核回归注意力机制
文章目录
- 注意力机制
-
- 1.1注意力提示
-
- 1.1.1生物学中的注意力提示
- 1.1.2查询、键和值
- 1.2注意力汇聚:Nadataya-Watson核回归
-
- 1.2.1生成数据集
- 1.2.2非参数注意力汇聚
注意力机制
灵长类动物的视觉系统接受了大量的感官输入, 这些感官输入远远超过了大脑能够完全处理的程度。 然而,并非所有刺激的影响都是相等的。 意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感兴趣的物体,例如猎物和天敌。 只关注一小部分信息的能力对进化更加有意义,使人类得以生存和成功。
自19世纪以来,科学家们一直致力于研究认知神经科学领域的注意力。 本章的很多章节将涉及到这些研究: 我们将首先回顾一个经典注意力框架,解释如何在视觉场景中展开注意力。 受此框架中的注意力提示(attention cues)的启发, 我们将设计能够利用这些注意力提示的模型。 1964年的Nadaraya-Waston核回归(kernel regression)正是具有 注意力机制(attention mechanism)的机器学习的简单演示。
然后,我们继续介绍的是注意力函数,它们在深度学习的注意力模型设计中被广泛使用。 具体来说,我们将展示如何使用这些函数来设计Bahdanau注意力。 Bahdanau注意力是深度学习中的具有突破性价值的注意力模型,它双向对齐并且可以微分。
最后,我们将描述仅仅基于注意力机制的transformer架构, 该架构中使用了多头注意力(multi-head attention) 和自注意力(self-attention)。 自2017年横空出世,transformer一直都普遍存在于现代的深度学习应用中, 例如语言、视觉、语音和强化学习领域。
1.1注意力提示
自经济学研究稀缺资源分配以来,我们正处在“注意力经济”时代, 即人类的注意力被视为可以交换的、有限的、有价值的且稀缺的商品。 许多商业模式也被开发出来去利用这一点: 在音乐或视频流媒体服务上,我们要么消耗注意力在广告上,要么付钱来隐藏广告; 为了在网络游戏世界的成长,我们要么消耗注意力在游戏战斗中, 从而帮助吸引新的玩家,要么付钱立即变得强大。 总之,注意力不是免费的。
注意力是稀缺的,而环境中的干扰注意力的信息却并不少。 比如我们的视觉神经系统大约每秒收到 1 0 8 10^8 108位的信息, 这远远超过了大脑能够完全处理的水平。 幸运的是,我们的祖先已经从经验(也称为数据)中认识到 “并非感官的所有输入都是一样的”。 在整个人类历史中,这种只将注意力引向感兴趣的一小部分信息的能力, 使我们的大脑能够更明智地分配资源来生存、成长和社交, 例如发现天敌、找寻食物和伴侣。
1.1.1生物学中的注意力提示
非自主性提示是基于环境中物体的突出性和易见性。 想象一下,假如你面前有五个物品: 一份报纸、一篇研究论文、一杯咖啡、一本笔记本和一本书, 如下图。 所有纸制品都是黑白印刷的,但咖啡杯是红色的。 换句话说,这个咖啡杯在这种视觉环境中是突出和显眼的, 不由自主地引起人们的注意。 所以你把视力最敏锐的地方放到咖啡上, 如 图所示。
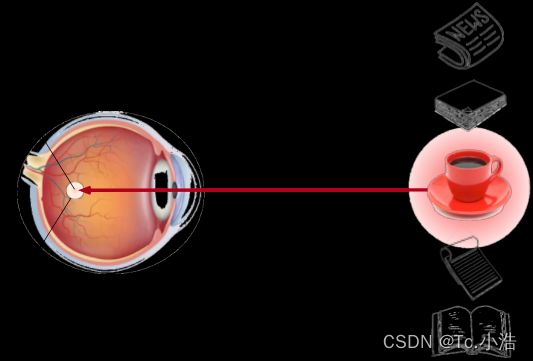
上图由于突出性的非自主性提示(红杯子),注意力不自主的指向了咖啡杯
喝咖啡后,你会变得兴奋并想读书。 所以你转过头,重新聚焦你的眼睛,然后看看书, 就像下图中描述那样。 与上图中由于突出性导致的选择不同, 此时选择书是受到了认知和意识的控制, 因此注意力在基于自主性提示去辅助选择时将更为谨慎。 受试者的主观意愿推动,选择的力量也就更强大。
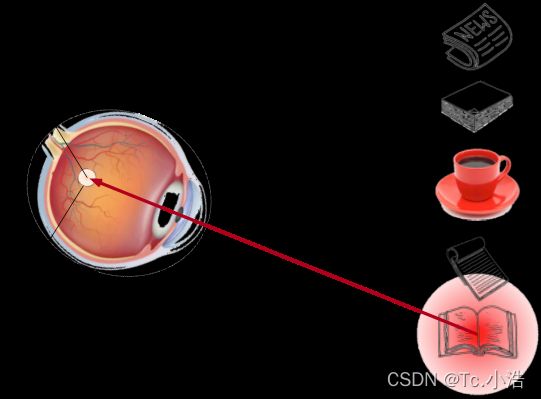
依赖于任务的意志提示(想读一本书),注意力被自主引导到书上
1.1.2查询、键和值
自主性的与非自主性的注意力提示解释了人类的注意力的方式, 下面我们看看如何通过这两种注意力提示, 用神经网络来设计注意力机制的框架,
首先,考虑一个相对简单的状况, 即只使用非自主性提示。 要想将选择偏向于感官输入, 我们可以简单地使用参数化的全连接层, 甚至是非参数化的最大汇聚层(池化层)或平均汇聚层。
因此,“是否包含自主性提示”将注意力机制与全连接层或汇聚层区别开来。 在注意力机制的背景下,我们将自主性提示称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。 在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。 如下图所示,我们可以设计注意力汇聚, 以便给定的查询(自主性提示)可以与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)。
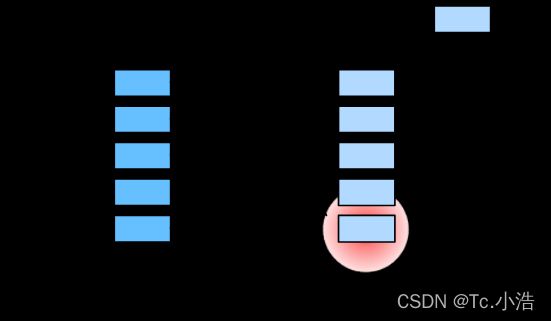
