redis的主从复制+集群+mysql缓存服务
目录
一、Redis主从复制
1.redis安装配置
2.Redis主从的自动切换
3.集群cluster
4. Redis cluster集群的故障迁移
5.redis+mysql的缓存服务器
6.配置gearman实现Redis和MySQL数据同步
1 什么是Redis
redis是一个高性能的、开源的key-value数据库,而且redis是一个NOSQL类型数据库(非关系型的数据库),是为解决高并发、高扩展,大数据存储等一系列的问题而产生的数据库解决方案,它还可以用作:数据库、缓存和消息中间件。但是,它也不能替代关系型数据库,只能作为特定环境下的扩充。
redis是一个以key-value存储的数据库结构型服务器,它支持的数据结构类型包括:字符串(String)、链表(lists)、哈希表(hash)、集合(set)、有序集合(Zset)等,也被人们称为数据结构服务器。为了保证读取的效率,redis把数据对象都存储在内存当中,它可以支持周期性的把更新的数据写入磁盘文件中 。而且它还提供了交集和并集,以及一些不同方式排序的操作。
MySQL(关系型数据库) :需要把数据存储到库、表、行、字段里,查询的时候根据条件一行一行地去匹配,当查询量非常大的时候就很耗费时间和资源,尤其是数据是需要从磁盘里去检索。
NoSQL(非关系型的数据库): 存储原理非常简单(典型的数据类型为k-v),不存在繁杂的关系链,不需要像mysql那样需要找到对应的库、表(通常是多个表)以及字段。
一、Redis主从复制
主从复制:主机数据更新后,根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。读写分离,容灾恢复
一个Master,两个Slave,Slave只能读不能写;当Slave与Master断开后需要重新slave of连接才可建立之前的主从关系;Master挂掉后,Master关系依然存在,Master重启即可恢复。
从库配置:replicaof [主库IP] [主库端口];注意:每次slave与master断开后,都需要重新连接,除非你配置进redis.conf文件;键入info replication 可以查看redis主从信息。
Slave启动成功连接到master后会发送一个sync命令;
Master接到命令启动后的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步;
全量复制:而slave服务在数据库文件数据后,将其存盘并加载到内存中;
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步;
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行。
1.redis安装配置
redis软件下载: https://redis.io/download
解压redis安装包,并进入目录

编译 安装


vim install_server.sh 注释掉本地连接

./install_server.sh ## 默认选项,一直回车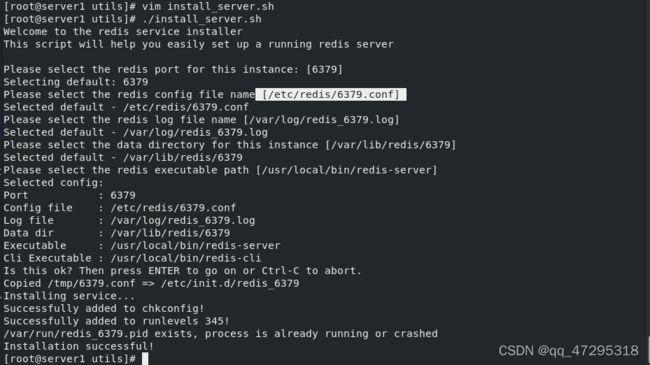
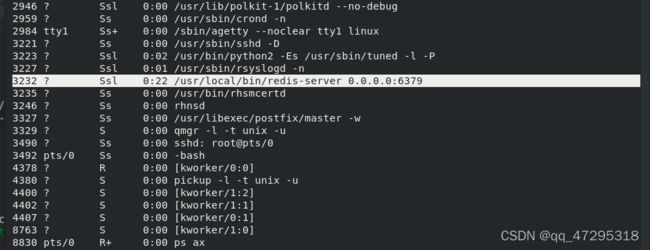
编辑配置文件/etc/redis/6379.conf,修改端口,为所有接口都能访问,然后重启服务


查看服务开启端口为6379,且监听的是本地
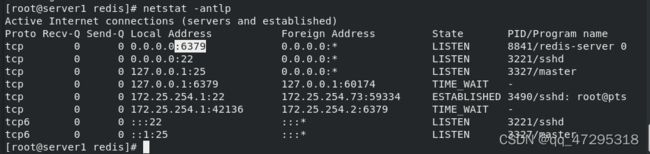
在server2和server3上 安装配置redis

