《机器学习》学习笔记(六)——支持向量机(SVM)
机器学习(Machine Learning)是一门多学科交叉专业,涵盖概率论知识,统计学知识以及复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式, 并将现有内容进行知识结构划分来有效提高学习效率。本专栏将以学习笔记形式对《机器学习》的重点基础知识进行总结整理,欢迎大家一起学习交流!
专栏链接:《机器学习》学习笔记
目录
1. 概述
2.感知机
3.支持向量机
3.1 引子
3.2 间隔
3.3 支持向量
3.4 对偶问题
拉格朗日乘子法
解的稀疏性
对偶方法重新求解前面的问题
3.5 核函数
3.6 软间隔与正则化
正则化
3.7 支持向量回归
支持向量回归机--SVR
损失函数
3.8 核方法
回顾总结
1. 概述
支持向量机(support vector machines, SVM)是一种二分类模型。
它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;
支持向量机还包括核技巧,这使它成为实质上的非线性分类器。
与之前学习笔记所述的分类问题不同的是:分类问题强调将不同类的样本点以一条线分隔开,而支持向量机则是强调将不同的两类样本点分隔的间隔最大。
★支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题,支持向量机的学习算法是求解凸二次规划的最优化算法。
其中,“凸”的含义为只有单极值点(一元二次函数那样),而不是有多个极值点;
“二次”含义为诸如: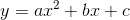 绘制的图形样式。
绘制的图形样式。
☆支持向量机学习方法包含构建由简至繁的模型:
☞线性可分支持向量机——硬间隔支持向量机(硬间隔最大化)——训练数据线性可分
 硬间隔示例图
硬间隔示例图
☞线性支持向量机——软间隔支持向量机(软间隔最大化)——训练数据近似线性可分
 软间隔示例图
软间隔示例图
☞非线性支持向量机——核技巧及软间隔最大化——训练数据线性不可分。
☆核方法是比支持向量机更为一般的机器学习方法。
2.感知机
感知机的模型就是尝试找到一条直线,能够把二元数据隔离开。
放到三维空间或者更高维的空间,感知机的模型就是尝试找到一个超平面,能够把所有的二元类别隔离开。
对于这个分离的超平面,定义为 ,如下图。
,如下图。
 感知机模型
感知机模型
在超平面上方的,我们定义为y=1;
在超平面下方的,我们定义为y=−1。
可以看出满足这个条件的超平面并不止一个。如何判断哪个超平面的分类效果更好。
接着我们看感知机模型的损失函数优化,它的思想是让所有误分类的点(定义为M)到超平面的距离和最小,即最小化下式:

当w和b成比例的增加,比如,当分子的w和b扩大N倍时,分母的L2范数也会扩大N倍。
在感知机模型中,我们采用的是保留分子,固定分母![]() ,即最终感知机模型的损失函数为:
,即最终感知机模型的损失函数为:

那么如果我们不是固定分母,改为固定分子,作为分类模型的改进问题进而引入了SVM。
3.支持向量机
3.1 引子
线性模型:在样本空间中寻找一个超平面, 将不同类别的样本分开。

