基于深度学习的单目2D/3D姿态估计综述(2021)
Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective, 2021
- 本文贡献
- 整体介绍
-
- MHPE应用场景
- MHPE分类
- 主要数据集
- 期刊会议
- 发展
-
- 2020年
- 针对MHPE的深度学习框架的概述
-
- 难点
- 现有解决方案
- 人体表示
-
- 基于关键点的表示
- 基于模型的表示
- 3D到2D投影
- 单目2D姿态估计(待补充)
- 单目3D姿态估计
-
- 分类
- 难点
- 特附2020-2021年3D姿态估计方法(与原文无关)
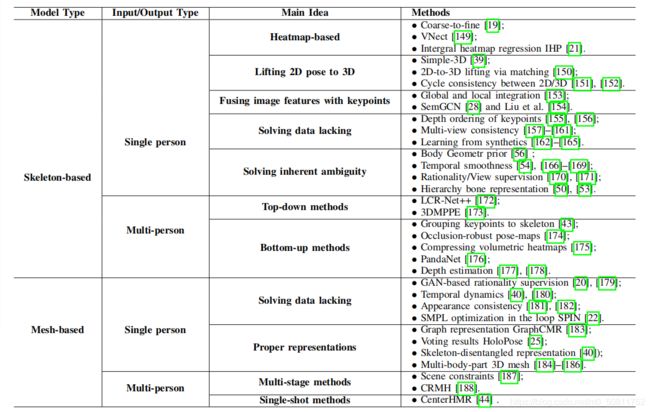
- 基于骨架的三维姿态估计
-
- 基于热图的方法
- 提升2D姿态到3D姿态
- 将图像特征与2D关键点进行集成
- 解决数据缺乏的问题
- 解决内在的模糊性问题
- 多人3D姿态估计
- 基于网格的3D姿态估计
- 评估指标
-
- 2D姿态估计的评价指标
-
- 正确部分的百分比(PCP)
- 正确关键点的百分比(PCK)
- 平均精度(AP)
- 3D姿态估计的评价指标
-
- 每个关节位置的平均误差(MPJPE)
- 按比例对齐的MPJPE(PA-MPJPE)
- 3D PCK & AUC
- 平均每关节角误差(MPJAE)
- 按比例对齐的MPJAE(PA-MPJAE)
- 数据集
-
- 图像级2D单人数据集(待补充)
-
- Leeds Sports Pose (LSP) Dataset
- Frames Labeled in Cinema (FLIC) Dataset
- MPII Dataset
- 图像级2D多人数据集
-
- Microsoft Common Objects in COntext (MSCOCO) Dataset
- AI-Challenger Dataset
- CrowdPose Dataset
- 视频级2D单人数据集
-
- J-HMDB Dataset
- Penn Action Dataset
- 视频级2D多人数据集
-
- PoseTrack Dataset
- Human-in-Events (HiEve) Dataset
- 3D单人数据集
-
- Human3.6M
- HumanEva-I
- MPI-INF-3DHP
- MoVi
- SURREAL Dataset
- AMASS
- 3D多人数据集
-
- 3DPW
- CMU Panoptic Dataset
- Joint Track Auto (JTA) Dataset
- 基准测试的分析 (Analysis of Benchmark)
- 姿态空间分析 (Pose Space Analysis)
- 研究结论及未来的发展方向
-
- 对复杂的姿势和弯曲的场景的姿势估计
- 用于三维网格恢复的基准测试、协议和工具包
- 现实的身体有表情的脸,手,头发和衣服
- 多人3D姿态估计
- 与3D世界和其他代理的交互
- 具有情感、语音和交流的虚拟数字人类生成
本文对2014年以来的2D和3D人体姿态估计方法进行全面调研,精选出里程碑的方法,系统地总结了各种方法的差异和联系,并介绍了数据集和评价指标。28页综述,共计232篇参考文献。
作者单位: 京东AI (梅涛等人)
- 摘要:单目相机的人体姿态估计一直是计算机视觉领域的一个新兴研究课题,有许多应用。近年来,由于深度学习技术,大量的研究努力大大地提高了2D和3D领域的单目人类姿态估计。虽然有一些工作可以总结不同的方法,但研究人员要深入了解这些方法是如何工作的仍然具有挑战性。在本文中,我们提供了一个全面的和整体的2D到3D的视角来解决这个问题。我们将自2014年以来的主流和里程碑方法分类在统一的框架下。通过系统地总结这些方法之间的差异和联系,我们进一步分析了具有挑战性的案例的解决方案,如缺乏数据、2D和3D之间固有的模糊性,以及复杂的多人场景。我们还总结了姿态表示风格、基准、评估度量和流行方法的定量性能。最后,我们讨论了这些挑战,并对未来的研究前景和发展方向进行了深刻的思考。我们相信,这项调查将为读者提供对单眼人类姿态估计的深刻和深刻的理解。
本文贡献
在本文中,主要对近年来基于深度学习的MHPE方法进行了全面的回顾。作者认为,大多数有代表性的MHPE方法都具有内在的相似性和联系。此外,随着三维姿态和形状估计的快速发展,有必要对从二维到三维的人体姿态估计进行更深入的调查。因此,与论文 “Monocular human pose estimation: A survey of deep learning-based methods” 相比,我们的调查有以下差异和优势。
Y.-C. Chen, Y.-L. Tian, and M.-Y. He, “Monocular human pose estimation: A survey of deep learning-based methods,” Computer Vision and Image Understanding, vol. 192, p. 102897, 2020.
- 1) 在统一框架下总结了二维和三维姿态估计的主流网络。它们代表了具有代表性的范式。
- 2) 为人类三维表示、三维数据集、三维形状恢复方法以及三维姿态估计的挑战和进一步工作提供了深入的分析。
- 3) 此外,作者还发布了一个用于三维姿态数据处理的详细代码工具箱 toolbox,这对三维姿态研究将及时而有用。
toolbox 地址:https://github.com/Arthur151/SOTA-on-monocular-3D-pose-and-shape-estimation
整体介绍
MHPE应用场景
Monocular human pose estimation (MHPE), 单目人体姿态估计的目的是从单目图像或视频中预测人体的姿势信息,如身体关节的空间位置和/或体型参数。MHPE被广泛应用于许多计算机视觉任务,如人重新识别、人类解析、人类动作识别、人机交互等。由于MHPE不需要复杂的多摄像机或可穿戴标记点,它已经成为许多现实应用程序的重要组成部分,如虚拟现实、3D电影制作/编辑、自动驾驶、运动和活动分析以及人机交互。
MHPE分类
根据输出结果的空间维度,主流的MHPE任务可以分为2D姿态估计和3D姿态估计两类。
- 单目2D人体姿态估计,也被称为2D关键点检测,旨在从图像中定位人体解剖关键点(身体关节)的2D坐标。考虑到给定图像中的人数,2D人体姿态估计任务可以进一步分为单人姿态估计和多人姿态估计。此外,给定一个视频序列,2D姿态估计可以利用时间信息来提高视频系统中的关键点预测。
- 与仅预测身体关节的2D位置不同,3D姿态估计进一步预测了深度信息,以获得更准确的空间表示。在此过程中,3D姿态估计可以作为3D姿态估计的中间表示。近年来,对理解人类详细姿态信息的要求,使得3D姿态估计不仅能够预测3D位置,还能够预测详细的3D形状和身体纹理。
主要数据集
受数据和计算资源的限制,早期的研究主要集中在手工制作的特征的设计或用优化算法拟合可变形的人体模型上。最近,随着大规模的二维/三维姿态数据集的增加,深度学习技术显著提高了人体姿态估计的性能。
- COCO
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C.-L. Zitnick, “Microsoft coco: Common objects in context,” in ECCV, 2014.
- MPII
M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in CVPR, 2014.
- Human3.6M
C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 7, pp. 1325–1339, 2014.
- 3DPW
T. von Marcard, R. Henschel, M.-J. Black, B. Rosenhahn, and G. PonsMoll, “Recovering accurate 3d human pose in the wild using imus and a moving camera,” in ECCV, 2018.
期刊会议
2014年至2020年,计算机视觉、多媒体、计算机图形等领域的主流会议(CVPR、ICCV、ECCV等)、期刊(TPAMI、TIP、TOG等)发表论文数量迅速增加。最近的工作主要集中在网络设计和优化、多任务交互、身体模型探索等。
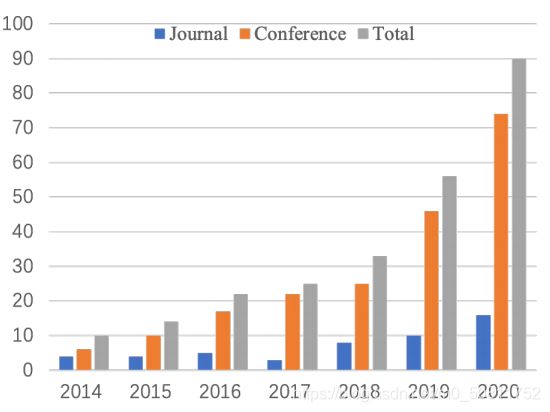
上图描述:2014年至2020年在主流计算机视觉、多媒体和计算机图形会议(CVPR、ICCV、ECCV等)和期刊(TPAMI、TIP、TOG等)上发表的论文数量。
发展
如下图所示,展示了2014年到2021年的里程碑、想法或数据集突破,以及2D和3D姿态估计的最先进方法。

上图描述:从2014年到2021年,里程碑、想法或数据集的突破,以及2D(顶部)和3D(底部)姿态估计的最先进的方法。
2020年
- 2D姿态估计
- D. Sánchez, M. Oliu, M. Madadi, X. Baró, and S. Escalera, “Multi-task human analysis in still images: 2d/3d pose, depth map, and multi-part segmentation,” in FG, 2019.
- Y. Cai, Z. Wang, Z. Luo, B. Yin, A. Du, H. Wang, X. Zhang, X. Zhou, E. Zhou, and J. Sun, “Learning delicate local representations for multiperson pose estimation,” in ECCV, 2020.
- B.-W. Cheng, B. Xiao, J.-D. Wang, H.-H. Shi, T.-S. Huang, and L. Zhang, “Higherhrnet: Scale-aware representation learning for bottomup human pose estimation,” in CVPR, 2020.