安装依赖性


vim install_server.sh 注释掉本地连接
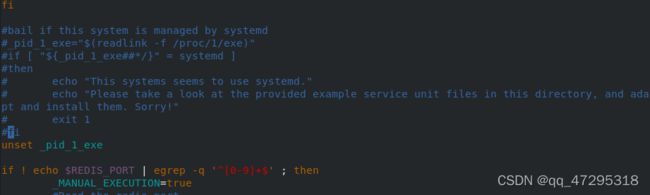

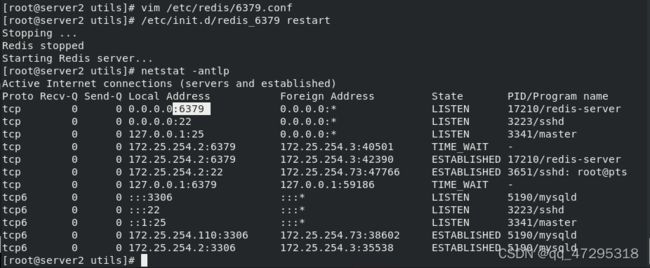
bind 0.0.0.0 #修改监听端口
在server2和server3上(slave),修改配置文件里的监听端口及在文件最后一行加入master信息

测试:
进入 master的redis数据库redis-cli info查看各种信息
 在server2上看到为slave
在server2上看到为slave

server1为master

set name westos定义key值为name,value值为westos,get name可以获取value值。

再进入 slave的redis数据库,可以获取value值,但不能删除,新定义value值,即**slave不可以进行写操作。**

![]()
server2和server3的配置相同
2.Redis主从的自动切换
基于sentinel哨兵模式,哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
一主两从的情况下,当master与两个slave或因网络关系断掉的情况下,客户端并不知道master失联,会持续写入数据,但此时slave端已经不能复制数据。
如果需要解决此问题,则需要两个slave同时认定不能连接master,或者,超过设定时间不能连接,则此时master端会拒绝客户端继续写入,那么重新接入变成slave时就不会造成数据丢失
Redis 的 Sentinel 分布式系统:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器。
redis常用指令:
config get * //查看配置
select 1 //选择数据库
flushdb //清空当前数据库
flushall //清空所有数据库
move key 1 //移动key
del key //删除
rename oldkey newkey //改名
expire key 10 //设置过期时间
persist key //设置持久化
keys user* //查询
exists key //判断是否存在
数据库默认一共16个,0到15




min-replicas-max-lag##从节点健康延迟时间:延迟时间小于该值的从节点判断为健康的

 在server1中,配置sentinel
在server1中,配置sentinel
sentinel monitor mymaster 172.25.254.1 6379 2 #master为server1,2表示需要两票通过
sentinel down-after-milliseconds mymaster 10000 #连接超时为10s

