电子病历结构化之实体识别(附完整项目代码)
对于医学领域的自然语言文献,例如医学教材、医学百科、临床病例、医学期刊、入院记录、检验报告等,这些文本中蕴含大量医学专业知识和医学术语。将实体识别技术与医学专业领域结合,利用机器读取医学文本,可以显著提高临床科研的效率和质量,并且可服务于下游子任务。医学领域中非结构化的文本,都是由中文自然语言句子或句子集合组成。实体抽取是从非结构化医学文本中找出医学实体,如疾病、症状的过程。
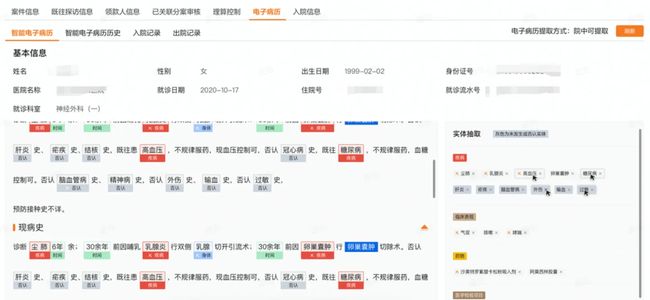
电子病历结构化解析
如上图所示,医院证明本文实现的是对案件的诊断,疾病,病历证明、入院记录(主诉,现病史,既往史等),出院记录(诊治过程)进行实体识别,并对疾病和体征的患者患病与否进行标注。
一、任务拆解
模块一: span-based 命名实体识别模型
- 该模块识别并抽取出与医学临床相关的实体,并将他们归类到预先定义好的类别。将医学文本命名实体划分为九大类,包括:疾病(dis),临床表现(sym),药物(dru),医疗设备(equ),医疗程序(pro),身体(bod),医学检验项目(ite),微生物类(mic),科室(dep)
数据集:Cblue-CmeEE
模型:Efficient GlobalPointe(Roberta wwm)
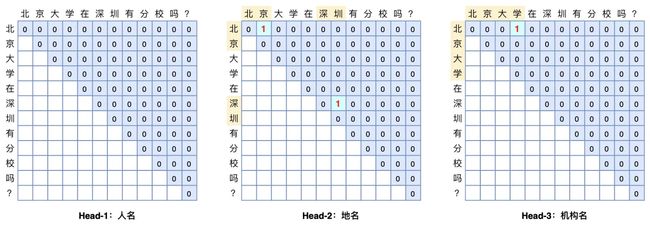
GlobalPointer多头识别嵌套实体
GlobalPointer是由苏剑林大佬提出来的一个span-based NER模型,可以很好的解决实体嵌套的问题,相比于"LSTM/BERT+CRF"的模型结构,GlobalPointer的设计更为优雅。
模型结构
如上图所示,右上三角的蓝色为序列中可能取到的实体,假设序列长度为 n ,则该序列能取到的可能的实体个数为 n(n+1)/2 个。假设有 m 种实体分类,则该问题转化为 m 个" n(n+1)/2 选 k "的问题。
序列encode我们通常用bert来做,encode过后,第 i 个位置和第 j 个位置的表示分别为 hi 和 hj ,通过变换, qi,α=Wq,αhi+bq,α 和 ki,α=Wk,αhi+bk,α ,每个span推断是实体的得分为 sα(i,j)=qi,α⊤kj,α 。其中 α 为实体的类别。
位置编码
仅仅是上面的得分还不够,如果不加入位置编码会造成“任意两个实体的首尾组合都当成目标预测出来”的问题。GlobalPointer加入了旋转位置编码-RoPE,进而引入位置信息。对于位置 i ,有变换矩阵 Ri ,满足关系Ri⊤Rj = Rj−i ,加入 q , k 中,有:
sα(i,j)=(Riqi,α)⊤(Rjkj,α)=qi,α⊤Ri⊤Rjkj,α=qi,α⊤Rj−ikj,α
损失函数
一个适用于多标签分类的损失函数,形式为
log(1+∑(i,j)∈Pαe−sα(i,j))+log(1+∑(i,j)∈Qαesα(i,j))
其中 Pα 是所有类型为 α 的实体首尾集合, Qα 是所有非实体或类型非 α 的实体首尾集合。
解码阶段,当 sα(i,j)>0 看作是实体的输出。
上面写的是概要模型结构,建议看原作者博客。见参考中链接
提交了CMeEE榜单,效果还ok
| 模型 | CMeEE-P | CMeEE-R | CMeEE-F1 |
| ernie | 62.560 | 69.538 | 65.865 |
| roberta_wwm | 67.104 | 66.460 | 66.780 |
2. 超长文本处理
bert模型由于位置编码的限制,不能处理超过512字符的长文本,但很多电子病历的长度往往超过bert能处理的最大长度。此处我们采用长文本分段,batch predict,拼接结果的方式解决这个问题。 假设请求参数中包含三段文本[0, 1, 2],其中0,2为长文本需要截成两断,即给出映射关系 {0: [1, 2], 1: [3], 2:[4, 5]}。将分割后的若干短句进行predict,再通过映射拼接还原。 关键代码如下:
def data_process(data, max_len):
mapping = OrderedDict() # 存文本与片段的映射列表
id = 0 # 记录第几个片段
sents = []
code_mapping = OrderedDict()
for i, d in enumerate(data):
code = d['code']
text = d['text']
lenth = len(text)
code_mapping[i] = code
if len(text) <= max_len:
mapping[i] = [id]
id += 1
sents.append(text)
continue
s_idx, e_idx = 0, max_len
while True:
sec = text[s_idx: e_idx]
if i not in mapping:
mapping[i] = [id]
else:
mapping[i].append(id)
id += 1
sents.append(sec)
if e_idx >= lenth: break
s_idx = e_idx
e_idx = min(lenth, e_idx+max_len)
return sents, mapping, code_mapping
def post_process(res, mapping, code_mapping, max_len):
entities_list = []
for k, v in mapping.items():
cur = []
start, end = v[0], v[-1]
for i, entities in enumerate(res[start: end+1]):
# 处理下标
for entity in entities:
entity['start_idx'] += max_len * i
entity['end_idx'] += max_len * i
cur += entities
entities_list.append({