-Q . 将训练样本分开的超平面可能有很多, 哪一个好呢?
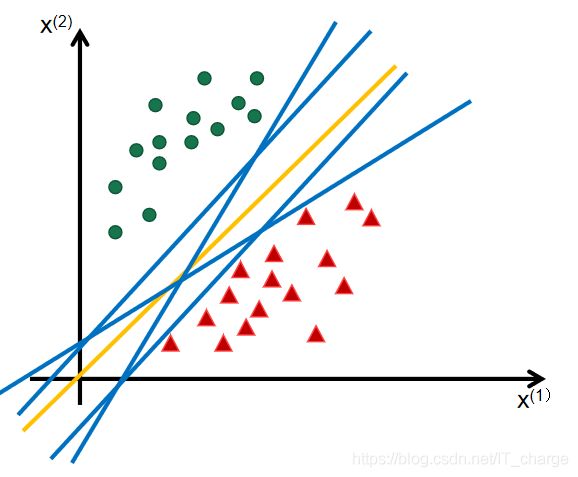
-A . 应选择”正中间”, 对局部扰动容忍性好, 鲁棒性高, 对未见示例的泛化能力最强。
在感知机模型中,可以找到多个可以分类的超平面将数据分开,并且优化时希望所有的点都离超平面远。
但是实际上离超平面很远的点已经被正确分类,让它离超平面更远并没有意义。
反而最关心是那些离超平面很近的点,这些点很容易被误分类。
如果可以让离超平面比较近的点尽可能的远离超平面,那分类效果会好有一些。
SVM的思想起源正起于此。
3.2 间隔
函数间隔是没有统一量度,没有规范化,并不能正常反应点到超平面的距离,在感知机模型里,当分子成比例的增长时,分母也是成倍增长。为了统一度量,需要对法向量w加上约束条件,这样就得到了几何间隔  , 定义为:
, 定义为:
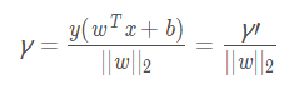
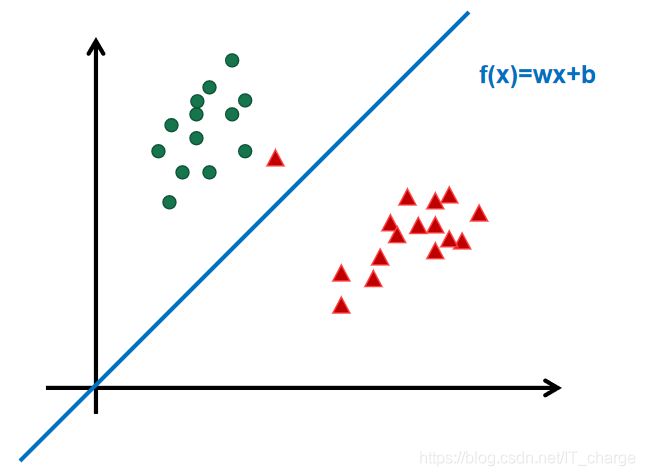
在样本空间中,划分超平面可通过如下线性方程来描述:
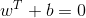
其中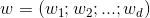 为法向量,决定了超平面的方向;
为法向量,决定了超平面的方向;
 为位移项,决定了超平面与原点之间的距离。
为位移项,决定了超平面与原点之间的距离。
划分超平面可被法向量 和位移确定,并将其记为
和位移确定,并将其记为![]() 。
。
样本空间中任意点 到超平面
到超平面![]() 的距离可写为
的距离可写为
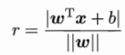
假设超平面![]() 能将训练样本正确分类,即对于
能将训练样本正确分类,即对于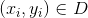
若 ,则有
,则有![]() ;
;
若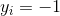 ,则有
,则有![]() 。令
。令
![]()
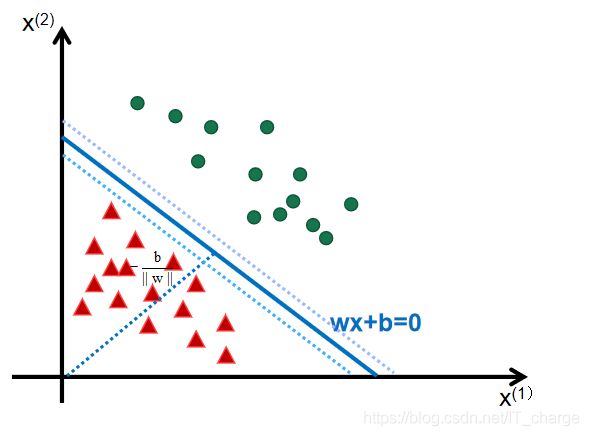
如下图所示,距离超平面最近的这几个训练样本点使上式等号成立,他们被称为“支持向量”
两个异类支持向量到超平面的的距离之和为
![]()
它被称为“间隔”。
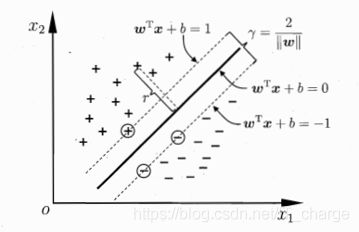 支持向量与间隔
支持向量与间隔
欲找到具有“最大间隔”的划分超平面,也就是要找到能满足式![]() 中约束的参数和,使得最大,即
中约束的参数和,使得最大,即
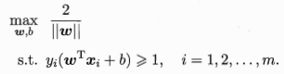
显然,为了最大化间隔,仅需最大化![]() ,这等价于最小化
,这等价于最小化![]() ,于是上式可写成
,于是上式可写成
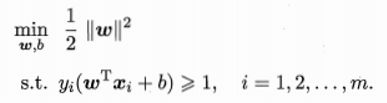
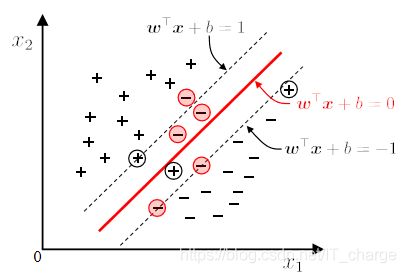
这就是支持向量机(SVM)的基本型。 ★★★
3.3 支持向量
如下图所示,分离超平面为 ,如果所有的样本不光可以被超平面分开,还和超平面保持一定的函数距离(下图函数距离为1),那么这样的分类超平面是比感知机的分类超平面优的。
可以证明,这样的超平面只有一个。
和超平面平行的保持一定的函数距离的这两个超平面对应的向量,我们定义为支持向量,如下图虚线所示。 
★超平面方程:![]()
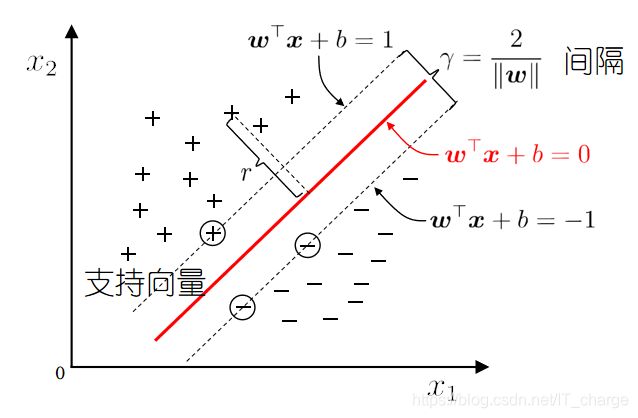
★最大间隔: 寻找参数 和
和![]() , 使得
, 使得![]() 最大.
最大.
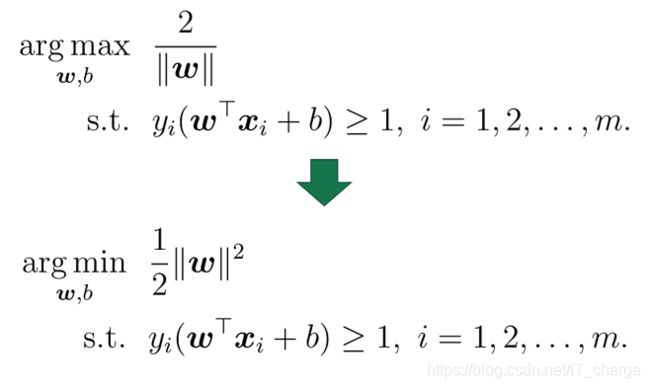
3.4 对偶问题

