R语言之K-mean聚类分析
K-mean聚类是很基础的算法,在本科阶段大家都会学,如何通过R语言自己写K-mean算法,话不多说,上代码,算法流程和函数解释代码后
K_means <- function(data,k,max.iter = 10){
rows <- nrow(data) #获取行数
cols <- ncol(data) #获取列数
within <- numeric(k) #用于存储组类平方和
lable_matrix <- matrix(0,rows,2) #用于存储类标签及到类中心的距离
centers <- matrix(0,cols,k) #用于存储类中心
centers_matrix <- matrix(0,rows,k) #用于存储初始确定初始类中心时到类中心的距离
iter <- 0 #迭代次数
random <- sample(1:rows,1)
centers[,1] <- as.matrix(data[random,])
for(j in 2:k){
for(i in 1:rows){
centers_matrix[i,j] <- sum((data[i,] - centers[,j-1])^2)+centers_matrix[i,j-1]
}
centers[,j] <- as.matrix(data[which(centers_matrix[,j] == max(centers_matrix[,j])),])
} #计算初始类中心
changed <- TRUE #用于判断数据的类标签是否发生改变
while(changed){
if(iter >= max.iter){
changed <- FALSE
break
}
for(j in 1:rows){
updata <- 1000000000
for( i in 1:k){
updatas <- sum((data[j,]-centers[,i])^2)
if(updatas < updata){
updata <- updatas
lable_matrix[j,1] <- updatas
lable_matrix[j,2] <- i
}
}
} #更新到类中心的距离以及类标签
center <- centers
for(i in 1:k){
centers[,i] <- colMeans(data[lable_matrix[,2]==i,])
} #更新类中心
changed <- !all(center == centers)#判断类中心是否变化
iter <- iter + 1
}
###计算函数返回值:
totss <- sum((t(data[,])-colMeans(data))^2)
withinss <- numeric()
for(i in 1:k){
withinss[i] <- sum((t(data[lable_matrix[,2]==i,])-(centers[,i]))^2)
}
tot.withinss <- sum(withinss)
betweenss<-0
for(i in 1:3){
betweenss <- betweenss + sum(nrow(data[lable_matrix[,2]==i,])*(rowMeans(t(data[lable_matrix[,2]==i,]))-colMeans(data))^2)
}
size <- aggregate(lable_matrix[,2], by=list(lable=lable_matrix[,2]),length)[,2]
centers_matrix <- t(centers)
colnames(centers_matrix) <- colnames(data)
result <- list(cluster = lable_matrix[,2],centers = centers_matrix,totss = totss,withinss = withinss,tot.withinss = tot.withinss
,betweenss = betweenss,size = size,iter = iter)
return(result)
}
df <- kmeans(iris[,1:4],3)
df$cluster
df$centers
df$totss
df$withinss
df$tot.withinss
df$betweenss
df$size
df$iter
K_means(iris[,1:4],3)对设置的函数参数以及输出的结果做一解释:
参数:data:用于聚类的数据;k:用于聚类的数目;max.iter:最大迭代次数
输出结果(均与R语言中自带kmeans函数输出结果命名一致):
cluster:聚类结果,即类标签;
centers:聚类中心;
totss:总平方和;
withinss:各组内的平方和;
tot.withinss:组内平方和;
betweenss:组间平方和;
size:各类的数量;
iter :迭代次数;
我用自己写的函数与R语言自带的kmeans函数结果做了对比,数据集使用iris数据集,结果如下:

 由上面两图的结果对比可知:除去迭代次数不一致外其余均相同;迭代次数不一致是因为选取的初始类中心为随机选取造成的。也不排除我的迭代过程不是最优的迭代方式造成,欢迎大家留言谈论!
由上面两图的结果对比可知:除去迭代次数不一致外其余均相同;迭代次数不一致是因为选取的初始类中心为随机选取造成的。也不排除我的迭代过程不是最优的迭代方式造成,欢迎大家留言谈论!
算法流程:
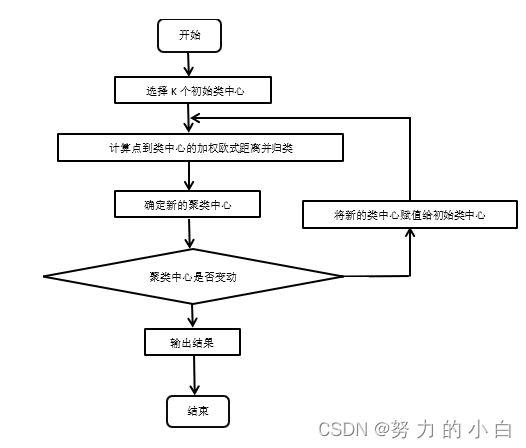
对于K-mean聚类算法的详细流程以及可改进地方和方向,我后期也会发类似的文章。