- F. Zhang, X. Zhu, H. Dai, M. Ye, and C. Zhu, “Distribution-aware coordinate representation for human pose estimation,” in CVPR, 2020.
- 3D姿态估计
- Y. Sun, Q. Bao, W. Liu, Y.-L. Fu, and T. Mei, “Centerhmr: a bottom-up single-shot method for multi-person 3d mesh recovery from a single image,” 2020.
- A. Benzine, F. Chabot, B. Luvison, Q.-C. Pham, and C. Achard, “Pandanet: Anchor-based single-shot multi-person 3d pose estimation,” in CVPR, 2020.
- M. Kocabas, N. Athanasiou, and M.-J. Black, “Vibe: Video inference for human body pose and shape estimation,” in CVPR, 2020.
- W. Jiang, N. Kolotouros, G. Pavlakos, X.-W. Zhou, and K. Daniilidis, “Coherent reconstruction of multiple humans from a single image,” in CVPR, 2020.
针对MHPE的深度学习框架的概述
难点
人体对于高度自由度的姿态是非刚性和灵活的,因此,从单目摄像机预测人体姿态估计面临着许多挑战,如复杂或奇怪的姿势、人与人的交互或遮挡,以及拥挤的场景等。不同的相机视图和复杂的场景也会引入截断、图像模糊、低分辨率和小目标人等问题。(一个来自于人或人群;一个来自于相机试图或复杂场景)
现有解决方案
- 为了解决这些问题,现有的方法探索了深度学习的强大表示,以挖掘姿态估计的更多的线索。虽然它们在全局设计或详细优化上都有所不同,但里程碑方法的网络架构在内部也有相似之处。如下图所示,大多数流行的单人姿态估计网络可以被认为是由姿势编码器(也称为特征提取器)和姿势解码器组成的。前者旨在通过高到低分辨率的过程来提取高级特征。后者以基于检测的方式或基于回归的方式估计目标输出、2D/3D关键点位置或3D网格。对于姿态解码器,基于检测的方法可以生成特征图或热图,而基于回归的方法可以直接输出目标参数。
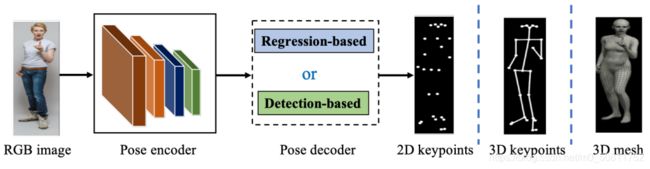
上图描述:单人姿态估计的典型框架 - 对于多人场景,为了估计每个人的2D或3D姿势,现有的作品利用自上而下的范式或自下而上的范式。自上而下的框架首先检测人员区域,然后从这些区域中提取边界框级特征。这些特征被用于估计每个人的姿势结果。相反,自下而上的范式首先检测所有的目标输出,然后通过分组或采样将它们分配给不同的人。如下图所示,具有代表性的两范式的多人的方法依赖于基于姿态编码器和解码器的架构,网络输入是被检测到的边界框或整个图像。
- 因此,如何设计一种有效的姿态编码器和姿态解码器结构是姿态估计中普遍流行的课题。与分类、检测和语义分割不同,人体姿态估计需要处理身体部位之间的细微差异,特别是在不可避免的截断、拥挤和遮挡的情况下。为了实现这一点,可以考虑车身结构模型、多尺度特征融合、多级管道、从粗到细的细化、多任务学习等。
- 此外,关于从单目图像估计3D姿态,另一个挑战是野外3D训练数据不足。由于设备的限制,常见的3D姿态数据集经常在受约束的实验环境中被捕获。例如,最广泛使用的3D姿势数据集,人类3.6M只包含15个由7人进行的室内活动。因此,人类的姿势、形状和场景的多样性是极其有限的。仅在这些数据集上训练的模型很容易在野外图像上失败。为了解决这个问题,许多方法将2D姿态作为中间表示或额外的监督,并从野外2D姿态信息中学习。然而,在这个过程中存在着固有的歧义,即,单个2D姿势可能对应于多个3D姿势,反之亦然。为了解决固有的歧义,我们必须考虑如何在人体、运动连续性和多视图一致性之前充分利用共同的结构。
人体表示
人体的各种表现已经被发展来描述不同方面复杂的人体姿势。他们已经表现出了不同的特征来处理姿态估计的各种挑战。现有的表示可以分为两类:1)基于关键点的表示;和 2)基于模型的表示。
基于关键点的表示
身体关键点的2D或3D坐标是身体骨架的简单而直观的表示,即基于关键点的表示(Keypoint-based Representation),它有几种表示形式。
- 二维/三维的关键点坐标
二维/三维的关键点坐标(2D/3D keypoint coordinates)。主体关键点可以用二维/三维坐标来明确地描述。如图(a)所示,关键点按照固有的身体结构进行连接。身体部分的方向可以从这些连接的四肢中得到。 - 二维/三维热图
二维/三维热图(2D/3D heatmaps)。为了使坐标更适合由卷积神经网络回归,许多方法以热图的方式表示关键点坐标。如图(b)所示,每个关键点的高斯热图在对应的二维/三维坐标上具有高响应值,在其他位置具有低响应值。 - 方向图
方向图(Orientation maps)。有些方法将身体关键点的定位图作为热图的辅助表示。OpenPose开发了著名的部分亲和力场(PAFs)来表示四肢之间的二维方向。如图©所示。PAF是一个二维向量场,它关联了一个肢体的两个关键点。场中的每个像素都包含一个二维向量,它指向四肢的一部分到另一个向量。Orinet进一步将其发展为三维方向图,它可以明确地建模肢体的方向。 - 层次的骨载体
层次的骨载体(Hierarchical bone vectors)。提出了CHP的二维层次骨表示,它是关节和骨向量的组合。Xu等人和Li等人进一步将其开发为3D。如图(d)所示。三维人体骨骼由一组骨骼载体表示。每个骨骼矢量都从父键指向子键,遵循一个运动学树。每个父关键点都与一个局部球坐标系关联。骨矢量可以用这个系统中的一个球面坐标来表示。

基于模型的表示
基于模型的表示(Model-based Representation)是根据人体固有的结构特征而开发的。它提供了比基于关键点的描述更丰富的身体信息。基于模型的表示可以分为基于部分的体积模型和统计的三维人体模型。
- 基于部分的体积模型
基于部分的体积模型(Part-based volumetric model)被开发来解决现实中的挑战。例如,在Y. Cheng等人的研究中,开发了圆柱体模型来生成被遮挡零件的标签。如图(e)的蓝色模型所示,每个肢体都被表示为一个圆柱体。每个圆柱体通过将顶部和底部表面中心与肢体的三维关键点来定位。类似地,如图(e)的粉红色模型所示。提出了以椭球体部件(M. Wang等人研究)为基本单位的椭圆体模型。它比一个圆柱体更灵活。
Y. Cheng, B. Yang, B. Wang, W.-D. Yan, and R.-T. Tan, “Occlusion-aware networks for 3d human pose estimation in video,” in ICCV, 2019.
M. Wang, F. Qiu, W.-T. Liu, C. Qian, X. Zhou, and L. Ma, “Ellipbody: A light-weight and part-based representation for human pose and shape recovery,” arXiv preprint arXiv:2003.10873, 2020.
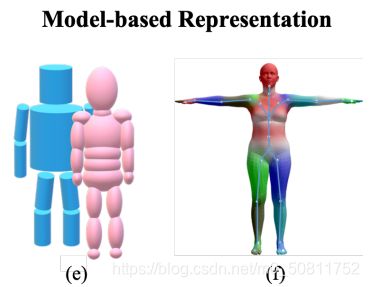
上图描述:(e)圆柱体模型(蓝色)和椭圆体(粉红色) (f) 骨架驱动的皮肤多人线性模型(SMPL)
- 详细统计的三维人体模型
与基于部分的体积模型相比,详细统计的三维人体模型(Detailed statistical 3D human body model)描述了更详细的信息,包括身体的姿势和形状。本文介绍了最广泛使用的皮肤多人线性模型(SMPL),这是一个骨架驱动的人体模型。
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M.-J. Black, “SMPL: A skinned multi-person linear model,” ACM Transactions on Graphics, 2015.