注意力机制通过注意力汇聚将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向。
1.2注意力汇聚:Nadataya-Watson核回归
具体来说,1964年提出的Nadaraya-Watson核回归模型 是一个简单但完整的例子,可以用于演示具有注意力机制的机器学习。
1.2.1生成数据集
简单起见,考虑下面这个回归问题: 给定的成对的“输入-输出”数据集 { ( x 1 , y 1 ) , . . . . , ( x n , y n ) (x_1,y_1),....,(x_n,y_n) (x1,y1),....,(xn,yn)},如何学习 f f f来预测任意新输入x的输出 y 新 = f ( x ) ? y_新=f(x)? y新=f(x)?
根据下面的非线性函数生成一个人工数据集, 其中加入的噪声项为 ϵ \epsilon ϵ:
y i = 2 sin ( x i ) + x i 0.8 + ϵ , y_i = 2\sin(x_i) + x_i^{0.8} + \epsilon, yi=2sin(xi)+xi0.8+ϵ,
其中 ϵ \epsilon ϵ服从均值为0和标准差为0.5的正态分布。 我们生成了50个训练样本和50个测试样本。 为了更好地可视化之后的注意力模式,我们将训练样本进行排序。
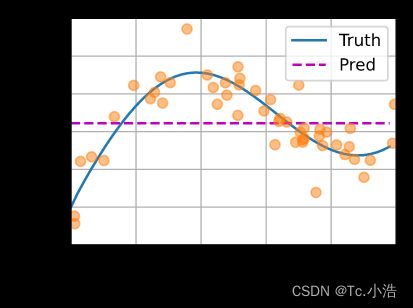
下面的函数将绘制所有的训练样本(样本由圆圈表示), 不带噪声项的真实数据生成函数(标记为“Truth”), 以及学习得到的预测函数(标记为“Pred”)。
使用最简单的估计器来解决回归问题:基于平均汇聚来计算所有训练样本输出值的平均值:
f ( x ) = 1 n ∑ i = 1 n y i , f(x) = \frac{1}{n}\sum_{i=1}^n y_i, f(x)=n1∑i=1nyi,
如下图所示,这个估计器确实不够聪明: 真实函数(“Truth”)和预测函数(“Pred”)相差很大。
import torch
from torch import nn
from d2l import torch as d2l
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
def f(x):
return 2 * torch.sin(x) + x**0.8
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
def plot_kernel_reg(y_hat):
d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],
xlim=[0, 5], ylim=[-1, 5])
d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)
1.2.2非参数注意力汇聚
显然上面的公式平均汇聚忽略了输入 x i x_i xi.提出了一个更好的想法,根据输入的位置对输出 y i y_i yi进行加权:
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i , f(x) = \sum_{i=1}^n \frac{K(x - x_i)}{\sum_{j=1}^n K(x - x_j)} y_i, f(x)=∑i=1n∑j=1nK(x−xj)K(x−xi)yi,
其中K是核(kernel)。 上面公式所描述的估计器被称为 Nadaraya-Watson核回归(Nadaraya-Watson kernel regression)。 这里我们不会深入讨论核函数的细节, 但受此启发, 成为一个更加通用的注意力汇聚(attention pooling)公式:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i , f(x) = \sum_{i=1}^n \alpha(x, x_i) y_i, f(x)=∑i=1nα(x,xi)yi,
其中x是查询,
( x i , y i ) (x_i,y_i) (xi,yi)是键值对。 比较上面两个公式, 注意力汇聚是 y i y_i yi
的加权平均。 将查询x和键 x i x_i xi
之间的关系建模为 注意力权重(attention weight) α ( x , x i ) \alpha(x,x_i) α(x,xi)
, 如上公式所示, 这个权重将被分配给每一个对应值 y i y_i yi
。 对于任何查询,模型在所有键值对注意力权重都是一个有效的概率分布: 它们是非负的,并且总和为1。
为了更好地理解注意力汇聚, 我们考虑一个高斯核(Gaussian kernel),其定义为:
K ( u ) = 1 2 π exp ( − u 2 2 ) . K(u) = \frac{1}{\sqrt{2\pi}} \exp(-\frac{u^2}{2}). K(u)=2π1exp(−2u2).
带入上面公式
