zeromq 无锁队列源码解析
前言
在我刚学无锁队列的时候,在网上找了很多资料,但基本都是一上来就开始讲无锁队列的实现,这让我很困惑,到底什么是无锁队列呢,设计这玩意的意图是什么?接下来我将给大家好好分析一下无锁队列。
什么是无锁队列
无锁队列顾名思义,就是无锁+队列,队列有以下几种操作模型:
(1)单生产者单消费者

(2)多生产者单消费者
(3)单生产者多消费者
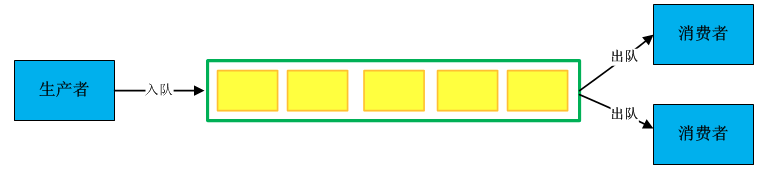
(4)多生产者多消费者

在我们实现生产者消费者模式的时候需要用到锁,来保证线程间的同步以及互斥
互斥:访问共享的队列的时候需要加锁
同步:(1)队列为空而消费者线程需要读取数据,此时应该阻塞消费者线程
(2)队列满了但生产者线程仍旧要往队列里添加数据,此时需要阻塞生产者线程
而设计无锁队列的意图就是不用锁来实现生产者消费者的问题
无锁队列的使用场景
无锁队列适用于1s大批量数据(1s 10w+)进入队列的场合,若数据量比较少(1s几百几千)的情况下就没必要使用无锁队列了,因为加锁的时间可以忽略不计了。
zeromq中无锁的设计思路(zeromq中的无锁队列只支持单生产者与单消费者)
在zeromq中,生产者可以任意生产,但消费者的读取存在限制,无锁实现的思路就是当消费者读取数据的时候,如果队列中元素为空,则返回false而不是用锁阻塞程序运行,之后在应用层由程序员根据返回的false让消费者等待一段时间(可以是sleep或者加锁),再重新开始运行,所以无锁队列只是在对共享变量的操作时候不用加锁。

zromq队列的实现
zeromq中yqueue.hpp中就是队列的实现,我们先来看看里面有哪些接口

队列中的chunk机制

yqueue由多个chunk构成,每个chunk都由N个元素组成,这样子的好处是每次malloc的时候会批量分配一批元素,减少内存的分配和释放,chunk与chunk的数据结构是双向链表,方便增加与查找。

在实际中的位置如图所示:

灰色表示填充数据的块,白色代表没有填充数据的块
back_pos 指向最后一个有数据的块
end_pos指向back_pos的后一位
![]()
spare_chunk指针,用于保存释放的chunk指针,当需要再次分配chunk的时候,会首先查看
这里,从这里分配chunk。这里使用了原子的cas操作来完成,利用了操作系统的局部性原理,意思是短暂
时间内队列的数据量是一个水平波动的过程。
其余函数与stl中queue的函数的名称与作用相同,且比较容易理解,这里不做过多介绍。
无锁队列ypipe的实现
在这之前要先讲讲cas(compare and set)操作
cas 在zeromq中用的是汇编来实现的

其内容转换为c语言是这样的:
int compare_and_swap (int* c, int com_, int val_)
{
int old_reg_val = *c;
if (old_reg_val == com_)
*c = val_;
return old_reg_val;
}
意思就是说,看一看c里的值是不是cmp_,如果是的话,则对其赋值val_,并返回c原来的值,如果不相等则直接返回c的值。
ypipe
现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。

