PyTorch深度学习快速入门学习笔记
此文章仅为本人的学习笔记,记录学习过程。
侵权删。
视频地址:https://www.bilibili.com/video/BV1hE411t7RN?share_source=copy_web
P1,P2,P3.PyTorch环境的配置及安装
1.安装 Anaconda
网址: www.anaconda.com
有序的管理环境
以后,你有可能会遇到不同的环境需要不同的版本的环境。比如一个项目需要pytorch 0.4 ,而另一个项目要用到pytorch 1.0 。不肯能运行一个项目就更换一个环境,那就太费事了。
所以,Anaconda集成的conda包就可以解决这个问题,它可以分别创造两个屋子,相互隔离。一个房子安装 0.4版本,一个房子安装1.0版本。需要哪个版本就去哪一个屋子工作。
1.首先使用conda指令创建一个屋子,叫做 pytorch(可自定义);
指令如下:
conda create -n pytorch python=3.6
其中,conda 是指调用conda包,create 是创建的意思, -n 是指后面是屋子的名字, pytorch是屋子的名字(可自定义),python=3.6 是指创建的屋子,是python3.6版本。
2.之后激活屋子
指令如下:
conda active pytorch
其中 pytorch指的是你要进入的环境。

2.Pytorch安装
https://blog.csdn.net/qq_41273406/article/details/118311409
P4.python中两大法宝函数
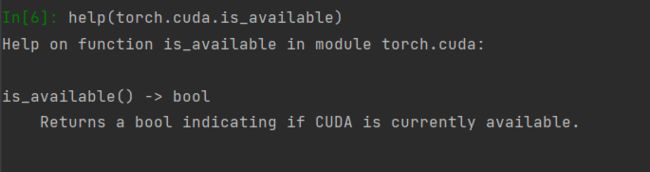
dir() # 打开,看看其中有哪些内容
help() # 说明书,如何使用这个工具

P5. Pytorch数据加载
from torch.utils.data import Dataset
import cv2
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir) #将两个地址加起来
self.img_path = os.listdir(self.path) #
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.path, img_name)
img = Image.open(img_item_path)
lable = self.label_dir
return img, lable
def __len__(self):
return len(self.img_path)
root_dir = "data/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
P7. Tensorboard的使用1
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# writer.add_image() #图像
# writer.add_scalar() #
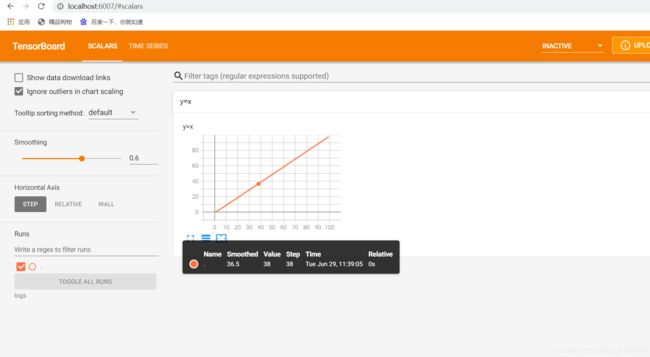
for i in range(100):
writer.add_scalar("y=x", i, i)
writer.add_scalar("y=2x", 2*i, i)
writer.close()
运行完会产生logs文件夹


可以修改端口:默认端口:6006
![]()

如果没有数据可以换一个浏览器,我在Google上可以看到。
P8. Tensorboard的使用2
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/0013035.jpg"#图片路径
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL) #将数据转换成numpy类型
writer.add_image("名字", img_array, 1, dataformats='HWC')#dataformats='HWC'是选择通道数, 1是步长
writer.close()
刷新网址

P9.Transforms的使用
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
# python的用法 ---> tensor 数据类型
# 通过 transforms.ToTensor 去看两个问题
#1.transforms该如何使用
#2.为什么我们需要Tensor数据类型
# img_path = r"E:\PyCharm_Demo\learn_pytorch\data\train\bees_image\16838648_415acd9e3f.jpg" #绝对路径 r 取消转义
img_path = "data/train/bees_image/16838648_415acd9e3f.jpg"#相对路径
img = Image.open(img_path)
#1.transforms该如何使用
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
# 2.
writer = SummaryWriter("logs")
writer.add_image("Tensor_img", tensor_img)
writer.close()


