论文笔记--An Overview of Cross-Media Retrieval: Concepts, Methodologies, ...-2018-(一)
论文信息:
论文-An Overview of Cross-Media Retrieval: Concepts, Methodologies, Benchmarks, and Challenges-2018-彭宇新
文末附50+篇跨媒体相关的英文论文下载地址
笔记包括两个部分。一是关于跨媒体检索相关概念和方法(1.1-1.7),二是跨媒体检索的实验和总结挑战(1.8-1.11)。整体目录如:
(一)跨媒体检索相关概念和方法
(二)跨媒体检索的实验和总结挑战
文章目录
- An Overview of Cross-Media Retrieval: Concepts, Methodologies, Benchmarks, and Challenges(一)
-
- 文献引用格式
- 摘要和目标
- 跨媒体检索定义
- 跨媒体检索相关工作
- 公共子空间学习(COMMON SPACE LEARNING, CSL)
- 跨媒体相似度衡量(CROSS-MEDIA SIMILARITY MEASUREMENT)
- 跨媒体检索的其它方法
- 资源
-
- 50+篇跨媒体相关英文论文
- 附:论文的参考文献
An Overview of Cross-Media Retrieval: Concepts, Methodologies, Benchmarks, and Challenges(一)
文献引用格式
Y. Peng, X. Huang and Y. Zhao, “An Overview of Cross-Media Retrieval: Concepts, Methodologies, Benchmarks, and Challenges,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 9, pp. 2372-2385, Sept. 2018. doi: 10.1109/TCSVT.2017.2705068
摘要和目标
摘要
跨媒体作为作为一项相对较新的研究主题,其概念,方法和基准在文献中尚不清楚。为解决这些问题,本文回顾了100多篇参考文献,概述了概念,方法,主要挑战和开放性问题,并建立了基准,包括数据集和实验结果。
本文构建了一个新的数据集XMedia,这是第一个公开可用的数据集,最多包含五种媒体类型(文本,图像,视频,音频和三维模型)。
目标
- 总结现有的工作和方法,以提供概述,这将有助于跨媒体检索的研究。
- 建立基准,包括数据集和实验结果。 这将有助于研究人员专注于算法设计,而不是耗时的比较方法和结果,因为他们可以直接采用基准来及时评估他们提出的方法。
- 提供新的数据集XMedia,以全面评估跨媒体检索。 这是第一个公开可用的数据集,包含多达五种媒体类型(文本,图像,视频,音频和3D模型)。
- 提出主要挑战和开放性问题,这对于跨媒体检索的进一步研究方向具有重要意义。
跨媒体检索定义
以两种媒体类型 X X X和 Y Y Y为例,训练数据可表示为 D t r = { X t r , Y t r } D_{tr}=\{X_{tr},Y_{tr}\} Dtr={Xtr,Ytr}其中 X t r = { x p } p = 1 n t r X_{tr}=\{x_{p}\}^{n_{tr}}_{p=1} Xtr={xp}p=1ntr, Y t r = { y p } p = 1 n t r Y_{tr}=\{y_{p}\}^{n_{tr}}_{p=1} Ytr={yp}p=1ntr。 n t r n_{tr} ntr表示用于训练的媒体实例的数量,并且 x p x_p xp表示第 p p p个媒体实例。 x p x_p xp和 y p y_p yp之间存在共存关系,这意味着不同媒体类型的实例一起存在以描述相关语义。