主要变量
T *w :指向下一个能写入的元素的位置
T *r: 指向第一个能读取的元素
T *f:指向预写的第一个元素
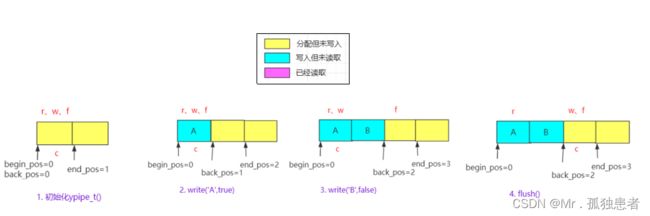
atomic_ptr_t c; 指向每一轮刷新的起点,正常读写的情况下c的值其实是一直等于w的,但当出现队列没有数据的情况下调用一次read后c的值才会变成NULL,这就表示读线程必然处于阻塞状态,所以返回false告诉程序员需要唤醒读线程。
flush()
inline bool flush(
{
// If there are no un-flushed items, do nothing.
if (w == f) // 不需要刷新,即是还没有新元素加入
return true;
// Try to set 'c' to 'f'.
// read时如果没有数据可以读取则c的值会被置为NULL
if (c.cas(w, f) != w) // 尝试将c设置为f,即是准备更新w的位置
{
//正常读写的情况下c的值其实是一直等于w的,但当出现队列没有数据的情况下调用一次read后c的值才会变成NULL,
//这就表示读线程必然处于阻塞状态,所以返回false告诉程序员需要唤醒读线程。
// Compare-and-swap was unseccessful because 'c' is NULL.
// This means that the reader is asleep. Therefore we don't
// care about thread-safeness and update c in non-atomic
// manner. We'll return false to let the caller know
// that reader is sleeping.
c.set(f); // 更新为新的f位置
w = f;
return false; //线程看到flush返回false之后会发送一个消息给读线程,这需要写业务去做处理
}
else // 读端还有数据可读取
{
//正常情况只需要把w更新为f表示预写入完成
// Reader is alive. Nothing special to do now. Just move
// the 'first un-flushed item' pointer to 'f'.
w = f; // 更新f的位置
return true;
}
}
check_read()
// 这里面有两个点,一个是检查是否有数据可读,一个是预取
inline bool check_read()
{
// queue.front() = r 表示数据读完了
if (&queue.front() != r && r) //判断是否在前几次调用read函数时已经预取数据了return true;
return true;
// There's no prefetched value, so let us prefetch more values.
// Prefetching is to simply retrieve the
// pointer from c in atomic fashion. If there are no
// items to prefetch, set c to NULL (using compare-and-swap).
// 两种情况
// 1. 如果c值和queue.front()相等, 返回c值并将c值置为NULL,此时没有数据可读
// 2. 如果c值和queue.front()不等, 返回c值,此时可能有数据能读
r = c.cas(&queue.front(), NULL); //尝试预取数据
// If there are no elements prefetched, exit.
// During pipe's lifetime r should never be NULL, however,
// it can happen during pipe shutdown when items are being deallocated.
if (&queue.front() == r || !r) //判断是否成功预取数据
return false;
// There was at least one value prefetched.
return true;
}
变化流程
代码理解有困难的化根据下图将数据代进去看看就行了。

