【语义分割semantic segmentation】--DeepLab(ASPP)系列学习笔记
关键问题概要:
像素级稠密预测任务中为提高感受野通常采用池化采样降低分辨率,容易丢失关键信息;
必要的多尺度特征提取能力有助于对场景中不同尺寸大小的物体信息进行捕获,提高特征表现能力;
DCNNS对局部图像转换的内置不变性有助于学习日益抽象的数据表示。这种不变性对分类认为是可取的,但会阻碍密集的预测任务。
DeepLabV1&V2
DeepLabv1: Semantic Image Segmentation with Deep Convolutional Nets, and Fully Connected CRFs
DeepLabv2: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
DeepLabv1首次提出了‘atrous’ algorithm,其实就是膨胀卷积的实现,本文不再赘述。DeepLabv2首次提出了Atrous Convolution和ASPP,将最终DCNN层的响应与全连接条件随机场(CRF)相结合来提高目标边界定位性能。
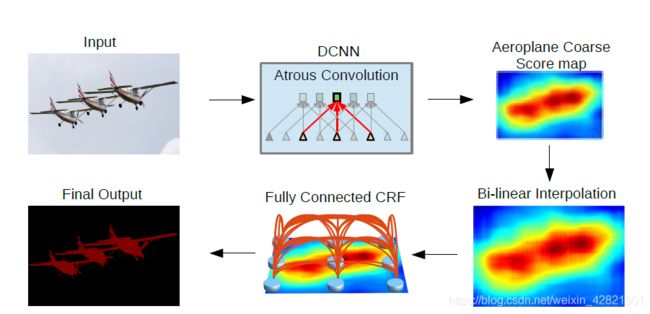
将DCNN应用到语义图像分割中的三个挑战:(1)降低特征分辨率,(2)多尺度上目标的存在,以及(3)由于DCNN的不变性导致定位精度降低。
deeplab的解决思想:使用深度卷积神经网络,如VGG-16或ResNet-101,以完全卷积的方式使用,使用atrous卷积来降低信号下采样的程度(从32x降到8x)。双线性插值阶段扩大特征映射到原始图像的分辨率。然后,应用全连接CRF来细化分割结果,更好地捕捉对象边界。
空洞卷积Atrous Convolution
如何扩大感受野是卷积神经网络在多个应用场景中的一项重要目标,通常的做法是连续的池化采样,得到抽象的低分辨特征图,然后通过线性插值或反卷积等上采样手段恢复分辨率,这个过程难免会造成一些信息的丢失。使用更大的卷积核或多个小卷积核的串行叠加固然可以也提高感受野,但其中参数量的增加是不可忽视的。
(Atrous convolution/dilated convolution)明确的控制输出特征图分辨率并提高感受野,在不增加参数量和复杂度的前提下捕获更大尺寸的场景信息。
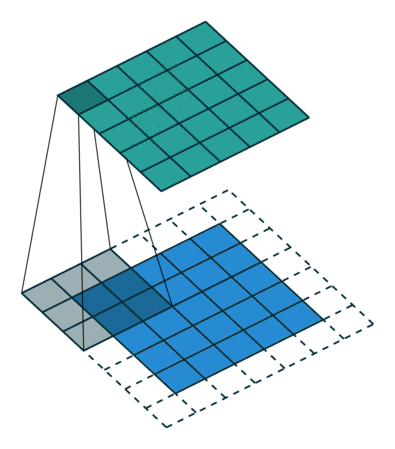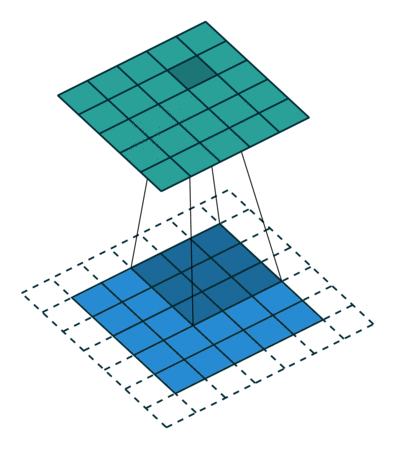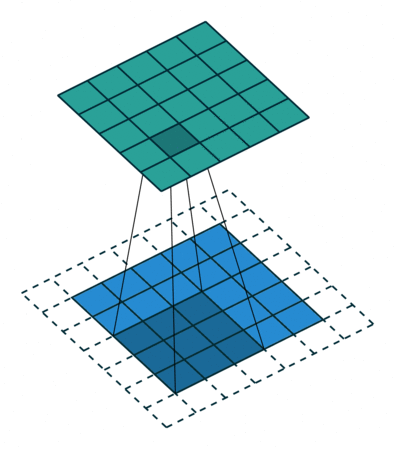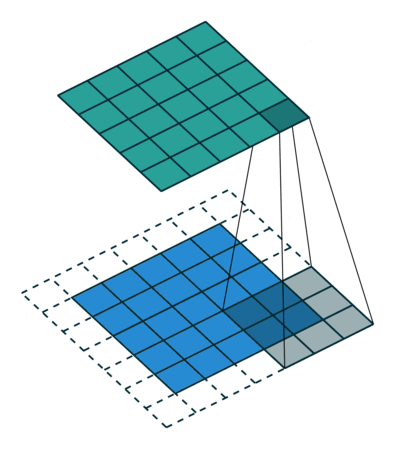