其中f(x)是目标函数,g(x)为不等式约束,h(x)为等式约束。
若f(x),h(x),g(x)三个函数都是线性函数,则该优化问题称为线性规划。
若任意一个是非线性函数,则称为非线性规划。
若目标函数为二次函数,约束全为线性函数,称为二次规划。
若f(x)为凸函数,g(x)为凸函数,h(x)为线性函数,则该问题称为凸优化。
注意这里不等式约束g(x)<=0则要求g(x)为凸函数,若g(x)>=0则要求g(x)为凹函数。
凸优化的任一局部极值点也是全局极值点,局部最优也是全局最优。
对于稍前所述的公式(SVM的基本型)
与
使用拉格朗日乘子法可得到其“对偶问题”
对上式的每条约束添加拉格朗日乘子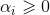 ,该问题的拉格朗日函数可写为:
,该问题的拉格朗日函数可写为:
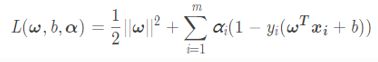
我们希望求解SVM的基本型公式来得到大间隔划分超平面所对应的模型
![]()
其中和是模型参数。
注意到SVM的基本型是一个凸二次规划问题。能直接用现成的优化计算包求解,但我们又更高效的办法。
拉格朗日乘子法
第一步:引入拉格朗日乘子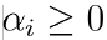 得到拉格朗日函数
得到拉格朗日函数
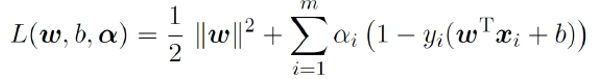
即