另外,提供训练数据的语义类别标签,表示为 { c p X } p = 1 n t r \{c^X_p\}^{n_{tr}}_{p=1} {cpX}p=1ntr和 { c p Y } p = 1 n t r \{c^Y_p\}^{n_{tr}}_{p=1} {cpY}p=1ntr,其指示媒体实例所属的语义类别。
类似地,测试数据表示为 D t e = { X t e , Y t e } D_{te}=\{X_{te},Y_{te}\} Dte={Xte,Yte},其中 X t e = { x p } p = 1 n t e X_{te}=\{x_{p}\}^{n_{te}}_{p=1} Xte={xp}p=1nte, Y t e = { y p } p = 1 n t e Y_{te}=\{y_{p}\}^{n_{te}}_{p=1} Yte={yp}p=1nte。
而我们的目标是计算跨媒体相似度 s i m ( x a , x b ) sim(x_a,x_b) sim(xa,xb),并在测试数据中检索不同媒体类型的相关实例以用于任何媒体类型的一个查询。
跨媒体检索相关工作
下图是从论文中截取的跨媒体检索相关工作。其中U表示无监督学习,S表示半监督学习,F表示监督学习方法,R是涉及相关反馈的方法(下一节同)。
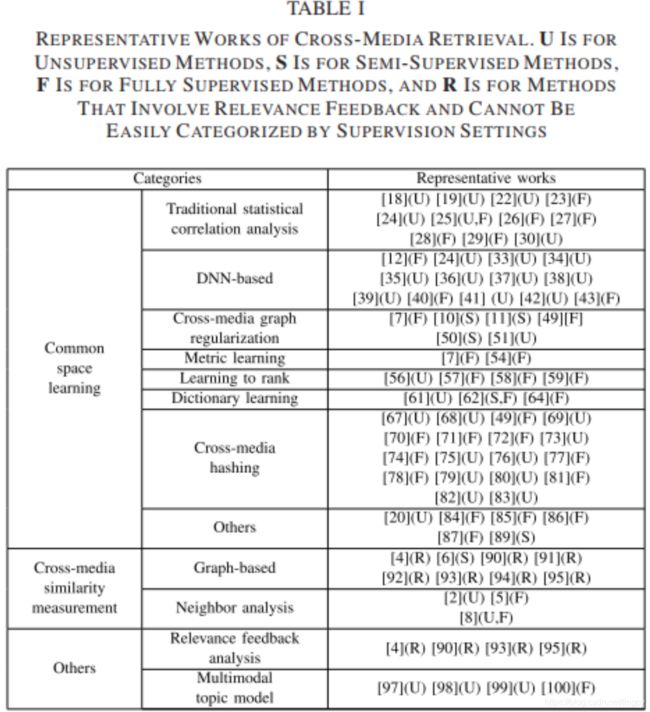
公共子空间学习(COMMON SPACE LEARNING, CSL)
基于公共空间学习的方法目前是跨媒体检索的主流。本文主要介绍现有方法的七大类,表1.1给出了这7种方法的详细描述,其中优缺点是笔者总结的。
| 方法名称 | 简介 | 相关论文 | 优缺点 |
|---|---|---|---|
| Traditional Statistical Correlation Analysis Methods (CCA) | 传统的统计相关分析方法是CSL的基本范式和基础,主要通过优化统计值来学习公共空间的线性投影矩阵。 | U:[18][19][22][24][30] F:[23][26][27][28][29] U-F:[25] | 优:相对有效,容易训练和实施 缺:难以模拟跨媒体数据复杂的相关性,大多数只能模拟两种媒体类型 |
| DNN-based | 基于DNN的方法以深度神经网络为基本模型,旨在利用其强大的抽象能力进行跨媒体相关学习。 | U:[24][33][34][35][36][37][38][39][41][42] F:[12][40][43] | 优: 具有处理复杂跨媒体相关性的抽象能力 缺: 暂定 |
| Cross-Media Graph Regularization Methods | 跨媒体图正则化方法采用图模型来表示复杂的跨媒体相关性 | U:[51] F:[7][49] | 优:可以模拟两种以上媒体类型 缺:时间和空间开销较大 |
| Metric Learning Methods | 度量学习方法将跨媒体关联视为一组相似/不相似的约束 | F:[7][54] | 优:保留了语义相似信息 缺:较多依赖于监督信息 |
| Learning to Rank Methods | 排序学习方法的重点是跨媒体排名信息作为他们的优化目标(对象) | U:[56] F:[57][58][59] | 优:提升最终检索性能 缺:一般应用于两种媒体类型 |
| Dictionary Learning Methods | 字典学习方法生成字典和学习的公共空间用于(解决)跨媒体数据的稀疏度 | U:[61] F:[64] S-F:[62] | 优:效率高? 缺:数据量大的优化问题是一个挑战 |
| Cross-Media Hashing Methods | 跨媒体散列(哈希)方法旨在学习共同的汉明空间以加速检索 | U:[67][68][69][73][75][76][79][80][82][83] F:[49][70][71][72][74][77][78][81] | 优:在大规模数据集检索效率高 缺:小数据集发挥不出效率高的优势 |
