软件工程——Alpha(2/3)
本周在学习深度学习的几个主要方法
卷积
卷积的重点是卷积核,卷积的过程其实就是一个特征提取的过程,加快模型的训练速度
- 代码
from torch.nn.modules.conv import Conv2d
from torch.utils.data import DataLoader
#@title 卷积操作
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('/content/sample_data',train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64)
class NN_test(nn.Module):
def __init__(self):
super(NN_test,self).__init__()
self.conv=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv(x)
return x;
writer=SummaryWriter("logs")
nn_test=NN_test()
step=0
for data in dataloader:
imgs,targets=data;
output=nn_test(imgs)
writer.add_images("input",imgs,step)
output=torch.reshape(output,(-1,3,30,30))
if step==0:
print(imgs.shape)
print(output.shape)
writer.add_images("output",output,step)
step=step+1
%load_ext tensorboard
%tensorboard --logdir logs
writer.close()
结果如下:

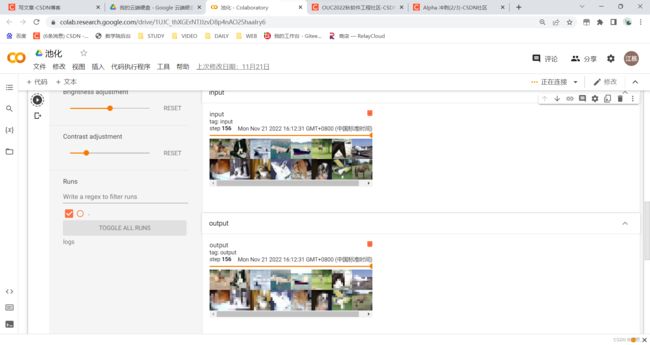
池化
保留范围中的最大值,减少数据量
from torch.utils.data import DataLoader
# @title 最大池化
#池化操作:卷积范围内最大的数值进行保留,减少数据量
import torch
from torch import nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('/content/sample_data',train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64)
class MaxPool(nn.Module):
def __init__(self):
super(MaxPool,self).__init__()
self.maxpool=nn.MaxPool2d(3,ceil_mode=True)
def forward(self,input):
output=self.maxpool(input)
return output
writer=SummaryWriter("logs")
step=0
maxpool=MaxPool()
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
output=maxpool.maxpool(imgs)
writer.add_images("output",output,step)
step=step+1
%load_ext tensorboard
%tensorboard --logdir logs
writer.close()
结果如下:
线性变换
将数据变为对应的形状
代码:
# @title 线性层
from torch.utils.data import DataLoader
import torch
from torch import nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('/content/sample_data',train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64,drop_last=True)
class Liner(nn.Module):
def __init__(self):
super(Liner,self).__init__()
self.Linear=nn.Linear(196608,10)
def forward(self,input):
output=self.Linear(input)
return output
writer=SummaryWriter("logs")
step=0
liner=Liner()
for data in dataloader:
imgs,targets=data
# writer.add_images("input",imgs,step)
output=liner.Linear(torch.flatten(imgs))
print(output)
# writer.add_images("output",output,step)
step=step+1
# %load_ext tensorboard
# %tensorboard --logdir logs
# writer.close()
结果如下:

非线性激活
做非线性变换,提高模型的泛化能力
主要方法:
- ReLU:直接截断小于0的部分
- Sigmoid:根据函数进行变化
代码:
# @title 非线性激活
from torch.utils.data import DataLoader
#做非线性变化,提高模型的泛化能力
import torch
from torch import nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('/content/sample_data',train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64)
#ReLU直接截断小于0的值
class Rel(nn.Module):
def __init__(self):
super(Rel,self).__init__()
self.Rel=nn.ReLU()
def forward(self,input):
output=self.ReLU(input)
return output
#Sigmoid根据公式对数据进行非线性的变换
class Sigmoid(nn.Module):
def __init__(self):
super(Sigmoid,self).__init__()
self.Sigmoid=nn.Sigmoid()
def forward(self,input):
output=self.Sigmoid(input)
return output
input=torch.tensor([[1,1,-1],
[2,-2,2],
[-3,3,3]])
#测试ReLU部分
rel=Rel()
output=rel.Rel(input)
print(output)
#测试Sigmoid部分
writer=SummaryWriter("logs")
step=0
sigmoid=Sigmoid()
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
output=sigmoid.Sigmoid(imgs)
writer.add_images("output",output,step)
step=step+1
%load_ext tensorboard
%tensorboard --logdir logs
writer.close()
结果

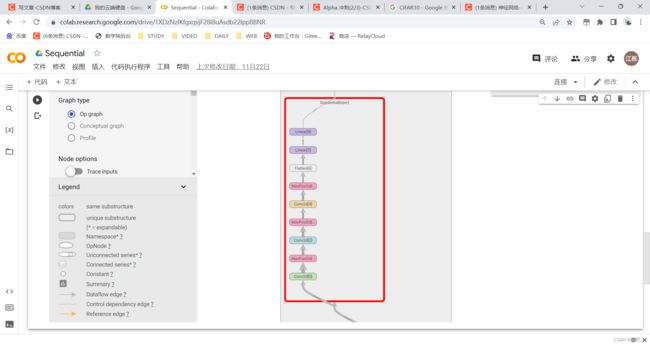
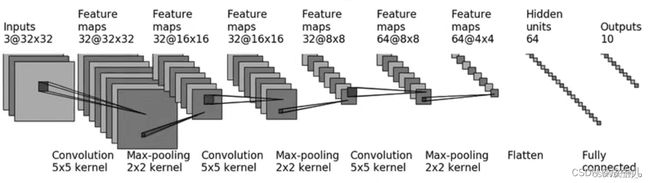
最后根据CIFAR10数据集进行训练
代码:
#@title 根据CIFAR10数据集进行小实战
import torch
from torch import nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10('/content/sample_data',train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64,drop_last=True)
class CIFAR10(nn.Module):
def __init__(self):
super(CIFAR10,self).__init__()
self.oper=nn.Sequential(
nn.Conv2d(3,32,5,padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,input):
output=self.oper(input)
return output
c=CIFAR10()
writer=SummaryWriter("logs")
test=torch.ones((64,3,32,32))
output=c.oper(test)
print(output.shape)
writer.add_graph(c,test)
# step=0
# for data in dataloader:
# imgs,targets=data
# writer.add_images("input",imgs,step)
# output=c.oper(imgs)
# print(output)
# # writer.add_images("output",output,step)
# step=step+1
%load_ext tensorboard
%tensorboard --logdir logs
writer.close()
结果可以查看具体的训练过程