第二步:令![]() 对和的偏导为零可得
对和的偏导为零可得

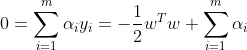
第三步:回代可得
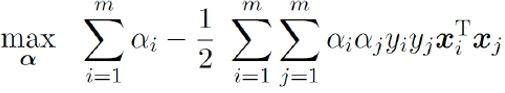
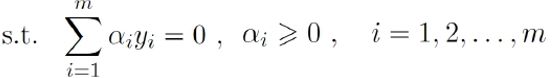
不难发现,这是一个二次规划问题。
然而,该问题的规模正比于训练样本数,这会在实际任务中造成很大的开销。
为了避开这个方案,人们提出了很多高效算法,SMO是其中一个著名的代表。
解的稀疏性
求出和后,可得最终模型:
![]()
KKT条件:

对任意样本 ,总有
,总有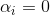 或
或![]() 。
。
若,则该样本将不会在式![]() 的求和中出现,也就不会对f(x)有任何影响;
的求和中出现,也就不会对f(x)有任何影响;
若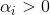 ,则必有
,则必有![]() ,所对应的样本点位于最大间隔边界上,是一个支持向量。
,所对应的样本点位于最大间隔边界上,是一个支持向量。
支持向量机解的稀疏性: 训练完成后, 大部分的训练样本都不需保留, 最终模型仅与支持向量有关。
重要性质:模型训练完后,大部分的训练样本都不需要保留,最终模型仅仅与支持向量有关。
对偶方法重新求解前面的问题
如下图所示的训练数据集,其正实例点是![]() ,
,![]() ,负实例点是
,负实例点是![]()
试求其线性可分的支持向量机。

解:正实例点是![]() ,
,![]()
负实例点是![]()
根据SVM的基本型
可得:
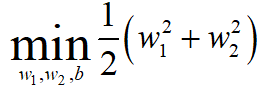
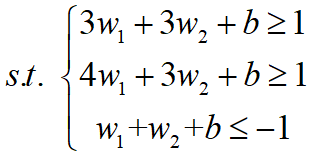
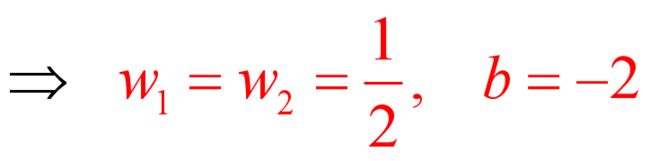
第一步:转化为对偶问题
由拉格朗日乘子法
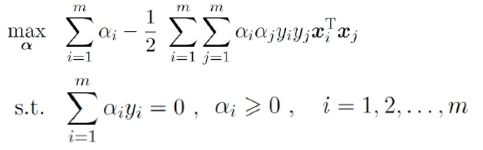
可得(求最小化问题添负号,三个样本故m=3,正样本y=+1,负样本y=-1)
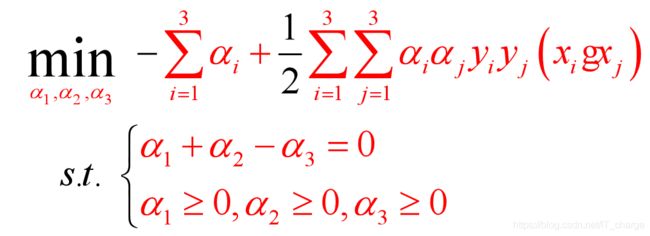
即

