Pandas知识点-读写Excel最全参数总结(收藏)
Pandas知识点-读写Excel最全参数总结(收藏)
pandas文件读写工具汇总
pandas中的文件读写工具由一组read的函数(执行Input)和一组write的对象方法(执行Output)组成,具体见下表。
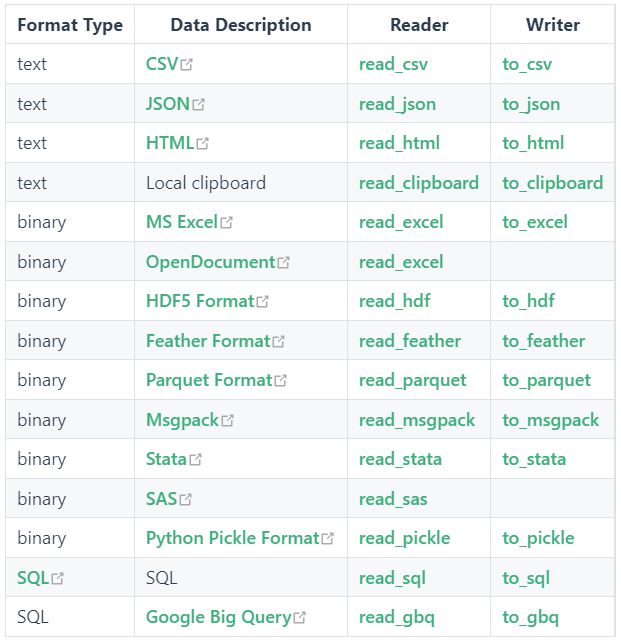
本文总结最常用的三组读写工具的所有参数用法,read_excel()和DataFrame.to_excel()、read_csv()和DataFrame.to_csv()、read_json()和DataFrame.to_json()。
read_excel()参数总结
read_excel():
- io: 字符串、字节、ExcelFile、xlrd.Book、路径对象或file-like对象。
任何有效的字符串路径都可以接受,字符串可以是一个URL,有效的URL格式包括http、ftp、s3和file,对于文件URL,最好有个主机地址,例如一个本地文件可以是file://localhost/path/to/table.xlsx这样的格式。
如果传递的是路径对象,则Pandas接受所有os.Pathlike对象。
通过file-like对象,可以引用具有read()方法的对象,例如文件处理(如内置函数open()函数)或StringIO。- sheet_name: 字符串、整数、列表、None,默认值0。
字符串用表格(sheet页)名称。整数用从0开始的表格索引(图表chart sheet不计算)。字符串/整数的列表用于获取多张表格。设置为None可获取所有表格(sheet页)。
示例:
0(默认): 将第一个sheet页读为一个DataFrame。
1: 将第二个sheet页读为一个DataFrame。
‘Sheet1’: 将名称为Sheet1的sheet页读为一个DataFrame。
[0, 1, ‘Sheet5’]: 将第一个、第二个和名称为Sheet5的sheet页读为一个DataFrame组成的字典。
None: 将所有sheet页读为一个DataFrame组成的字典。- header: 整数或整数组成的列表,默认值0。
用作DataFrame的列名的行(通过0开始的行索引选一行),如果用整数列表指定多个行,则组合为MultiIndex。如果没有header,则设置为None。- names: array-like,默认值None。
指定列名的列表,如果数据文件中不包含列名,通过names指定列名,同时应该设置header=None。names中不允许有重复值。- indexl_col: 整数或整数组成的列表,默认值None。
设置DataFrame的行索引(通过0开始的列索引选一列),如果用整数列表指定多个列,则组合为MultiIndex。如果没有用作行索引的列,则设置为None。如果使用usecols选择了数据的子集,则indexl_col将基于这个子集。- usecols: 字符串、list-like、可调用对象,默认值None。
None: 解析所有列。
字符串:解析以逗号分隔的Excel列字母和列范围。例如“A:E”或“A,C,E:F”,E:F这种范围包括两端的列。
整数列表:解析列表中索引编号的列。
字符串列表:解析列表中指定列名的列。
可调用对象:根据可调用对象(如函数)判断每个列名,如果返回True,则解析该列。
使用usecols可以大大加快解析时间并降低内存使用率。- squeeze: 布尔值,默认值False。
如果解析的数据仅包含一个列,那么结果将以Series的形式返回。
1.4.0版本后已弃用。- dtype: 类型名,或列名和类型名组成的字典,默认值None。
指定部分列或整体数据的数据类型,如{‘a’: np.float64, ‘b’: np.int32}。- engine: 字符串,默认值None。
支持的引擎:xlrd, openpyxl, odf, pyxlsb。
xlrd: 支持旧式Excel文件(.xls扩展名)。
openpyxl: 支持最新的Excel文件格式(.xlsx)。
odf: 支持OpenDocument文件格式(.odf, .ods, .odt)。
pyxlsb: 支持二进制excel文件。- converters: 字典,默认值None。
列和转换函数构成的字典,keys可以是列索引或列名,values是接收一个参数(Excel单元格内容)并返回已转换内容的函数。- true_values: 列表,默认值None。考虑为True的值。
- false_values: 列表,默认值None。考虑为False的值。
- skiprows: list-like、整数、可调用对象,可选。
要跳过的行索引列表或文件开头要跳过的行数(int)。