| Other Methods | 其它方法 | U:[20] S:[89] F:[84][85][86][87] | …… |
跨媒体相似度衡量(CROSS-MEDIA SIMILARITY MEASUREMENT)
跨媒体相似性计算方法旨在直接计算异构数据的相似性,而无需将媒体实例从其单独的空间直接投影到公共空间。因为没有公共空间,所以不能通过距离测量或正常分类器直接计算跨媒体相似性。一种直观的方法是使用数据集中的已知媒体实例和相关性作为桥接“媒体鸿沟”的基础。
用于跨媒体相似性测量的现有方法通常采用使用图中的边来表示媒体实例和多媒体文档(MMD)之间的关系的思想。根据方法的不同侧重点,我们进一步将它们分为两类:(A)基于图的方法(Graph-based methods),其侧重于图的构造,(B)邻近分析方法(neighbor analysis methods)主要考虑如何利用数据的邻居关系相似度量。这两个类别在算法过程中具有重叠,因为可以在构造的图中分析邻居关系。
以上两类方法的介绍如表1.2所示。
| 方法名称 | 简介 | 相关论文 | 优缺点 |
|---|---|---|---|
| Graph-based methods | 基于图的方法的基本思想是将跨媒体数据视为一个或多个图中的顶点,并且边是由跨媒体数据的相关性构成 | S:[6]R:[4][90][91][92][93][94][95] | 优:对合并不同类型信息有帮助 缺:时间和空间开销较大;现实场景中存在挑战 |
| neighbor analysis methods | 邻居分析方法通常基于图构造,因为可以在给定图中分析邻居。该方法侧重于使用邻域关系进行相似性测量 | U:[2] F:[5] U-F:[8] | 优:方法灵活 缺:时间和空间开销较大;确保邻居的相关关系困难,性能不稳定 |
跨媒体检索的其它方法
介绍两种其它方法:(A)相关反馈分析是一种辅助方法,用于提供有关用户意图的更多信息,以提高检索性能。 (B)多模式主题模型在主题级别中查看跨媒体数据,并且通常通过计算条件概率来获得跨媒体相似性。这两种具体方法描述如表1.3所示。
| 方法名称 | 简介 | 相关论文 | 优缺点 |
|---|---|---|---|
| Relevance Feedback Analysis | 相关反馈广泛应用于跨媒体相似性测量。包括短期和长期两种反馈类型 | R:[4][90][93][95] | 优:提供更准确的信息,有助于提高检索准确性 缺:需要一些人工成本 |
| Multimodal Topic Model | LDA模型在多模态领域的扩展 | U:[97][98][99] F:[100] | 优:论文中未提到 缺:跨媒体主题分布的约束条件… |
资源
50+篇跨媒体相关英文论文
下载地址
附:论文的参考文献
[1] M. S. Lew, N. Sebe, C. Djeraba, and R. Jain, “Content-based multimedia information retrieval: State of the art and challenges,” ACM Trans. Multimedia Comput., Commun., Appl., vol. 2, no. 1, pp. 1–19, 2006.
[2] S. Clinchant, J. Ah-Pine, and G. Csurka, “Semantic combination of textual and visual information in multimedia retrieval,” in Proc. ACM Int. Conf. Multimedia Retr. (ICMR), 2011, p. 44.
