FastReID阅读笔记
×
参考链接
博主的中文文档
MSTM17 Google Drive下载链接
[MSTM17 百度云下载链接]
DUKE完事了 MSTM还没完事。

摘要
General Instance Re-identification,涵盖such as person/vehicle re-identification,face recognition. 他们这个工具箱高度模块化和可拓展的设计方便我们验证new research ideas. 还支持单个GPU和多个GPU的服务器.
1. Introduction

注意到他们提到:
which is easily extended to a range of tasks, such as general image retrieve and
face recognition.

person re-idcross-domain person re-idpartial person re-idvehicle re-idface recognitionobject retrieval
将来会释放人脸识别和目标检索的模型. 没必要再读了.
2. Highlight of FastReID
首先,他们这个是个strong baseline(that are capable of achieving state-of-the-art performance), 还提供了完整的工具箱for

trainingevaluationfinetuningfinetune 还不咋会.model deployment 这个是啥
2.1 Modular and extensible design

引入模块化设计,使用户可以将定制设计的模块插入REID系统的几乎任何部分。只需要更改某个模块, 就比如我要实现某一位置的Idea, 我只需要替换掉那部分. 没必要再读了.
2.2 Manageable system configuration
- 可以在
Multi-GPU servers上快速训练. - 模型的定义,训练和测试都是写成
YAML文件.模型的定义写成YAML很特别.

可以选择的一些组件
backbone网络吧?head aggregation layer这是啥? 在后面Head和Aggregation是分着的, 不是一个玩意. 先弄清楚headloss functiontraining strategy
没必要再读了.
cuhk03的结果不好,原因可能是多方面的. 可能之前的这些设置都是针对于market1501的. 而针对cuhk03需要做出相应更改呢.
根据目前我Googlesheet里面的获得的cuhk03的结果,我发现, 他们这个比SAN还好.但是尚且不确定Split方式和测试协议.
2.3 Richer evaluation system
别人提供的都是单一的CMC evaluation index.

为了更加地在实际中能用, 他们还给出ROC, mINP. 这些能更好地反映出模型的表现. 没必要再读了.
2.4 Engineering deployment
太深的模型在狭小硬件或者AI芯片很难部署,因为consuming inference和unrealizable layers.

FastReID实现了知识蒸馏模块来获得lightweight model. 这块我暂时不涉及.没必要再读了.
2.5 State-of-the-art pre-trained models

可以公开release一些pretrained inference model, 然后就很容易把FastReID扩展到人脸识别. 没必要再读了.
3. Architecture of FastReID
也就是FastReID的详细流程, pipeline. 整个流程包括四部分:
image-Preprocessingbackboneaggregation聚合 aggregationthe formation of a number of things into a cluster. 聚合是啥? 头又是啥?head
3.1 Image-Preprocessing.

上来先resize到相同的尺寸. 按batch输入到网络.
flippingas data augmentation bymirroringthe source images to make data more diverse. 罗浩也有这个步骤.Random erasing是啥? 应该就是REA. 罗浩也有这个步骤Random patch是啥? 不太确定是不是罗浩那个 B = P ∗ K B=P*K B=P∗K 应该不是吧, 不然不至于引个新文献啊? 这里指的random patch应该是特殊的patch方法.Cutout是啥? 将图像部分像素值置零zero values.
-Auto-augment是啥? is based onautomltechnique. 也是数据增强的方式,可以让特征表达更鲁棒. 这个罗浩没用.


不像之前我人脸的数据增强方法是自己指定, 而这里是自动搜索fusion policy来结合translation, rotation, shearing.
这些预处理方式是在程序里实现了? 还是给的数据集就这么处理好了? 应该是程序后期再处理.
3.2 Backbone

得ResNet去掉the last average pooling layer.
- ResNet
ResNeXtResNeSt
还涉及的模块
attention-like non-localmodule 这个模块怎么加的, 缩写是啥? 类-视觉注意的非局部模块 而不是真正的attentioninstance batch normalization (IBN)
加上述2个模块也是为了more robust feature.

感觉这块这个with_NL就是指的non-local那个module. 对的, 因为下面这句话.
We also add
attention-like non-local moduleandinstance batch normalization (IBN)module into backbones to learn more robust feature.
- 那这块这个
WITH_SE是啥呢? 反正不管BOT还是SBS, 这个SE都没用到.
3.3 Aggregation(聚合) 就是怎么把feature map变成global feature.