可以传入可调用函数,函数将行索引作为参数传入,跳过返回计算结果为True的行,如skiprows=lambda x: x in [0, 2]。- nrows: 整数,默认值None。每次读取的行数,适用于读取大文件的片段。
- na_values: 标量、字符串、list-like、字典,默认值None。
识别为NaN的其他字符串,指定某些值为空值。
默认情况下,以下值被解析为空值:‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’。 - keep_default_na: 布尔值,默认值True。
在解析数据时是否包括默认的空值。根据是否传入na_values,分为如下四种情况:
如果keep_default_na为True,并且指定na_values,则会将na_values指定的值和默认的NaN值解析为空值。
如果keep_default_na为True,并且未指定na_values,则只将默认的NaN值解析为空值。
如果keep_default_na为False,并且指定na_values,则只将na_values指定的值解析为空值。
如果keep_default_na为False,并且未指定na_values,则不会将任何字符串解析为空值。
注意,如果na_filter传入为False,则keep_default_na和na_values参数将被忽略。- na_filter: 布尔值,默认值True。
检测缺失值(默认的NaN和na_values指定的值)。在没有NaN的数据中,设置na_filter=False可以提高读取大文件的性能。- verbose: 布尔值,默认值False。指定放在非数字列中的NaN值的数量。
- parse_dates: 布尔值、list-like、字典,默认值False。
布尔值如果为True,尝试将索引当成日期解析。
整数或列名的列表,例如[1, 2, 3]尝试将1,2,3列分别作为单独的日期列进行解析。
嵌套列表,例如[[1, 3]]将第一列和第三列合并解析为一个日期列。
字典,例如{‘foo’: [1, 3]},将第一列和第三列解析为日期,并且合并成一列将列名重命名为foo。
如果列或索引包含不可解析的日期,则整个列或索引将作为对象数据类型返回,不会被更改。
如果不希望将某些单元格解析为日期,只需将它们在Excel中的类型修改为“文本”。
对于非标准的datetime解析,在pd.read_excel之后使用pd.to_datetime。- date_parser: 函数,可选。
用于将字符串列转换为datetime实例的函数,默认使用dateutil.parser.parser进行转换。
pandas将尝试以三种不同的方式调用date_parser,如果发生异常则前进到下一种方式:
- 将一个或多个数组(由date_parser定义)作为参数传递。
- 将date_parser定义的列中的字符串值(按行)连接起来存到一个数组中,并传递该数组。
- 使用一个或多个字符串(对应于date_parser定义的列)作为参数为每行调用一次date_parser。
- thousands: 字符串,默认值None。
千分位符。注意,此参数仅对Excel中存储为TEXT的列必须,其他任何数值列都会自动解析,无论显示格式如何。- decimal: 字符串,默认’.'。
识别为小数点的字符。注意,此参数仅对Excel中存储为TEXT的列必须,其他任何数值列都会自动解析,无论显示格式如何。- comment: 字符串,默认值None。
设置注释符号,注释掉行的其余内容。将一个或多个字符串传递给此参数以在输入文件中指示注释。注释字符串与当前行结尾之间的任何数据都将被忽略。- skipfooter: 整数,默认值0。设置文件底部要忽略的行数。
- convert_float: 布尔值,默认值True。
将浮点整数转换为整数(如1.0 -> 1)。如果为False,则所有数字数据将被读取为浮点数,Excel将所有数字存储为内部浮点数。
1.3.0版本后已弃用。- mangle_dupe_cols: 布尔值,默认值True。
当列名有重复时,将列名解析为‘X’, ‘X.1’, …’X.N’。如果该参数为False,那么当列名中有重复时,前列会被后列覆盖。
1.5.0版本后已弃用。- storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
to_excel()参数总结
DataFrame.to_excel():
- excel_writer: path-like、file-like、ExcelWriter对象。
文件路径或已有的ExcelWriter对象。- sheet_name: 字符串,默认值’Sheet1’。
即将写入DataFrame数据的sheet页名称。- na_rep: 字符串,默认值’'(空字符)。缺失值表示方式。
- float_format: 字符串,可选。