注:这里赘述一点关于上式中的难点推导:
已知正样本1:![]()
正样本2:![]()
负样本 :![]()
那么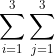 是将样本全部遍历一遍
是将样本全部遍历一遍
当i=1,j=1时:
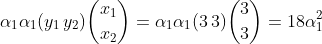
就这样将i=1,2,3和y=1,2,3两两组合共九种情况结果相加即可
算时唯一一点要注意的是负样本的取值前要添加负号!
第二步:代入约束条件
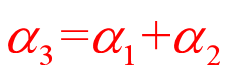
目标函数变形为:

接下来分别对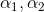 求偏导
求偏导

令上两式均等于0
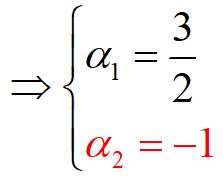
由于![]() ,不满足KKT条件第一条,故不符合要求,从而最小值在边界达到;
,不满足KKT条件第一条,故不符合要求,从而最小值在边界达到;
第三步:利用KKT条件,计算向量
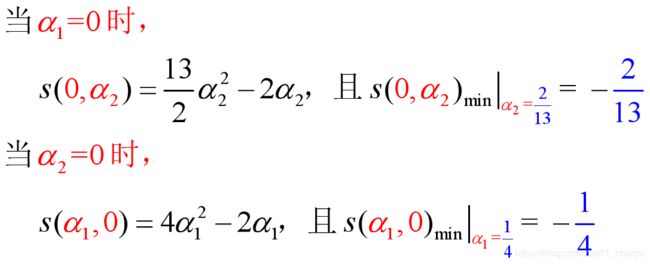
又由于![]()

根据公式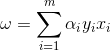 可得:
可得:
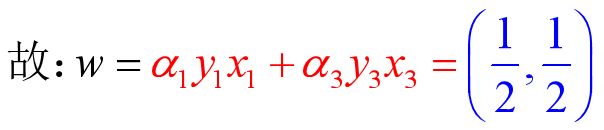
对上式计算具体而言,![]()
第四步:利用KKT条件,计算b




如果样本变多,人工计算不现实,需要一种高效的计算算法。
3.5 核函数
线性不可分
-Q:若不存在一个能正确划分两类样本的超平面, 怎么办?
-A:将样本从原始空间映射到一个更高维的特征空间, 使得样本在这个特征空间内线性可分.
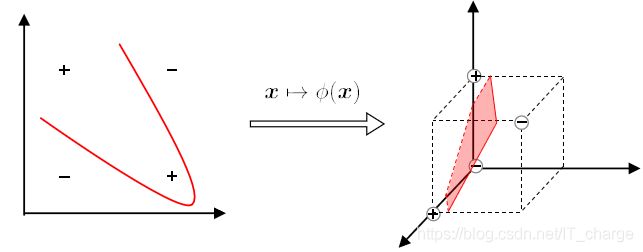
核支持向量机
设样本映射后的向量为 , 划分超平面
, 划分超平面![]()
原始问题 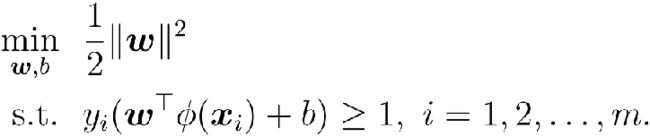
对偶问题 
预测 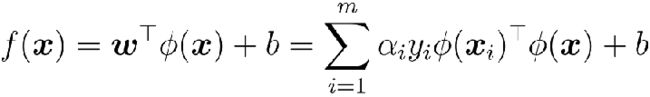
核函数
基本想法:不显式地设计核映射, 而是设计核函数.

