论文阅读:Scale-aware Automatic Augmentation for Object Detection (CVPR 2021)

paper: https://arxiv.org/abs/2103.17220
code: https://github.com/dvlab-research/SA-AutoAug GitHub - dvlab-research/SA-AutoAug
目录
1 Motivation
1.1 图像级增强 Image-level augmentations
1.2 盒级增强 Box-level augmentations
2 Methods
2.1 搜索空间
2.2 评价指标
2.3 搜索算法
2.4 整体框架
3 实验
数据增强包括两个发展方向,一类是数据增强方法,另外一类是数据增强的组合策略。本文延续了AutoAugment的思路,提出一种适合目标检测的数据增强策略搜索方法。
自动增强方法[9,51,22,27,26]通常将寻找最佳增强策略的过程描述为一个搜索问题。数据增强的组合策略问题一般包括三个部分:(1)搜索空间;(2)搜索算法;(3)评价指标。搜索空间可能因任务而异,例如:对AutoAugment,数据增强策略包含五个子策略(sub-policy),每个子策略包括两个操作(operations),每个操作对应一种数据增强方法的强度和执行概率;对于搜索算法,通常使用强化学习[52]和进化算法[38]在迭代中探索搜索空间;评价指标是模型在代理任务(训练集子集)上训练测试,用作搜索算法的反馈。
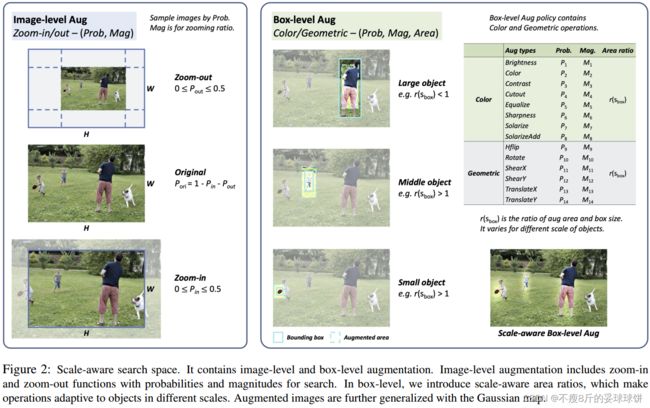
设计的缩放感知搜索空间包含图像级和框级增强。图像级增强功能包括对整个图像的放大和缩小功能。对于框级增强,在图像中搜索对象的颜色和几何操作。
1 Motivation
1.1 图像级增强 Image-level augmentations
为了处理尺度变化,对象检测器通常使用图像金字塔进行训练。但是,这些比例设置高度依赖手工选择。在我们的搜索空间中,我们通过可搜索的放大和缩小功能来减轻这种负担。如图2左侧所示,放大和缩小功能由概率P和幅度M指定。具体而言,概率Pin和Pout在0到0.5的范围内搜索。在这个范围内,可以用概率来保证原始尺度的存在。
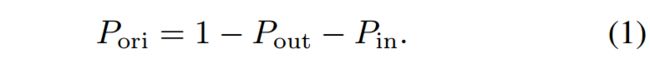
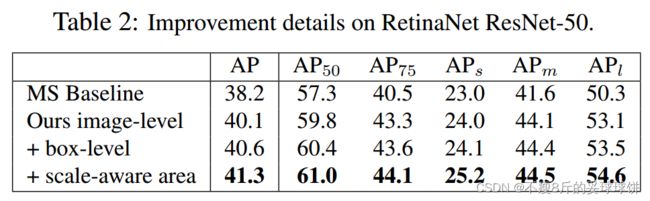
据我们所知,以前没有任何工作考虑自动尺度感知变换搜索用于目标检测。实验验证了该方法在Tab2中优于传统的多尺度训练。
1.2 盒级增强 Box-level augmentations
[ECCV-20] Learning data augmentation strategies for object detection存在两个问题
- previous box-level augmentation [51] works exactly bring two issues, which generate an obvi- ous boundary gap between the augmented and original region, and which brings the gap between training and inference.
(1)box-level augmentation直接在bbox中执行,和背景差异大,降低了网络定位增强目标的难度。解决方法: 本文提出基于高斯,按比例渐近地融合原图片和增强操作,使得box-level增强更加自然丝滑。
增强区域A的公式如下,其中α表示Gaussian map,I和T分别表示Input以及Transform。作者认为这种disigned gaussian-based方法可以soften边界的gap。


- The second issue in previous operations is the lack of considering receptive fields and object scales.
(2)toy experiment显示:不同大小的目标受背景影响程度不同。如表1所示,如果将COCO 验证集中的context信息(也就是background)删除,那么APs会降低,但是APl会增大。