设置字符串格式化输出时浮点数的小数位数。如float_format=‘%.2f’。- columns: 字符串序列或字符串列表,可选。要写入的列。
- header: 布尔值或字符串列表,默认值True。
写入列名称。如果传入一个字符串列表,则设置为列的列名。- index: 布尔值,默认值True。
写入数据时会将行名称(索引)写入。- index_label: 字符串或序列,可选。
索引列的列标签(如果需要)。如果没有设置,并且header和index参数为True,则使用索引的names。如果使用MultiIndex,则应传入一个序列。- startrow: 整数,默认值0。存储DataFrame时,设置左上方单元格的行。
- startcol: 整数,默认值0。存储DataFrame时,设置左上方单元格的列。
- engine: 字符串,可选。
写入时使用的引擎,openpyxl或xlsxwriter,可以通过io.excel.xlsx.writer, io.excel.xls.writer和io.excel.xlsm.write设置。
1.2.0版本后已弃用。- merge_cells: 布尔值,默认值True。
将MultiIndex和分层行写为合并单元格。- encoding: 字符串,可选。
设置写入excel文件的编码。仅xlsxwriter有必要设置此参数,其他writer本身就支持unicode。
1.5.0版本后已弃用。- inf_rep: 字符串,默认值’inf’。
无穷大的表示方式(在Excel中没有无穷大的原始表示)。- verbose: 布尔值,默认值True。
在错误日志中显示更多信息。
1.5.0版本后已弃用。- freeze_panes: 整数组成的元组,长度为2,可选。
指定要冻结单元格的最下方行和最右侧列。- storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
read_csv()参数总结
read_csv():
- filepath_or_buffer: 字符串、路径对象、file-like对象,必填。
任何有效的字符串路径都可以接受,字符串可以是一个URL。有效的URL格式包括http、ftp、s3和file,对于文件URL,最好有个主机地址,例如一个本地文件可以是file://localhost/path/to/table.csv这样的格式。
如果传递路径对象,则pandas接受所有os.Pathlike对象。
通过file-like对象,可以引用具有read()方法的对象,例如文件处理(如内置函数open()函数)或StringIO。- sep: 字符串,默认值’,‘。分隔符,read_csv()默认分隔符为’,'。
- delimiter: 字符串,默认值None。sep的替代参数。
- delim_whitespace: 布尔值,默认值False。
指定是否将空格(如’ ‘或‘\t’)当作delimiter,等价于设置sep=’\s+'。如果这个选项被设置为True,就不要给delimiter传参了。- header: 整数或整数组成的列表、None,默认值’infer’。
将某一行或几行设置成列名,默认’infer’,自动推导。当设置为默认值或header=0时,将首行设为列名。
如果列名(names参数)传入指定值时要设置header=0或默认值。当header=0时,传入的列名会覆盖header=0取到的列名。
header可以用整数构成的列表指定多行,这样结果的列名就是多重索引MultiIndex,例如[1, 2, 3]。
如果指定的多个行中间跳过了某些行,则读取数据时跳过的行不会读取出来。如[0, 1, 3]跳过了索引2的行,读取的数据中也没有索引2这行的数据。
注意,如果skip_blank_lines=True,此参数将忽略空行和注释行,header=0表示第一行数据而非文件的第一行。- names: array-like,可选。
指定列名的列表,如果数据文件中不包含列名,通过names指定列名,那么应该设置header=None。列名列表中不允许有重复值。- index_col: 整数、字符串、整数/字符串组成的列表,False,默认值None,可选。
设置DataFrame的行索引,可以是数字或字符串(通过列名选一列作为行索引),默认None(行索引为整数索引,False也一样)。
如果传入一个字符串列表/整数列表,则组合为MultiIndex。- usecols: list-like或可调用对象,可选。
返回指定列的数据,用list-like的方式传入,即使只取一列数据也用列表,默认None,返回所有列的数据。
列表中可以是列名或列索引(但不能两者混合),列名的列表构成所有列的一个子集,列表中的元素顺序可以忽略,usecols=[0, 1]等价于usecols=[1, 0]。