Mercer定理(充分非必要):只要一个对称函数所对应的核矩阵半正定, 则它就能作为核函数来使用.
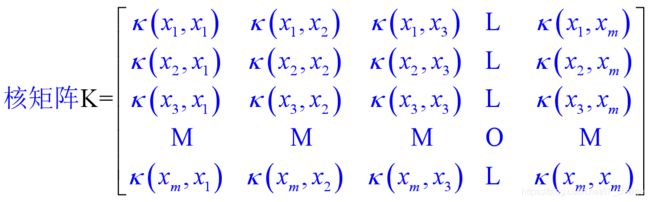

核函数的注意事项:
核函数选择成为svm的最大变数
经验:文本数据使用线性核,情况不明使用高斯核
核函数的性质:
- 1 核函数的线性组合仍为核函数
- 2 核函数的直积仍为核函数

- 3 设
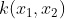 为核函数,则对于任意函数g
为核函数,则对于任意函数g
3.6 软间隔与正则化
软间隔
-Q:现实中, 很难确定合适的核函数使得训练样本在特征空间中线性可分; 同时一个线性可分的结果也很难断定是否是有过拟合造成的.
-A:引入”软间隔”的概念, 允许支持向量机在一些样本上不满足约束.
0/1损失函数
基本想法:最大化间隔的同时, 让不满足约束的样本应尽可能少.
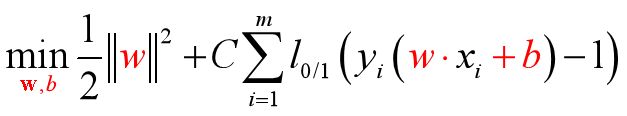
正则化常数C>0,如果C→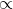 ,则等价于要求所有的样本点都分类正确,否则就允许一部分极少的样本分类错误
,则等价于要求所有的样本点都分类正确,否则就允许一部分极少的样本分类错误
其中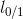 是”0/1损失函数”
是”0/1损失函数”

存在的问题:0/1损失函数非凸、非连续, 不易优化!
替代损失

软间隔支持向量机
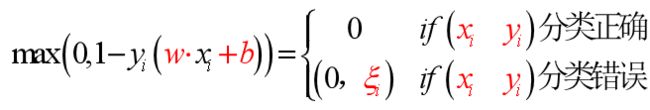
原始问题
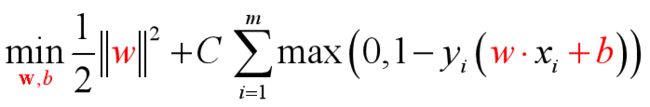
引入“松弛变量”
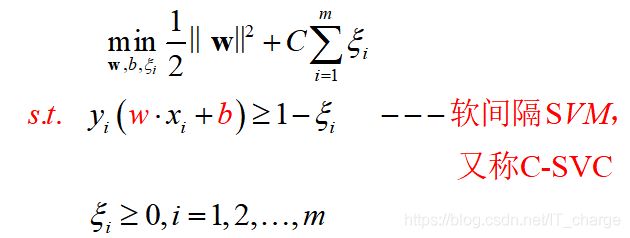
注:每一个样本都对应一个松弛变量,用以表征该样本不满足约束![]() 的程度。
的程度。
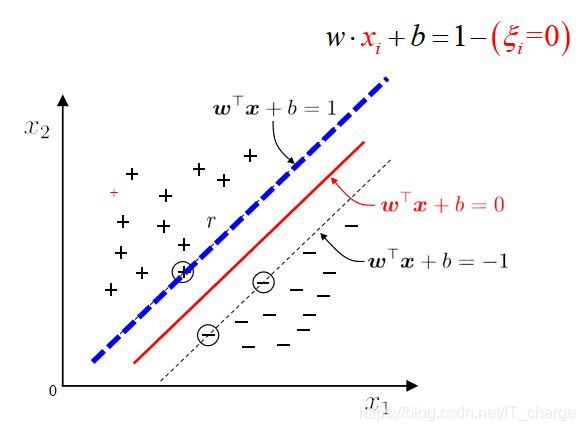
软间隔与松弛向量
超平面方程:![]()