聚合feature maps成为a global feature.
四种聚合方法如下:
max pooling和以前的一样么average pooling和以前的一样么GeM pooling这是啥?attention pooling这是啥?


感觉像是将那种3364拉成
四种pooling的公式如下:

W c W_c Wc是softmax attention weights. 在config文件里有没有这个 α ? \alpha? α?

没必要再读了.
3.4 Head

Head是处理由聚合模块生成的全局向量的部分
感觉像是在aggregation后怎么处理得到的the global vector generated by aggregation的一种方式.
说白了,就是怎么处理得到的一维特征向量
分为如下三种:
linear headdecision layer.batch normalization headdecision layer + bn.Reduction headdecision layer + bn+ reduction layer + (conv+bn+relu+dropout)
decision layer这个和普通CNN的什么对应呢? Decision layer outputs the probability of different catergories 感觉这像是和取完Softmax的那个prediction对应? 而不是那个correct_prediction?
三种head的具体方式:

看看程序里到底用的哪个HEAD:
应该就是Batch normalization head但是这个和BNNeck是完全一样的东西么? 尚且不确定.
4. Training
4.1 Loss Function
说是在FastReID里实现了不同的loss functions.
Cross-entropy说这个容易导致过拟合, 因为too confident about its predictions. 所以会用到Label Smoothingarcface loss会把笛卡尔坐标映射到球面坐标. 在于添加Additive angular margin penalty m in the intra-class measure. 这个在程序里用什么缩写代表的???circle loss更多细节查找原文.triplet loss到底是facenet最早还是专门用于REID的triplet?
4.2 Training Strategy
4.2.1 Learning rate warm-up
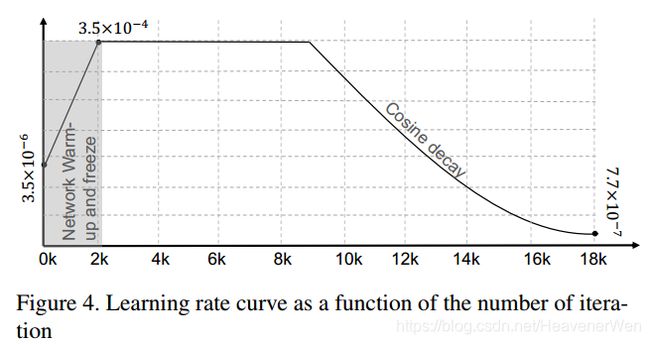
这里涉及到底看看一个epoch跑多少Iteration?
4.2.2 Backbone freeze

起先的有的是ImageNet pre-trained model, 用于我们的任务时候, 用the collected data from the tasks to fine-tune on the ImageNet model.

应该是: 在原有网络基础上, add a classifier, 然后这个classifier的参数是randomly initialized的.
为了能更好地初始化the parameters of the classifier, 在刚开始训练的前2k iteration, 我们freezing the network parameters and only train the classifier parameters.
在2k iteration以后, 把所有的网络参数都free掉, 然后直到end-to-end training.
感觉应该是2k次训练就会让classifier大致训好,然后网络前半部分和classifier整体训好, 从而达到某种和谐. 尚且不确定,需要找人问问.
5. Testing
5.1 Distance Metric
在fastreid里面一共实现了:
EucildeanCosinea local matching method: Deep spatial reconstruction(DSR)
然后就是介绍什么是Deep spatial reconstruction?

假设有一对图像, 然后就是依靠在CNN得到的特征图,然后定义了一些数学, 暂时先不探究.
5.2 Post-processing
Two re-rank methods:
K-reciprocal coding罗浩不涉及这个吧?Query Expansion(QE)罗浩不涉及这个吧?
5.2.1 Query Expansion

有个公式, 此外就是会把之前的用来query的特征处理一下, 怎么处理? 把现在这个和验证的gallery那些features平均.
the new query feature is constructed by averaging the verified gallery features and the query features.
然后用the new query feature来进行下面的image retrieve.
5.3 Evaluation
有大家都用的(CMC)和(mAP). 他们还多了ROC和mINP.
5.4 Visualization