如果想实例化一个自定义列顺序的DataFrame,可以使用pd.read_csv(data, usecols=[‘foo’, ‘bar’])[[‘foo’, ‘bar’]],这样列的顺序为[‘foo’, ‘bar’]。
usecols也可以传入函数,函数将根据列名计算,返回计算结果为True的列名,如usecols=lambda x: x.upper() in [‘AAA’, ‘BBB’, ‘DDD’]。
使用usecols可以加快解析时间并降低内存使用率。- squeeze: 布尔值,默认值False。
如果解析的数据仅包含一个列,那么结果将以Series的形式返回,默认False。
1.4.0版本后已弃用。- prefix: 字符串,可选。
当没有header时,可通过该参数为数字列名添加前缀,默认None。
1.4.0版本后已弃用。- mangle_dupe_cols: 布尔值,默认值True。
当列名有重复时,将列名解析为‘X’, ‘X.1’, …’X.N’。如果该参数为False,那么当列名中有重复时,前列会被后列覆盖。
1.5.0版本后已弃用。- dtype: 类型名,或列名和类型名组成的字典,默认值None。
指定部分列或整体数据的数据类型,如{‘a’: np.float64, ‘b’: np.int32}。
1.5.0版本新增。- engine: {‘c’, ‘python’, ‘pyarrow’},可选。
使用的解析引擎。C引擎的速度更快,python引擎的功能更完备。多线程目前仅支持pyarrow引擎。
1.4.0版本新增。- converters: 字典,可选。
列和转换函数构成的字典,keys可以是列索引或列名,values是接收一个参数并返回已转换内容的函数。- true_values: 列表,可选。考虑为True的值。
- false_values: 列表,可选。考虑为False的值。
- skipinitialspace: 布尔值,默认值False。在分隔符之后跳过空格。
- skiprows: list-like、整数、可调用对象,可选。
要跳过的行索引列表或文件开头要跳过的行数(int)。
可以传入可调用函数,函数将行索引作为参数传入,跳过返回计算结果为True的行,如skiprows=lambda x: x in [0, 2]。- skipfooter: 整数,默认值0。设置文件底部要忽略的行数。
- nrows: 整数,默认值None。每次读取的行数,适用于读取大文件的片段。
- low_memory: 布尔值,默认值True。
在处理数据时,解析时内存利用率降低,可能是混合类型推理。如果确认没有混合类型,请设置为False,或使用dtype参数指定类型。
注意,无论数据大小或迭代器参数是多少,整个文件都会被读取到单个DataFrame中。(仅C引擎有效)- memory_map: 布尔值,默认值False。
如果用filepath_or_buffer指定文件路径,可以将文件对象直接映射到内存并直接从内存访问数据。
使用此选项可以提高性能,因为不再有任何I/O开销。- na_values: 标量、字符串、list-like、字典,可选。
识别为NaN的其他字符串,指定某些值为空值。
默认情况下,以下值被解析为空值:‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’。 - keep_default_na: 布尔值,默认值True。
在解析数据时是否包括默认的空值。根据是否传入na_values,分为如下四种情况:
如果keep_default_na为True,并且指定na_values,则会将na_values指定的值和默认的NaN值解析为空值。
如果keep_default_na为True,并且未指定na_values,则只将默认的NaN值解析为空值。
如果keep_default_na为False,并且指定na_values,则只将na_values指定的值解析为空值。
如果keep_default_na为False,并且未指定na_values,则不会将任何字符串解析为空值。
注意,如果na_filter传入为False,则keep_default_na和na_values参数将被忽略。- na_filter: 布尔值,默认值True。
检测缺失值(默认的NaN和na_values指定的值)。在没有NaN的数据中,设置na_filter=False可以提高读取大文件的性能。- verbose: 布尔值,默认值False。指定放在非数字列中的NaN值的数量。
- skip_blank_lines: 布尔值,默认值True。
如果为True,则跳过空白行,而不是将其解析为NaN值。- parse_dates: 布尔值、数字列表、列名列表、嵌套列表、字典,默认值False。
布尔值如果为True,尝试将索引当成日期解析。