"code": code_mapping[k],
"entities": cur
})
return entities_list模块二: 时间抽取
正则表达式方式抽取时间,正则表达式如下,共126个正则
class Regexparser():
def __init__(self, regex, logger=None):
'''
正则匹配的构造函数
:param regex: 加载正则,list形式, 用于正则匹配的结构为namedtuple
:param logger: 日志logger
'''
if logger is not None:
self.logger = logger
else:
self.logger = logging.getLogger('utils.time.parser')
Regex = namedtuple("Regex", ["pattern"])
self.re = []
for t in regex:
try:
pattern = re.compile(t)
except Exception as e:
self.logger.error("regex has some problem! %s\n%s" % (e, traceback.format_exc()))
continue
self.re.append(Regex(pattern=pattern))
self.logger.info('正则parser模块初始化完毕!')
def match_all(self, content):
'''
用批量正则匹配文本
:param content: 待匹配文本
:return: 匹配到的内容和位置,list形式返回
'''
info = []
for i in self.re:
result_finditer = i.pattern.finditer(content)
for k in result_finditer:
span = k.span()
info.append({'word': k.group(), 'start': span[0], 'end': span[1]})
ret = {
'text': content,
'entities': info
}
return ret模块三:后处理
- 负面实体判断
方法:分句,疾病/症状和负面前缀在同一句出现即否定疾病/症状,目前否定词为['无', '没有', '否认']。当然也可以用句法分析找出否定词和疾病/症状有无关联关系。
def neg_match(negword_list, entities, text):
'''
negword_list: 存放否定词
illness: 疾病
return: 若存在该疾病则返回True,否则返回False
'''
for r in entities:
# 拆短句
short_sentences = re.split(r'[,,::;;。]', text)
if r['type'] in ['dis', 'sym']:
flag = True
illness = r['entity']
for short_sentence in short_sentences:
for negword in negword_list:
if negword in short_sentence and illness in short_sentence:
r['is_neg'] = 'neg'
flag = False
if flag:
r['is_neg'] = 'pos'
return entities2. 贪心去重
正则表达式进行时间抽取会有两个问题:
- 不同正则表达式可能抽取相同的内容,即需要去重
- 相连的时间抽取成两个实体,需要把实体合并。如抽取“2021年”,“5月”,“1日”三个实体,应连起来为“2021年5月1日”
方法:贪心
def fixup(data):
'''
目前的问题为:
1. 去重
2. 合并相连的时间 如抽取2021年,5月,1日,连起来为2021年5月1日
:param :
:return:
'''
text, entities = data['text'], data['entities']
# 去重
info = []
for x in entities:
if x not in info: info.append(x)
if len(info) <= 1:
data = {
'text': text,
'entities': info
}
return data
ret = [info[0]]
# 合并挨着的实体
info.sort(key=lambda x: x['start'])
for x in info:
if ret[-1]['end'] >= x['start']:
start = ret[-1]['start']
end = max(ret[-1]['end'], x['end'])
ret[-1]['end'] = end
ret[-1]['word'] = text[start: end]
else:
ret.append(x)
# 为了和实体识别结果保持统一,end_span需要 -1
for x in ret: x['end'] -= 1
data = {
'text': text,
'entities': ret
}
return data
def combine_entities_time(text, entities, parser):
ret = parser.match_all(text)
ret = fixup(ret)
for r in ret['entities']:
entities.append({
"start_idx": r['start'],
"end_idx": r['end'],
"type": "time",
"entity": r['word'],
})
return entities二、GPU CUDA环境配置踩坑
- CUDA配置流程见参考
2. CPU指令集需要提单修改为Sandy Bridge,IvyBridge之类,否则tensor加载不到gpu。很坑。。。谷歌的方法尝试了一遍都不好使,bug太隐蔽了