pytorch深度学习实战lesson24
第二十四课 VGG网络
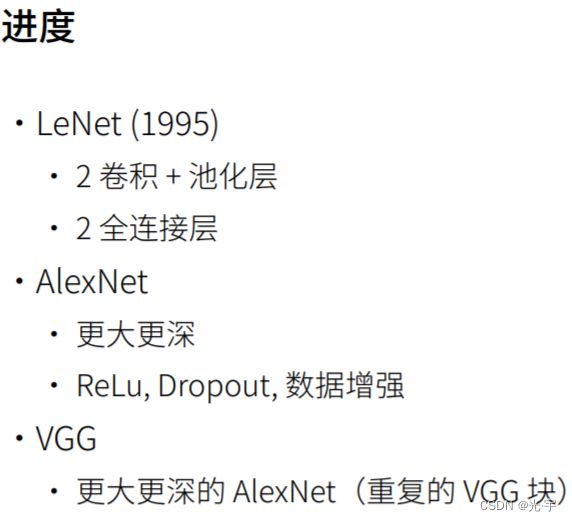
VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
目录
理论部分
实践部分
理论部分
考虑vgg之前,可以先考虑一下Alexnet的最大问题是什么了?最大问题是它的结构并不是很规则。所以就是说,我如果想让网络变得更深更大,我需要更好的设计思想,就是说我需要把整个框架搞得更加的 regular,这就是vgg的一个思路。

怎么样才能把网络弄得更深更大呢?第一个是使用更多的全连接层,但全连接层是一个很贵的结构,它特别占内存,而且计算量也不算那么便宜;第二个是可以使用更多的卷积层,但是alexnet卷积层做得不是那么好,就是说他先把lenet弄大,然后再加三个卷积层。所以这个东西的感觉上,这个不太好。
所以 vgg 的思想是把整个东西组成一些小块,一些卷积块,然后再把卷积块摞上去。

vgg块的核心思想是说我用大量的3*3的东西给你堆起来,然后再堆多个vgg块得到最后的网络。那么为什么用的是3*3 而不是5*5。是因为他们发现同样的计算的开销的情况下,我堆更多的3乘3的效果,比用少一点的5乘5的效果会好,就是说你模型更深,但是窗口更小更窄一点,效果更好。
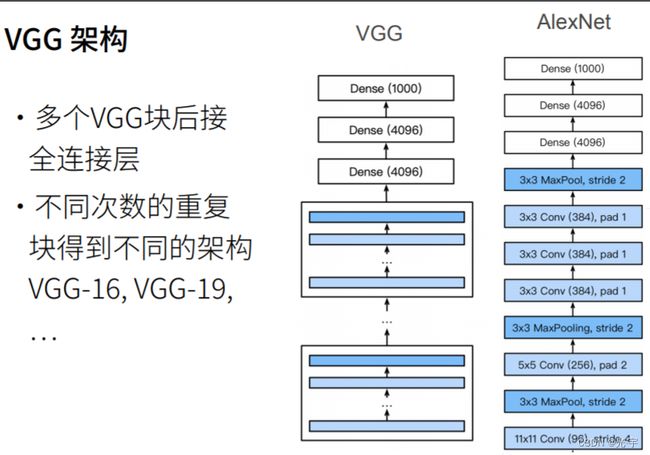
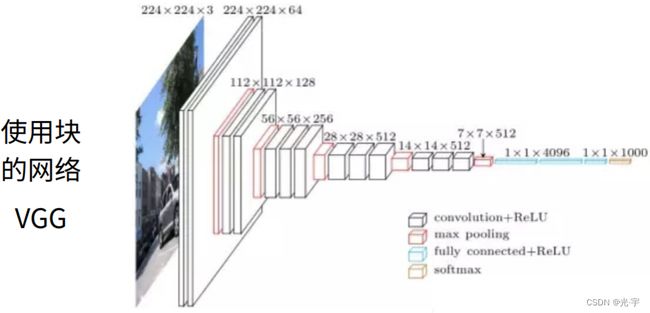
接下来的 vgg 架构其实就是替换掉Alex net 整个卷积层的架构, Alex net 是一个大的 lenet所以 vgg 把它替换成N个vgg 块,把这些块串在一起,可以串不同大小的卷积核,得到不同的VGG架构。