[3] Y. Liu, W.-L. Zhao, C.-W. Ngo, C.-S. Xu, and H.-Q. Lu, “Coherent bagof audio words model for efficient large-scale video copy detection,” in Proc. ACM Int. Conf. Image Video Retr. (CIVR), 2010, pp. 89–96.
[4] Y. Yang, D. Xu, F. Nie, J. Luo, and Y. Zhuang, “Ranking with local regression and global alignment for cross media retrieval,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2009, pp. 175–184.
[5] X. Zhai, Y. Peng, and J. Xiao, “Effective heterogeneous similarity measure with nearest neighbors for cross-media retrieval,” in Proc. Int. Conf. MultiMedia Modeling (MMM), 2012, pp. 312–322.
[6] X. Zhai, Y. Peng, and J. Xiao, “Cross-modality correlation propagation for cross-media retrieval,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Mar. 2012, pp. 2337–2340.
[7] X. Zhai, Y. Peng, and J. Xiao, “Heterogeneous metric learning with joint graph regularization for cross-media retrieval,” in Proc. AAAI Conf. Artif. Intell. (AAAI), 2013, pp. 1198–1204.
[8] D. Ma, X. Zhai, and Y. Peng, “Cross-media retrieval by cluster-based correlation analysis,” in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2013, pp. 3986–3990.
[9] X. Zhai, Y. Peng, and J. Xiao, “Cross-media retrieval by intra-media and inter-media correlation mining,” Multimedia Syst., vol. 19, no. 5, pp. 395–406, Oct. 2013.
[10] X. Zhai, Y. Peng, and J. Xiao, “Learning cross-media joint representation with sparse and semisupervised regularization,” IEEE Trans. Circuits Syst. Video Technol., vol. 24, no. 6, pp. 965–978, Jun. 2014.
[11] Y. Peng, X. Zhai, Y. Zhao, and X. Huang, “Semi-supervised crossmedia feature learning with unified patch graph regularization,” IEEE Trans. Circuits Syst. Video Technol., vol. 26, no. 3, pp. 583–596, Mar. 2016.
[12] Y. Peng, X. Huang, and J. Qi, “Cross-media shared representation by hierarchical learning with multiple deep networks,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2016, pp. 3846–3853.
[13] J. Jeon, V. Lavrenko, and R. Manmatha, “Automatic image annotation and retrieval using cross-media relevance models,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2003, pp. 119–126.
[14] J. Mao, W. Xu, Y. Yang, J. Wang, Z. Huang, and A. Yuille. (2014). “Deep captioning with multimodal recurrent neural networks (m-RNN).” [Online]. Available: https://arxiv.org/abs/1412.6632
[15] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 3156–3164.
[16] J. Tang, X. Shu, Z. Li, G.-J. Qi, and J. Wang, “Generalized deep transfer networks for knowledge propagation in heterogeneous domains,” ACM Trans. Multimedia Comput., Commun., Appl., vol. 12, no. 4s, pp. 68:1–68:22, 2016.
[17] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Trans. Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, Oct. 2010.
[18] H. Hotelling, “Relations between two sets of variates,” Biometrika, vol. 28, nos. 3–4, pp. 321–377, 1936.
[19] D. R. Hardoon, S. Szedmak, and J. Shawe-Taylor, “Canonical correlation analysis: An overview with application to learning methods,” Neural Comput., vol. 16, no. 12, pp. 2639–2664, 2004.
[20] Y. Verma and C. V. Jawahar, “Im2Text and Text2Im: Associating images and texts for cross-modal retrieval,” in Proc. Brit. Mach. Vis. Conf. (BMVC), 2014, pp. 1–13.
[21] B. Klein, G. Lev, G. Sadeh, and L. Wolf, “Associating neural word embeddings with deep image representations using fisher vectors,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 4437–4446.