3D到2D投影
3D到2D投影(3D-to-2D Projection)将3D空间连接到2D图像平面。介绍此工具必须更好地了解使用它的方法。3D到2D投影使用相机模型生成3D-2D姿势对,使用2D姿态注释监督3D姿势,或通过3D姿态投影细化2D姿势。透视相机模型和弱透视相机模型是两种广泛使用的相机模型。
- 透视照相机模型
Perspective camera model。透视照相机模型通常用于将三维空间中的点投影到图像平面上的二维像素坐标中。通常,它由两个步骤组成。首先,需要用外部矩阵 [R|t] 将三维点转换为相机坐标,它描述相机的旋转和平移。其次,我们需要内在矩阵K来进行自适应调整来精确投影。因此,三维关键点J3d的二维投影J2d可以被描述为J2d=K[R|t]J3d。 - 弱透视图的摄像机模型
Weak-perspective camera model。在大多数情况下,输入的二维图像未经校准,很难检索到完整的透视相机参数。因此,弱透视相机模型更广泛地应用于现有的计算三维关键点J3d的二维投影Jwp2d的方法。
单目2D姿态估计(待补充)
(这个部分,后面再补充,先讲3D姿态估计,目前我自己也在做3D的姿态估计。)
单目3D姿态估计
分类
根据输出表示法,单目3D姿态估计可以分为基于骨架的3D姿态估计和基于网格的3D姿态估计。前者预测身体关节的3D位置,而后者根据人体网格拓扑或统计的3D身体模型输出3D身体网格。与2D姿态估计相比,从单目2D图像中估计3D姿态更具挑战性。除了2D部分的所有挑战外,单目3D姿态估计还缺乏野外3D数据和固有的2D到3D的模糊性。
难点
- 第一个大的挑战是缺乏足够的具有准确3D注释的野外数据。大多数存在的3D姿态数据集的多样性是不够的。精确地捕捉2D图像的3D姿态注释是很困难和昂贵的,尤其是在户外条件下。现有的3D姿态数据集往往偏向于特定的环境中受限的行为 (例如室内)。例如著名的3D姿态数据集Human3.6M,只有11个参与者执行15个活动。相比之下,2D姿态数据很容易被收集,它包含了更丰富的姿态和环境。因此,经常使用2D姿态数据集来改进3D算法的泛化。例如,大多数现有的3D姿态估计方法都采用2D姿态作为中间表示或甚至网络输入,以减少困难。此外,许多方法提出了无监督或弱监督框架来减轻完全监督方法对数据集的依赖。
- 失去深度信息可能会导致3D姿态估计中固有的2D到3D的模糊问题。特别是对于基于两个阶段的3D姿态估计方法,它们首先尝试从图像中估计2D姿态,然后将2D姿态提升到3D。这些方法固有的模糊问题甚至很严重,因为多个3D姿势可以映射到相同的2D关键点。许多方法试图通过使用各种先验信息来解决这个问题,如几何先验知识、统计模型和时间平滑性。
上图描述:具有代表性的基于深度学习的单目三维姿态估计方法
特附2020-2021年3D姿态估计方法(与原文无关)
(关于2020-2021年3D姿态估计的方法归纳在我另一篇文章中有介绍)
3D人体姿态估计(介绍及论文归纳)
基于骨架的三维姿态估计
如下图所示,根据该表示,常用的单人三维姿态估计方法一般采用三种框架,即基于 1) 体积热图、2) 将2D姿态提升到3D姿态,3) 将图像特征与2D姿态融合的方法。此外,由于其重要意义,我们还总结了解决3D姿态估计中两种常见的具有挑战性的情况的方法,即 4) 缺乏3D数据和 5) 2D-3D固有的模糊性。
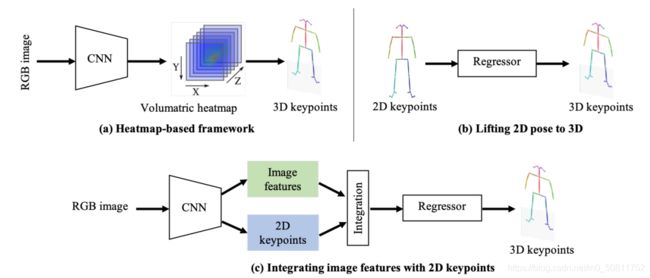
上图描述:单目三维人体姿态估计的代表性框架
基于热图的方法
基于热图的方法 (Heatmap-based Methods)。与直接预测每个关键点的3D位置的基于回归的方法不同,基于热图的方法将每个3D关键点表示为热图中的3D高斯分布。然后在后处理中,我们可以通过获取局部最大值,轻松地从估计的体积热图中解析3D关键点坐标。因此,如上图(a)所示,基于热映射的方法被设计为通过端到端框架直接从单目图像估计体积热图。沿着这种流程,提出了 Coarse-to-Fine (C2F) 网络来叠加沙漏网络,并逐步扩展预测的热图的体积方向,以获得良好的结果。此外,VNect是一种实时单目3D姿态估计方法。它使相干运动骨架在后处理中得到拟合,从而基于相干运动骨架产生时间稳定的姿态结果。为了简化后处理,积分人姿态Integral Human Pose (IHP) 提出了一种积分操作,在正向推理过程中以可微的方式将热图直接转换为关键点坐标。它在基于热图的方法和基于回归的方法之间建立了一个桥梁。
提升2D姿态到3D姿态
提升2D姿态到3D姿态 ( Lifting 2D Pose to 3D)。受益于稳健的2D姿态估计方法,如上图(b)所示,许多方法侧重于通过一个简单的回归器将2D姿态提升到3D。整个流程可分为两部分:1)从单目照片中估算2D姿态 2) 将估计的2D姿势提升到3D姿势。这样,他们就可以建立基于2D姿态估计的3D方法。模型的复杂度要低得多,而泛化性则可以得到改进。
- Martinez等人,提出了一种简单的3D方法,这是一种著名的简单的基线方法,可以从2D姿态中估计每个关键点的深度。它只包含两个完全连接的块,同时在相关的基准测试上实现了良好的性能。
J. Martinez, R. Hossain, J. Romero, and J.-J. Little, “A simple yet effective baseline for 3d human pose estimation,” in CVPR, 2017.
- Chen等人,通过姿态匹配,解决了2D到3D的关键点提升问题。为了丰富匹配库,他们通过使用随机照相机将3D姿态投影回2D图像平面,生成大量的2D-3D位姿对。然后他们会得到一个大型的包含2D-3D姿势对的库。选择配对的3D姿态作为3D姿态估计结果。
C.-H. Chen and D. Ramanan, “3D human pose estimation = 2d pose estimation+ matching,” in CVPR, 2017.
- Tome等人,开发了一个多阶段的卷积网络来递归地优化估计的三维位姿。他们改进了利用估计的三维姿态的后投影进行中间二维姿态,这逐步提高了二维和三维位姿估计的精度。
D. Tome, C. Russell, and L. Agapito, “Lifting from the deep: Convolutional 3d pose estimation from a single image,” in CVPR, 2017.
- 此外,Chen等人,利用二维姿态输入与估计的三维姿态的二维投影之间的周期一致性,以无监督的方式学习二维到三维的提升函数。如果没有任何3D注释,循环一致性就不能帮助模型正确地学习深度。该模型可以收敛到一个具有恒定深度的局部最小值。为了解决这个问题,他们利用了几何之前,即来自不同视图的相同三维姿态的二维投影应该提升到相同的三维姿态。具体地说,首先将提升的三维姿态从随机视图投影回二维图像,以利用生成对抗的二维姿态来监督深度合理性。然后,他们将随机投影的二维姿态提升到三维,并监督其来自原始视图的二维投影与原始二维姿态输入之间的差异。这样,模型就可以不需要任何三维注释而得到正确的训练。
C.-H. Chen, A. Tyagi, A. Agrawal, D. Drover, S. Stojanov, and J. M. Rehg, “Unsupervised 3d pose estimation with geometric self-supervision,” in CVPR, 2019.
将图像特征与2D关键点进行集成
将图像特征与2D关键点进行集成 (Integrating Image Features with 2D Keypoints)。如上图©所示,一些方法试图将基于热映射和提升2D姿态到3D框架集成在一起。一方面,2D关键点提供了有限的人体信息,这可能会使2D到3D的提升在具有挑战性的场景中模糊不清。另一方面,图像特征提供了更多的上下文信息,这有助于确定准确的3D姿态。
Nie等人就是这样做的,建议将关键点的局部图像纹理特征集成到2D姿态的全局骨架中。然后建立了LSTM网络的两级层次结构,逐步建模全局和局部特征。此外,SemGCN和Liu等人,都提取联合级图像特征,并将它们与关键点坐标集成以形成多个图形节点。接下来,使用GCN和LSTM,利用图像功能,深入挖掘这些节点之间的关系。
解决数据缺乏的问题
解决数据缺乏的问题 (Solving the Data Deficiency Problem)。大多数三维姿态数据集都捕捉到了一些参与者在室内环境中非常有限的活动。与二维姿态数据集相比,三维姿态数据集在姿态和环境的多样性上表现得较差。为了处理这个问题,许多方法试图以无监督或弱监督的方式训练模型。
-
Pavlakos等人,利用关键点之间的弱有序深度关系进行监督。实验表明,与使用地面真值三维姿态标注的直接监督相比,顺序监督也能达到比较性能。
G. Pavlakos, X. Zhou, and K. Daniilidis, “Ordinal depth supervision for 3d human pose estimation,” in CVPR, 2018.
-
Hemlets 通过一个热图三重态损失作为地面真相来编码相邻关键点的显式深度排序。
K. Zhou, X.-G. Han, N.-J. Jiang, K. Jia, and J.-B. Lu, “Hemlets pose: Learning part-centric heatmap triplets for accurate 3d human pose estimation,” in ICCV, 2019.
除了之前的身体结构外,许多方法都建议使用多视图一致性来进行监督。然而,只有考虑到多视图的一致性,才会导致一个退化的解。该模型可能被困在一个局部最小值中,并对不同的输入产生相似的零姿态。
-
Rhodin等人,建议使用少量的标记数据来避免局部最小值,并纠正预测。
H. Rhodin, J. Spörri, I. Katircioglu, V. V. Constantin, F. Meyer, E. Müller, M. Salzmann, and P. Fua, “Learning monocular 3d human pose estimation from multi-view images,” in CVPR, 2018.
-
Rhodin等人,建议使用序列图像为身体表示学习提供时间一致性先验。
H. Rhodin, M. Salzmann, and P. Fua, “Unsupervised geometry-aware representation for 3d human pose estimation,” in ECCV, 2018.
-
EpipolarPose 利用多视图二维姿态,通过上极性几何生成三维姿态注释。通过这种方式,就可以以一种自我监督的方式来训练整个框架。
M. Kocabas, S. Karagoz, and E. Akbas, “Self-supervised learning of 3d human pose using multi-view geometry,” in CVPR, 2019.
-
Umar等人,通过一种新的基于对准的对象函数来解决退化陷阱,而不需要外部相机校准。他们使用未标记的多视图图像和二维姿态数据集来训练模型。二维姿势只用于训练二维姿势主干。利用多视图图像进行了相应的三维姿态估计。多视图三维姿态结果被归一化,然后使用普罗克鲁斯分析的一致性。在这个过程中,三维姿态被转换为相同的尺度的刚性对齐。
I. Umar, M. Pavlo, and K. Jan, “Weakly-supervised 3d human pose learning via multi-view images in the wild,” in CVPR, 2020.
-
Mitra等人,提出了多视图一致的半监督学习(MCSS)框架,它试图学习以半监督方式嵌入的视图不变姿态。一方面,训练该模型通过使左骨盆骨平行于XZ平面来估计视图不变的三维姿势。另一方面,应用基于时间关系的硬负挖掘来获得不同视图中一致的姿态嵌入。
R. Mitra, N.-B. Gundavarapu, A. Sharma, and A. Jain, “Multiview-consistent semi-supervised learning for 3d human pose estimation,” in CVPR, 2020.