P12.常见的Transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("images/img.png")
print(img)
# ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
#Normalize的使用(归一化)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) #提供标准差
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
writer.close()

from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("images/img.png")
print(img)
# ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
#Normalize的使用(归一化)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) #提供标准差
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
print(img.size)
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
#Compose - resize -2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize2", img_resize_2, 1)
#RandomCrop
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
总结:

P14. torchvision中的数据集使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
# print(test_set[0])
#
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])
writer = SummaryWriter("P14" )
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
假如下载速度太慢,可以用迅雷下载,下载网址如下图

从上图跳转到下图,向上翻可以找到url,这个就是网址。
下载好后。
新创一个如下图的文件夹,将下载的压缩包直接复制到该文件下运行即可。

提取压缩包:

它会自动减压文件,如下图。
P15. DataLoader 的使用
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=dataset_transform )
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# dataset:数据来源 batch_size:一组的数量, shuffle:是否打乱顺序取值 drop_last:是否删除最后数量不够的一组
#测试数据集中的第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloder")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
# writer.add_images("test_data", imgs, step)
writer.add_images("test_data_drop_last", imgs, step)
step = step + 1
writer.close()

P16.神经网络的基本骨架-nn.Module的使用
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):#定义卷积网络
output = input + 1
return output
module = MyModule()
x = torch.tensor(1.0)
output = module(x)
print(output) # tensor(2.)
P17. 卷积操作
计算规则:

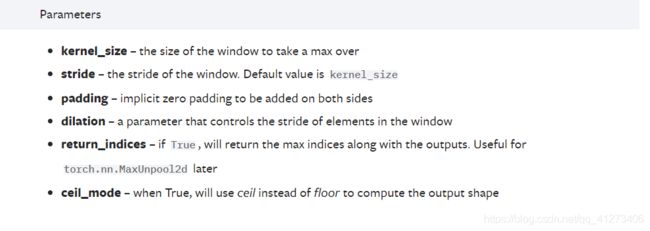
参数设置:

import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape) #torch.Size([5, 5])
print(kernel.shape) #torch.Size([3, 3])
# 尺寸变换
input = torch.reshape(input, (1, 1, 5, 5)) #改成卷积可以接受的形式
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape) #torch.Size([1, 1, 5, 5])
print(kernel.shape) #torch.Size([1, 1, 3, 3])
output = F.conv2d(input, kernel, stride=1) #stride:步长
print(output)
output2 = F.conv2d(input, kernel, stride=2) #stride:步长
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1) #padding:补零的长度
print(output3)
P18. 卷积层

import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloder = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
module = MyModule()
print(module)
writer = SummaryWriter("P18_logs")
step = 0
for data in dataloder:
imgs, target = data
output = module(imgs)
print(imgs.shape) #torch.Size([64, 3, 32, 32])
print(output.shape) #torch.Size([64, 6, 30, 30])
writer.add_images("input", imgs, step)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1

P19.神经网络—最大池化使用


import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape) #torch.Size([1, 1, 5, 5])
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
module = MyModule()
output = module(input)
print(output)

import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape) #torch.Size([1, 1, 5, 5])
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloder = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
module = MyModule()
output = module(input)
print(output)
writer = SummaryWriter("P19_logs")
step = 0
for data in dataloder:
imgs, targets = data
output = module(imgs)
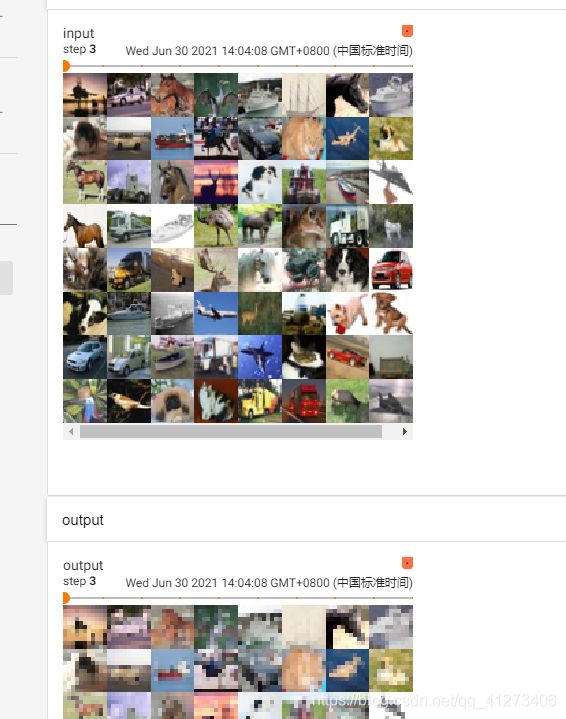
writer.add_images("input", imgs, step)
writer.add_images("output", output, step)
step = step + 1
writer.close()
P20.神经网络—非线性激活
Rule
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
intput = torch.reshape(input, (-1, 1, 2, 2))
print(intput.shape) #torch.Size([1, 1, 2, 2])
class Module(nn.Module):
def __init__(self):
super(Module, self).__init__()
self.relu1 = ReLU()
def forward(self,input):
output = self.relu1(input)
return output
module = Module()
print(intput)
output = module(intput)
print(output)