[22] S. Akaho. (2006). “A kernel method for canonical correlation analysis.” [Online]. Available: https://arxiv.org/abs/cs/0609071
[23] N. Rasiwasia, D. Mahajan, V. Mahadevan, and G. Aggarwal, “Cluster canonical correlation analysis,” in Proc. Int. Conf. Artif. Intell. Statist. (AISTATS), 2014, pp. 823–831.
[24] G. Andrew, R. Arora, J. Bilmes, and K. Livescu, “Deep canonical correlation analysis,” in Proc. Int. Conf. Mach. Learn. (ICML), 2010, pp. 3408–3415.
[25] Y. Gong, Q. Ke, M. Isard, and S. Lazebnik, “A multi-view embedding space for modeling Internet images, tags, and their semantics,” Int. J. Comput. Vis., vol. 106, no. 2, pp. 210–233, Jan. 2014.
[26] V. Ranjan, N. Rasiwasia, and C. V. Jawahar, “Multi-label cross-modal retrieval,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015,pp. 4094–4102.
[27] N. Rasiwasia et al., “A new approach to cross-modal multimedia retrieval,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2010, pp. 251–260.
[28] J. C. Pereira et al., “On the role of correlation and abstraction in crossmodal multimedia retrieval,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 3, pp. 521–535, Mar. 2014.
[29] A. Sharma, A. Kumar, H. Daume, III, and D. W. Jacobs, “Generalized multiview analysis: A discriminative latent space,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2012, pp. 2160–2167.
[30] D. Li, N. Dimitrova, M. Li, and I. K. Sethi, “Multimedia content processing through cross-modal association,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2003, pp. 604–611.
[31] A. Frome et al., “DeViSE: A deep visual-semantic embedding model,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2013, pp. 2121–2129.
[32] R. Kiros, R. Salakhutdinov, and R. Zemel, “Multimodal neural language models,” in Proc. Int. Conf. Mach. Learn. (ICML), 2014, pp. 595–603.
[33] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deep learning,” in Proc. Int. Conf. Mach. Learn. (ICML), 2011, pp. 689–696.
[34] N. Srivastava and R. Salakhutdinov, “Multimodal learning with deep boltzmann machines,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2012, pp. 2222–2230.
[35] F. Yan and K. Mikolajczyk, “Deep correlation for matching images and text,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 3441–3450.
[36] F. Feng, X. Wang, and R. Li, “Cross-modal retrieval with correspondence autoencoder,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 7–16.
[37] H. Zhang, Y. Yang, H. Luan, S. Yang, and T.-S. Chua, “Start from scratch: Towards automatically identifying, modeling, and naming visual attributes,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 187–196.
[38] W. Wang, R. Arora, K. Livescu, and J. A. Bilmes, “On deep multiview representation learning,” in Proc. Int. Conf. Mach. Learn. (ICML), 2015, pp. 1083–1092.
[39] F. Wu et al., “Learning of multimodal representations with random walks on the click graph,” IEEE Trans. Image Process., vol. 25, no. 2, pp. 630–642, Feb. 2016.
[40] Y. Wei et al., “Cross-modal retrieval with CNN visual features: A new baseline,” IEEE Trans. Cybern., vol. 47, no. 2, pp. 449–460, Feb. 2017.
[41] Y. He, S. Xiang, C. Kang, J. Wang, and C. Pan, “Cross-modal retrieval via deep and bidirectional representation learning,” IEEE Trans. Multimedia, vol. 18, no. 7, pp. 1363–1377, Jul. 2016.
[42] W. Wang, B. C. Ooi, X. Yang, D. Zhang, and Y. Zhuang, “Effective multi-modal retrieval based on stacked auto-encoders,” in Proc. Int. Conf. Very Large Data Bases (VLDB), 2014, pp. 649–660.
[43] L. Castrejon, Y. Aytar, C. Vondrick, H. Pirsiavash, and A. Torralba, “Learning aligned cross-modal representations from weakly aligned data,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 2940–2949.