此外,还提出了从数据合成中学习模型的方法。通常,合成数据管道有两种类型:1)2D图像拼接管道和 2)3D模型投影管道。对于第一个框架,Rogez等人,尝试生成来自3D运动捕捉 (MoCap) 数据集的3D姿势的2D图像。他们首先选择其2D姿态与投影的3D姿态的一部分相匹配的图像补丁。在运动学约束下,局部图像补丁被缝合,以形成3D姿态的完整2D图像。
不同的是,Chen等人和 Varol等人,遵循3D模态投影管道。他们将纹理统计人体模型投影到二维野外背景图像上,用于进行数据生成,例如,the Shape Completion and Animation of People (SCAPE) 和SMPL。这样,就可以获得2D野外人图像的完整的3D注释。注释不仅包含3D身体姿势、形状和纹理,还包含相机和灯光参数。综上所述,2D图像拼接管道有潜力生成更真实的人的图像,而3D模型投影管道可以获得更全面的3D注释。此外,人利用3D到2D投影构建了一个自监督的训练管道。
PGP-Human 利用从野外视频中采样的图像对进行训练,其中包含同一个人在不同的背景下执行不同的动作。该模型经过训练,通过混合从图像对中提取的图像和姿态信息,以进行图像重新合成。在此过程中,采用the Puppet model 将后投影二维姿态转换为部分分割图,以促进外观重建。
解决内在的模糊性问题
解决内在的模糊性问题 (Solving the Inherent Ambiguity Problem)。由于在深度上固有的模糊性,单个二维姿态可能对应于多个三维姿势,特别是在将二维姿势提升到三维的管道中。因此,采用各种先验约束来确定特定的姿势。**许多方法使用时间一致性和动力学来解决单个二维姿态的模糊性。**例如,方法RSTV会直接回归从边界框的时空体积到中心框架中的三维姿态。该方法通过训练两个网络来预测连续帧之间的大体位移,然后进行细化来实现运动补偿。Fang等人,通过双向rnn的层次结构,明确地将身体先验(包括运动学、对称性和驱动的关节协调)合并到模型中。这样,就可以监督三维姿态预测,以遵循身体的先验约束和时间动力学。
此外,Lin等人,TP-Net和Lee等人,开发由LSTM单元组成的序列到序列网络来从二维姿态估计三维姿态序列。通过探索运动序列中的运动动力学,可以更好地确定每个帧的具体位置。此外,为了提高计算效率,视频姿态三维和OANet在二维姿态序列上采用时间卷积,以保证时间一致性。完整的卷积体系结构可以实现高效的并行计算。不同的是,OANet使用圆柱体人体模型来生成遮挡标签,这可以帮助模型学习身体部位之间的碰撞。此外,Sharma等人,以生成的对抗方式解决歧义。他们训练一个有条件的VAE网络来证明基于二维姿态的三维姿态样本的合理性。此外,ActiveMoCap试图估计不同预测的不确定性,后者用于选择具有较低模糊性的最佳输出。它帮助模型学习三维姿态估计的最佳观点。
除了时间一致性之外,其他一些方法还试图通过开发一种更接近身体结构的表示法来解决模糊性。例如,Xu等人和Li等人,采用了层次骨表示,在该层次的骨表示中,明确地建模了相邻关节的几何依赖性,主要侧重于监督骨的长度和关节的方向。利用分层骨骼表示,三维身体骨架是可分离的,很容易混合合成新的骨架。因此,Li等人,建议通过混合不同的骨骼图像来丰富训练数据的姿态空间。使用扩展数据的训练有助于改进模型的泛化。
多人3D姿态估计
多人3D姿态估计 (Multi-person 3D Pose Estimation)。在一般情况下,现实世界中的场景总是包含多个人。与多人2D姿态估计所面临的挑战相似,3D情况也可以预测了每个人的根深度和关键点相对深度。根据处理管道,现有的多人3D姿态估计方法大致可以分为两类:1)自上而下的范式,2)自下而上的范式。自上而下的方法首先检测这个人,然后分别估计每个人的3D姿势。自下而上的方法首先检测关键点,然后将它们分组以形成每个人的3D姿势。
- 自上而下的范式 (Top-down Methods)
作为一种典型的自上而下的范式,LCRNet建立在通用的两阶段基于锚的检测框架上。他们首先从主持人提案中收集姿势候选人,然后通过评分排名确定最终结果。同样地,Moon等人的工作也是建立在基于锚的检测框架之上的。他们利用从检测到的人员区域及其边界框位置得到的单独网络分支估计了三维绝对根定位和根相对姿态估计。
G. Rogez, P. Weinzaepfel, and C. Schmid, “Lcr-net++: Multi-person 2d and 3d pose detection in natural images,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 5, pp. 1146–1161, 2019.
G. Moon, J.-Y. Chang, and K.-M. Lee, “Camera distance-aware top-down approach for 3d multi-person pose estimation from a single rgb image,” in ICCV, 2019.
- 自下而上的范式 (Bottom-up Methods)
遵循这个范式,Zanfir等人,提出了一种自下而上的多阶段单目多人三维姿态估计框架。他们首先从单个图像中估计体积热图,以确定三维关键点的位置。然后,预测检测到的关键点之间所有可能连接的置信度分数将形成四肢。最后,他们执行骨骼分组,将四肢分配给不同的人。此外,为了处理多人场景中的遮挡问题,Mehta等人,开发了一个遮挡-鲁强的姿态映射(ORPM),以包括冗余的遮挡信息。此外,他们还提出了第一个多人三维姿态数据集MuCo3DHP,这极大地促进了这一领域的发展。此外,Fabbri等人,提出以编码器-解码器的方式估计体积热图,并从它们中回归多人三维姿态。中间编码特征是通过地面真关键点热图的编码特征来压缩体积热图的。不同的是,PandaNet 是一种基于锚的多人三维姿态估计单镜头模型。它直接预测每个锚定位置的二维/三维姿态。此外,SMAP 估计多个映射,表示每个位置的身体根深度和部分相对深度。要对热图上的关键点进行分组,它们将使用估计的深度来确定关联。HMOR 对多人交互关系进行建模,以获得更好的性能。它通过实例级、部分级和联合级,按层次结构估计多人的顺序关系 (instance-level, part-level, joint-level)。
基于网格的3D姿态估计
基于网格的3D姿态估计 (Mesh-based 3D Pose Estimation)。基于网格的来自单个图像的三维姿态估计可以提供除关键点位置之外的额外的体型信息,因此引起了人们的广泛关注。这个社区最近的作品可以大致地分为两类。第一种是直接从输入图像中恢复三维人体形状,输入图像使用具有数千个顶点的三维网格来表示人体。例如,基于预定义的网格拓扑,GraphCMR 可以使用图形卷积神经网络 (GCNNs)来恢复三维网格顶点。同样地,Pose2Mesh 提出了一个使用GCNN的级联模型。不同的是,I2L-MeshNet 提出了一个图像到像素(线像素)预测网络,它预测了一维热图上的每像素的可能性,以回归每个网格顶点坐标。
与网格顶点回归不同,其他一种方法采用统计3D人模型,如 SMPL,作为表示,它可以带来强几何先验。从而将三维姿态估计表示为对SMPL姿态和形状参数的估计。如下图所示,一般框架是直接从一人2D RGB图像估计相机和SMPL参数。首先,我们可以从SMPL参数中推导出3D人体网格,并从网格中回归3D关键点。在这个社区中,大多数工作都集中在 1)如何解决三维数据短缺问题,2) 为基于网格的三维姿态估计提供更适当的表示,3) 在实际应用场景中处理多人情况。

上图描述:基于SMPL模型的基于网格的3D姿态估计的代表性框架
- Solving the Lack of Data
解决数据不足的问题:由于数据短缺,应该使用所有可用的2D/ 3D姿态数据集进行监督。许多方法开发各种损失函数来监督估计的身体网格的不同方面。Human Mesh Recovery (HMR)利用从2D姿态和3D运动捕捉数据集中学习非配对数据的方法。如果只有在没有深度监督的情况下学习2D姿势,就会导致不合理的三维姿势和形状。相反,他们使用2D pose and 3D motion capture (MoCap) 数据以生成式对抗的方式来监督估计参数的合理性。建立了一种鉴别器来确定估计的SMPL姿态和形状参数是否合理。
为了指导模型显式地从现有数据中学习,一些方法对2D图像的固有特性进行监督。为了从时间动力学中学习,训练了一个3D人类动力学模型 ( human dynamics model) 来估计当前、过去和未来帧的3D姿态。为了将静态图像转移到一个运动序列中,我们学会了一个幻觉器来估计过去和未来运动的合成特征。为了从时间的光滑性中学习,Kocabas等人,开发了一个名为VIBE的时间网络。在HMR之后,他们使用运动鉴别器以生成对抗的方式监督预测运动序列的合理性。具体地说,通过 Gated Recurrent Units (GRUs),描述运动序列的SMPL参数在每个时间步长都被映射到一个潜在的表示形式。除了利用时间信息外,TexturePose 还利用同一人在多个视点或相邻视频帧之间的外观一致性进行监督。身体纹理从二维图像映射到UV映射,后者在语义上对齐多视图或顺序纹理。每个人的多个紫外线贴图中只有可见的部分会以纹理一致性进行监督。
此外,还提出了一些方法来发展更详细的监督。例如,HoloPose 提出了一个多任务网络来估计 DensePose 、2D和3D的关键点,以及基于部分的3D重建。提出了一种迭代改进方法来改进基于模型的3D关键点估计与 DensePose 之间的一致性。此外,Human Mesh Deformation (HMD) 利用附加信息,包括身体关键点、轮廓和每像素阴影,来优化估计的3D网格。通过分层网格投影和变形细化,身体网格与输入2D图像中的人良好对齐。 SMPLify 提出通过将SMPL模型与预测的2D关键点拟合并最小化重新投影误差来估计3D人网格。循环方法中的SMPL优化方法试图结合基于回归和基于优化的方法的优点。他们利用SMPLify来改进训练循环中的估计结果,以提供额外的3D监督。
R.-A. Guler and I. Kokkinos, “Holopose: Holistic 3d human reconstruction in-the-wild,” in CVPR, 2019.
R.-A. Guler, N. Neverova, and I. Kokkinos, “Densepose: Dense human pose estimation in the wild,” in CVPR, 2018.
H. Zhu, X. Zuo, S. Wang, X. Cao, and R. Yang, “Detailed human shape estimation from a single image by hierarchical mesh deformation,” in CVPR, 2019.
F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, and M.-J. Black, “Keep it smpl: Automatic estimation of 3D human pose and shape from a single image,” in ECCV, 2016.