复制sentinel.conf到server2和server3


配置server3的redis



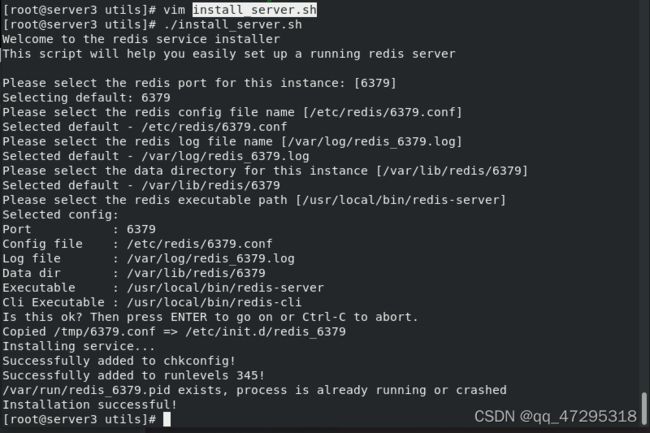




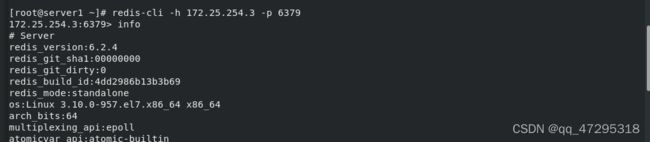
查看server3状态为slave

server1中查看master状态
redis-cli
> info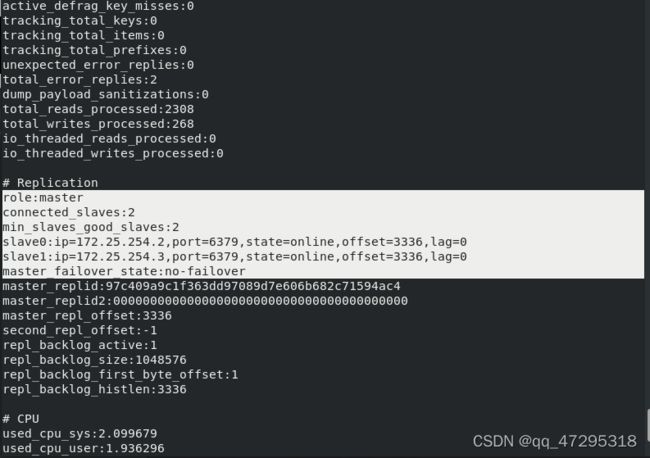
在server1上redis-sentinel /etc/redis/sentinel.conf ##启动sentinel
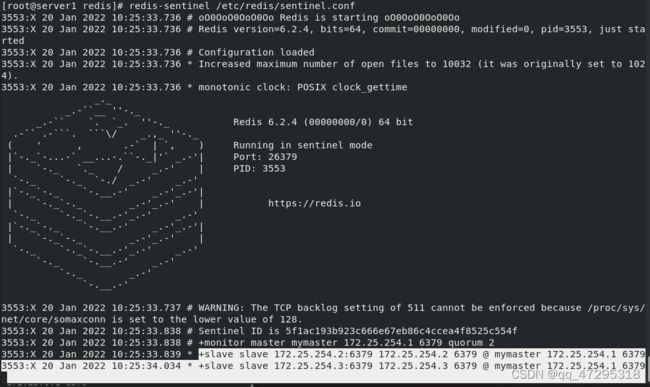
在server2上redis-sentinel /etc/redis/sentinel.conf ##启动sentinel

在server3上redis-sentinel /etc/redis/sentinel.conf ##启动sentinel

关闭server1的redis

server2提为master

投票切换,2票切换master,server2为master
在server3上查看server2为master

在server2上看到为master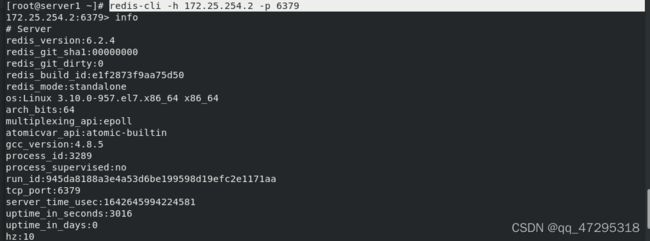

开启serve1

查看进程

server1变为slave


3.集群cluster
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的内容
redis集群: 自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
redis-cli --cluster help

集群内部划分为16384个数据分槽,分布在三个主redis中。
从redis中没有分槽,不会参与集群投票,也不会帮忙加快读取数据,仅仅作为主机的备份。
三个主节点中平均分布着16384数据分槽的三分之一,每个节点中不会存有有重复数据,仅仅有自己的从机帮忙冗余。
停掉redis服务(redis服务本身监听的端口是6379端口)
![]() Redis Cluster搭建
Redis Cluster搭建
启动redis Cluster对应的6个节点
 查看进程
查看进程
 创建集群(集群中的主从节点是随机的),节点全部启动后,每个节点目前只能识别出自己的节点信息,彼此之间并不知道对方的存在;实现集群的快速搭建,需要使用
创建集群(集群中的主从节点是随机的),节点全部启动后,每个节点目前只能识别出自己的节点信息,彼此之间并不知道对方的存在;实现集群的快速搭建,需要使用redis-cluster来创建集群
redis-cli --cluster create 输入yes
# 使用create命令创建集群 --replicas 1 参数表示为每个主节点创建一个从节点,其他参数是实例的地址集合。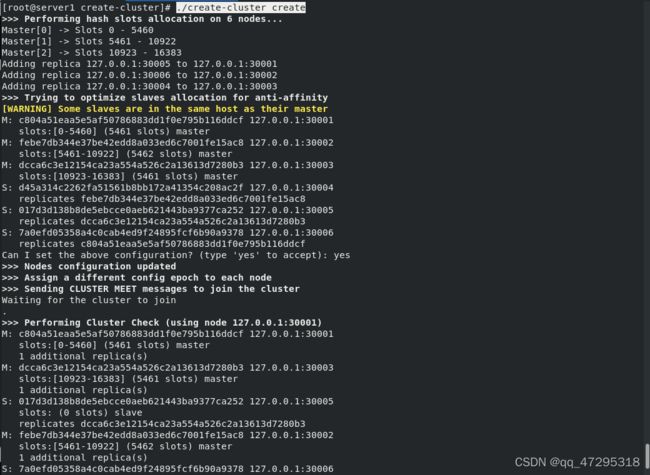
查看该集群的具体信息
一主一从,分别为3对,6个节点