实践部分

代码:
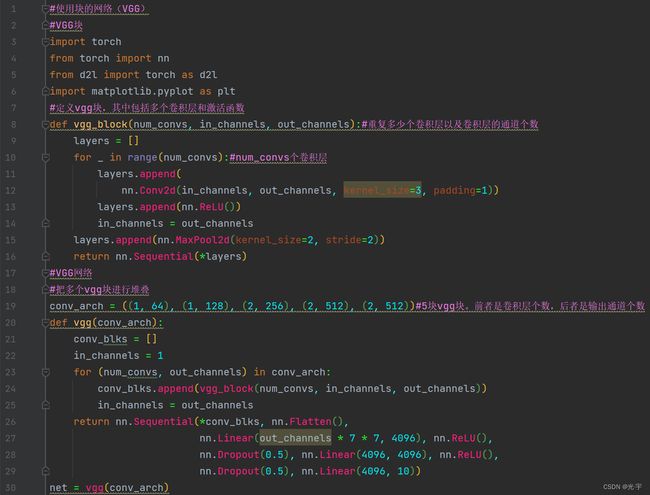
#使用块的网络(VGG)
#VGG块
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
#定义vgg块,其中包括多个卷积层和激活函数
def vgg_block(num_convs, in_channels, out_channels):#重复多少个卷积层以及卷积层的通道个数
layers = []
for _ in range(num_convs):#num_convs个卷积层
layers.append(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
#VGG网络
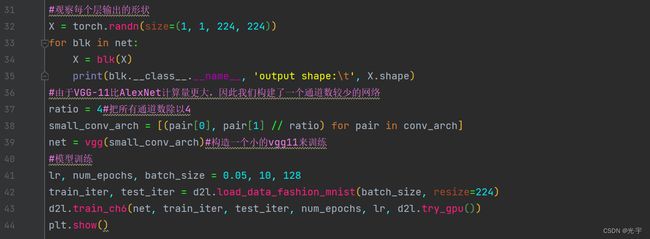
#把多个vgg块进行堆叠
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))#5块vgg块。前者是卷积层个数,后者是输出通道个数
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096, 10))
net = vgg(conv_arch)
#观察每个层输出的形状
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)
#由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络
ratio = 4#把所有通道数除以4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)#构造一个小的vgg11来训练
#模型训练
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
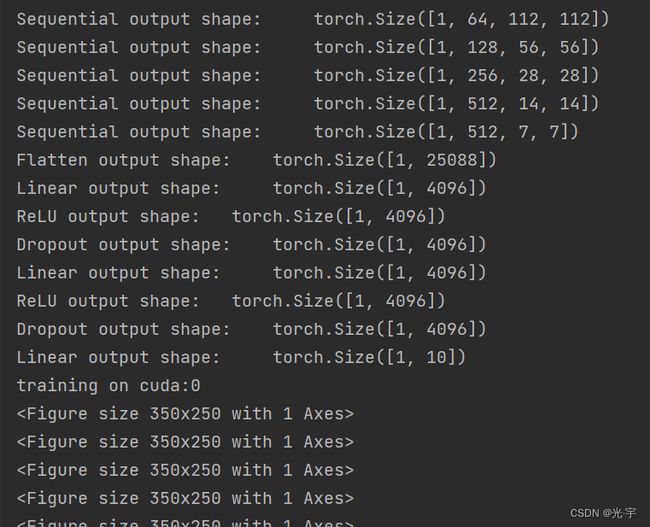
plt.show()Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
training on cuda:0
*n
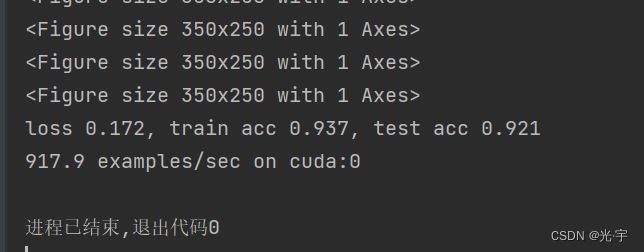
loss 0.172, train acc 0.937, test acc 0.921
917.9 examples/sec on cuda:0