测试无锁队列性能
void *mutexqueue_producer_thread(void *argv)
{
PRINT_THREAD_INTO();
for (int i = 0; i < s_queue_item_num; i++)
{
s_mutex.lock();
s_list.push_back(s_count_push);
s_count_push++;
s_mutex.unlock();
}
PRINT_THREAD_LEAVE();
return NULL;
}
void *mutexqueue_consumer_thread(void *argv)
{
int value = 0;
int last_value = 0;
int nodata = 0;
PRINT_THREAD_INTO();
while (true)
{
s_mutex.lock();
if (s_list.size() > 0)
{
value = s_list.front();
s_list.pop_front();
last_value =value;
s_count_pop++;
nodata = 0;
}
else
{
nodata = 1;
}
s_mutex.unlock();
if (nodata)
{
// usleep(1000);
sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
else
{
// printf("s_count_pop:%d, %d, %d\n", s_count_pop, s_queue_item_num, s_producer_thread_num);
}
}
printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
PRINT_THREAD_LEAVE();
return NULL;
}
#include "ypipe.hpp"
ypipe_t<int, 10000> yqueue;
void *yqueue_producer_thread(void *argv)
{
PRINT_THREAD_INTO();
int count = 0;
for (int i = 0; i < s_queue_item_num;)
{
yqueue.write(count, false); // enqueue的顺序是无法保证的,我们只能计算enqueue的个数
count = lxx_atomic_add(&s_count_push, 1);
i++;
yqueue.flush();
}
PRINT_THREAD_LEAVE();
return NULL;
}
void *yqueue_consumer_thread(void *argv)
{
int last_value = 0;
PRINT_THREAD_INTO();
while (true)
{
int value = 0;
if (yqueue.read(&value))
{
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1 && (last_value + 1) != value) // 只有一入一出的情况下才有对比意义
{
// printf("pid:%lu, -> value:%d, expected:%d\n", pthread_self(), value, last_value + 1);
}
lxx_atomic_add(&s_count_pop, 1);
last_value = value;
}
else
{
// printf("%s %lu no data, s_count_pop:%d\n", __FUNCTION__, pthread_self(), s_count_pop);
usleep(100);
// sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
}
PRINT_THREAD_LEAVE();
return NULL;
}
std::mutex ypipe_mutex_;
std::condition_variable ypipe_cond_;
void *yqueue_producer_thread_condition(void *argv)
{
PRINT_THREAD_INTO();
int count = 0;
for (int i = 0; i < s_queue_item_num;)
{
yqueue.write(count, false); // enqueue的顺序是无法保证的,我们只能计算enqueue的个数
count = lxx_atomic_add(&s_count_push, 1);
i++;
if(!yqueue.flush()) {
// printf("notify_one\n");
std::unique_lock<std::mutex> lock(ypipe_mutex_);
ypipe_cond_.notify_one();
}
}
std::unique_lock<std::mutex> lock(ypipe_mutex_);
ypipe_cond_.notify_one();
PRINT_THREAD_LEAVE();
return NULL;
}
void *yqueue_consumer_thread_condition(void *argv)
{
int last_value = 0;
PRINT_THREAD_INTO();
while (true)
{
int value = 0;
if (yqueue.read(&value))
{
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1 && (last_value + 1) != value) // 只有一入一出的情况下才有对比意义
{
// printf("pid:%lu, -> value:%d, expected:%d\n", pthread_self(), value, last_value + 1);
}
lxx_atomic_add(&s_count_pop, 1);
last_value = value;
}
else
{
// printf("%s %lu no data, s_count_pop:%d\n", __FUNCTION__, pthread_self(), s_count_pop);
// usleep(100);
std::unique_lock<std::mutex> lock(ypipe_mutex_);
printf("wait\n");
ypipe_cond_.wait(lock);
// sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
}
printf("%s dequeue: last_value:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
PRINT_THREAD_LEAVE();
return NULL;
}
int test_queue(thread_func_t func_push, thread_func_t func_pop, char **argv)
{
int64_t start = get_current_millisecond();
pthread_t tid_push[s_producer_thread_num] = {0};
for (int i = 0; i < s_producer_thread_num; i++)
{
int ret = pthread_create(&tid_push[i], NULL, func_push, argv);
if (0 != ret)
{
printf("create thread failed\n");
}
}
pthread_t tid_pop[s_consumer_thread_num] = {0};
for (int i = 0; i < s_consumer_thread_num; i++)
{
int ret = pthread_create(&tid_pop[i], NULL, func_pop, argv);
if (0 != ret)
{
printf("create thread failed\n");
}
}
for (int i = 0; i < s_producer_thread_num; i++)
{
pthread_join(tid_push[i], NULL);
}
for (int i = 0; i < s_consumer_thread_num; i++)
{
pthread_join(tid_pop[i], NULL);
}
int64_t end = get_current_millisecond();
int64_t temp = s_count_push;
int64_t ops = (temp * 1000) / (end - start);
printf("spend time : %ldms\t, push:%d, pop:%d, ops:%lu\n", (end - start), s_count_push, s_count_pop, ops);
return 0;
}
// ./test 1 1
int main(int argc, char **argv)
{
if (argc >= 4 && atoi(argv[3]) > 0)
s_queue_item_num = atoi(argv[3]);
if (argc >= 3 && atoi(argv[2]) > 0)
s_consumer_thread_num = atoi(argv[2]);
if (argc >= 2 && atoi(argv[1]) > 0)
s_producer_thread_num = atoi(argv[1]);
printf("\nthread num - producer:%d, consumer:%d, push:%d\n\n", s_producer_thread_num, s_consumer_thread_num, s_queue_item_num);
for (int i = 0; i < 1; i++)
{
s_count_push = 0;
s_count_pop = 0;
printf("\n\n--------->i:%d\n", i);
#if 1
printf("use mutexqueue ----------->\n");
test_queue(mutexqueue_producer_thread, mutexqueue_consumer_thread, NULL);
#endif
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1)
{
s_count_push = 0;
s_count_pop = 0;
printf("\nuse ypipe_t ----------->\n");
test_queue(yqueue_producer_thread, yqueue_consumer_thread, NULL);
s_count_push = 0;
s_count_pop = 0;
printf("\nuse ypipe_t condition ----------->\n");
test_queue(yqueue_producer_thread_condition, yqueue_consumer_thread_condition, NULL);
}
else
{
printf("\nypipe_t only support one write one read thread, bu you write %d thread and read %d thread so no test it ----------->\n",
s_producer_thread_num, s_consumer_thread_num);
}
}
printf("finish\n");
return 0;
}
测试结果
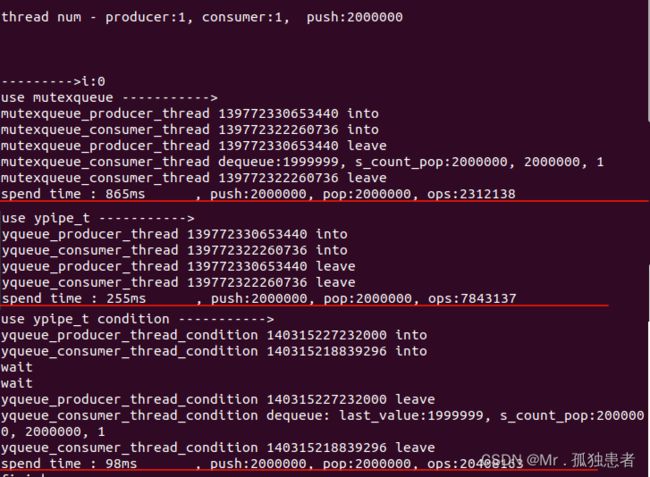
可见采用usleep的无锁队列速度快了三倍左右,而采用unique_lock()处理的无锁队列快了将近10倍。