测试存取值:
客户端连接集群redis-cli需要带上 -c
redis-cli用来进行集群交互,客户端连接任意一个节点,使用-c表示以集群方式登陆,-p指定端口。当连接master端时,读写正常,在连接slave时,执行写操作时,自动切换到master端进行写入操作




根据redis cluster的key值分配,name被分配到节点30002上,我们查看name的值,上面显示了redis cluster自动从30001跳转到30002上
 在30002节点获取name值,就不会跳转,因为本来就存储在30002节点
在30002节点获取name值,就不会跳转,因为本来就存储在30002节点
 4. Redis cluster集群的故障迁移
4. Redis cluster集群的故障迁移
节点30002挂掉
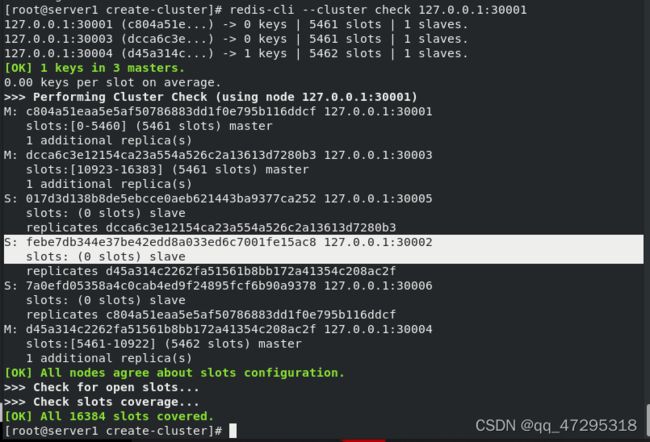
![]() 检查集群,看到30004变成新的master
检查集群,看到30004变成新的master

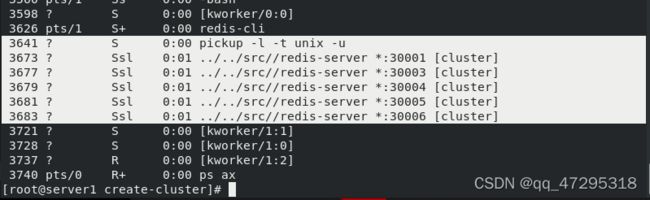
重新 启动集群
 查看状态会发现30002变成了slave
查看状态会发现30002变成了slave
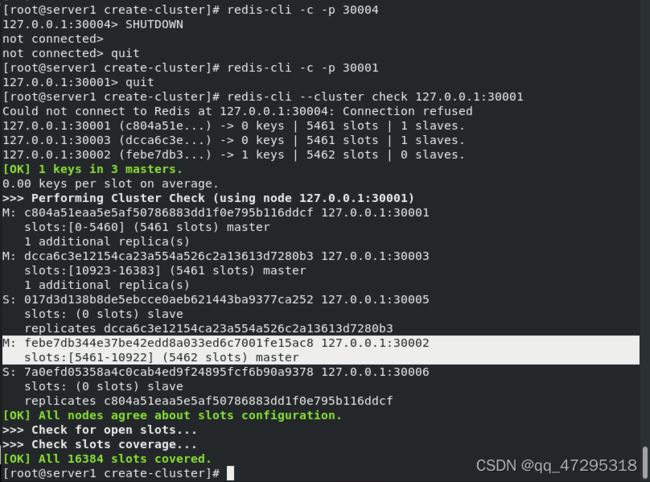
 down掉30004,30002又变回master
down掉30004,30002又变回master
 如果将30002节点也手动down掉,那么该集群也就费了,因为至少三个master。
如果将30002节点也手动down掉,那么该集群也就费了,因为至少三个master。