sigmoid
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloder = DataLoader(dataset, batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
module = Module()
writer = SummaryWriter("P20_sigmoid")
step = 0
for data in dataloder:
imgs, targets = data
output = module(imgs)
writer.add_images("input", imgs, global_step=step)
writer.add_images("output", output, global_step=step)
step = step + 1
writer.close()

P21. 神经网络—线性层及其他层
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
module = Module()
for data in dataloader:
imgs, targets = data
print(imgs.shape) # torch.Size([64, 3, 32, 32])
output = torch.reshape(imgs, (1, 1, 1, -1))
print(output.shape) # torch.Size([1, 1, 1, 196608])
output1 = module(output)
print(output1.shape) # torch.Size([1, 1, 1, 10])
output = torch.flatten(imgs)
print(output.shape) # torch.Size([196608])
output = module(output)
print(output.shape) #torch.Size([10])
P22. 神经网络—搭建小实战和Sequential的使用
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)#
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)#
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.Linear2 = Linear(64, 10)
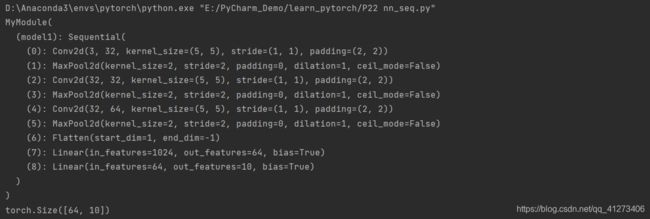
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.Linear2(x)
x = self.model1(x)
return x
module = MyModule()
print(module)
input = torch.ones(64, 3, 32, 32)
output = module(input)
print(output.shape)
writer = SummaryWriter("P22_logs")
writer.add_graph(module, input)
writer.close()
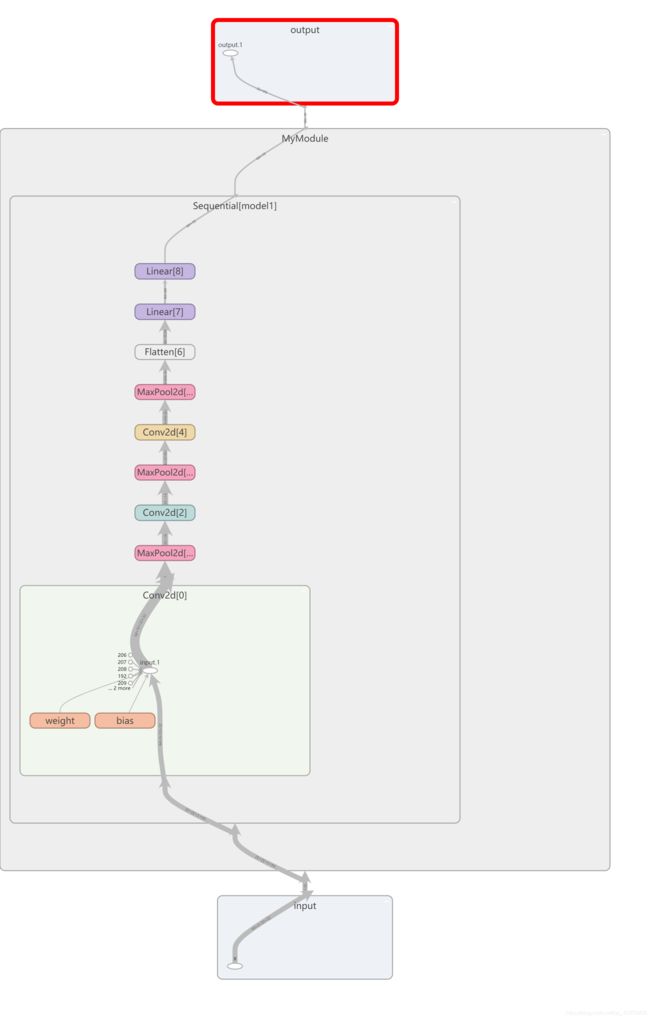
P23.损失函数与反向传播
不同的损失函数的用法
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
res = loss(inputs, targets)
print(res) #tensor(0.6667)
loss_mse = nn.MSELoss()
res_mse = loss_mse(inputs, targets) # (0+0+2^2)/3
print(res_mse) # tensor(1.3333)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, [1, 3])
loss_cross = nn.CrossEntropyLoss()
res_cross = loss_cross(x, y)
print(res_cross) #tensor(1.1019)
损失函数在神经网络中的运用
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
module = MyModule()
for data in dataloader:
imgs, targets = data
outputs = module(imgs)
# print(outputs)
# print(targets)
res_loss = loss(outputs, targets)
# print(res_loss)
res_loss.backward() #反向传播
P23.优化器
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
module = MyModule()
optim = torch.optim.SGD(module.parameters(), lr=0.001)
for epoch in range(10):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = module(imgs)
res_loss = loss(outputs, targets)
optim.zero_grad() #重置
res_loss.backward()
optim.step() #调优
running_loss = running_loss + res_loss
print(running_loss)

