置一些requires_grad=False
设置完了可以输出查看一下修改成功了吗。
- 查看当前模型:
unet # 查看模型,因为U-Net模型没有什么卷积层和全连接层所以其实这个演示效果可能不是那么理想。
结果展示:

- 输出名为outc的层相关信息:
unet.outc#输出最后一层
结果展示:

3. 输出名为outc的层里面定义的卷积(当前定义的是二次卷积)
unet.outc.conv#输出最后一层里面定义的卷积(上面定义的是二次卷积)
结果展示:
![]()
4. 到了具体的层之后我们就可以.weight,输出结果是一个tensor的矩阵,后面有参数, requires_grad=True表示要求模型允许梯度迭代更新,如果用gpu的话还有一个参数device=‘卡号’,。
unet.outc.conv.weight
#到了具体的层之后我们就可以.weight,是一个tensor的矩阵,后面有参数, requires_grad=True表示要求模型允许梯度迭代更新,如果用gpu的话还有一个参数device='卡号',。
结果展示:
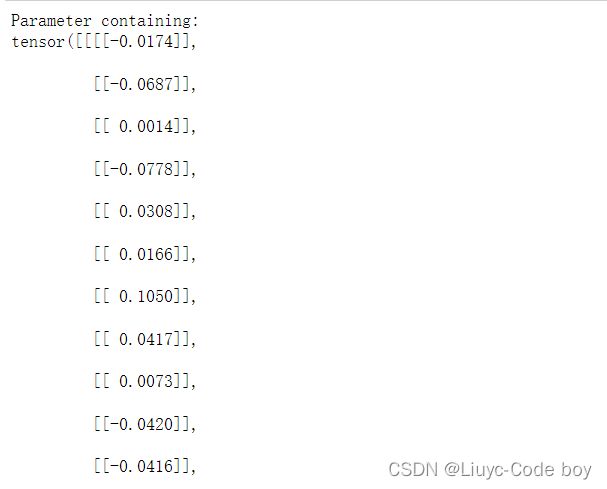

5. 修改outc层的weight和bias的requires_grad = False:
最后一定要用for循环看看所有层的.requires_grad看看是不是所修改层的所有的requires_grad是否都已经修改为False。
# 这里面unet.module.outc是我们上面定义的U-Net模块的最后一层,这里.module是因为示例中是多卡的形式。
#unet.module.outc.conv.weight.requires_grad = False #这个就是我们特指他不允许梯度迭代更新
unet.outc.conv.weight.requires_grad = False # 如果像我一样是cpu的话可以 ,中间不用.module
#unet.module.outc.conv.bias.requires_grad = False #这个就是我们特指他的偏置值也不允许梯度迭代更新
unet.outc.conv.bias.requires_grad = False
for layer, param in unet.named_parameters():
print(layer, '\t', param.requires_grad)#for循环看看所有层的.requires_grad
结果展示:

观察发现outc层均为False
3.4 半精度训练
目的:解决占用cpu/gpu太多的情况
3.4.1 pytorch精度测试
先看一下我们当前使用的image变量的数据类型:
image.dtype # 这是我们上面定义Carvana模型的时候定义的一个变量,当我们不干扰他的时候是一个32位浮点数默认是float32
#但是我们大部分时候不需要32位的精度,我们可以把它变成float16,16位浮点数(再小就没了,比如float8就,没有了)
结果展示:
![]()
我们再看一下pytorch是否提供了16位的浮点数:
torch.float16
结果展示:
![]()
输出结果说明pytorch提供了16位的浮点数。
我们再看一下pytorch是否提供了8位的浮点数:
torch.float8
结果展示:

输出结果说明pytorch没有提供8位的浮点数。
所以我们接下来将原始的32位浮点数数据转换成16位的浮点数数据,观察程序执行显卡的占用情况。
3.4.2 半精度训练
使用半精度只需要对三个地方进行修改:
1. 位置1: import一个关键模块 from torch.cuda.amp import autocast (没有from torch.amp import autocast这个模块,可能cpu也是添加前面那个模块)
## 演示时需要restart kernel,并运行Unet模块
# -----------------------------------------------here------------------------------------------------------
from torch.cuda.amp import autocast
os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'
class CarvanaDataset(Dataset):
def __init__(self, base_dir, idx_list, mode="train", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir+"train")
self.masks = os.listdir(base_dir+"train_masks")
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4]+"_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train", image_file))
if self.mode=="train":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask!=0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "./"
transform = transforms.Compose([transforms.Resize((256,256)), transforms.ToTensor()])
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir+"train_masks"))), test_size=0.3)
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=True)
val_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=False)
2. 位置2: 在forward之前加一个@autocast()修饰器函数,可以百度以下修饰器怎么用(不太好理解)。
class UNet_half(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet_half, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
# -----------------------------------------------here------------------------------------------------------
@autocast()
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
unet_half = UNet_half(3,1)
unet_half = nn.DataParallel(unet_half).cuda()
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(unet_half.parameters(), lr=1e-3, weight_decay=1e-8)
3. 位置3: 在训练的时候加一个with autocast():,做一个半精度16位计算。
def dice_coeff(pred, target):
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
def train_half(epoch):
unet_half.train()
train_loss = 0
for data, mask in train_loader:
data, mask = data.cuda(), mask.cuda()
# -----------------------------------------------here------------------------------------------------------
with autocast():
optimizer.zero_grad()
output = unet_half(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val_half(epoch):
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])
unet_half.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda()
with autocast():
output = unet_half(data)
loss = criterion(output, mask)
val_loss += loss.item()*data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu())*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
最后,设置完成之后我们重新执行训练与测试:
注意: 如果设置完了这三个地方要重跑项目看显存占用的话,应该先刷新Jupyter不然显存是不会默认清空的。
epochs = 100
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.8)
for epoch in range(1, epochs+1):
train_half(epoch)
val_half(epoch)
scheduler.step()
!nvidia-smi #查看一下gpu使用情况
结果如下:

只占用了刚刚训练和测试时候一半的显卡,执行速度得到了极大提升。
3.5 数据增强-imgaug
深度学习最重要的是数据。我们需要大量数据才能避免模型的过度拟合。但是我们在许多场景无法获得大量数据,例如医学图像分析。数据增强技术的存在是为了解决这个问题,这是针对有限数据问题的解决方案。数据增强一套技术,可提高训练数据集的大小和质量,以便我们可以使用它们来构建更好的深度学习模型。 在计算视觉领域,生成增强图像相对容易。即使引入噪声或裁剪图像的一部分,模型仍可以对图像进行分类,数据增强有一系列简单有效的方法可供选择,有一些机器学习库来进行计算视觉领域的数据增强,比如:imgaug 官网它封装了很多数据增强算法,给开发者提供了方便。通过本章内容,您将学会以下内容:imgaug的简介和安装以及使用imgaug对数据进行增强。
3.5.1 imgaug简介和安装
imgaug是计算机视觉任务中常用的一个数据增强的包,相比于torchvision.transforms,它提供了更多的数据增强方法,因此在各种竞赛中,人们广泛使用imgaug来对数据进行增强操作。除此之外,imgaug官方还提供了许多例程让我们学习,本章内容仅是简介,希望起到抛砖引玉的功能。
Github地址:imgaug
Readthedocs:imgaug
官方提供notebook例程:notebook
imgaug的安装
imgaug的安装方法和其他的Python包类似,我们可以通过以下两种方式进行安装(我本人是用的conda install安装的,亲测有效):
conda:
conda config --add channels conda-forge
conda install imgaug
pip:
# install imgaug either via pypi
pip install imgaug
# install the latest version directly from github
pip install git+https://github.com/aleju/imgaug.git
3.5.2 imgaug处理单张图片
1)图片读取
imgaug仅仅提供了图像增强的一些方法,但是并未提供图像的IO操作,因此我们需要使用一些库来对图像进行导入,建议使用imageio进行读入,如果使用的是opencv进行文件读取的时候,需要进行手动改变通道,将读取的BGR图像转换为RGB图像。除此以外,当我们用PIL.Image进行读取时,因为读取的图片没有shape的属性,所以我们需要将读取到的img转换为np.array()的形式再进行处理。因此官方的例程中也是使用imageio进行图片读取。
这是我参考的一篇讲解关于各种强化器的CSDN博客:imgaug数据增强神器:增强器一览
图片读取代码如下:
import os
import numpy as np
import torch
import torch.nn as nn
import torchvision
import imageio
import imgaug as ia
%matplotlib inline
# 图片的读取
img = imageio.imread("./bear.jpg")
# 使用Image进行读取
# img = Image.open("./Lenna.jpg")
# image = np.array(img)
# ia.imshow(image)
# 可视化图片
ia.imshow(img)
结果展示:
2)图片旋转
图片的旋转:
注:值仿射变换(Affine Transformation) Affine Transformation是一种二维坐标到二维坐标之间的线性变换,保持二维图形的“平直性”(译注:straightness,即变换后直线还是直线不会打弯,圆弧还是圆弧)和“平行性”。
rotate=(-4,45)表示图像旋转位于-4~45之间的随机。
代码如下:
from imgaug import augmenters as iaa
# 设置随机数种子
ia.seed(4)
# 实例化方法
rotate = iaa.Affine(rotate=(-4,45))#图像旋转位于-4~45之间的随机值
img_aug = rotate(image=img)
ia.imshow(img_aug)
结果展示:

这是对一张图片进行一种操作方式,但实际情况下,我们可能对一张图片做多种数据增强处理。这种情况下,我们就需要利用imgaug.augmenters.Sequential()来构造我们数据增强的pipline,该方法与torchvison.transforms.Compose()相类似。
3)对一张图片进行多种增强操作
类似模块定义中的Sequential方法,我们用一个序列的方式定义对图片所要进行的一系列数据增强操作。
代码如下:
iaa.Sequential(children=None, # Augmenter集合
random_order=False, # 是否对每个batch使用不同顺序的Augmenter list
name=None,
deterministic=False,
random_state=None)
- Affine(rotate=(-25,25))对图片进行值仿射变换(Affine Transformation),并且图像旋转位-25~25之间的随机值。
- AdditiveGaussianNoise(scale=(10,60)),#加性高斯白噪声。"白"是指功率谱恒定,高斯指的是概率p (x)满足高斯函数。
#将高斯噪声添加到图像中,每个像素从正态分布N(0,s)采样一次,其中s对每个图像采样并在10和60之间变化。 - CropAndPad的代理。 它只接受正像素/百分比值并将它们作为负值传给CropAndPad。
- 对图片进行处理,image不可以省略,也不能写成images。
# 构建处理序列
aug_seq = iaa.Sequential([
iaa.Affine(rotate=(-25,25)),#图像旋转位-4~45之间的随机值
iaa.AdditiveGaussianNoise(scale=(10,60)),#加性高斯白噪声。"白"是指功率谱恒定,高斯指的是概率p (x)满足高斯函数。
#将高斯噪声添加到图像中,每个像素从正态分布N(0,s)采样一次,其中s对每个图像采样并在10和60之间变化:
iaa.Crop(percent=(0,0.2))
#这是CropAndPad的代理。 它只接受正像素/百分比值并将它们作为负值传给CropAndPad。
])
# 对图片进行处理,image不可以省略,也不能写成images
image_aug = aug_seq(image=img)
ia.imshow(image_aug)
结果展示:
总的来说,对单张图片处理的方式基本相同,我们可以根据实际需求,选择合适的数据增强方法来对数据进行处理。
3.5.3 imgaug处理批次图片
在实际使用中,我们通常需要处理更多份的图像数据。此时,可以将图形数据按照NHWC的形式或者由列表组成的HWC的形式对批量的图像进行处理。主要分为以下两部分,对批次的图片以同一种方式处理和对批次的图片进行分部分处理。
1)对批次的图片以同一种方式处理
对一批次的图片进行处理时,我们只需要将待处理的图片放在一个list中,并将image改为image即可进行数据增强操作,代码如下:
images = [img,img,img,img,]
images_aug = rotate(images=images)
ia.imshow(np.hstack(images_aug))
结果展示:
在上述的例子中,我们仅仅对图片进行了仿射变换,同样的,我们也可以对批次的图片使用多种增强方法,与单张图片的方法类似,我们同样需要借助Sequential来构造数据增强的pipline。
代码如下:
aug_seq = iaa.Sequential([
iaa.Affine(rotate=(-25, 25)),
iaa.AdditiveGaussianNoise(scale=(10, 60)),
iaa.Crop(percent=(0, 0.2))
])
# 传入时需要指明是images参数
images_aug = aug_seq.augment_images(images = images)
#images_aug = aug_seq(images = images)
ia.imshow(np.hstack(images_aug))
结果展示:

2)对批次的图片分部分处理
imgaug相较于其他的数据增强的库,有一个很有意思的特性,即就是我们可以通过imgaug.augmenters.Sometimes()对batch中的一部分图片应用一部分Augmenters,剩下的图片应用另外的Augmenters。
代码如下:
iaa.Sometimes(p=0.5, # 代表划分比例
then_list=None, # Augmenter集合。p概率的图片进行变换的Augmenters。
else_list=None, #1-p概率的图片会被进行变换的Augmenters。注意变换的图片应用的Augmenter只能是then_list或者else_list中的一个。
name=None,
deterministic=False,
random_state=None)
3.5.4 对不同大小的图片进行处理
上面提到的图片都是基于相同的图像。以下的示例具有不同图像大小的情况,我们从本地文件夹中加载三张图片,将它们作为一个批次进行扩充,然后一张一张地显示每张图片。具体的操作跟单张的图片都是十分相似,因此不做过多赘述。
代码如下:
# 构建pipline
seq = iaa.Sequential([
iaa.CropAndPad(percent=(-0.2, 0.2), pad_mode="edge"), # crop and pad images
iaa.AddToHueAndSaturation((-60, 60)), # change their color
iaa.ElasticTransformation(alpha=90, sigma=9), # water-like effect
iaa.Cutout() # replace one squared area within the image by a constant intensity value
], random_order=True)
# 加载不同大小的图片
images_different_sizes = [
#imageio.imread("https://upload.wikimedia.org/wikipedia/commons/e/ed/BRACHYLAGUS_IDAHOENSIS.jpg"),
#imageio.imread("https://upload.wikimedia.org/wikipedia/commons/c/c9/Southern_swamp_rabbit_baby.jpg"),
#imageio.imread("https://upload.wikimedia.org/wikipedia/commons/9/9f/Lower_Keys_marsh_rabbit.jpg")
imageio.imread(r"F:\python\研究生python\Datawhale\Pytorch\thorough-pytorch-main\thorough-pytorch-main\notebook\第六章 PyTorch进阶训练技巧\pict.jpg"),
imageio.imread(r"F:\python\研究生python\Datawhale\Pytorch\thorough-pytorch-main\thorough-pytorch-main\notebook\第六章 PyTorch进阶训练技巧\bear.jpg"),
imageio.imread(r"F:\python\研究生python\Datawhale\Pytorch\thorough-pytorch-main\thorough-pytorch-main\notebook\第六章 PyTorch进阶训练技巧\daishu.jpg")
]
# 对图片进行增强
images_aug = seq(images=images_different_sizes)
# 可视化结果
print("Image 0 (input shape: %s, output shape: %s)" % (images_different_sizes[0].shape, images_aug[0].shape))
ia.imshow(np.hstack([images_different_sizes[0], images_aug[0]]))
print("Image 1 (input shape: %s, output shape: %s)" % (images_different_sizes[1].shape, images_aug[1].shape))
ia.imshow(np.hstack([images_different_sizes[1], images_aug[1]]))
print("Image 2 (input shape: %s, output shape: %s)" % (images_different_sizes[2].shape, images_aug[2].shape))
ia.imshow(np.hstack([images_different_sizes[2], images_aug[2]]))
结果展示:
3.5.5 imgaug在PyTorch的应用
关于PyTorch中如何使用imgaug每一个人的模板是不一样的,大佬也仅仅给出imgaug的issue里面提出的一种解决方案,大家可以根据自己的实际需求进行改变。 具体链接:how to use imgaug with pytorch
大佬的代码如下;
import numpy as np
from imgaug import augmenters as iaa
