用树莓派4b构建深度学习应用(十四)素描线稿篇

前言
上一篇我们完成了一对戴口罩和脱面罩的互补应用,这一篇来看一下最近抖音上看到一个批量提取线稿的视频,掌握其核心原理,我们用 OpenCV 就很容易实现一个更快速的方案。

Photoshop 提取线稿
最近刷抖音看见一个视频
实现原理
要将一张图片转为线稿图,基本要经历以下几个步骤:
将彩色图转换成灰度图
对灰度图进行求其反
做高斯模糊
颜色减淡融合到灰度图
OpenCV 提取线稿
为了方便看图片效果,这次我们用 jupyter notebook 来做。
1. 导入库文件
import cv2
from matplotlib import pyplot as plt
%matplotlib inline
2. 显示原图
input_img = cv2.imread("image.jpg")
plt.figure(figsize=(10,7))
plt.imshow(cv2.cvtColor(input_img, cv2.COLOR_BGR2RGB))

3. 转灰度图
gray_img = cv2.cvtColor(input_img, cv2.COLOR_BGR2GRAY)
plt.figure(figsize=(10,7))
plt.imshow(cv2.cvtColor(gray_img, cv2.COLOR_BGR2RGB))
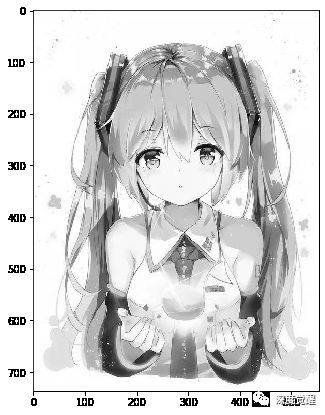
4. 灰度图反色
inv_gray_img = 255 - gray_img
plt.figure(figsize=(10,7))
plt.imshow(cv2.cvtColor(inv_gray_img, cv2.COLOR_BGR2RGB))
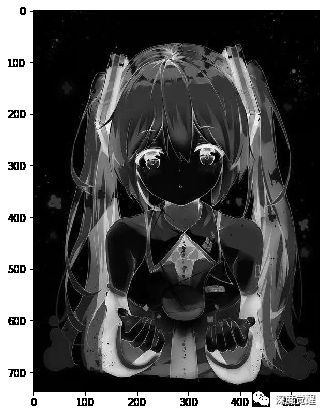
5. 高斯模糊
ksize=21
sigma=0
blur_img = cv2.GaussianBlur(inv_gray_img, ksize=(ksize, ksize), sigmaX=sigma, sigmaY=sigma)
plt.figure(figsize=(10,7))
plt.imshow(cv2.cvtColor(blur_img, cv2.COLOR_BGR2RGB))
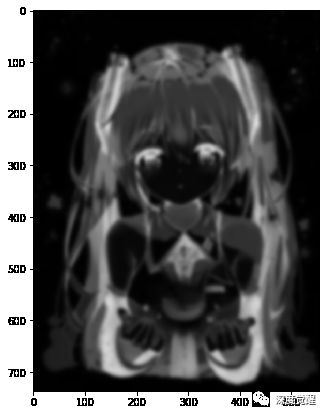
6. 颜色减淡融合
sketch_img = cv2.divide(gray_img, 255 - blur_img, scale=256) # 颜色减淡融合
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(sketch_img, cv2.COLOR_BGR2RGB))