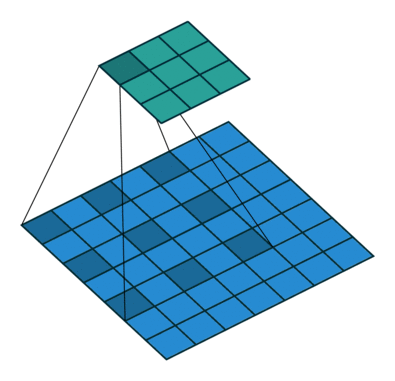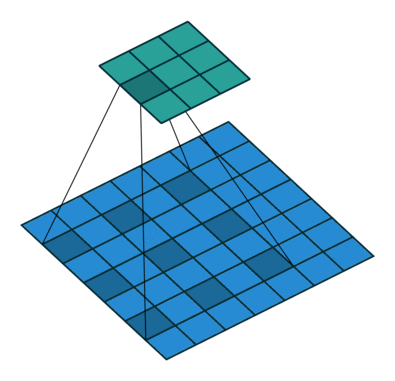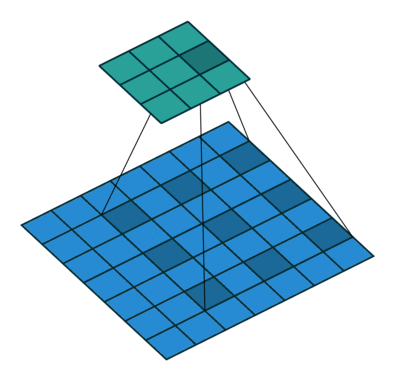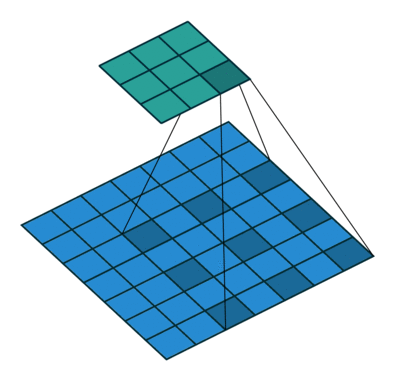
如上图所示,一个普通的3×3的卷积核,可以理解为dilation rate(膨胀率) =1时的空洞卷积,作为空洞卷积的一个特殊形式;而dliation rate = 2的空洞卷积是在普通的3×3的卷积核的基础上,通过在该卷积核九个采样点的周围增加权重为0的空洞点,来将一个3×3的卷积核等同扩张为5×5的卷积核,增大了感受野。
这样的设置下虽然卷积核的感受野扩大了,但是采样点仍然是9个,参数量并未增加;同时通过Atrous Convolution可针对不同需要调整超参数,控制卷积核大小和输出特征图大小,避免下采样和上采样过程。
空洞空间卷积池化金字塔(Atrous spatial pyramid pooling)
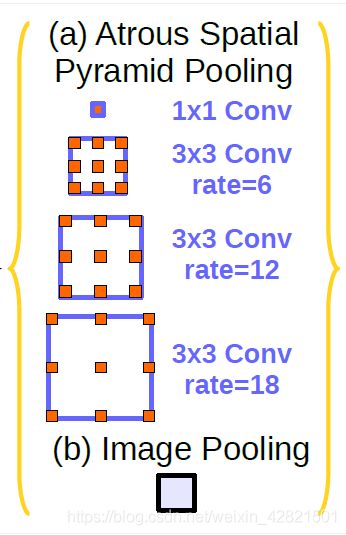
针对场景中多尺度特征的提取需要,deeplab提出了一种得到广泛应用的结构:空洞空间卷积池化金字塔。

如上图所示,该结构使用不同膨胀率的多个并行Atrous Convolution,对每个Atrous Convolution提取的特征在单独的分支中进一步处理,并融合生成最终结果。
上述结构的的pytorch实现代码如下:
class ASPP(nn.Module):
def __init__(self, in_channel=64, depth=32):
super(ASPP, self).__init__()
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.atrous_block24 = nn.Conv2d(in_channel, depth, 3, 1, padding=24, dilation=24)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
atrous_block24 = self.atrous_block24(x)
net = self.conv_1x1_output(torch.cat([atrous_block6,atrous_block12,
atrous_block18,atrous_block24], dim=1))
return net
输入的特征图会被并行输入到四个不同膨胀率的Atrous Convolution中,得到的特征图通过concatenation操作重新联结为一幅特征图,并通过一个1×1卷积融合特征得到输出。