整数或列名的列表,例如[1, 2, 3]尝试将1,2,3列分别作为单独的日期列进行解析。
嵌套列表,例如[[1, 3]]将第一列和第三列合并解析为一个日期列。
字典,例如{‘foo’: [1, 3]},将第一列和第三列解析为日期,并且合并成一列将列名重命名为foo。
如果列或索引包含不可解析的日期,则整个列或索引将作为对象数据类型返回,不会被更改。- infer_datetime_format: 布尔值,默认值False。
如果设置为True且有列启用了parse_dates,尝试推断日期格式以加快处理。- keep_date_col: 布尔值,默认值False。
如果设置为True且parse_dates指定组合多列,则保留原始列。- date_parser: 函数,可选。
用于将字符串列转换为datetime实例的函数,默认使用dateutil.parser.parser进行转换。
pandas将尝试以三种不同的方式调用date_parser,如果发生异常则前进到下一种方式:
- 将一个或多个数组(由date_parser定义)作为参数传递。
- 将date_parser定义的列中的字符串值(按行)连接起来存到一个数组中,并传递该数组。
- 使用一个或多个字符串(对应于date_parser定义的列)作为参数为每行调用一次date_parser。
- dayfirst: 布尔值,默认值False。DD/MM格式日期,国际和欧洲格式。
- cache_dates: 布尔值,默认值True。
如果为True,请使用已转换的唯一日期的缓存来应用日期时间转换。在分析重复日期字符串时,可能会产生显著的提速,尤其是具有失去偏移量的字符串。- iterator: 布尔值,默认值False。为get_chunk()迭代或获取数据块返回TextFileReader对象。
- chunksize: 整数,默认值None。返回用于迭代的TextFileReader对象,每次读取chunksize行。
- compression: 字符串或字典,默认值’infer’。
用于磁盘数据的实时解压缩。可选值:{‘infer’, ‘zip’, ‘gzip’, ‘bz2’, ‘zstd’, ‘tar’}。
如果使用’infer’,且如果filepath_or_buffer是以‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’结尾的字符串,则使用gzip、bz2、zip或xz,否则不进行解压缩。如果使用‘.zip’,则ZIP文件必须只包含一个要读取的数据文件。设置为None,表示不解压。- thousands: 字符串,可选。千分隔符。
- decimal: 字符串,默认’.'。识别为小数点的字符。
- float_precision: 字符串,可选。
指定C引擎浮点值使用哪个转换器。
None: 普通转换器。
high: 高精度转换器。
round_trip: 往返转换器。- lineterminator: 字符串(长度为1),可选。设置文件分行的字符,仅对C引擎有效。
- quotechar: 字符串(长度为1),可选。用于表示引用项的开始和结束的字符,引用的项可以包括分隔符,他将被忽略。
- quoting: 整数或csv.QUOTE_*实例,默认值0。
控制每个csv.QUOTE_*常量的字段引用行为。使用QUOTE_MINIMAL(0), QUOTE_ALL(1), QUOTE_NONNUMERIC(2)或QUOTE_NONE(3)中的一个。- doublequote: 布尔值,默认值True。
当指定quotechar并且quoting不是QUOTE_NONE时,指示是否将字段内的两个连续quotechar元素解释为单个quotechar元素。- escapechar: 字符串(长度为1),默认值None。
当quoting为QUOTE_NONE时,用于转义分隔符的一个字符串。- comment: 字符串,可选。
设置注释符号,注释掉行的其余内容。如果在一行开头匹配到该字符,则该行将被完全忽略,此参数必须为单个字符。
与空行(只要skip_blank_lines=True)一样,完全注释的行被参数header忽略,而不是被参数skiprows忽略。
例如,如果comment=‘#’,解析’#empty\na,b,c\n1,2,3’且header=0,结果将’a,b,c’视为header。也就是第一行被comment注释了,header=0取到第二行。- encoding: 字符串,可选。读/写时使用UTF的编码(如’utf-8’)。
- encoding_errors: 字符串,可选,默认值’strict’。如何处理编码错误。
1.3.0版本新增。- dialect: 字符串或csv.Dialect实例,可选。
如果提供,则此参数将覆盖以下参数的值: delimiter, doublequote, escapechar, skipinitialspace, quotechar和quoting。- error_bad_lines: 布尔值,可选,默认值True。