A rank list tool of retrieval result.
一个小工具
6 Deployment

实现了知识蒸馏module, 然后实现了high-precision,high-efficiency,lightweight model.
这个有关于teacher model和student model的具体描述. 然后, 细节我没仔细看, 有空再来看.
7. Projects
注意到项目中关于sbs101-ibn有两个yaml, 内容并不是完全相同.
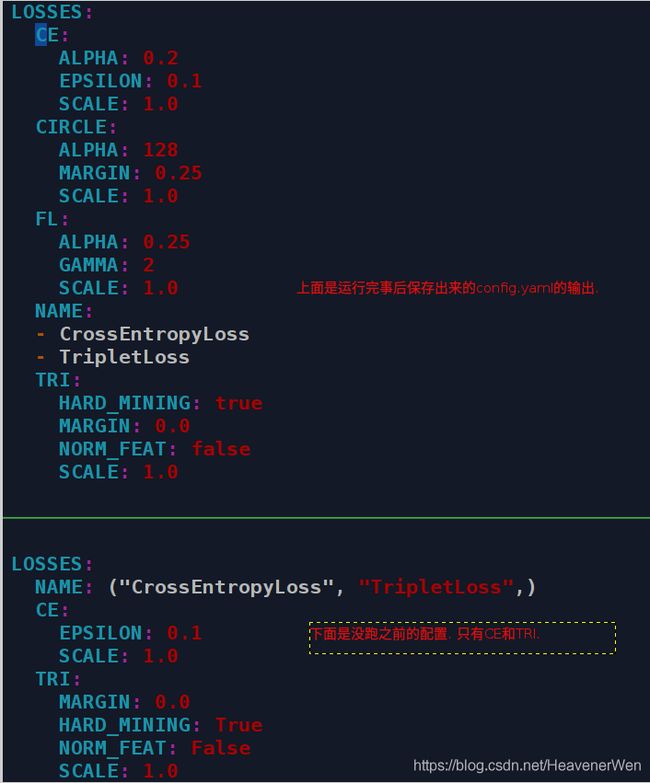
如果从上面看的话,还会多出:
CircleFL我猜测这是ArcFace那个loss.
那么就是得弄清楚到底用了哪些loss来监控? 到底是按照跑之前的yaml还是按照跑之后的yaml? 此外, 当margin=0时候, 还得知道:到底代不代表就没用triplet?
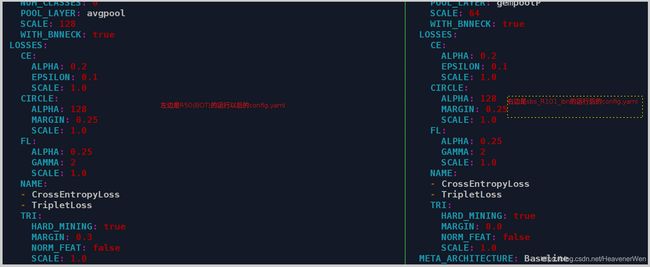
看这个的话, 好像BOT里面也会用到
Circle和FL. 但是sbs应该没有triplet因为margin为0.
截止2020.11.30完全不知道到底用了哪些loss?
7.1 Person Re-identification
7.1.1 Dataset

Market1501DukeMTMCMSMT17
关于数据集的描述,他们没说.
没在cuhk03上面测试。Luo Hao Stronge Baseline也没在cuhk03上面测试。
7.1.2 FastReID Setting

涉及的预处理:
flipping在前面预处理提到过了.random erasing在前面预处理提到过了.auto-augment在前面预处理提到过了.
Backbone
IBN-ResNet101 with a non-local module

会有IBN, 也会有Non-local.
Loss function
从论文是: circle loss and triplet loss
从yaml是: 尚且不确定.
HEAD
bnneck(和batch normalization head是不是一个?)
Aggregation layer
The gem pooling
7.1.3 Result
他们这个IBN-Resnet101-Non-local在上面三个数据集都得第一.