DeepLabV3
DeepLabv3: Rethinking Atrous Convolution for Semantic Image Segmentation
DeepLabv3主要改进了ASPP模块,以Atrous Convolution为基础提出了更多
(1)级联空洞卷积模块

该模块复制了ResNet的最后几个block,并将它们级联排列,其结构类似于原来的ResNet。引入该模型的动机是为了在较深的block中更容易地捕获远距离信息。
(2)改进的ASPP模块
文中的实验讨论了一种现象:由于边缘效应的影响(大的膨胀率下padding随之增加),当采样率变大时,卷积核有效权重的数量(即应用于有效特征区域的权重,而不是填充的零)会变小,即卷积核有效性退化。
为了克服上述问题,并将全局上下文信息整合到模型中,在ASPP中采用了图像级特征,使用全局平均池化得到图像级全局特征,并上采样恢复原有分辨率。
上图在pytorch中的实现代码如下:
class ASPP(nn.Module):
def __init__(self, in_channel=6, depth=16):
super(ASPP, self).__init__()
self.mean = nn.AdaptiveAvgPool2d((1, 1))
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net
与deeplabv2中的ASPP相比,输入的特征图不但会由4个膨胀率分别为1,6,12,18的卷积核并行处理,也会输入到一个“池化-上采样”模块中生成image_features,进一步融合到输出的特征图中。
(3)网络整体框架

deeplabv3的整体网络框架中去除了CRF,模块化的设计让整体的通用性变强,可以修改应用至多个应用场景的网络中。
DeepLabV3+
DeepLabv3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
空间金字塔池化模块(spp)能够使用不同采样率的卷积核和池化操作编码多尺度的上下文信息,而编码-解码结构(encoder-decoder)能够通过逐渐恢复空间信息来捕捉更清晰的物体边界信息。

DeepLabv3+中以DeepLabv3的ASPP模块作为编码器, 并设计了额外的解码器恢复特征信息。Decoder中首先将Encoder模块中的输出进行上采样,然后从DCNN的网络过程中输出分辨率一致的特层次特征图low-level features ,该低层次特征经过1×1的卷积层调整通道数使之与Encoder的输出一致,然后concatenation到一起,通过3×3的卷积层和上采样获得最终预测结果。