[44] S. E. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee, “Generative adversarial text to image synthesis,” in Proc. Int. Conf. Mach. Learn. (ICML), 2016, pp. 1060–1069.
[45] S. E. Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele, and H. Lee, “Learning what and where to draw,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2016, pp. 217–225.
[46] I. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2014, pp. 2672–2680.
[47] I. Goodfellow. (2017). “NIPS 2016 tutorial: Generative adversarial networks.” [Online]. Available: https://arxiv.org/abs/1701.00160
[48] M. Belkin, I. Matveeva, and P. Niyogi, “Regularization and semisupervised learning on large graphs,” Learning Theory. Berlin, Germany: Springer, 2004, pp. 624–638.
[49] F. Wu, Z. Yu, Y. Yang, S. Tang, Y. Zhang, and Y. Zhuang, “Sparse multi-modal hashing,” IEEE Trans. Multimedia, vol. 16, no. 2, pp. 427–439, Feb. 2014.
[50] K. Wang, R. He, L. Wang, W. Wang, and T. Tan, “Joint feature selection and subspace learning for cross-modal retrieval,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 10, pp. 2010–2023, Oct. 2015.
[51] J. Liang, Z. Li, D. Cao, R. He, and J. Wang, “Self-paced cross-modal subspace matching,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2016, pp. 569–578.
[52] N. Quadrianto and C. H. Lamppert, “Learning multi-view neighborhood preserving projections,” in Proc. Int. Conf. Mach. Learn. (ICML), 2011, pp. 425–432.
[53] B. McFee and G. Lanckriet, “Metric learning to rank,” in Proc. Int. Conf. Mach. Learn. (ICML), 2010, pp. 775–782.
[54] W. Wu, J. Xu, and H. Li, “Learning similarity function between objects in heterogeneous spaces,” Microsoft Res., Redmond, WA, USA, Tech. Rep. MSR-TR-2010-86, 2010.
[55] B. Bai et al., “Learning to rank with (a lot of) word features,” Inf. Retr., vol. 13, no. 3, pp. 291–314, Jun. 2010.
[56] D. Grangier and S. Bengio, “A discriminative kernel-based approach to rank images from text queries,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 30, no. 8, pp. 1371–1384, Aug. 2008.
[57] F. Wu, X. Lu, Z. Zhang, S. Yan, Y. Rui, and Y. Zhuang, “Cross-media semantic representation via bi-directional learning to rank,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2013, pp. 877–886.
[58] X. Jiang et al., “Deep compositional cross-modal learning to rank via local-global alignment,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2015, pp. 69–78.
[59] F. Wu et al., “Cross-modal learning to rank via latent joint representation,” IEEE Trans. Image Process., vol. 24, no. 5, pp. 1497–1509, May 2015.
[60] G. Monaci, P. Jost, P. Vandergheynst, B. Mailhe, S. Lesage, and R. Gribonval, “Learning multimodal dictionaries,” IEEE Trans. Image Process., vol. 16, no. 9, pp. 2272–2283, Sep. 2007.
[61] Y. Jia, M. Salzmann, and T. Darrell, “Factorized latent spaces with structured sparsity,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2010, pp. 982–990.
[62] F. Zhu, L. Shao, and M. Yu, “Cross-modality submodular dictionary learning for information retrieval,” in Proc. ACM Int. Conf. Conf. Inf. Knowl. Manage. (CIKM), 2014, pp. 1479–1488.
[63] S. Wang, L. Zhang, Y. Liang, and Q. Pan, “Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2012, pp. 2216–2223.
[64] Y. Zhuang, Y. Wang, F. Wu, Y. Zhang, and W. Lu, “Supervised coupled dictionary learning with group structures for multi-modal retrieval,” in Proc. AAAI Conf. Artif. Intell. (AAAI), 2013, pp. 1070–1076.
[65] J. Wang, W. Liu, S. Kumar, and S.-F. Chang, “Learning to hash for indexing big data—A survey,” Proc. IEEE, vol. 104, no. 1, pp. 34–57, Jan. 2016.