P25.现有网络模型的使用及修改
import torchvision
from torch import nn
train_data = torchvision.datasets.CIFAR10("dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
vgg16_true.add_module('add_linear', nn.Linear(1000, 10)) #在原有的模型上再加一层
print("-------------------------------------")
print(vgg16_true)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10)) #在classifier的模型里再加一层
print("-------------------------------------")
print(vgg16_true)
print("+++++++++++++++++++++++++++++++++++++++++")
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)#直接修改模型
print("+++++++++++++++++++++++++++++++++++++++++")
print(vgg16_false)
P26.网络模型的保存和读取
保存
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)#未经过训练的
### 保存方式1 : 模型结构+模型参数
torch.save(vgg16, "models/vgg16_model1.pth")
### 保存方式2 : 模型参数(官方推荐)
torch.save(vgg16.state_dict(), "models/vgg16_model2.pth")
# 陷阱
class Mymodule(nn.Module):
def __init__(self):
super(Mymodule, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
module = Mymodule()
torch.save(module, "models/model1.pth")
读取
import torch
import torchvision
### 方式1---》加载 保存方式1
from torch import nn
model1 = torch.load("models/vgg16_model1.pth")
# print(model1)
### 方式2---》加载 保存方式2
model2 = torch.load("models/vgg16_model2.pth")
# print(model2)
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(model2)
print(vgg16)
#陷阱1: 直接读取会报错,因为当前没有自定义个那个类
# 解决方法:将这个;类写上
# class Mymodule(nn.Module):
# def __init__(self):
# super(Mymodule, self).__init__()
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
#
# def forward(self, x):
# x = self.conv1(x)
# return x
# 解决方法2 引入
from P26_model_save import *
model = torch.load("models/model1.pth")
print(model)
P27.完整的模型训练套路
# 1.准备数据集
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from P27_model import *
train_data = torchvision.datasets.CIFAR10("dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("训练数据集的长度为:{}".format(test_data_size))
#2. 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
# class Mymodule(nn.Module):
# def __init__(self):
# super(Mymodule, self).__init__()
# self.model = nn.Sequential(
# nn.Conv2d(3, 32, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 32, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 64, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Flatten(),
# nn.Linear(64*4*4, 64),
# nn.Linear(64, 10)
#
#
# )
#
# def forward(self, x):
# x = self.model(x)
# return x
### model另外写再引用 网络模型
module = Mymodule()
#3. 损失函数
loss_fn = nn.CrossEntropyLoss()
#4. 优化器
### learning_rate = 0.01
### 1e-2 = 1* 10^(-2) =0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(module.parameters(), lr=learning_rate)
#5. 设置训练网络的一些参数
## 记录训练的次数
total_train_step = 0
### 记录测试的次数
total_test_step = 0
### 记录训练的轮数
epoch = 10
### 添加tensorboard
writer = SummaryWriter("P27_logs")
for i in range(epoch):
print("-----------第{}轮训练开始-----------".format(i+1))
# 6.训练步骤开始
module.train()
for data in train_dataloader:
imgs, targets = data
output = module(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {}, loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 7.测试步骤开始
module.eval()
total_test_loss = 0
### 整体正确的个数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = module(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(module,"models/model_{}.pth".format(i))
# torch.save(module.state_dict(), "models/model_{}.pth".format(i))
print("模型已保存")
writer.close()
P30.利用GPU训练1
# 1.准备数据集
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
train_data = torchvision.datasets.CIFAR10("dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("训练数据集的长度为:{}".format(test_data_size))
#2. 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Mymodule(nn.Module):
def __init__(self):