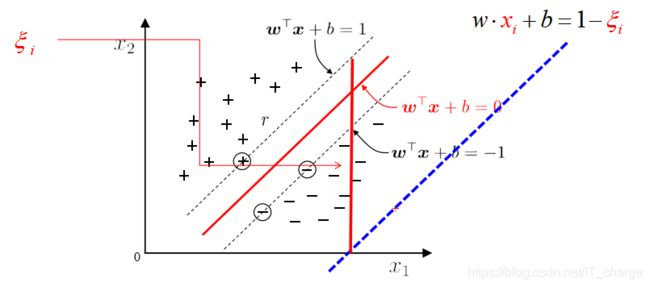
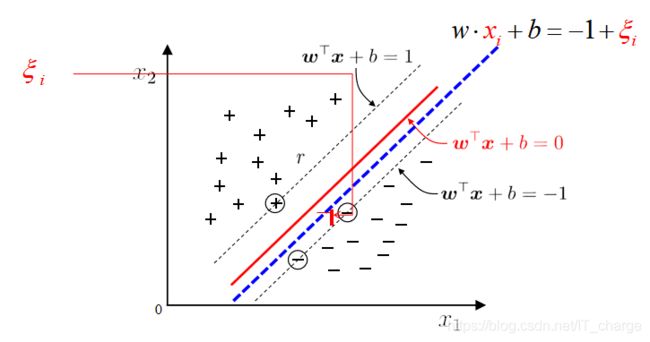

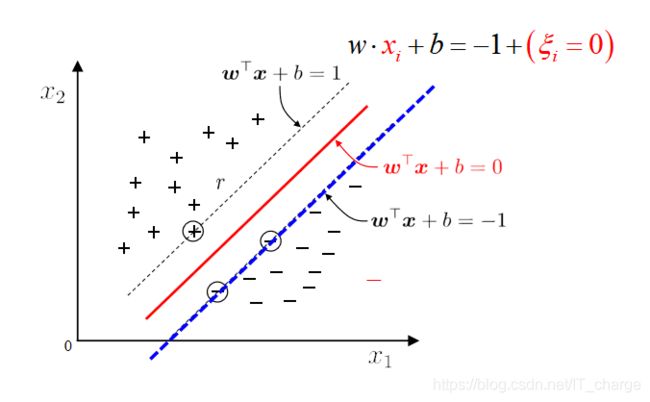
求解软间隔问题:
构造Lagrange 函数
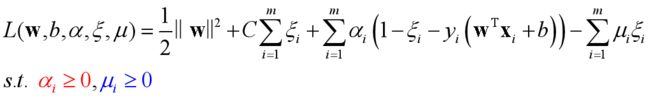
分别对变量求导,并令其为0,得到
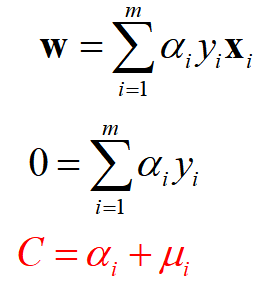
原始问题

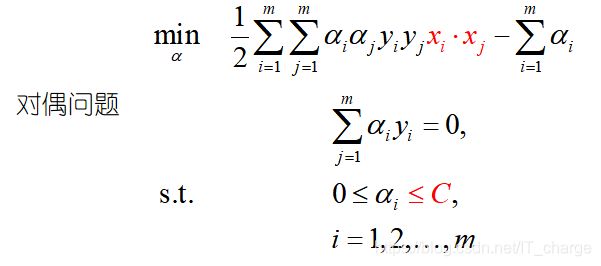
根据KKT条件可推得最终模型仅与支持向量有关, 也即hinge损失函数依然保持了支持向量机解的稀疏性.
软间隔支持向量机KKT条件