[66] J. Tang, Z. Li, M. Wang, and R. Zhao, “Neighborhood discriminant hashing for large-scale image retrieval,” IEEE Trans. Image Process., vol. 24, no. 9, pp. 2827–2840, Sep. 2015.
[67] S. Kumar and R. Udupa, “Learning hash functions for cross-view similarity search,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2011, pp. 1360–1365.
[68] D. Zhang, F. Wang, and L. Si, “Composite hashing with multiple information sources,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2011, pp. 225–234.
[69] Y. Zhen and D.-Y. Yeung, “Co-regularized hashing for multimodal data,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2012, pp. 1376–1384.
[70] Y. Hu, Z. Jin, H. Ren, D. Cai, and X. He, “Iterative multiview hashing for cross media indexing,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 527–536.
[71] Y. Zhen and D.-Y. Yeung, “A probabilistic model for multimodal hash function learning,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining (SIGKDD), 2012, pp. 940–948.
[72] Z. Yu, F. Wu, Y. Yang, Q. Tian, J. Luo, and Y. Zhuang, “Discriminative coupled dictionary hashing for fast cross-media retrieval,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2014, pp. 395–404.
[73] M. Long, Y. Cao, J. Wang, and P. S. Yu, “Composite correlation quantization for efficient multimodal retrieval,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2016, pp. 579–588.
[74] M. M. Bronstein, A. M. Bronstein, F. Michel, and N. Paragios, “Data fusion through cross-modality metric learning using similarity-sensitive hashing,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2010, pp. 3594–3601.
[75] M. Rastegari, J. Choi, S. Fakhraei, D. Hal, and L. Davis, “Predictable dual-view hashing,” in Proc. Int. Conf. Mach. Learn. (ICML), 2013, pp. 1328–1336.
[76] G. Ding, Y. Guo, and J. Zhou, “Collective matrix factorization hashing for multimodal data,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2014, pp. 2083–2090.
[77] D. Zhai, H. Chang, Y. Zhen, X. Liu, X. Chen, and W. Gao, “Parametric local multimodal hashing for cross-view similarity search,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2013, pp. 2754–2760.
[78] Y. Zhuang, Z. Yu, W. Wang, F. Wu, S. Tang, and J. Shao, “Crossmedia hashing with neural networks,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 901–904.
[79] Q. Wang, L. Si, and B. Shen, “Learning to hash on partial multimodal data,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2015, pp. 3904–3910.
[80] D. Wang, X. Gao, X. Wang, and L. He, “Semantic topic multimodal hashing for cross-media retrieval,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2015, pp. 3890–3896.
[81] H. Liu, R. Ji, Y. Wu, and G. Hua, “Supervised matrix factorization for cross-modality hashing,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2016, pp. 1767–1773.
[82] D. Wang, P. Cui, M. Ou, and W. Zhu, “Deep multimodal hashing with orthogonal regularization,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), 2015, pp. 2291–2297.
[83] J. Zhou, G. Ding, and Y. Guo, “Latent semantic sparse hashing for cross-modal similarity search,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2014, pp. 415–424.
[84] L. Zhang, Y. Zhao, Z. Zhu, S. Wei, and X. Wu, “Mining semantically consistent patterns for cross-view data,” IEEE Trans. Knowl. Data Eng., vol. 26, no. 11, pp. 2745–2758, Nov. 2014.
[85] C. Kang, S. Xiang, S. Liao, C. Xu, and C. Pan, “Learning consistent feature representation for cross-modal multimedia retrieval,” IEEE Trans. Multimedia, vol. 17, no. 3, pp. 370–381, Mar. 2015.
[86] Y. Hua, S. Wang, S. Liu, Q. Huang, and A. Cai, “TINA: Cross-modal correlation learning by adaptive hierarchical semantic aggregation,” in Proc. IEEE Int. Conf. Data Mining (ICDM), Dec. 2014, pp. 190–199.