super(Mymodule, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
module = Mymodule()
##### 使用GPU
if torch.cuda.is_available():
module = module.cuda()
#3. 损失函数
loss_fn = nn.CrossEntropyLoss()
#### 使用GPU
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
#4. 优化器
### learning_rate = 0.01
### 1e-2 = 1* 10^(-2) =0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(module.parameters(), lr=learning_rate)
#5. 设置训练网络的一些参数
## 记录训练的次数
total_train_step = 0
### 记录测试的次数
total_test_step = 0
### 记录训练的轮数
epoch = 10
### 添加tensorboard
writer = SummaryWriter("P27_logs")
start_time = time.time()
for i in range(epoch):
print("-----------第{}轮训练开始-----------".format(i+1))
# 6.训练步骤开始
module.train()
for data in train_dataloader:
imgs, targets = data
#### 使用GPU
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = module(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print("运行时间{}".format(end_time-start_time))
print("训练次数: {}, loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 7.测试步骤开始
module.eval()
total_test_loss = 0
### 整体正确的个数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
#### 使用GPU
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = module(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(module,"models/model_{}.pth".format(i))
# torch.save(module.state_dict(), "models/model_{}.pth".format(i))
print("模型已保存")
writer.close()
P31.利用GPU训练2
# 1.准备数据集
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data = torchvision.datasets.CIFAR10("dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("训练数据集的长度为:{}".format(test_data_size))
#2. 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Mymodule(nn.Module):
def __init__(self):
super(Mymodule, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
module = Mymodule()
##### 使用GPU
module = module.to(device)
#3. 损失函数
loss_fn = nn.CrossEntropyLoss()
#### 使用GPU
loss_fn = loss_fn.to(device)
#4. 优化器
### learning_rate = 0.01
### 1e-2 = 1* 10^(-2) =0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(module.parameters(), lr=learning_rate)
#5. 设置训练网络的一些参数
## 记录训练的次数
total_train_step = 0
### 记录测试的次数
total_test_step = 0
### 记录训练的轮数
epoch = 10
### 添加tensorboard
writer = SummaryWriter("P27_logs")
start_time = time.time()
for i in range(epoch):
print("-----------第{}轮训练开始-----------".format(i+1))
# 6.训练步骤开始
module.train()
for data in train_dataloader:
imgs, targets = data
#### 使用GPU
imgs = imgs.to(device)
targets = targets.to(device)
output = module(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print("运行时间{}".format(end_time-start_time))
print("训练次数: {}, loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 7.测试步骤开始
module.eval()
total_test_loss = 0
### 整体正确的个数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
#### 使用GPU
imgs = imgs.to(device)
targets = targets.to(device)
outputs = module(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(module,"models/model_{}.pth".format(i))
# torch.save(module.state_dict(), "models/model_{}.pth".format(i))
print("模型已保存")
writer.close()
P32.完整的模型验证套路
import torch
import torchvision
from PIL import Image
from torch import nn
# image_path ="E:\PyCharm_Demo\learn_pytorch\images\dog.png"
image_path =r"E:\PyCharm_Demo\learn_pytorch\images\airplane.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')#转换通道数
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Mymodule(nn.Module):
def __init__(self):
super(Mymodule, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model1 = torch.load("E:\PyCharm_Demo\learn_pytorch\models\model_9.pth", map_location=torch.device('cpu'))#模型是在cuda上训练的,现在用cpu运行 需要更改map_location参数
print(model1)
image = torch.reshape(image, (1, 3, 32, 32))
model1.eval()
with torch.no_grad():
output = model1(image)
print(output)
print(output.argmax(1))