启动集群节点又恢复回来

添加节点和分配哈希槽
修改配置文件并启动服务
在配置文件中修改节点个数为8
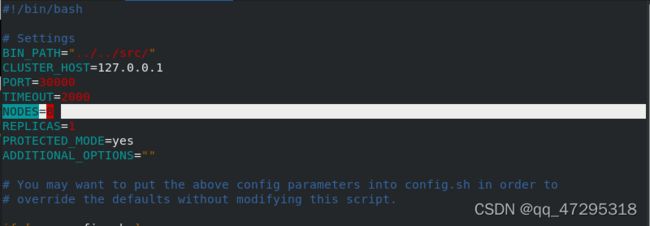
 将300007添加到集群中,未指定master端ID,没有多余的master端不能自动分配,由于哈希槽的数量是固定的,添加进去之后没有分配到 时隙
将300007添加到集群中,未指定master端ID,没有多余的master端不能自动分配,由于哈希槽的数量是固定的,添加进去之后没有分配到 时隙

30007变为master
 添加节点 30008到指定的master端30007
添加节点 30008到指定的master端30007
 30008成为slave
30008成为slave
 分片操作
分片操作
How many slots do you want to move (from 1 to 16384)? 1000 ##想要移动的插槽数量
What is the receiving node ID? ##接收节点的ID
Source node #1: all ##从哪些节点获取这些资源,all指的是从每个组中都获取一些 分片操作完成,获得了从30001,30001,30003分出的1000个哈希槽
分片操作完成,获得了从30001,30001,30003分出的1000个哈希槽
 清除集群节点
清除集群节点
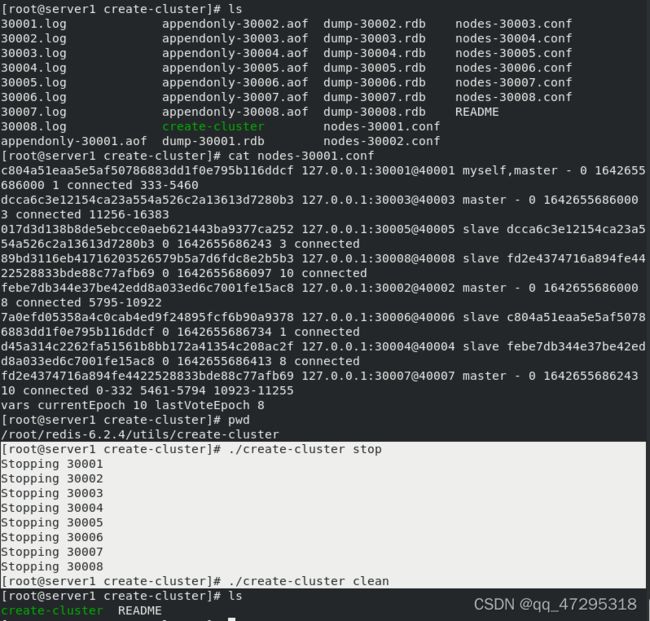 5.redis+mysql的缓存服务器
5.redis+mysql的缓存服务器
搭建实验环境:
在server4上安装mariadb-server服务端,设定redis的server2为master
server2为master:



在server4中:
安装mariadb服务
 授予test数据库权限
授予test数据库权限

做开机不启动
 在
在
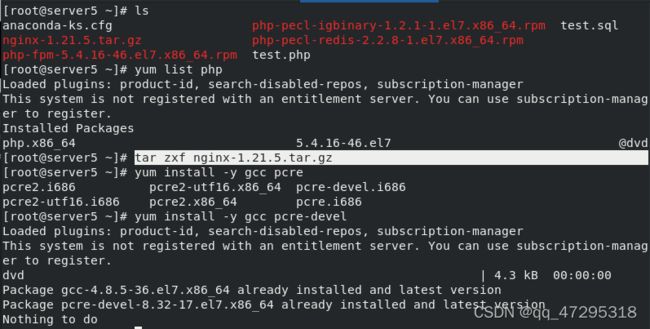 重新打开虚拟机server5安装nginx
重新打开虚拟机server5安装nginx


