1、SelectKBest和自然语言处理
import pandas as pd
tweets = pd.read_csv('../data/twitter_sentiment.csv', encoding='latin1')
tweets.head()

from sklearn.model_selection import GridSearchCV
def get_best_model_and_accuracy(model, params, X, y):
grid = GridSearchCV(model,
params,
error_score=0.0
)
grid.fit(X, y)
print('最佳的准确率为:{}'.format(grid.best_score_))
print('得到最佳准确率的最佳参数:{}'.format(grid.best_params_))
print('拟合的平均时间:{} 秒'.format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))
print('预测的平均时间:{} 秒'.format(round(grid.cv_results_['mean_score_time'].mean(), 3)))
tweets_X = tweets['SentimentText']
tweets_y = tweets['Sentiment']
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
vect = CountVectorizer()
text_pipe = Pipeline(
[
('vect', vect),
('nb', MultinomialNB())
]
)
text_pipe_params = {
'vect__ngram_range':[(1, 2)],
'vect__max_features':[5000, 10000],
'vect__min_df':[0.0, 0.1, 0.2, 0.3],
'vect__max_df':[0.7, 0.8, 0.9, 1.0]
}
get_best_model_and_accuracy(text_pipe, text_pipe_params, tweets_X, tweets_y)

from sklearn.feature_selection import SelectKBest
vect = CountVectorizer(ngram_range=(1, 2))
select_pipeline = Pipeline([
('vect', vect),
('select_k', SelectKBest()),
('nb', MultinomialNB())
])
select_pipeline_params = {
'select_k__k':[1000, 5000]
}
get_best_model_and_accuracy(select_pipeline, select_pipeline_params, tweets_X, tweets_y)

2、特征选择指标——针对基于树的模型
'''
特征选择指标——针对基于树的模型
拟合决策树时候,决策树会从根节点开始,在每个节点贪婪地选择最优分割,优化节点纯净度指标。
默认scikit-learn选择基尼系数进行优化。每次分割时候,模型会记录每个分割对整体优化目标的帮助。这些指标对特征重要性有作用。
'''
credit_card_default = pd.read_csv("../data/credit_card_default.csv")
X = credit_card_default.drop('default payment next month', axis=1)
y = credit_card_default['default payment next month']
from sklearn.tree import DecisionTreeClassifier
d_tree = DecisionTreeClassifier()
d_tree.fit(X, y)
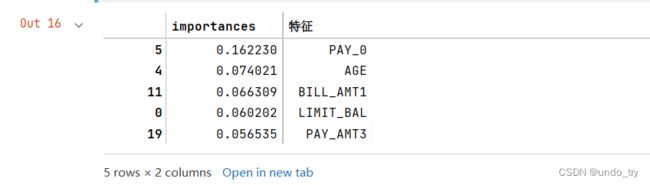
importances = pd.DataFrame(
{
'importances':d_tree.feature_importances_,
'特征':X.columns
}
).sort_values('importances', ascending=False)
importances.head()
'''
之前的SelectKBest,是基于排序函数(例如ANOVA的p值)取前k个特征
SelectFromModel使用机器学习模型内部的指标来评估特征的重要性
最大的不同:
SelectFromModel和SelectKBest相比,不使用k,而是使用阈值,代表重要性的最低限度。
'''
from sklearn.feature_selection import SelectFromModel
select_from_model = SelectFromModel(DecisionTreeClassifier(),threshold=0.05)
selected_X = select_from_model.fit_transform(X, y)
selected_X.shape
tree_pipe_params = {
'd_tree__max_depth':[1, 3, 5, 7],
'select__threshold':[0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 'mean', 'median', '2.*mean'],
'select__estimator__max_depth':[None,1, 3, 5, 7]
}
tree_pipe = Pipeline([
('select', SelectFromModel(DecisionTreeClassifier())),
('d_tree', d_tree)
])
get_best_model_and_accuracy(tree_pipe, tree_pipe_params, X, y)

tree_pipe.set_params(**
{
'd_tree__max_depth':2,
'select__threshold':0.01,
'select__estimator__max_depth':None
}
)
tree_pipe.steps[0][1].fit(X, y)
X.columns[tree_pipe.steps[0][1].get_support()]

3、特征选择指标——线性模型
'''
特征选择指标——线性模型
SelectFromModel可以处理包括feature_importances_或者coef_属性的机器学习方法模型。
基于树的模型会暴露前者,线性模型会暴露后者。
拟合后,线性模型会将一个系数放在特征的斜率前面,SelectFromModel会认为这个系数等同于重要性,并根据拟合时的系数选择特征。
'''
from sklearn.linear_model import LogisticRegression
lr_selector = SelectFromModel(LogisticRegression())
lr_reg_pipe = Pipeline([
('lr_selector', lr_selector),
('d_tree', d_tree),
])
lr_reg_pipe_params = {
'd_tree__max_depth':[1, 3, 5, 7],
'lr_selector__threshold':[0.01, 0.05, 0.1, 'mean', 'median', '2.*mean'],
'lr_selector__estimator__penalty':['l1', 'l2']
}
get_best_model_and_accuracy(lr_reg_pipe, lr_reg_pipe_params, X, y)

lr_reg_pipe.set_params(**
{
'd_tree__max_depth':5,
'lr_selector__threshold':'median',
'lr_selector__estimator__penalty':'l2'
}
)
lr_reg_pipe.steps[0][1].fit(X, y)
X.columns[lr_reg_pipe.steps[0][1].get_support()]