他说他们的算法在Market1501, DukeMTMC, MSMT17上都得到最佳精度。
7.2 Cross-domain Person Re-identification
Problem definition

跨域人员重新识别的目的是使在标记的源域数据集上训练的模型适应于没有任何注释的另一个目标域数据集.
是真的压根第二个数据集本上就没有标注,还是说有,但是因为没用到第二个的标注
Setting

我们提出了一种跨域方法FastReID-MLT,该方法采用混合标签传输来通过多粒度策略学习伪标签。

先用source domain数据集训练一个模型,然后用target-domain的伪标签finetune那个之前的预训练模型。
Result
7.3 Partial Person Re-identification
7.4 Vehicle Re-identification
8. Conclusion

这个是个general instance re-identification的库, 他们希望发布这个FastReID可以accelerate progress in the area of general instance re-identification.
===================================================
实验部分
![]()
程序部分
IBN101和普通50
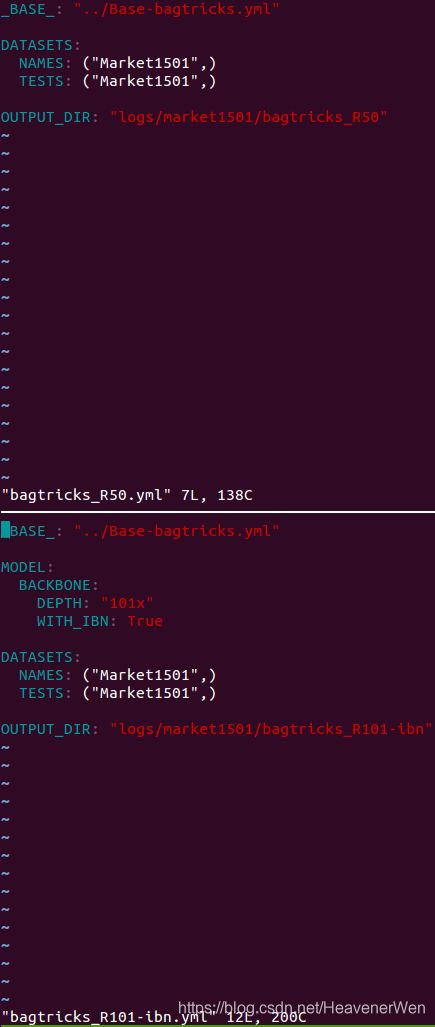
所以得确定论文得到的结果是基于哪个yaml文件,分为sbs,agw还有bagtricks. 在Table 3里,BOT代表the bag of tricks方法, which is a strong baseline in the ReID task(BOT代表文献44也就是罗浩的方法). 我以为sbs才代表Strong Baseline. 这个疑惑在下面带蓝色字体的图里可以解除。sbs是比BOT更强的stronger baseline.
怎么去找到对应?

在name列点击一下,就到具体的yaml configure文件了。

可以看到sbs还分为:
BoFBoS
以BoT为例子说明yaml文件怎么工作?
BoT(R50)BoT(R50-ibn)BoT(S50)BoT(R101-ibn)
BoT(R50):
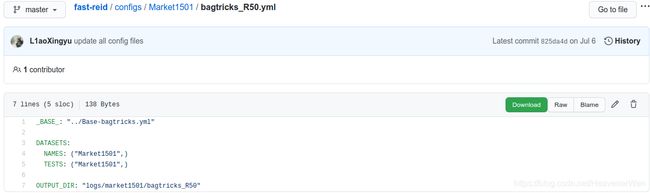
BoT(R50-ibn)
可以看出, 不明确指定的话就默认的ResNet50.
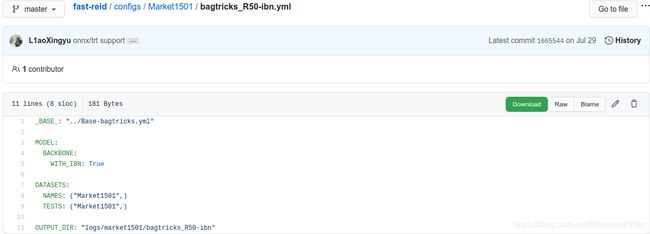
BoT(R101-ibn)

可以看出来, 这边不是默认了, 会指定DEPTH. 将网络由ResNet50变成ResNet101.
BoT(S50)

这里干脆将网络都换了, 通过NAME来将网络不再用ResNet. 而是用ResneSt.
表一

通过上图, 只能确定用的网络的类型,却不知道到底用了哪个yml文件的tricks.