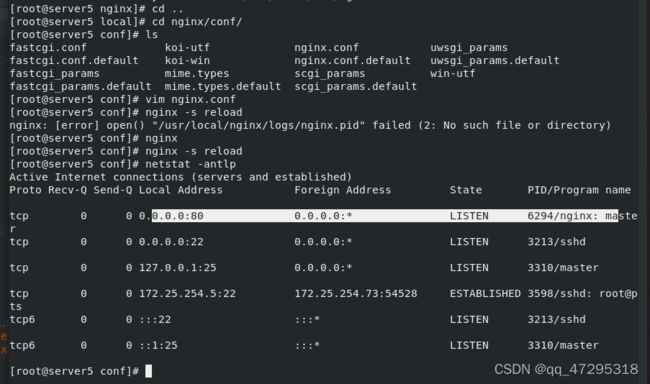
 vim nginx.conf
vim nginx.conf
 查看80端口
查看80端口
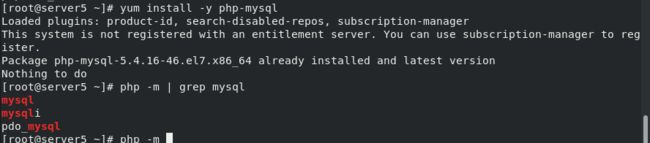
 安装相关软件包
安装相关软件包




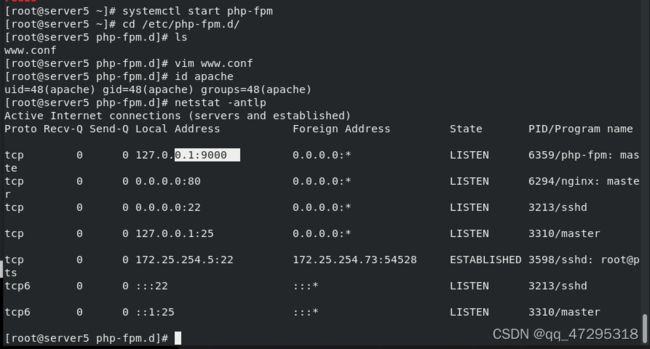
 vim www.conf
vim www.conf

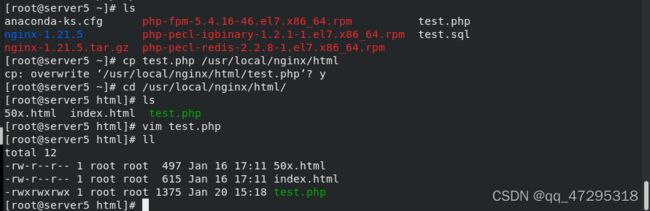 vim test.php
vim test.php
172.25.254.2 ##master主机ip
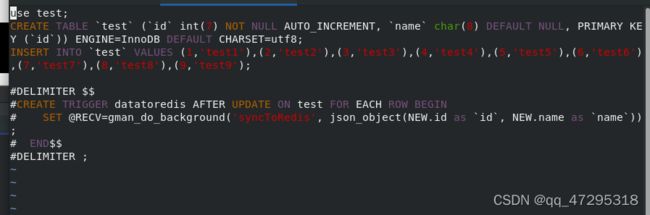
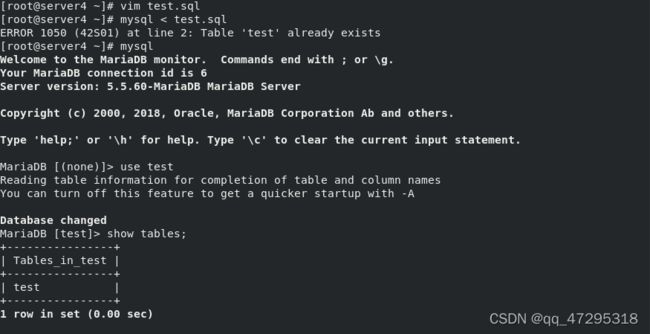
172.25.254.4 ##mariadb服务主机ip 编写mysql触发器脚本test.sql,并导入test数据库
编写mysql触发器脚本test.sql,并导入test数据库