- Model Representations
模型表示:考虑到从全局图像特征中对所有参数的回归对于复杂的体网格是模糊的,越来越多的研究人员专注于探索基于网格的3D姿态估计的更适当的表示。例如,Graph CMR 对3D人体网格使用了基于图形的表示。通过图卷积网络(GCN),估计每个网格顶点在每个节点上的3D位置。然后,可以从这些顶点中估计出SMPL参数。基于DensePose,DenseRaC 使用估计的 IUV 映射作为中间表示来估计SMPL参数。具体地说,使用差分渲染器 ( differential renderer) 将估计的体网格渲染回 IUV 映射,并与用于监督的输入进行比较。Sun等人,利用双线性变换开发了一种骨架解纠缠表示法来解决二维姿态的特征耦合问题和其他细节。他们还使用了一个基于变压器的网络来学习时间平滑性,其中开发了一种无监督的对抗性训练策略,通过排序洗牌帧 (ordering the shuffled frames) 来学习运动动力学。
与恢复单体三维网格不同,一些工作将研究扩展到多体三维网格恢复的表示中。例如,SMPL+H 将三维手模型集成到SMPL身体模型中,以共同恢复身体和手的三维网格。Xiang等人,提出了MTC方法,使用单独的CNN网络来估计身体、手和脸,然后共同将 Adam 模型拟合到所有身体部分的输出中。SMPL-X 将 FLAME head model 和 SMPL+H 结合起来,并通过拟合模型到三维扫描数据来学习与姿势相关的混合形状。SMPLify-X 被提出通过迭代匹配 SMPL-X 到面部、手、身体的二维关键点来恢复人体的三维网格。
N. Kolotouros, G. Pavlakos, and K. Daniilidis, “Convolutional mesh regression for single-image human shape reconstruction,” in CVPR, 2019.
Y.-L. Xu, S.-C. Zhu, and T. Tung, “Denserac: Joint 3d pose and shape estimation by dense render-and-compare,” in ICCV, 2019.
Y. Sun, Y. Ye, W. Liu, W.-P. Gao, Y.-L. Fu, and T. Mei, “Human mesh recovery from monocular images via a skeleton-disentangled representation,” in ICCV, 2019.
J. Romero, D. Tzionas, and M.-J. Black, “Embodied hands: Modeling and capturing hands and bodies together,” ACM Transactions on Graphics, vol. 36, no. 6, p. 245, 2017.
D.-L. Xiang, H. Joo, and Y. Sheikh, “Monocular total capture: Posing face, body, and hands in the wild,” in CVPR, 2019.
G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A.-A. Osman, D. Tzionas, and M.-J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” in CVPR, 2019.
T.-Y. Li, T. Bolkart, M.-J. Black, H. Li, and J. Romero, “Learning a model of facial shape and expression from 4D scans,” ACM Transactions on Graphics, vol. 36, no. 6, pp. 194–1, 2017.
- Multi-person 3D Mesh Recovery
多人3D网格恢复:虽然在单人场景的单目3D人体姿态和形状估计方面取得了很大进展,但处理截断、环境遮挡和人-遮挡的多人案例是至关重要的。现有的多阶段方法为单人管道配备了一个2D人检测器来处理多人场景。与只估计几十个身体关节的2D/3D关键点估计不同,最近的工作也试图探索三维网格恢复的特殊性。例如, Zanfir等人,建议在多人场景中使用自然场景约束。为了得到初始的3D体网格,他们将SMPL模型与3D姿势相匹配,并根据图像估计其语义分割。为了排除体积占用的情况,他们在目标函数中施加了碰撞约束。同时,估计地平面可以模拟地平面与所有人类受试者之间的相互作用。此外,Jiang等人,提出使用 the coherent reconstruction of multiple humans (CRMH) 进行多人三维网格恢复。他们基于更快的 RCNN 构建他们的方法,其中使用roi对齐的特征来预测SMPL参数。特别来说,它们发展了一个可微的插值损失,以避免体网格之间的碰撞。此外,为了学习多人之间正确的深度排序,他们通过实例分割来监督多人身体网格的呈现。最近,Sun等人,提出了一种基于中心的实时人网恢复网络,这是一种新型的自下自上的单镜头恢复方法。训练该模型同时预测两个特征图,它们分别表示每个人体中心的位置和每个中心的3D人体网格的相应参数向量。显式的基于中心的表示保证了像素级的特征编码。每个人的3D网格结果都是从以可见身体部位为中心的特征来估计的,这提高了在遮挡条件下的鲁棒性。此外,为了处理具有严重重叠的拥挤情况,本文提出了一种遮挡感知中心表示方法。
A. Zanfir, E. Marinoiu, and C. Sminchisescu, “Monocular 3d pose and shape estimation of multiple people in natural scenes-the importance of multiple scene constraints,” in CVPR, 2018.
W. Jiang, N. Kolotouros, G. Pavlakos, X.-W. Zhou, and K. Daniilidis, “Coherent reconstruction of multiple humans from a single image,” in CVPR, 2020.
Y. Sun, Q. Bao, W. Liu, Y.-L. Fu, and T. Mei, “Centerhmr: a bottom-up single-shot method for multi-person 3d mesh recovery from a single image,” 2020.
评估指标
2D姿态估计的评价指标
二维姿态估计的评价指标 (Evaluation Metrics of 2D Pose Estimation)。二维位姿估计的评估旨在测量预测的二维位置的准确性。根据数据集的特点,广泛使用的评估指标包括正确零件百分比(PCP)、正确关键点百分比(PCK)和平均精度(AP),具体介绍如下。
正确部分的百分比(PCP)
正确部分的百分比(Percentage of Correct Parts, PCP)被提出了来测量身体部分预测的准确性。如果估计的相应肢体的两个端点在地面真端点的阈值(50%)内,那么身体部分的预测是准确的。具体来说,M. Andriluka等人的研究中的PCPm是通过使用整个测试集中的平均地面真值段长度的50%作为PCP的匹配阈值来定义的。然而,PCP有一个缺点,即缩短缩短影响不同视图和范围内的身体部位的正确测量。
V. Ferrari, M. Marin-Jimenez, and A. Zisserman, “Progressive search space reduction for human pose estimation,” in CVPR, 2008.
M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in CVPR, 2014.
正确关键点的百分比(PCK)
正确关键点的百分比(Percentage of Correct Keypoints, PCK)是一个广泛使用的度量标准来衡量二维关键点预测的准确性。在Y. Yang等人的研究中,测量关键点的阈值定义为人边界框大小的一小部分。类似地,检测到的关节的百分比(the Percentage of Detected Joints, PDJ)将阈值设置为由每个测试样本[B. Sapp等人]的躯干高度标准化的像素半径。[email protected]是对PCK的一个轻微的修改。采用匹配阈值作为测试人员头段长度的50%。通过使用水头尺寸作为参考,PCKh使测量的清晰度独立于测量。通过改变阈值百分比,可以生成曲线下的面积(AUC),以进一步评估不同的姿态估计算法的能力。
Y. Yang and D. Ramanan, “Articulated human detection with flexible mixtures of parts,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 12, pp. 2878–2890, 2012.
B. Sapp and B. Taskar, “Modec: Multimodal decomposable models for human pose estimation,” in CVPR, 2013.
平均精度(AP)
平均精度(Average Precision, AP),首先称为关键点的平均精度(APK),在Y. Yang等人的研究中提出了测量在测试时没有注释边界框的真实系统中的姿态估计。如果检测到的候选关键点在基本阈值内,则被认为是正确的(true positive,真阳性)。每个关键点分别计算其与地面真实姿态的对应关系。 AP正确地惩罚了错过的发现和假阳性。在T.-Y. Lin等人的研究中,对于多人姿态估计,是通过测量对象关键点相似度(OKS)来计算AP的。就和在目标检测中的IoU一样,OKS测量了预测和真事实之间的相似性:
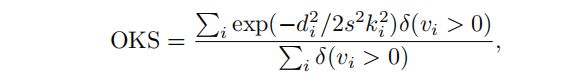
其中di是检测到的关键点和相应的地面真值之间的欧几里得距离,vi是地面真值的可见性标志,s是人的尺度,ki是一个控制下降的关键点常数。对于每个关键点,OKS的范围介于0和1之间。
对于所有标记关键点的OKS,可以计算平均精度(AP)和平均召回率(AR)。通过调整OKS值,可以计算出精确召回曲线。不同OKS下的AP和AR可以完全反映测试算法的性能。对于COCO数据集[T.-Y. Lin等人研究],有10个度量值用于评估关键点检测器的性能,包括AP0.5(AP at OKS = 0.50)AP0.75, AP (the mean of AP scores at 10 values, OKS = 0.50 : 0.05 : 0.95), APM for medium objects, APL for large objects, AR0.5, AR0.75, AR, ARM for medium objects, ARL for large objects. AP和AR的度量标准有助于理解哪些关键点比其他关键点更困难。它们已被广泛应用作多人姿态估计的评价度量。
Y. Yang and D. Ramanan, “Articulated human detection with flexible mixtures of parts,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 12, pp. 2878–2890, 2012.
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C.-L. Zitnick, “Microsoft coco: Common objects in context,” in ECCV, 2014.
3D姿态估计的评价指标
三维姿态估计的评价指标 (Evaluation Metrics of 3D Pose Estimation)。
每个关节位置的平均误差(MPJPE)
每个关节位置的平均误差(The Mean Per Joint Position Error, MPJPE)是3D姿态估计中应用最广泛的评价指标。它测量了从3D姿态预测到地面真相的平均欧几里得距离,单位为毫米。预测和地面真相关键点由骨盆关键点对齐,以进行比较。
按比例对齐的MPJPE(PA-MPJPE)
对齐MPJPE(Procrustes Aligned MPJPE, PA-MPJPE)是对MPJPE的一种修正,可以通过将预测的姿态与毫米严格校正来得到。它也被称为重建误差。通过普罗克鲁特的对齐,消除了平移、旋转和尺度的影响,这使得PA-MPJPE专注于评估重建的3D骨架的准确性。
3D PCK & AUC
3D PCK是PCK度量的3D版本。在不同的方法中,成功预测的阈值通常设置为50毫米或150毫米。相应地,通过将阈值从0改变到200mm来计算PCK来计算作为PCK阈值曲线下的总面积的AUC。
**AUC(Area Under Curve)**被定义为ROC曲线下与坐标轴围成的面积。
其中,ROC曲线全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。
平均每关节角误差(MPJAE)
平均每关节角误差(The Mean Per Joint Angle Error, MPJAE)测量预测关键点方向与地面真实方向之间的角度。方向差以 SO(3) 中的测地线距离来测量。详细的定义可以在 “以下引用论文” 中建立起来。此外,只使用四肢和根的角度进行评价。
G. Pons-Moll, “Human pose estimation from video and inertial sensors,” Ph.D. dissertation, Leibniz Universität Hannover Hannover, 2014.