字段过多(例如,带有过多逗号的csv行)的行默认会引发异常,不会返回DataFrame。如果设置为False,则这些“坏行”将从返回的DataFrame中删除。
1.3.0版本已弃用。- warn_bad_lines: 布尔值,可选,默认值True。
如果error_bad_lines为False,并且warn_bad_lines为True,则会为每个“坏行”输出一条警告。
1.3.0版本已弃用。- on_bad_lines: {‘error’, ‘warn’, ‘skip’}中的一个、可调用对象,默认值’error’。
当遇到坏行(字段太多的行)时要执行的操作。
error: 遇到坏行时抛出异常。
warn: 遇到坏行时发出警告并跳过该行。
skip:遇到坏行时跳过他们,不抛出异常和警告。
1.3.0版本新增。- storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
to_csv()参数总结
DataFrame.to_csv():
- path_or_buf: 字符串、路径对象、file-like对象、None,默认值None。
字符串、路径对象,或实现了write()函数的file-like对象,如果为None,则结果以字符串形式返回。- sep: 字符串,默认值’,‘。分隔符,to_csv()默认分隔符为’,'。
- na_rep: 字符串,默认值’'(空字符)。缺失值表示方式。
- float_format: 字符串,可调用对象,默认值None。
设置字符串格式化输出时浮点数的小数位数。如果给出一个可调用对象,他优先于其他数字格式参数。- columns: 序列,可选。要写入的列。
- header: 布尔值或字符串组成的列表,默认值True。
写入列名称。如果传入一个字符串列表,则设置为列的别名。- index: 布尔值,默认值True。写入数据时会将行名称(索引)写入。
- index_label: 字符串、序列、False,默认值None。
索引列的列标签(如果需要)。如果设置为None,并且header和index参数为True,则使用索引的names。如果使用MultiIndex,则应传入一个序列。如果设置为False,则不会打印索引名称的字段,使用index_label=False可在R中更方便地导入。- mode: 字符串,默认值’w’。Python写入模式,可用的写入模式与open()相同。
- encoding: 字符串,可选。
表示要在输出文件中使用的编码的字符串,默认值为’utf-8’。如果path_or_buf是非二进制文件对象,则不支持encoding。- compression: 字符串或字典,默认值’infer’。用于在线压缩输出数据。
如果使用’infer’,且如果path_or_buf参数是path-like对象,则从以下扩展名中检测压缩:‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’或‘.tar.bz2’(否则不会进行压缩)。设置为None,表示不进行压缩。- quoting: 来自csv模块的可选常量。
默认为csv.QUOTE_MINIMAL。如果设置了float_format格式,则将float转换为字符串,csv.QUOTE_NONNUMERIC将其视为非数字格式。- quotechar: 字符串,默认值单边双引号"。长度为1的字符串,用于引用字段的字符。
- lineterminator: 字符串,可选。
在输出文件中使用的换行字符或字符序列。默认为os.linesep,这取决于调用此方法的操作系统(linux为’\n’,Windows为‘\r\n’)。- chunksize: 整数或Noen。一次写入chunksize行。
- date_format: 字符串,默认值None。日期时间对象的格式字符串。
- doublequote: 布尔值,默认值True。控制同一个quotechar参数引用的范围内的quoting参数。
- escapechar: 字符串,默认值None。长度为1的字符串,用于避开sep参数和quotechar参数的字符。
- decimal: 字符串,默认值’.‘。识别为十进制分隔符的字符串。例如,对欧洲数据使用’,'。
- errors: 字符串,默认值’strict’。
指定如何处理编码和解码错误。完整的选项列表,可以参考open()的错误参数,有strict, ignore, replace, surrogateescape, xmlcharrefreplace, backslashreplace, namereplace。- storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