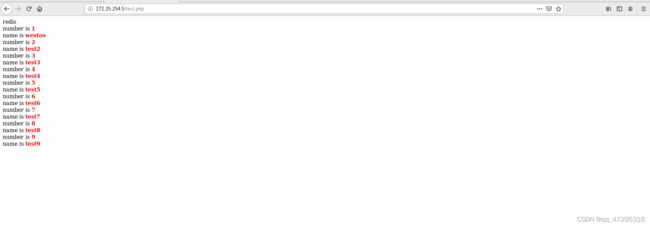
在浏览器访问172.25.254.5/test.php

在server2master主机中

更改mysql中的内容
 在redis中没有 变化
在redis中没有 变化

在浏览器访问172.25.254.5/test.php此数据只能同步复制,不能异步复制,只能在redis上改写和读取数据,mysql端更改不生效,即数据不一致,因为客户端读取的时候找redis缓存;客户端写的时候 去找mysql
6.配置gearman实现Redis和MySQL数据同步
Gearman是一个用来把工作委派给其他机器、分布式的调用更适合做某项工作的机器、并发的做某项工作在多个调用间做负载均衡、或用来在调用其它语言的函数的系统
一个Gearman请求的处理过程涉及三个角色:Client -> Job -> Worker。
Client:请求的发起者,可以是 C,PHP,Perl,MySQL UDF 等等。
Job:请求的调度者,用来负责协调把 Client 发出的请求转发给合适的 Worker。
Worker:请求的处理者,可以是 C,PHP,Perl 等等。
因为 Client,Worker 并不限制用一样的语言,所以有利于多语言多系统之间的集成。
甚至我们通过增加更多的 Worker,可以很方便的实现应用程序的分布式负载均衡架构。

在server4上,解压lib_mysqludf_json-master.zip

安装gcc 和mariadb-devel
 gcc进行编译
gcc进行编译

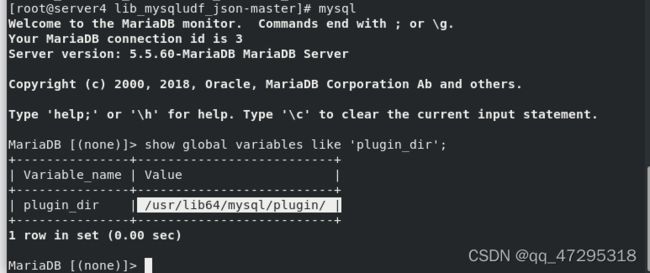
通过lib_mysqludf_json UDF 库函数将关系映射为JISON格式,将lib_mysqludf_json-master/lib_mysqludf_json.so模块拷贝到/usr/lib64/mysql/plugin/插件目录下
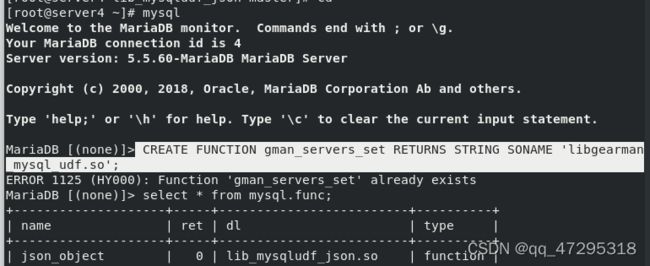
 注册udf函数,并查看。
注册udf函数,并查看。
 安装libgearman安装包,并安装管理gearman的分布式队列插件,进行编译和安装
安装libgearman安装包,并安装管理gearman的分布式队列插件,进行编译和安装