按比例对齐的MPJAE(PA-MPJAE)
对齐MPJAE(Procrustes Aligned MPJAE, PA-MPJAE)测量由所有预测方向的旋转矩阵归一化的MPJAE的方向。旋转矩阵由普罗克鲁特斯对齐得到。同样地,PA-MPJAE也忽略了全局不匹配。
数据集
相关数据集的快速发展促进了基于深度学习的姿态估计方法的发展。公共数据集为不同的方法提供了培训来源和公平的比较。考虑到数据集的规模和姿势和场景的多样性,在本节中,主要介绍了近年来的代表性数据集。它们中大多数都是高质量和大规模的数据集,在不同的拍摄场景中都有良好的注释。
图像级2D单人数据集(待补充)
Leeds Sports Pose (LSP) Dataset
Leeds Sports Pose (LSP) Dataset(LSP)是从Flickr使用八项运动活动(田径、羽毛球、棒球、体操、跑酷、足球、网球和排球)的标签收集的。该数据集包含2000张图像,其中1000张图像用于训练,其余1000张图像用于测试。每个人都由全身的14个关键点进行标记。与那些新发布的数据集相比,LSP的规模相对较小。它是对单人姿态估计方法的初始性能评估。
S. Johnson and M. Everingham, “Clustered pose and nonlinear appearance models for human pose estimation.” in BMVC, 2010.
Frames Labeled in Cinema (FLIC) Dataset
Frames Labeled in Cinema (FLIC) Dataset包含从好莱坞电影中收集的5003张图像。他们每在30部电影的第十帧上运行一次人体探测器[L. Bourdev等人的研究]。最初,2万名候选人是由众包市场亚马逊机械土耳其有10个上半身关键点。患者被遮挡或严重非额叶的图像被滤掉。最后,选择了1016张图像作为测试集。
B. Sapp and B. Taskar, “Modec: Multimodal decomposable models for human pose estimation,” in CVPR, 2013.
L. Bourdev and J. Malik, “Poselets: Body part detectors trained using 3d human pose annotations,” in ICCV, 2009.
MPII Dataset
MPII数据集是一个大型数据集,包含丰富的活动和多样性捕获环境。它是从YouTube上跨越491个不同活动的3913个视频中收集出来的。从收集的视频中提取24,920帧。这些注释是由亚马逊机械土耳其人(AMT)上的内部工人进行的。注释包括16个关键点的二维位置,完整的三维躯干和头部方向,关键点的遮挡标签,和活动标签。相邻的视频帧也可用于运动信息。最后,标记人数为40522人,其中28821人用于培训,11701人用于检测。MPII数据集已被广泛应用于姿态估计和其他姿态相关的任务。表中的内容。四、展示了在MPII测试集上评估的最新方法。由于该姿势相对容易,所以检测到的二维关键点的精度较高而且性能也接近饱和度。
M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in CVPR, 2014.
图像级2D多人数据集
Microsoft Common Objects in COntext (MSCOCO) Dataset
Microsoft Common Objects in COntext (MSCOCO)数据集包含用于对象检测、泛视分割和关键点检测的注释。这些图片收集的来自谷歌、必应和Flickr等网站。这些注释由Amazon’s Mechanical Turk (AMT)上的工作人员执行。该数据集包含超过20万张图像和25万人的实例。与数据集一起,自2016年以来,COCO关键点检测的挑战每年都在举行。该数据集有两个版本。区别在于训练和验证集的分割。在2017年的最新版本中,训练/val图像分割是118K/5K,而不是之前的83K/41K。测试集包含20K个图像,注释由官方测试服务器保存。此外,还发布了12万张未标记图像,它们遵循与标记图像相同的类分布。它们可以用于半监督的学习。对于关键点检测,17个关键点与可见性标签、边界框和身体分割区域一起被标记。COCO数据集一直是一个被广泛使用的评估基准,并作为动作识别和人的ReID等姿势相关任务的辅助数据。下表中的相关内容显示了最先进的方法在COCO测试集中的性能。RSN[Y. Cai等人的研究]实现了78.6mAP,显示了自上而下的方法的优越性。随着网络骨干网和关键分组方法的改进,自下而上的方法迅速发展。HigherHRNet [B.-W. Cheng等人的研究]获得70.5mAP。自下而上的方法可能有可能实现与自上而下的方法类似的性能。
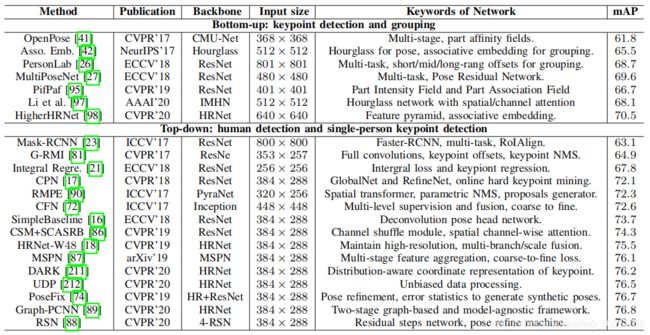
上图描述:具有代表性的二维多人姿态估计方法在COCO测试开发集上的性能。对于自下而上的方法,所报告的结果使用了多尺度的测试
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C.-L. Zitnick, “Microsoft coco: Common objects in context,” in ECCV, 2014.
Y. Cai, Z. Wang, Z. Luo, B. Yin, A. Du, H. Wang, X. Zhang, X. Zhou, E. Zhou, and J. Sun, “Learning delicate local representations for multi-person pose estimation,” in ECCV, 2020.
B.-W. Cheng, B. Xiao, J.-D. Wang, H.-H. Shi, T.-S. Huang, and L. Zhang, “Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation,” in CVPR, 2020.
AI-Challenger Dataset
AI-Challenger Dataset,也被称为人类骨骼系统关键点检测数据集 Keypoint Detection Dataset (HKD),包含300K高分辨率图像用于关键点检测和中国字幕,以及81,658张用于零镜头识别的图像。大规模的数据集有多个人和不同的姿势。每个人都贴有一个边界框和14个关键点。整个数据集分别分为训练集、验证集、测试A集、测试B集和210K、30K、30K、30K图像。由于其大规模、高分辨率和场景丰富,人工智能挑战者数据集已被广泛用作2D/3D姿态估计网络训练和姿态相关任务的辅助数据集。
J.-H. Wu, H. Zheng, B. Zhao, Y.-X. Li, B.-M. Yan, R. Liang, W.-J. Wang, S.-P. Zhou, G.-S. Lin, and Y.-W. Fu, “AI Challenger: A largescale dataset for going deeper in image understanding,” arXiv preprint arXiv:1711.06475, 2017.
CrowdPose Dataset
CrowdPose Dataset旨在更好地评估拥挤场景中的人体姿态估计方法。通过测量人群指数,从MSCOCO (person subset)、MPII和AI Challenger处收集图像。定义的人群指数是用来评估图像的拥挤程度的。通过人群指数对30K图像进行分析,最后选择20K高质量图像。接下来,14个关键点和全身边界框被注释为大约8万人。培训、验证和测试子集都按比例划分为5:1:4。由于在人群场景中对人的边界框或关键点的检测相对较困难,因此 CrowdPose Dataset 在多人姿态估计社区中仍然具有挑战性。
J.-F. Li, C. Wang, H. Zhu, Y.-H. Mao, H.-S. Fang, and C.-W. Lu, “Crowdpose: Efficient crowded scenes pose estimation and a new benchmark,” in CVPR, 2019.
视频级2D单人数据集
J-HMDB Dataset
J-HMDB数据集[H. Jhuang等人的研究]是联合注释HMDB的缩写,是HMDB51数据库[H. Kuehne等人的研究]的一个子集,包含51个人类行为的5100个片段。J-HMDB数据集包含928个包含21个动作类别的片段。每个动作类包含36-55个片段。每个剪辑包括15-40帧。31,838张图片通过Amazon Mechanical Turk上的2D puppet model[S. Zuffi and M.-J. Black的研究]进行了注释。多达15个可见的身体关键点被标记,连同the scale, viewpoint, segmentation, puppet mask, and puppet flow。训练和测试图像数量的比率大约为7:3。J-HMDB数据集被广泛应用于视频姿态估计和动作识别任务。
H. Jhuang, J. G. S. Zuffi, C. Schmid, and M.-J. Black, “Towards understanding action recognition,” in ICCV, 2013.
H. Kuehne, H.-H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: a large video database for human motion recognition,” in ICCV, 2011.
S. Zuffi and M.-J. Black, “Puppet flow,” International Journal of Computer Vision, vol. 101, no. 3, pp. 437–458, 2013.
Penn Action Dataset
Penn Action Dataset[W.-Y. Zhang等人的研究]是另一个无约束的视频数据集,包含2326个视频涵盖15个动作的片段。训练集和测试集都有1,163个视频片段。该数据集包含各种类内参与者的演员外观、动作执行率、视点、时空分辨率和复杂的自然背景。注释是通过部署在Amazon Mechanical Turk上的半自动视频注释工具进行的。每个人都注释有13个具有2D坐标、可见性和摄像机视点的关键点。
W.-Y. Zhang, M.-L. Zhu, and K.-G. Derpanis, “From actemes to action: A strongly-supervised representation for detailed action understanding,” in ICCV, 2013.