read_json()参数总结
read_json():
- path_or_buf: 一个有效的JSON字符串、路径对象、file-like对象。
任何有效的字符串路径都可以接受,字符串可以是一个URL。有效的URL格式包括http、ftp、s3和file,对于文件URL,最好有个主机地址,例如一个本地文件可以是file://localhost/path/to/table.json这样的格式。
如果传递路径对象,则pandas接受所有os.Pathlike对象。
通过file-like对象,可以引用具有read()方法的对象,例如文件处理(如内置函数open()函数)或StringIO。- typ: {‘frame’, ‘series’},默认值frame。要恢复的对象类型。
- orient: 期望的JSON字符串格式。兼容的JSON字符串可以由to_json()生成。并具有相应的orient值。
split: 类似于{index -> [index], columns -> [columns], data -> [values]}的字典。
records: 类似于[{column -> value}, … , {column -> value}]的列表。
index: 类似于{index -> {column -> value}}的字典。
columns: 类似于{column -> {index -> value}}的字典。
values: 仅为值的数组。
table: 类似于{‘schema’: {schema}, ‘data’: {data}}的字典。
typ == ‘series’: 默认为index,允许的值为{‘split’,‘records’,‘index’},Series的索引在orient为index时必须是唯一的。
typ == ‘frame’: 默认为columns,允许的值为{‘split’,‘records’,‘index’, ‘columns’,‘values’, ‘table’},DataFrame的索引在orient为index和columns时必须是唯一的,DataFrame的列名在orient为index、columns和records时必须是唯一的。- dtype: 布尔值、字典,默认值None。
如果为True,推断dtypes,如果为列和dtype组成的字典,则使用字典中的dtype。如果为False,则不推断dtypes,仅适用于数据。
对于除table之外的所有orient参数,默认值为True。- convert_axes: 布尔值,默认值None。
尝试将列转换为正确的dtypes。对于除table之外的所有orient参数,默认值为True。- convert_dates: 布尔值或字符串列表,默认值True。
如果为True,则可以转换默认日期格式的列(取决于keep_default_dates参数),如果为False,则不会转换日期。
如果是一个列名组成的列表,则将转换这些列,并且也可以转换默认日期格式的列(取决于keep_default_dates参数)。- keep_default_dates: 布尔值,默认值True。
如果解析日期(convert_dates不是False),则尝试解析默认的日期格式列。列标签属于日期格式的列为:以’_at’结尾、以’_time’结尾、以’timestamp’开头、列名为’modified’或’date’。- numpy: 布尔值,默认值False。
直接解析为numpy数组。虽然column和index标签可能是非数字的,但仅支持数字数据。
注意,如果numpy=True,则每个组的JSON顺序必须相同。
1.0.0版本后已弃用。- precise_float: 布尔值,默认值False。
当解码字符串为双精度类型值时,设置为能使用更高精度(strtod)函数。默认(False)使用快速但不精确的内置功能。- date_unit: 字符串,默认值None。
用于检测转换日期的时间戳单位。默认情况下,尝试并检测正确的精度,如果不满足期望,则传递‘s’, ‘ms’, ‘us’或‘ns’中的一个,以强制设置时间戳精度分别为秒、毫秒、微秒或纳秒。- encoding: 字符串,默认值’utf-8’。用于解码python3字节的编码。
- encoding_errors: 字符串,默认值’strict’。
指定如何处理编码错误。完整的选项列表,可以参考open()的错误参数,有strict, ignore, replace, surrogateescape, xmlcharrefreplace, backslashreplace, namereplace。
1.3.0版本新增。- lines: 布尔值,默认值False。读取文件每行作为一个JSON对象。
- chunksize: 整数,可选。
