模型部署:pytorch转onnx踩坑实录(上)
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
![]()
计算机视觉研究院专栏
![]()
2
0
在深度学习模型部署时,从pytorch转换onnx的过程中,踩了一些坑。本文总结了这些踩坑记录,希望可以帮助其他人。
2
2




https://github.com/hpc203/license-plate-detect-recoginition-pytorch

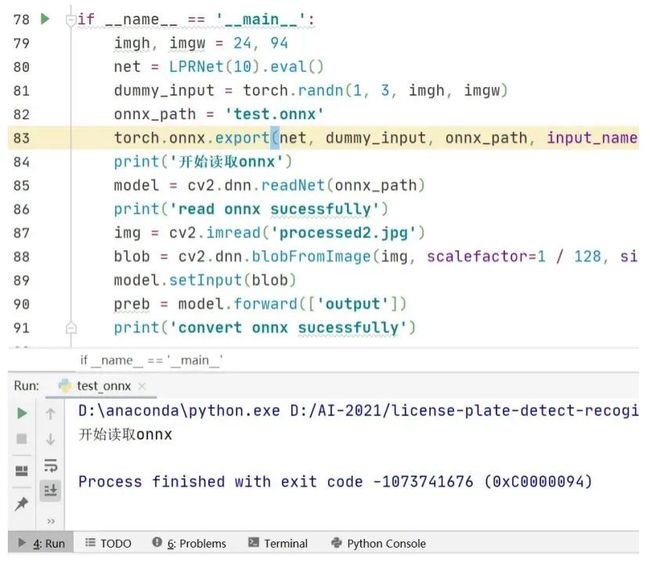


于是,我做了一个实验,定义一个只含有3维池化层的网络,转换生成onnx文件,然后opencv读取onnx文件做前向推理,程序运行结果如下。

可以看到在这时能成功读取onnx文件,但是在执行前向计算model.forward时出错,换成3维平均池化,运行结果如下:

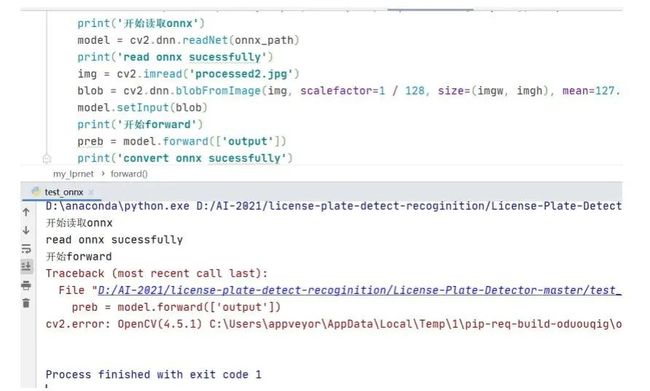
可以看到依然出错,这说明opencv的深度学习模块里不支持3维池化。不过,对比3维池化和2维池化的前向计算原理可以发现,3维池化其实等价于2个2维池化。程序实例如下:


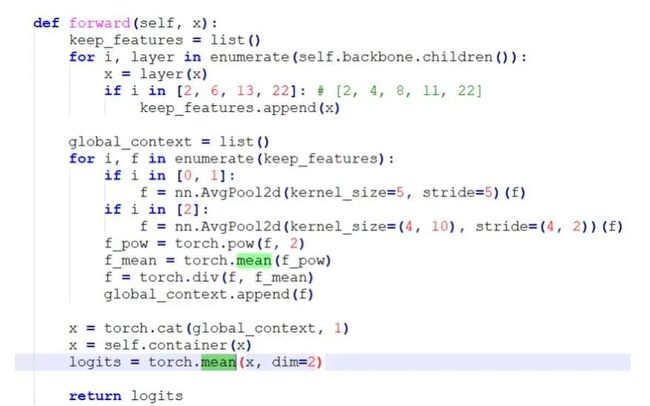
于是继续观察LPRNet的网络结构,在forward函数里看到有求平均值的操作,代码截图如下所示:

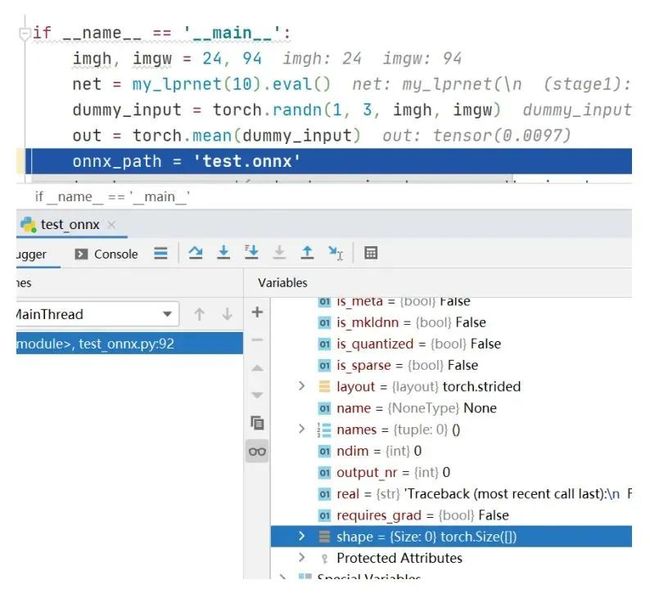
在修改这个代码bug后重新生成onnx文件,使用opencv读取onnx文件做前向计算就不再出现异常错误了。通过以上几个程序实验,可以总结出opencv读取onnx文件做深度学习前向计算的2个坑:
opencv里的深度学习模块不支持3维池化计算,解决办法是修改原始网络结构,把3维池化转换成两个2维池化,重新生成onnx文件
当神经网络里有torch.mean和torch.sum这种把4维张量收缩到一个数值的运算时,opencv执行forward会出错,这时的解决办法是修改原始网络结构,在torch.mean的后面加上.item()
此外,在torch.mean的后面加与不加.item(),在生成onnx文件后,Netron查看网络结构,会产生不一样的网络结构图,详情可以查看我的github仓库里一个网友发的帖子:
https://github.com/hpc203/license-plate-detect-recoginition-opencv/issues/1
在解决这些坑之后,编写了一套使用opencv做车牌检测与识别的程序,包含C++和python两个版本的代码。使用opencv的dnn模块做前向计算,后处理模块是自己使用C++和Python独立编写的。
代码已发布在github上,地址是:
https://github.com/hpc203/license-plate-detect-recoginition-opencv
三、opencv与onnxruntime的差异
起初在github上看到一个使用DBNet检测条形码的程序,不过它是基于pytorch框架做的。于是我编写一套程序把pytorch模型转换到onnx文件,使用opencv读取onnx文件做前向计算。编写完程序后在运行时没有出错,但是最后输出的结果跟调用pytorch 的输出结果不一致,并且从可视化结果看,没有检测出图片中的条形码。这时在看到网上有很多使用onnxruntime部署onnx模型的文章,于是决定使用onnxruntime部署,编写完程序后运行,选取几张快递单图片测试,结果如下图所示DBNet检测到的4个点,图中绿色的点,红色的线是把4个连接起来的直线。


并且我还编写了一个函数比较opencv和onnxruntime的输出结果,程序代码和运行结果如下,可以看到在相同输入,读取同一个onnx文件的前提下,opencv和onnxruntime的输出结果竟然不相同。

ONNXRuntime是微软推出的一款推理框架,用户可以非常便利的用其运行一个onnx模型。从这个实验,可以看出相比于opencv库,onnxruntime库对onnx模型支持的更好。
我把这套使用DBNet检测条形码的程序发布在github上,地址是:
https://github.com/hpc203/dbnet-barcode
后来,我尝试把github上一个很热门的背景抠图程序用opencv部署,但是在opencv读取onnx文件时出错了,但是onnxruntime就能正常读取,代码如下:
import onnxruntime
import numpy as np
import cv2
if __name__=='__main__':
onnxpath = 'weights/onnx_mobilenetv2_4k.onnx'
sess = onnxruntime.InferenceSession(onnxpath)
src = np.random.normal(size=(1, 3, 1080, 1920)).astype(np.float32)
bgr = np.random.normal(size=(1, 3, 1080, 1920)).astype(np.float32)
pha, fgr = sess.run(['pha', 'fgr'], {'src': src, 'bgr': bgr})
net = cv2.dnn.readNet(onnxpath)
blob = cv2.dnn.blobFromImages([src, bgr])
net.setInput(blob)
outs = net.forward(net.getUnconnectedOutLayersNames())
print(outs)运行到 net = cv2.dnn.readNet(onnxpath) 这一行时出错了,报错信息如下:

很明显是opencv不能创建TopK这个层,在github仓库里搜索TopK,看到在model/refiner.py里有这么一段代码。它是直接调用pytorch的接口函数topk的,但是这个在opencv的dnn模块里并不支持,可是onnxruntime库读取onnx文件却是正常的,这又说明了onnxruntime库对onnx模型支持的更好。
后来,我在github上发布了一套使用ONNXRuntime部署鲁棒性视频抠图的程序,依然是包含C++和Python两种版本的程序。起初,我想使用opencv的dnn模块作为推理引擎,但是程序运行到cv2.dnn.readNet(modelpath) 这里时报错,因此使用onnxruntime 作为推理引擎,源码地址是:
https://github.com/hpc203/robustvideomatting-onnxruntime
转自于CSDN:nihate


未完待续

© The Ending
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
纯干货:Box Size置信度偏差会损害目标检测器(附源代码)
优于FCOS:在One-Stage和Anchor-Free目标检测中以最小的成本实现最小的错位(代码待开源)
利用TRansformer进行端到端的目标检测及跟踪(附源代码)
改进的YOLOv5:AF-FPN替换金字塔模块提升目标检测精度
用于吸烟行为检测的可解释特征学习框架(附论文下载)
图像自适应YOLO:恶劣天气下的目标检测(附源代码)
新冠状病毒自动口罩检测:方法的比较分析(附源代码)
NÜWA:女娲算法,多模态预训练模型,大杀四方!(附源代码下载)
实用教程详解:模型部署,用DNN模块部署YOLOv5目标检测(附源代码)
LCCL网络:相互指导博弈来提升目标检测精度(附源代码)
Poly-YOLO:更快,更精确的检测(主要解决Yolov3两大问题,附源代码)