视频级2D多人数据集
PoseTrack Dataset
PoseTrack Dataset[U. Iqbal等人和M. Andriluka等人的研究]是第一个大规模的多人姿态估计和跟踪数据集。它从MPII Multi-Person Pose dataset[M. Andriluka等人的研究]的未标记视频中收集。它有两个版本,即PoseTrack2017和PoseTrack2018。PoseTrack2017包含550个视频,分别分为292、50和208个视频,用于培训、验证和测试。总共23000帧被标注有153615个姿势标签。PoseTrack2018是它的扩展版。它包含593个训练视频,170个验证视频和375个测试视频。对于训练集中的每个视频,中间注释30帧。对于验证集和测试集,会对中间的30帧以及每四帧进行注释。标签包含15个2D关键点、一个唯一的人ID和每个人的头部边界框。跟踪是具有挑战性的,因为视频包含各种姿势外观和尺度变化,以及身体部分遮挡和截断。它已被广泛应用于评估多人姿态估计和跟踪算法的基准。
下表中的相关内容介绍了PoseTrack2017测试集中的代表性方法的性能。多步自上而下方法比自下而上方法具有优越的性能,而后者更有效率。姿态估计任务只依赖于关键点预测的准确性,而姿态跟踪也需要一个可靠的、鲁棒的数据关联方案。随着姿态估计和数据关联的发展,姿态跟踪有潜力以更高的效率实现更好的性能。
U. Iqbal, A. Milan, and J. Gall, “Posetrack: Joint multi-person pose estimation and tracking,” in CVPR, 2017.
M. Andriluka, U. Iqbal, E. Insafutdinov, L. Pishchulin, A. Milan, J. Gall, and B. Schiele, “Posetrack: A benchmark for human pose estimation and tracking,” in CVPR, 2018.
M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in CVPR, 2014.
Human-in-Events (HiEve) Dataset
Human-in-Events (HiEve) Dataset[W.-Y. Lin等人的研究]是一个大型的基于视频的数据集,用于真实事件,特别是针对人群和复杂事件。它包含2D姿势、动作、轨迹跟踪和姿势跟踪。该数据集从9个真实场景中收集,包含49820帧,注释为1302481个边界框、2687个轨迹ID、56643个动作(14个动作类别)和1099357个人2D姿势。2D姿势的标签包含14个关键点,并过滤掉沉重的遮挡和小的边界框(小于500像素)。HiEve数据集是迄今为止最大规模的以人为中心的数据集,它将在人类行为分析的许多任务中非常有用。
W.-Y. Lin, H.-B. Liu, S.-Z. Liu, Y.-X. Y. Li, G.-J. Qi, R. Qian, T. Wang, N. Sebe, N. Xu, and H.-K. Xiong, “Human in events: A large-scale benchmark for human-centric video analysis in complex events,” arXiv preprint arXiv:2005.04490, 2020.
3D单人数据集
Human3.6M
Human3.6M是使用最广泛的多视图单人三维人体姿态基准。该数据集使用4个RGB摄像机、1个飞行时间传感器和10台运动摄像机在4米×3米的室内空间中捕获。它包含了360万个3D人体姿势和15个场景中的相应视频(50FPS),比如讨论、坐在椅子上、拍照等。特别是,三维位置和关键点的角度都是可用的。目前,由于隐私问题,只有7个受试者的数据可用。为了评估,视频通常被每5/64帧向下采样,以消除冗余。方法通常根据两种常用的协议进行评估以进行比较。第一项方案是对5个受试者(S1、S5、S6、S7、S8)进行训练,并对受试者S9和S11进行测试。第二个方案共享相同的训练/测试集,但只评估在正面视图中捕获的图像。
C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 7, pp. 1325–1339, 2014.
HumanEva-I
HumanEva-I是一个从3台60Hz摄像机视角拍摄的单人3D姿势数据集。它包含4个主题来执行6个动作。相关方法通常评估由3个参与者S1、S2、S3执行的3个动作、散步、慢跑和拳击。
L. Sigal, A.-O. Balan, and M.-J. Black, “HumanEva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion,” International Journal of Computer Vision, vol. 87, no. 1-2, p. 4, 2010.
MPI-INF-3DHP
MPI-INF-3DHP拍摄在14相机工作室使用商业无标记运动捕捉设备获取地面真相三维姿势。它包含8个演员,表演8个活动。RGB视频从广泛的角度录制。从所有14台相机中都可以捕捉到超过130万像素的帧。除了一个人的室内视频外,他们还提供MATLAB代码,通过混合分段的前景人类外观来生成一个多人数据集MuCo-3DHP。通过提供的身体部分分割,研究人员还可以使用额外的纹理数据来交换衣服和背景。
D. Mehta, H. Rhodin, D. Casas, P. Fua, O. Sotnychenko, W.-P. Xu, and C. Theobalt, “Monocular 3d human pose estimation in the wild using improved cnn supervision,” in 3DV, 2017.
MoVi
MoVi是一个带有3DMoCap注释的大型单人视频数据集。与Human3.6M和MPIINF-3DHP不同,它包含了更多的受试者(60名女性和30名男性)。每个人执行20个预定义的动作和一个自我选择的动作。与运动捕捉同步的视频从正面和侧面两个角度拍摄的。除了三维姿态注释和照相机参数外,MoVi还提供了通过MoSh++获得的SMPL参数。
S. Ghorbani, K. Mahdaviani, A. Thaler, K. Kording, D. J. Cook, G. Blohm, and N.-F. Troje, “MoVi: A large multipurpose motion and video dataset,” arXiv preprint arXiv:2003.01888, 2020.
SURREAL Dataset
SURREAL Dataset是一个大型的合成数据集,通过在背景图像上渲染纹理SMPL模型。SMPL模型由大量的三维运动捕获数据驱动。然而,身体的纹理是有限的和低分辨率的,这使得渲染的二维图像是不现实的。
G. Varol, J. Romero, X. Martin, N. Mahmood, M.-J. Black, I. Laptev, and C. Schmid, “Learning from synthetic humans,” in CVPR, 2017.
AMASS
AMASS是一个大规模的运动捕获(MoCap)数据集。它通过MoSh++将15个MoCap数据集转换为SMPL参数,将这些数据集统一起来。它包含了超过40个小时的运动数据,跨越300多个受试者,和超过110K个运动。通过监督估计的姿态或运动的合理性,积累被广泛用于建立一个先验的人类运动空间。
N. Mahmood, N. Ghorbani, N.-F. Troje, G. Pons-Moll, and M.-J. Black, “Amass: Archive of motion capture as surface shapes,” in ICCV, 2019.
3D多人数据集
3DPW
3DPW 是一个单视图的多人野外3D人体姿势数据集,包含60个视频序列(24个训练、24个测试和12个验证)的丰富活动,如攀岩、高尔夫、在海滩上放松等。这些视频可以在各种场景中拍摄,如森林、街道、操场、购物中心等。尽管场景很复杂,但他们还是利用IMU获得了准确的三维姿态。特别是,3DPW包含了大量的三维注释,包括二维/三维姿态注释、三维身体扫描和SMPL参数。然而,在一些拥挤的场景中(例如。在街道上),3DPW只提供目标人的标签,忽略了路过的行人。通常,整个数据集用于评估,没有任何fine-tuning。
CMU Panoptic Dataset
CMU Panoptic Dataset是一个大规模的多视图和多人三维姿态数据集。目前,它包含65个序列和150万个3D骨架。他们建造了一个令人印象深刻的360度运动捕捉的穹顶,其中包括480台VGA相机(25FPS)、31台高清相机(30FPS)、10台Kinect2传感器(30FPS)和5个DLP投影仪。特别是,它包含了多人的社会场景。多人三维姿态估计方法通常会提取部分数据进行评估。Zanfir等人,和Jiang等人,选择4个社交活动(争吵、黑手党、最后通牒和披萨)中的2个子序列(从高清摄像头16和30中的9600帧)以进行评估。
H. Joo, H. Liu, L. Tan, L. Gui, B. Nabbe, I. Matthews, T. Kanade, S. Nobuhara, and Y. Sheikh, “Panoptic studio: A massively multiview system for social motion capture,” in ICCV, 2015.
H. Joo, T. Simon, X.-L. Li, H. Liu, L. Tan, L. Gui, S. Banerjee, T.-S. Godisart, B. Nabbe, I. Matthews, T. Kanade, S. Nobuhara, and Y. Sheikh, “Panoptic studio: A massively multiview system for social interaction capture,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
Joint Track Auto (JTA) Dataset
Joint Track Auto (JTA) Dataset是一个用于多人三维姿态评估的逼真的合成数据集。JTA是使用著名的电子游戏《Grand Theft Auto 5》生成的,它包含了512段行人在城市场景中行走的高清视频。每个视频有30秒长,录制为30帧每秒。
====================================================================
有关广泛使用的基准测试的细节,请参见表:
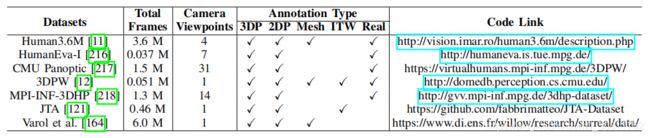
上图描述:被广泛使用的三维姿态估计数据集的细节
此外,我们还在Github2上发布了一个3D姿态数据处理的详细比较和代码工具箱。
https://github.com/Arthur151/SOTA-on-monocular-3D-pose-and-shape-estimation
基准测试的分析 (Analysis of Benchmark)
3D姿态估计和3D网格恢复的基准排行榜见下两个表。由此可见,3D姿态估计方法在获得更好的3D姿态精度方面具有明显的优势在室内单人3D姿势基准上,Human3.6M和HumanEva。3D网格恢复方法更适合于更全面的3D人员分析和可视化。此外,3DPW是一种新的野外多人3D姿态基准。3D网格恢复方法在其上表现出了良好的泛化能力。
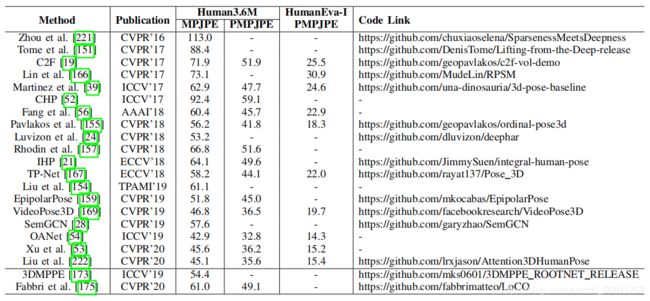
上图描述:在Human3.6M和HumanEva数据集上的三维姿态估计方法的比较
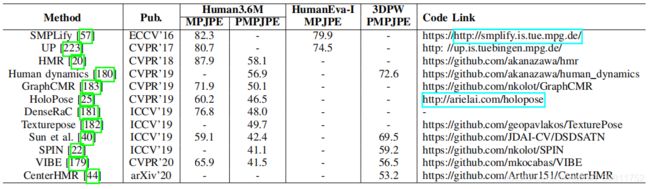
上图描述:在Human3.6M、HumanEva和3DPW数据集上的3D网格恢复方法的比较
姿态空间分析 (Pose Space Analysis)
单目三维姿态估计的主要挑战之一是缺乏足够的训练数据,特别是在多样性方面。因此,我们分析了四个3D基准测试的姿态空间,并将统计结果可视化。详细地,我们首先将所有数据集的3D姿态注释对齐到骨盆,然后执行集群分析。在这里,我们使用k-means聚类算法来平均划分姿态空间。对于可视化,使用UMAP来减少尺寸。统计结果见下图
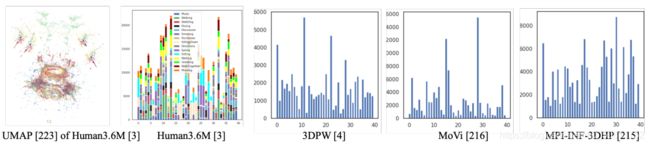
上图描述:针对四个三维姿态基准测试的姿态空间分析:Human3.6M、3DPW、MoVi和MPI-INF-3DHP
姿态空间中不同活动的分布如上图所示,姿态空间中的样品密度非常不均匀。大多数样本被收集在一起。从四个基准测试的聚类结果中也可以得出类似的结论。我们观察到,大多数样本的三维姿势都接近行走或站立姿势。姿态空间的分布是有偏差的,这限制了这些数据集的多样性。
L. McInnes, J. Healy, N. Saul, and L. Grossberger, “Umap: Uniform manifold approximation and projection,” The Journal of Open Source Software, vol. 3, no. 29, p. 861, 2018.