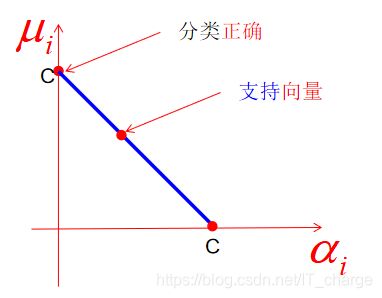
★软间隔支持向量机有稀疏性
正则化
支持向量机学习模型的更一般形式

通过替换上面两个部分, 可以得到许多其他学习模型:对数几率回归(Logistic Regression)、最小绝对收缩选择算子(LASSO) ……
3.7 支持向量回归
支持向量回归机--SVR
对于有限个样本组成的训练集来说,一定存在一个带状区域包含所有的样本点。并且这样的带状区域有无穷多个,宽度最小的带状区域才是我们关心的。

当带状区域很大,所得的回归模型不精确,此时允许模型输出和实际输出间存在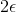 的偏差.
的偏差.
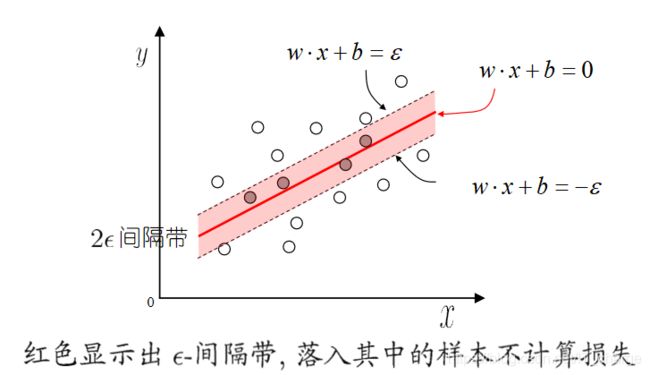
损失函数
落入中间间隔带的样本不计算损失, 从而使得模型获得稀疏性.
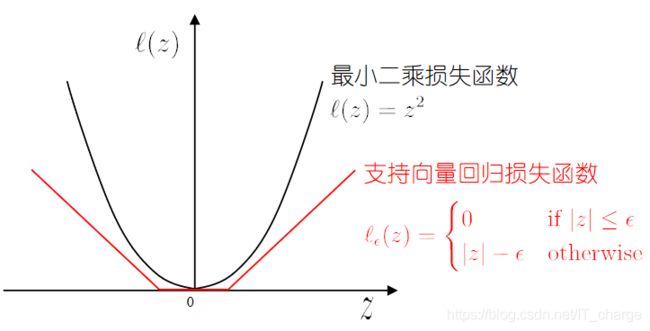
★支持向量分类支持向量在线上面
支持向量回归支持向量在线外面
3.8 核方法
表示定理

结论: 无论是支持向量机还是支持向量回归, 学得的模型总可以表示成核函数的线性组合.
更一般的结论(表示定理): 对于任意单调增函数 和任意非负损失函数, 优化问题
和任意非负损失函数, 优化问题

的解总可以写为
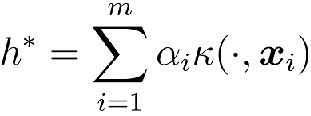
核线性判别分析
通过表示定理可以得到很多线性模型的”核化”版本
- 核SVM
- 核LDA
- 核PCA
- ……
核LDA: 先将样本映射到高维特征空间, 然后在此特征空间中做线性判别分析
 .
.
回顾总结
- 支持向量机的”最大间隔”思想
- 对偶问题及其解的稀疏性
- 通过向高维空间映射解决线性不可分的问题
- 引入”软间隔”缓解特征空间中线性不可分的问题
- 将支持向量的思想应用到回归问题上得到支持向量回归
- 将核方法推广到其他学习模型
欢迎留言,一起学习交流~~~
感谢阅读