DABDetr论文解读+核心源码解读
文章目录
- 前言
- 1、论文解读
-
- 1.1.空间注意力热图可视化
- 1.2.模型草稿
- 1.3.详细模型
- 1.4.设置温度系数
- 1.5.实验
- 2、代码讲解
-
- 2.1.Decoder
- 2.2.DecoderLayer
- 总结
前言
本文主要介绍下发表在ICLR2022的DAB-Detr论文的基本思想以及代码的实现。
1、代码地址
2、论文地址
另外,感兴趣可以看下本人写的关于detr其他文章:
1、nn.Transformer使用
2、mmdet解读Detr
3、DeformableDetr
4、ConditionalDetr
1、论文解读
整体模型结构图和Detr很相似:

1.1.空间注意力热图可视化

本文认为原始的Detr系列论文中:可学习的object queries仅仅是给model预测bbox提供了参考点(中心点)信息,却没有提供box的宽和高信息。于是,本文考虑引入可学习的锚框来使model能够适配不同尺寸的物体。上图是可视化的三个模型的空间注意力热图(pk*pq),若读者对热图如何产生的,可参考Detr热图可视化。从图中可以看出,引入可学习锚框后,DAB-Detr能够很好覆盖不同尺寸的物体。本文所得出的一个结论:query中content query和key计算相似度完成特征提取,而pos query则用于限制提取区域的范围及大小。
1.2.模型草稿
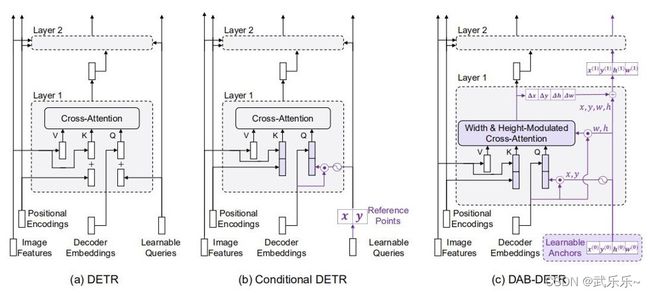
图中紫色是改动的区域,大体流程是:DAB-Detr直接预设了N个可学习的anchor,这点类似于SparseRCNN。然后经过宽高调制交叉注意力模块,预测出每个锚框四个元素偏移量来更新anchor。
1.3.详细模型

上图是我做的一张PPT,展示的是一层DecoderLayer。简单说下流程:首先设定了N个可学习的4维的anchors,然后经过PE和MLP将其映射成Pq。
1) 在self-attn部分:常规的自注意力,使用的是Cq和Pq做加法;
2) 在cross-attn部分:参考点(x,y)部分完全和ConditionalDetr一样,Cq和Pq使用拼接来生成Qq;唯一区别是“宽和高调制交叉注意力模块”:在计算Pk和Pq的权重相似度时引入了一个(1/w,1/h)的一个尺度变换操作。
1.4.设置温度系数
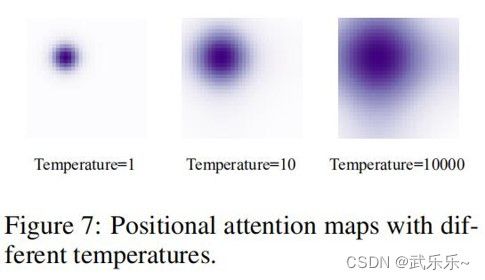
Detr中给特征图每个位置生成位置Pk完全使用的是Transformer中温度系数,而Transformer针对的是单词的嵌入向量设计的,而特征图中像素值大多分布在[0,1]之间,因此,贸然采用10000不合适,所以,本文采用了20。算是个trick吧,能涨一个点左右。
1.5.实验
在四个backbone比较了性能,总体来看,达到最优。