 安装libgearman安装包
安装libgearman安装包
 编译安装
编译安装
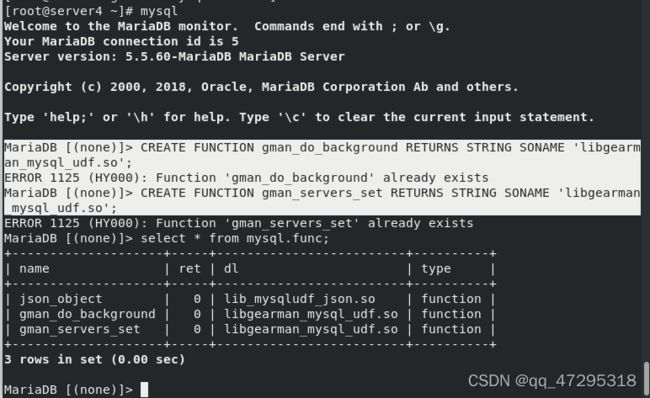
 再次注册两个udf函数
再次注册两个udf函数
server5下载安装gearman(gman的worker端),开启gearmand服务并查看其端口号4730是否开启
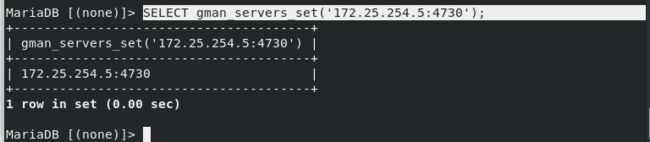
 在server4指定gearman的服务信息
在server4指定gearman的服务信息
编写mysql触发器脚本test.sql,并导入test数据库
![]()
 在server2上(gman的worker端),开启gearmand服务并查看其端口号4730是否开启
在server2上(gman的worker端),开启gearmand服务并查看其端口号4730是否开启


查看触发器
 编写
编写worker.php脚本,并放到/usr/local目录下

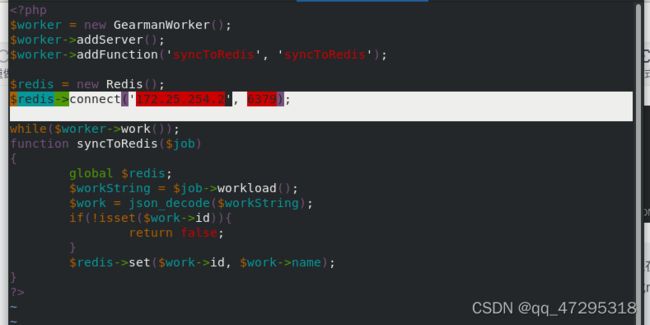
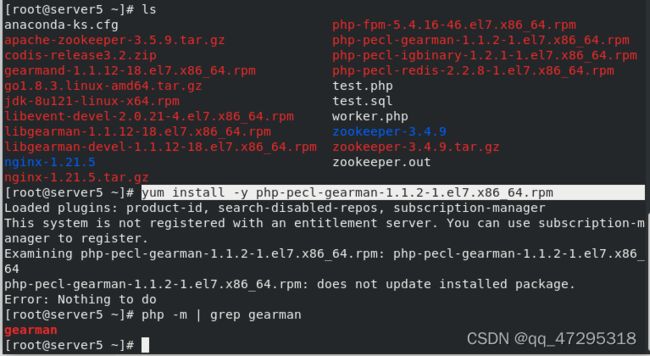 在后台运行worker
在后台运行worker

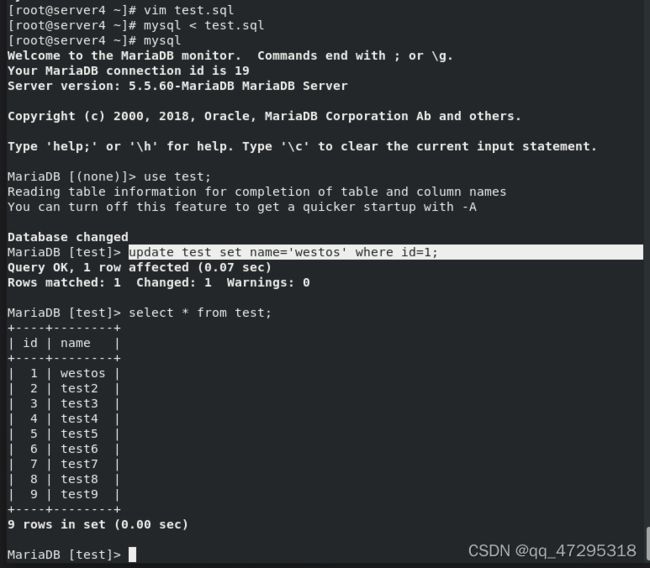
 测试:在server4更新数据并查看
测试:在server4更新数据并查看
 在server2尝试获取,发生改变
在server2尝试获取,发生改变
 在浏览器中查看,看到发生改变
在浏览器中查看,看到发生改变
在浏览器中可以看到此时server5已经同步了server4中mysql经由server2中redis上传的数据