几行代码就搞定了,要比速度的话,那 Python+OpenCV 就没有输过。
( PS 的设计师别打我!)
sketchKeras 提取线稿
上面 OpenCV 的方法虽然简单,但仔细看发髻和袖口处的线条还是不够清晰,那么我们用神经网络的方式再来实现一下。
1. 源码下载
克隆源码
git clone https://github.com/lllyasviel/sketchKeras.git
下载权重文件 mod.h5,放到项目目录下
2. 分析网络结构
sketchKeras 是一个 u-net 类型的网络, 作者没有公布模型结构,但我们可以通过 tensorboard 用其 Keras 的模型文件来解读一下其网络结构形式。
先把 keras 转成 pb 文件
python keras_to_tensorflow.py --input_model="mod.h5" --output_model="mod.pb"
然后就能用 tensorboard 导入模型
mkdir logs
python3 tensorboard_graph.py
项目下生成 logs 目录就导出了计算图
tensorboard --logdir=logs/ --host=127.0.0.1
我们可以看到就是一个典型的 unet 架构,输入 [3 * 512 * 512 * 1] 不停的下采样到 [3 * 32 * 32 * 512],然后再上采样回来的过程。
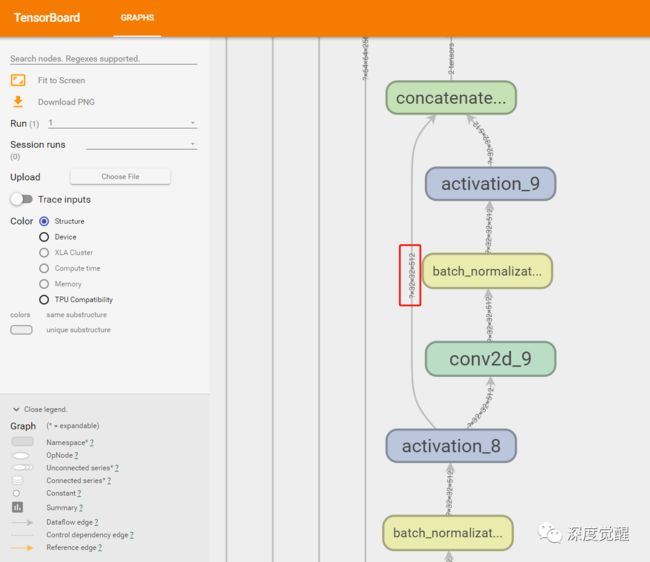
也可以安装一个 Netron,解读网络会更方便些。
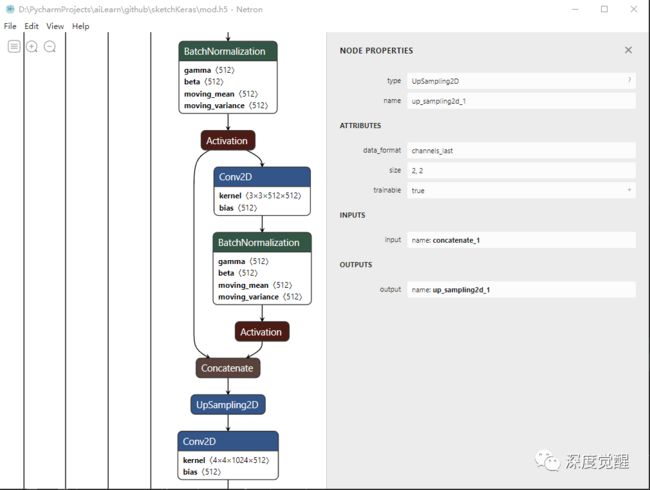
3. 预处理
输入原始图片,先 resize 成 384*512(长或宽一边为 512),然后转灰度图,再做高斯模糊,两者相减之后,最后归一化处理成 [3, 512, 512, 1] 的 Tensor,就完成了预处理。
from_mat = from_mat.transpose((2, 0, 1))
light_map = np.zeros(from_mat.shape, dtype=np.float)
for channel in range(3):
light_map[channel] = get_light_map_single(from_mat[channel])
light_map = normalize_pic(light_map)
light_map = resize_img_512_3d(light_map)

4. 推理输出
上面分析过,神经网络输出是 [3, 512, 512, 1],需要按比例裁剪到原始尺寸,然后降噪处理后就得到我们需要的线框图了。
# 模型推理 (3, 512, 512, 1)
line_mat = mod.predict(light_map, batch_size=1)
# 去除 batch 维度 (512, 512, 3)
line_mat = line_mat.transpose((3, 1, 2, 0))[0]
# 裁剪 (512, 384, 3)
line_mat = line_mat[0:int(new_height), 0:int(new_width), :]
show_active_img_and_save('sketchKeras_colored', line_mat, 'sketchKeras_colored.jpg')
line_mat = np.amax(line_mat, 2)
# 降噪
show_active_img_and_save_denoise_filter2('sketchKeras_enhanced', line_mat, 'sketchKeras_enhanced.jpg')
show_active_img_and_save_denoise_filter('sketchKeras_pured', line_mat, 'sketchKeras_pured.jpg')
show_active_img_and_save_denoise('sketchKeras', line_mat, 'sketchKeras.jpg')
完美!
✎ Tip
如果遇到 load_model requires h5py 报错的话,安装一下 h5py 即可。
sudo apt-get install libhdf5-dev
pip install h5py
可以看到,用 sketchKeras 转换的线稿笔顺会更清晰些,而 sketchKeras_colored 包含了颜色的要素,这对后续图片上色会有很大帮助。
源码下载
本期相关文件资料,可在公众号“深度觉醒”,后台回复:“rpi14”,获取下载链接。
既然已经提取了线稿,
那左右互搏的话,
下一篇我们就用线稿图,
来“还原”回彩色图像。
敬请期待...


往期推荐
用树莓派4b构建深度学习应用(人脸修复篇)
用树莓派4b构建深度学习应用(口罩篇)
用树莓派4b构建深度学习应用(ngrok篇)