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
# 构建pipline
tfs = transforms.Compose([
iaa.Sequential([
iaa.flip.Fliplr(p=0.5),
iaa.flip.Flipud(p=0.5),
iaa.GaussianBlur(sigma=(0.0, 0.1)),
iaa.MultiplyBrightness(mul=(0.65, 1.35)),
]).augment_image,
# 不要忘记了使用ToTensor()
transforms.ToTensor()
])
# 自定义数据集
class CustomDataset(Dataset):
def __init__(self, n_images, n_classes, transform=None):
# 图片的读取,建议使用imageio
self.images = np.random.randint(0, 255,
(n_images, 224, 224, 3),
dtype=np.uint8)
self.targets = np.random.randn(n_images, n_classes)
self.transform = transform
def __getitem__(self, item):
image = self.images[item]
target = self.targets[item]
if self.transform:
image = self.transform(image)
return image, target
def __len__(self):
return len(self.images)
def worker_init_fn(worker_id):
imgaug.seed(np.random.get_state()[1][0] + worker_id)
custom_ds = CustomDataset(n_images=50, n_classes=10, transform=tfs)
custom_dl = DataLoader(custom_ds, batch_size=64,
num_workers=4, pin_memory=True,
worker_init_fn=worker_init_fn)
注意:关于num_workers在Windows系统上只能设置成0,但是当我们使用Linux远程服务器时,可能使用不同的num_workers的数量,这是我们就需要注意worker_init_fn()函数的作用了。它保证了我们使用的数据增强在num_workers>0时是对数据的增强是随机的。
3.6 使用argparse进行调参
在深度学习中时,超参数的修改和保存是非常重要的一步,尤其是当我们在服务器上跑我们的模型时,如何更方便的修改超参数是我们需要考虑的一个问题。这时候,要是有一个库或者函数可以解析我们输入的命令行参数再传入模型的超参数中该多好。到底有没有这样的一种方法呢?答案是肯定的,这个就是 Python 标准库的一部分:Argparse。那么下面让我们看看他是多么方便。通过本节课,您将会收获以下内容:argparse的简介、argparse的使用、如何使用argparse修改超参数。
3.6.1 argparse简介
argsparse是python的命令行解析的标准模块,内置于python,不需要安装。这个库可以让我们直接在命令行中就可以向程序中传入参数。我们可以使用python file.py来运行python文件。而argparse的作用就是将命令行传入的其他参数进行解析、保存和使用。在使用argparse后,我们在命令行输入的参数就可以以这种形式python file.py --lr 1e-4 --batch_size 32来完成对常见超参数的设置。
3.6.2 argparse的使用
总的来说,我们可以将argparse的使用归纳为以下三个步骤:
-
创建ArgumentParser()对象
-
调用add_argument()方法添加参数
-
使用parse_args()解析参数 在接下来的内容中,我们将以实际操作来学习argparse的使用方法。
代码如下:
# demo.py
import argparse
# 创建ArgumentParser()对象
parser = argparse.ArgumentParser()
# 添加参数
parser.add_argument('-o', '--output', action='store_true',
help="shows output")
# action = `store_true` 会将output参数记录为True
# type 规定了参数的格式
# default 规定了默认值
parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3')
parser.add_argument('--batch_size', type=int, required=True, help='input batch size')
# 使用parse_args()解析函数
args = parser.parse_args()
if args.output:
print("This is some output")
print(f"learning rate:{args.lr} ")
我们在命令行(终端)使用python demo.py --lr 3e-4 --batch_size 32,就可以看到以下的输出:

argparse的参数主要可以分为可选参数和必选参数。可选参数就跟我们的lr参数相类似,未输入的情况下会设置为默认值。必选参数就跟我们的batch_size参数相类似,当我们给参数设置required =True后,我们就必须传入该参数,否则就会报错。看到我们的输入格式后,我们可能会有这样一个疑问,我输入参数的时候不使用–可以吗?答案是肯定的,不过我们需要在设置上做出一些改变。
代码如下:
# positional.py
import argparse
# 位置参数
parser = argparse.ArgumentParser()
parser.add_argument('name')
parser.add_argument('age')
args = parser.parse_args()
print(f'{args.name} is {args.age} years old')
当我们不实用–后,将会严格按照参数位置进行解析。
结果展示:

3.6.3 更加高效使用argparse修改超参数(脚本)
每个人都有着不同的超参数管理方式,在这里我将分享我使用argparse管理超参数的方式,希望可以对大家有一些借鉴意义。通常情况下,为了使代码更加简洁和模块化,我一般会将有关超参数的操作写在config.py,然后在train.py或者其他文件导入就可以。具体的config.py可以参考如下内容。
代码如下:
import argparse
def get_options(parser=argparse.ArgumentParser()):
parser.add_argument('--workers', type=int, default=0,
help='number of data loading workers, you had better put it '
'4 times of your gpu')
parser.add_argument('--batch_size', type=int, default=4, help='input batch size, default=64')
parser.add_argument('--niter', type=int, default=10, help='number of epochs to train for, default=10')
parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3')
parser.add_argument('--seed', type=int, default=118, help="random seed")
parser.add_argument('--cuda', action='store_true', default=True, help='enables cuda')
parser.add_argument('--checkpoint_path',type=str,default='',
help='Path to load a previous trained model if not empty (default empty)')
parser.add_argument('--output',action='store_true',default=True,help="shows output")
opt = parser.parse_args()
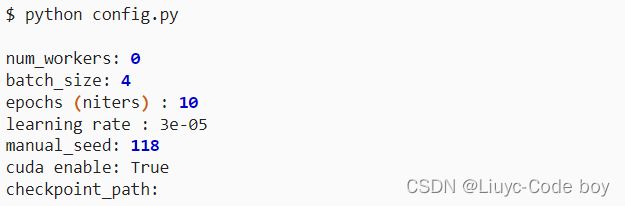
if opt.output:
print(f'num_workers: {opt.workers}')
print(f'batch_size: {opt.batch_size}')
print(f'epochs (niters) : {opt.niter}')
print(f'learning rate : {opt.lr}')
print(f'manual_seed: {opt.seed}')
print(f'cuda enable: {opt.cuda}')
print(f'checkpoint_path: {opt.checkpoint_path}')
return opt
if __name__ == '__main__':
opt = get_options()
结果展示:
随后在train.py等其他文件,我们就可以使用下面的这样的结构来调用参数。
代码如下:
# 导入必要库
...
import config
opt = config.get_options()
manual_seed = opt.seed
num_workers = opt.workers
batch_size = opt.batch_size
lr = opt.lr
niters = opt.niters
checkpoint_path = opt.checkpoint_path
# 随机数的设置,保证复现结果
def set_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
...
if __name__ == '__main__':
set_seed(manual_seed)
for epoch in range(niters):
train(model,lr,batch_size,num_workers,checkpoint_path)
val(model,lr,batch_size,num_workers,checkpoint_path)
3.6.4 关于__name__ == ‘main’
在大多数编排得好一点的脚本或者程序里面都有这段if name == ‘main’。
一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。因此if name == ‘main’: 的作用就是控制这两种情况执行代码的过程,在if name == ‘main’: 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
举个例子,下面在test.py中写入如下代码:
print ("I'm the first.")
if __name__== "__main__":
print ("I'm the second.")
结果展示:

并直接执行test.py,结果如下图,可以成功print两行字符串。即,if name==“main”: 语句之前和之后的代码都被执行。
现在我们在同一文件夹再编写一个名称为test_import.py的脚本,只输入如代码:
import test
结果如下:
![]()
只输出了第一行字符串。即,if name==“main”: 之前的语句被执行,之后的没有被执行。
**原理:**每个python模块(python文件,也就是此处的test.py和test_import.py)都包含内置的变量__name__,当运行模块被执行的时候,__name__等于文件名(包含了后缀.py);如果import到其他模块中,则__name__等于模块名称(不包含后缀.py)。而“main”等于当前执行文件的名称(包含了后缀.py)。进而当模块被直接执行时,name == 'main’结果为真。
同样举例说明,我们在test.py脚本的if name == main:之前加入print name,即将__name__打印出来。
print ("I'm the first.")
print(__name__)
if __name__== "__main__":
print ("I'm the second.")
结果展示:

可以看出,此时变量__name__的值为__main__;
再执行test_import.py,模块内容和执行结果如下:

此时,test.py中的__name__变量值为test,不满足__name__==__main__的条件,因此,无法执行其后的代码。