研究结论及未来的发展方向
对复杂的姿势和弯曲的场景的姿势估计
对复杂的姿势和弯曲的场景的姿势估计 (Pose Estimation for Complex Postures and Crowed Scenes)。在日常生活中,人体可能会形成各种复杂或罕见的姿势。这使得一般的模型无法准确地识别这个姿势。特别是,对于现实世界的应用,如体操、跳水和跳高的体育比赛,运动员可能会在很短的时间内表现出极端的姿势。复杂和快速变化的姿势将混淆在一般数据集上训练的现有模型。因此,一方面,需要复杂和罕见姿态的数据集来提高现有模型的性能。另一方面,具有复杂行为和姿势的模型将会有帮助。此外,在现实的场景中,如购物中心、交通监控和体育赛事中,对拥挤人群的姿态估计非常具有挑战性。尽管一些研究[91],[98]曾试图解决2D姿态估计中的人群和遮挡问题,但它们在真实场景中仍然存在低性能的问题。此外,对于3D姿态估计,拥挤场景造成的遮挡会混淆模型,对人体形状和姿态造成不合理的重构。由于复杂场景的上下文包含了人与人与人与对象之间互动的线索,进一步的工作可以利用场景与人的关系来解释看不见或被遮挡的身体部位的原因。
J.-F. Li, C. Wang, H. Zhu, Y.-H. Mao, H.-S. Fang, and C.-W. Lu, “Crowdpose: Efficient crowded scenes pose estimation and a new benchmark,” in CVPR, 2019.
B.-W. Cheng, B. Xiao, J.-D. Wang, H.-H. Shi, T.-S. Huang, and L. Zhang, “Higherhrnet: Scale-aware representation learning for bottomup human pose estimation,” in CVPR, 2020.
用于三维网格恢复的基准测试、协议和工具包
用于三维网格恢复的基准测试、协议和工具包 (Benchmark, Protocol, and Toolkit for 3D Mesh Recovery)。虽然单目三维人网格恢复是一个很有前途的方向,由于没有大规模的三维网格数据集,3D网格恢复的评估通常是执行基于骨骼的3D姿态基准,如评估MPJPE和PA-MPJPE的关节位置误差。由于3D网格包含比3D关键点更多的信息,例如,外观信息,因此这种间接评估是不够的。因此,我们需要大规模的3D人形网格数据集和协议来进行综合评估。此外,随着技术的成熟,工业应用程序需要易于操作的工具包,特别是在云服务器和手持设备上的轻量级实现。一些公司或社区,如谷歌、微软和张流,已经开发了工具包或应用程序编程接口用于2D姿态估计的。在未来,随着应用需求的增加,我们相信2D和3D姿态估计的更成熟和通用的工具箱将进一步促进先进算法的实现。
[Online]. Available: https://developers.google.com/ml-kit/vision/pose-detection.
[Online]. Available: https://software.intel.com/content/www/us/en/develop/articles/human-pose-estimation-demo-microsoft-windows.html.
[Online]. Available: https://www.tensorflow.org/lite/examples/pose_estimation/overview.
现实的身体有表情的脸,手,头发和衣服
现实的身体有表情的脸,手,头发和衣服 (Realistic Bodies with Expressive Faces, Hands, Hair, and Clothes)。为了更好地理解场景中的人类,我们需要更丰富的线索,如面部表情、情感状态、手势和衣服来描述3D范式中的一个人。考虑到近年来单个身体部位(如身体、手和面部)的3D姿势恢复得到了很好的发展,继续对头发、衣服和表现状态提供逼真细节的真实3D全身恢复是一种自然的趋势。这是一个全新的研究领域,而只有少数人在研究[如下引用],尝试将身体、手和脸结合在一个统一的表示框架中。这项任务的主要挑战在于缺乏包含所有详细信息的配对3D姿态数据集,以及不同身体部位之间的尺度差异。虽然有许多可用的单独的2D/3D身体/脸、手、衣服/头发数据集,但很难同时捕捉到真实的全身运动。因此,进一步的工作可以开发弱/无监督的方法来利用所有的单部分数据来进行有效的学习。此外,随着计算机图形学的发展,逼真的合成数据可以进一步改进研究。
D.-L. Xiang, H. Joo, and Y. Sheikh, “Monocular total capture: Posing face, body, and hands in the wild,” in CVPR, 2019.
G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A.-A. Osman, D. Tzionas, and M.-J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” in CVPR, 2019.
多人3D姿态估计
多人3D姿态估计 (Multi-person 3D Pose Estimation)。虽然近年来对多人场景的2D姿态估计得到了广泛的研究,但对3D案例的研究才刚刚开始。多人3D姿态估计是一个非常有前途的方向,并且接近于实际的应用场景。大多数现有的性能良好的方法都是多阶段的框架,它们严重依赖于2D的人类检测。单镜头的方法有潜力获得更有吸引力的效率。然而,当推理这些姿势,特别是3D形式中的多个人的形状时,这些问题将比2D关键点估计要复杂得多。例如,人-人或人-场景信息的交互式信息是确定模糊姿势的一个重要线索,而它通常被大多数现有的方法忽略了。因此,在2D图像中利用更全面的交互式信息将会对于估计更合理的3D姿势很重要。
与3D世界和其他代理的交互
与3D世界和其他代理的交互 (Interaction with 3D World and Other Agents)。我们生活在一个动态的3D世界中,人和对象与环境交互。建立一个交互感知系统,可以从单目图像中捕获和理解这些在三维世界中体现的实体代理,这将是很有趣的和很有前途的。尽管有一些工作集中在三维手对象交互[引用1:B. Tekin等人和L. Huang等人的研究],以及3D主体与一些特定对象[引用2:M. Hassan等人和J.-Y. Zhang等人的研究]的交互,但如何在不控制的野外场景中处理整体三维场景理解仍然具有挑战性。一方面,从单目图像中对一般物体的三维恢复还没有得到很好的解决。对一般物体的更详细的统计模型将带来显著的推动。另一方面,如何有效地表示人、对象和场景之间的关系,而不是建模独立的构图,这将极大地影响推理结果。此外,随着三维场景捕捉技术的发展,大规模的真实三维数据集将会进行变革,以促进算法的发展。
B. Tekin, F. Bogo, and M. Pollefeys, “H+o: Unified egocentric recognition of 3d hand-object poses and interactions,” in CVPR, 2019.
L. Huang, J. Tan, J. Meng, J. Liu, and J. Yuan, “Hot-net: Non-autoregressive transformer for 3d hand-object pose estimation,” in ACM MM, 2020.
M. Hassan, V. Choutas, D. Tzionas, and M.-J. Black, “Resolving 3d human pose ambiguities with 3d scene constraints,” in ICCV, 2019.
J.-Y. Zhang, S. Pepose, H. Joo, D. Ramanan, J. Malik, and A. Kanazawa, “Perceiving 3d human-object spatial arrangements from a single image in the wild,” in ECCV, 2020.
具有情感、语音和交流的虚拟数字人类生成
具有情感、语音和交流的虚拟数字人类生成 (Virtual Digital Human Generation with Emotion, Speech, and Communication)。虚拟数字人是指具有数字形象特征的虚拟人。它具有外表、性别和个性等特殊特征,以及用语言、面部表情和身体动作来表达和交流的能力。该技术在电影制作、虚拟主机、智能客户服务、虚拟教师等行业引起了人们的广泛关注。2D/3D人性的建模和生成是虚拟数字人类产品的核心。大多数现有的产品依赖于计算机图形技术和在操作上昂贵而复杂的标记动作捕捉设备。随着市场需求的急剧增长,虚拟数字人类正在朝着更智能、方便和多样化的产品形式迈进。未来,随着单目3D人体恢复技术的发展,没有专业传感设备的无标记运动捕捉有望实现简单、易用、低价格。此外,虽然目前的数字人已经实现了面部表情和口腔运动的智能合成,但身体其他部位的运动只支持记录和广播。将会有更多的集成和自动化的技术来实现逼真的2D/3D全身模型,包括身体运动、面部表情、手指手势、声音等。此外,多模态人机交互的发展还将促进与数字人的自然交流和互动。
后面再继续更新。
====================================================================
总之,单目人体姿态估计是一项具有挑战性和实际意义的任务。深度学习对位姿估计的发展是很有前途和令人兴奋的。在未来,人体姿态估计的研究和应用都包含了许多机遇和挑战。单目人体姿态估计的未来将在很大程度上取决于算法、数据和应用场景的实际重点和进展。