2、代码讲解
感觉这套代码质量非常高,因为作者基本上开源了每个实验的代码,值得反复看(包括deformable attn的算子、分布式训练等等)。
2.1.Decoder
首先看下整体Decoder的forward函数部分:
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
refpoints_unsigmoid: Optional[Tensor] = None, # num_queries, bs, 4
):
# 第一层tgt初始化全0,output即输入的Cq!
output = tgt
# 保存中间结果
intermediate = []
reference_points = refpoints_unsigmoid.sigmoid() # [300,batch,4]
ref_points = [reference_points]
# import ipdb; ipdb.set_trace()
for layer_id, layer in enumerate(self.layers):
# 取出anchor的中心Aq
obj_center = reference_points[..., :self.query_dim] # [num_queries, batch_size, 2]
# 执行Pq = MLP(PE(obj_center)),将中心点转成256维度的嵌入向量
query_sine_embed = gen_sineembed_for_position(obj_center)
query_pos = self.ref_point_head(query_sine_embed)
# For the first decoder layer, we do not apply transformation over p_s
if self.query_scale_type != 'fix_elewise':
if layer_id == 0:
pos_transformation = 1
# Cq经过MLP得到用于中心的变换
else:
pos_transformation = self.query_scale(output)
else:
pos_transformation = self.query_scale.weight[layer_id]
# 得到Pq
query_sine_embed = query_sine_embed[...,:self.d_model] * pos_transformation
# modulated HW attentions
if self.modulate_hw_attn:
# Cq经过MLP和sigmoid得到Wq,ref和Hq,ref
refHW_cond = self.ref_anchor_head(output).sigmoid() # nq, bs, 2
# 应用宽高调制损失
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / obj_center[..., 3]).unsqueeze(-1)
# 执行当前层的decoder layer
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos, query_sine_embed=query_sine_embed,
is_first=(layer_id == 0))
# iter update
if self.bbox_embed is not None:
if self.bbox_embed_diff_each_layer:
# 在Cq基础上预测tmp:即bbox的误差量:[delta_x, delta_y, delta_w, delta_h]
tmp = self.bbox_embed[layer_id](output)
else:
tmp = self.bbox_embed(output)
# 更新bbox
tmp[..., :self.query_dim] += inverse_sigmoid(reference_points)
# 经过sigmoid得到新的bbox
new_reference_points = tmp[..., :self.query_dim].sigmoid()
if layer_id != self.num_layers - 1:
# 存储每层的参考点
ref_points.append(new_reference_points)
# 更新参考点,为下一层decoder layer使用
reference_points = new_reference_points.detach()
# 保存中间的Cq
if self.return_intermediate:
intermediate.append(self.norm(output))
# 循环结束,按要求返回所需的值
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
if self.bbox_embed is not None:
return [
torch.stack(intermediate).transpose(1, 2),
torch.stack(ref_points).transpose(1, 2),
]
else:
return [
torch.stack(intermediate).transpose(1, 2),
reference_points.unsqueeze(0).transpose(1, 2)
]
return output.unsqueeze(0)
2.2.DecoderLayer
内部就是调用了self-attn和cross-attn,pq,pk,cq,ck按照论文中相加或者拼接即可。
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None,
query_sine_embed = None,
is_first = False):
# ========== Begin of Self-Attention =============
if not self.rm_self_attn_decoder:
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.sa_qcontent_proj(tgt) # target is the input of the first decoder layer. zero by default.
q_pos = self.sa_qpos_proj(query_pos)
k_content = self.sa_kcontent_proj(tgt)
k_pos = self.sa_kpos_proj(query_pos)
v = self.sa_v_proj(tgt)
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
# 自注意力: 相加
q = q_content + q_pos
k = k_content + k_pos
tgt2 = self.self_attn(q, k, value=v, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
# ========== End of Self-Attention =============
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# ========== Begin of Cross-Attention =============
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.ca_qcontent_proj(tgt)
k_content = self.ca_kcontent_proj(memory)
v = self.ca_v_proj(memory)
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
k_pos = self.ca_kpos_proj(pos)
# For the first decoder layer, we concatenate the positional embedding predicted from
# the object query (the positional embedding) into the original query (key) in DETR.
if is_first or self.keep_query_pos:
q_pos = self.ca_qpos_proj(query_pos)
q = q_content + q_pos
k = k_content + k_pos
else:
q = q_content
k = k_content
# 拆成多头并将cq和pq进行拼接
q = q.view(num_queries, bs, self.nhead, n_model//self.nhead)
query_sine_embed = self.ca_qpos_sine_proj(query_sine_embed)
query_sine_embed = query_sine_embed.view(num_queries, bs, self.nhead, n_model//self.nhead)
# 拆成多头并将ck和pk进行拼接
q = torch.cat([q, query_sine_embed], dim=3).view(num_queries, bs, n_model * 2)
k = k.view(hw, bs, self.nhead, n_model//self.nhead)
k_pos = k_pos.view(hw, bs, self.nhead, n_model//self.nhead)
k = torch.cat([k, k_pos], dim=3).view(hw, bs, n_model * 2)
# 调用nn.MultiHeadAttn模块
tgt2 = self.cross_attn(query=q,
key=k,
value=v, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
# ========== End of Cross-Attention =============
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
总结
后面会介绍DN-DETR,敬请期待。若有问题欢迎+vx:wulele2541612007,拉你进群探讨交流。