受此启发,仅仅对boxes内或外增强并不能解决所有尺度的物体,作者认为针对不同大小的目标,应该有不同的背景尺度,例如:对于小目标,就应该囊括更多的背景,因为他们的检测受背景影响大。因此作者引出了area ratio这个参数,使得增强区域自适应物体的大小。
具体来说,对于某个图片H * W和检测框(xc, yc, h, w),高斯映射(Gaussian map)进一步表示为:

augmentation area V(增强区域V)用公式4表示:

对box-level增强方法的区域比例定义为r,是可搜索的:![]() 。因此,标准差可以通过下式算得:
。因此,标准差可以通过下式算得:
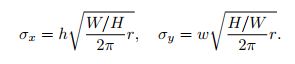
2 Methods
2.1 搜索空间
image-level Aug → (Color box-level Aug → Geometric box-level Aug)^5 → scale ratios
我们的搜索空间包含image-level图像级和box-level框级增强。对于image-level图像级增强,我们搜索zoom-in/out缩放操作的参数。为了与惯例保持一致[51],我们的box-level盒级操作有5个子策略,其中子策略包括颜色Color操作和几何Geometric Aug操作,每种增强方法包括6个离散的执行概率和6个执行强度。概率从一组6个离散值中采样,从0到1.0,以0.2为间隔。强度表示具有自定义范围值的每个操作的强度因子。我们将震级范围映射到一组标准化的6个离散值,从0到10,间隔为2。对于box-level级别的操作,area ratios包括small, middle和Large三种,每个面积比在一组10个离散值中独立搜索。我们在补充材料中列出了这些操作的细节。总之,总的搜索空间提供了![]() 的候选策略,是[51]的两倍。
的候选策略,是[51]的两倍。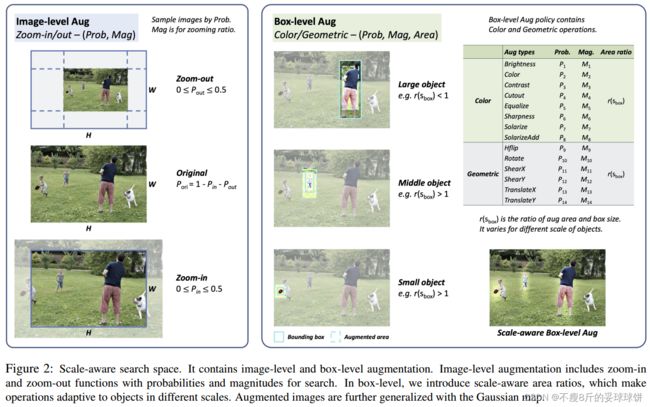
2.2 评价指标
首先训练一个模型,记录它在验证集上的准确率,和每个尺度目标的准确率;然后将该模型在子策略上进一步fine-tune,记录子模型各个尺度目标的损失和准确率。目标函数如下:
![]()
包括两个部分:(1)损失的标准差:各个尺度目标对应的损失要求方差尽可能小;(2)Pareto Optimality惩罚fine-tune后效果变差的项。
![]()
![]()
2.3 搜索算法
进化算法,例如:tournament selection algorithm。验证集包含5k张图片,从MS COCO的train2017中随机采样;剩下的部分用于子模型训练;每个子模型fine-tune 1k iterations。进化搜索中,进化过程迭代10次,初始种群大小设为50,选择最好的10个作为下一代的父母。
2.4 整体框架

3 实验
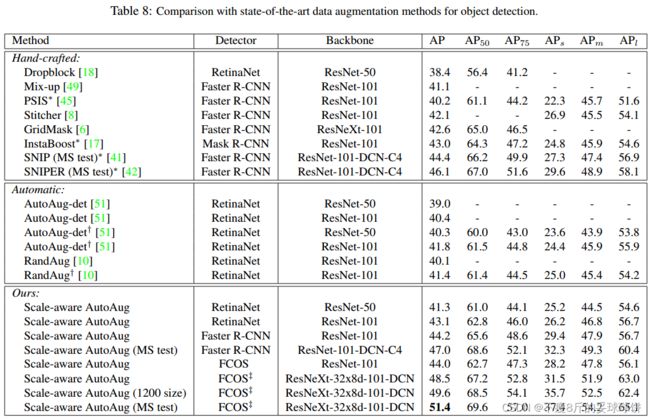
和Baseline和Multi-scale training baseline作比较,其中MS Baseline,通过随机选择640-800中的一个尺度去训练。


参考链接:https://blog.csdn.net/qq_40731332/article/details/118969759
https://blog.csdn.net/weixin_43823854/article/details/118752974