与lines=True结合使用,返回一个JSON读取器(JsonReader),每次迭代读取chunksize行。如果为None,则文件将一次性全部读入内存。- compression: 字符串或字典,默认值’infer’。
用于磁盘数据的实时解压缩。如果使用’infer’,且如果path_or_buf参数是path-like对象,则从以下扩展名中检测压缩:‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’或‘.tar.bz2’(否则不会进行压缩)。如果使用’zip’或‘tar’,则ZIP文件必须只包含一个要读取的数据文件。设置为None,表示不进行压缩。- nrows: 整数,可选。
每次从jsonfile中读取的行数。仅当lines参数为True时才能生效。如果为None,则返回所有行。- storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
to_json()参数总结
DataFrame.to_json():
- path_or_buf: 字符串、路径对象、file-like对象、None,默认值None。
字符串、路径对象,或实现了write()函数的file-like对象,如果为None,则结果返回一个JSON字符串。- orient: 字符串。期望的JSON字符串格式。
Series: 默认为index,允许的值为{‘split’, ‘records’, ‘index’, ‘table’}。
DataFrame: 默认为columns,允许的值为{‘split’, ‘records’, ‘index’, ‘columns’, ‘values’, ‘table’}。
split: 类似于{index -> [index], columns -> [columns], data -> [values]}的字典。
records: 类似于[{column -> value}, … , {column -> value}]的列表。
index: 类似于{index -> {column -> value}}的字典。
columns: 类似于{column -> {index -> value}}的字典。
values: 仅为值的数组。
table: 类似于{‘schema’: {schema}, ‘data’: {data}}的字典。- date_format: 字符串,{None, ‘epoch’, ‘iso’}。
日期类型的转换。epoch是时间戳,iso是ISO8601标准。
默认值取决于orient参数,对于orient=‘table’,默认值为iso,对于其他的orient值,默认值为epoch。- double_precision: 整数,默认值10。对浮点值进行编码时使用的小数位数。
- force_ascii: 布尔值,默认值True。强制设置编码字符串为ASCI。
- date_unit: 字符串,默认值’ms’(milliseconds,毫秒)。
编码的时间单位,管理时间戳和ISO8601的精度,可选‘s’, ‘ms’, ‘us’, ‘ns’中的一个,分布表示秒、毫秒、微秒和纳秒。- default_handler: 可调用对象,默认值None。
如果一个对象没有转换成一个恰当的JSON格式,处理程序就会被调用。采用单个参数(即要转换的对象),并返回一个序列化的对象。- lines: 布尔值,默认值False。
如果orient参数为records,则将每行写入记录为json,orient参数是其他格式,将抛出ValueError异常,因为其他格式不是list-like。- compression: 字符串或字典,默认值’infer’。用于在线压缩输出数据。
如果使用’infer’,且如果path_or_buf参数是path-like对象,则从以下扩展名中检测压缩:‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’或‘.tar.bz2’(否则不会进行压缩)。设置为None,表示不进行压缩。- index: 布尔值,默认值True。
是否在JSON字符串中包含索引值。仅当orient为split或table时,才支持不包含索引(index=False)。- indent: 整数,可选。用于缩进每条记录的空格长度。
- storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
以上就是pandas中最常见的三种数据读写方法的参数完整介绍,建议收藏本文,需要使用时方便查看。也欢迎点赞和关注支持,用wx关注我方便接收更多最新Python文章。
参考文档:
[1] pandas中文网:https://www.pypandas.cn/docs/
相关阅读:
Pandas知识点-详解表级操作管道函数pipe