2022.11.23 flask项目开发-语音识别
1.项目介绍:
1.flask语音识别功能:
1.选择wav语音文件,提交后会自动显示翻译结果
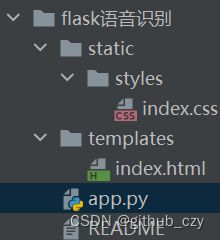
2.static文件夹保存静态文件
templates文件夹保存html代码
app.py是程序源代码及程序入口
3.涉及到speechrecognition,html,py
2.项目结构:
3.知识点:
1.在处理文件时打开线程
app.run(debug=True,threaded = True)
2.html中选择文件的其实也是表单
Upload new File
3.在py代码中获取post请求数据,并通过语音识别模块识别出来
1. 先对传递过来的数据进行处理和判断
1.#如果file不在请求里面,重定向到提交的页面
if "file" not in request.files:
return redirect(request.url)
用request.files获取表单传递的文件
request.url重定向
2. #如果提交的是空白文件
file = request.files["files"]
if file.filename == "":
return redirect(request.url)
用file.filename来判断是否是空文件
4.使用语音识别模块
if file:
#初始化
recognizer = sr.Recognizer()
#将文件转化为sr模块可以理解的方式
audiofile = sr.AudioFile(file)
with audiofile as source:
data = recognizer.record(audiofile)
text = recognizer.recognize_google(data,key=None)
print(text)5.下载要处理的音频文件
http://www.voiptroubleshooter.com/open_speech/chinese.html下载wav文件
https://online-audio-converter.com/将mp3文件转化为wav文件
6.css样式引入
问题:
1.没有反应,并返回302
file = request.files["files"]是这一行出现问题了
多打了一个s
2.speech_recognition.RequestError: recognition connection failed: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
进入源代码pyhon所在路径\Lib\site-packages\speech_recognition
在这个目录下,有一个__init__.py,打开这个文件,找到recognize_google()函数,这个函数中有一个url的变量,吧这个变量后面的网址"http://www.google.com/speech-api/v2/recognize?{}"改成"http://www.google.cn/speech-api/v2/recognize?{}"也就是把com改成cn这样就可以正常访问了
google.cn在中国才可以正常访问
查找pycharm安装位置是在C:\Users\HP\AppData\Local\Programs\Python\Python39\Lib\site-packages这里
3.又爆了个speech_recognition.RequestError: recognition request failed: Not Found
只能改用sphinx
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx下载安装包
pip3 install pocketsphinx-0.1.15-cp39-cp39-win_amd64.whl
修改后的py代码:
if file:
#初始化
recognizer = sr.Recognizer()
#将文件转化为sr模块可以理解的方式
audiofile = sr.AudioFile(file)
with audiofile as source:
data = recognizer.record(source)
# 使用Sphinx识别语音
try:
print("Sphinx识别结果为:" + recognizer.recognize_sphinx(data))
except sr.UnknownValueError:
print("无法识别音频")
except sr.RequestError as e:
print("识别错误; {0}".format(e))