[87] Y. Wei et al., “Modality-dependent cross-media retrieval,” ACM Trans. Intell. Syst. Technol., vol. 7, no. 4, pp. 57:1–57:13, 2016.
[88] J. H. Ham, D. D. Lee, and L. K. Saul, “Semisupervised alignment of manifolds,” in Proc. Int. Conf. Uncertainty Artif. Intell. (UAI), vol. 10. 2005, pp. 120–127.
[89] X. Mao, B. Lin, D. Cai, X. He, and J. Pei, “Parallel field alignment for cross media retrieval,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2013, pp. 897–906.
[90] Y.-T. Zhuang, Y. Yang, and F. Wu, “Mining semantic correlation of heterogeneous multimedia data for cross-media retrieval,” IEEE Trans. Multimedia, vol. 10, no. 2, pp. 221–229, Feb. 2008.
[91] H. Tong, J. He, M. Li, C. Zhang, and W.-Y. Ma, “Graph based multimodality learning,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2005, pp. 862–871.
[92] Y. Yang, F. Wu, D. Xu, Y. Zhuang, and L.-T. Chia, “Cross-media retrieval using query dependent search methods,” Pattern Recognit., vol. 43, no. 8, pp. 2927–2936, Aug. 2010.
[93] Y. Yang, F. Nie, D. Xu, J. Luo, Y. Zhuang, and Y. Pan, “A multimedia retrieval framework based on semi-supervised ranking and relevance feedback,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 4, pp. 723–742, Apr. 2012.
[94] Y. Zhuang, H. Shan, and F. Wu, “An approach for cross-media retrieval with cross-reference graph and pagerank,” in Proc. IEEE Int. Conf. Multi-Media Modelling (MMM), Jan. 2006, pp. 161–168.
[95] Y. Yang, Y.-T. Zhuang, F. Wu, and Y.-H. Pan, “Harmonizing hierarchical manifolds for multimedia document semantics understanding and cross-media retrieval,” IEEE Trans. Multimedia, vol. 10, no. 3, pp. 437–446, Apr. 2008.
[96] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent Dirichlet allocation,” J. Mach. Learn. Res., vol. 3, pp. 993–1022, Mar. 2003.
[97] D. M. Blei and M. I. Jordan, “Modeling annotated data,” in Proc. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. (SIGIR), 2003, pp. 127–134.
[98] D. Putthividhy, H. T. Attias, and S. S. Nagarajan, “Topic regression multi-modal latent Dirichlet allocation for image annotation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2010, pp. 3408–3415.
[99] Y. Jia, M. Salzmann, and T. Darrell, “Learning cross-modality similarity for multinomial data,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Nov. 2011, pp. 2407–2414.
[100] Y. Wang, F. Wu, J. Song, X. Li, and Y. Zhuang, “Multi-modal mutual topic reinforce modeling for cross-media retrieval,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 307–316.
[101] T.-S. Chua, J. Tang, R. Hong, H. Li, Z. Luo, and Y. Zheng, “Nuswide: A real-world Web image database from national University of Singapore,” in Proc. ACM Int. Conf. Image Video Retr. (CIVR), 2009, p. 48.
[102] G. A. Miller, “WordNet: A lexical database for English,” Commun. ACM, vol. 38, no. 11, pp. 39–41, 1995.
[103] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The Pascal visual object classes (VOC) challenge,” Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, Sep. 2009.
[104] X. Hua et al., “Clickage: Towards bridging semantic and intent gaps via mining click logs of search engines,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2013, pp. 243–252.
[105] Y. Pan, T. Yao, X. Tian, H. Li, and C. Ngo, “Click-throughbased subspace learning for image search,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 233–236.
[106] G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller, “Labeled faces in the wild: A database for studying face recognition in unconstrained environments,” Dept. Comput. Sci., Univ. Massachusetts, Amherst, MA, USA, Tech. Rep. 07-49, 2007.
[107] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2009, pp. 248–255.