Darknet框架下如何利用自己的数据集训练YOLOv4模型
第一步:安装darknet
参考:Windows搭建Darknet框架环境-Yolov4-GPU_乐观的lishan的博客-CSDN博客
darknet的源码说明中也已经简单介绍了如何利用数据集训练网络
第二步:制作VOC格式数据集
网上搜集自己需要的数据集,或自己拍摄相关视频,然后提取帧图片
大部分的网络公开数据集已经附带有标注好的xml文件
推荐交通领域公开数据集(包含无人驾驶、交通标志、车辆检测三大类)链接如下:【智能交通数据集】一文道尽智能交通领域数据集合集(一) - 飞桨AI Studio - 人工智能学习与实训社区
也有一部分数据集没有xml格式的标注文件,此时需要使用其他方法将其转换为xml文件
例如BITVehicle数据集提供的就是一个mat格式的标注文件,需要编写程序读取数据并生成对应图片的xml文件
对于没有标签的数据集或者是自己拍摄的数据集,需要使用labelimg工具进行标定,生成xml文件,使用pip安装命令即可安装
pip install labelimg打开labelimg命令
labelimg新建一个文件夹,参照VOC数据集的目录分布建立其他子文件夹(此时文件夹内还没有文件)

-
将数据集所有图片放到JPEGImages文件夹
-
将所有图片对应的xml标注文件放到Annotations
-
生成txt相关文件放在Main文件夹下(利用gen_files.py文件)
文件在VOCdevkit同级目录下运行,文件来源于博客:Yolov4训练自己的数据集_sinat_28371057的博客-CSDN博客_yolov4训练自己的数据集
#!/usr/bin/env python # -*- coding: utf-8 -*- # file: gen_files.py # 生成训练所需txt文件 import os import random root_path = './VOCdevkit/VOC2007' xmlfilepath = root_path + '/Annotations' txtsavepath = root_path + '/ImageSets/Main' if not os.path.exists(root_path): print("cannot find such directory: " + root_path) exit() if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) trainval_percent = 0.9 # 训练验证集占比 train_percent = 0.8 # 训练集占比 total_xml = os.listdir(xmlfilepath) num = len(total_xml) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(range(num), tv) train = random.sample(trainval, tr) print("train and val size:", tv) print("train size:", tr) ftrainval = open(txtsavepath + '/trainval.txt', 'w') ftest = open(txtsavepath + '/test.txt', 'w') ftrain = open(txtsavepath + '/train.txt', 'w') fval = open(txtsavepath + '/val.txt', 'w') for i in range(num): name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close() -
生成最终的txt文件和label文件夹(利用voc_label.py文件)
文件在VOCdevkit同级目录下运行,文件来源于darknet下的scripts文件夹
#!/usr/bin/env python # -*- coding: utf-8 -*- # file: voc_label.py # 生成最终的txt文件和label文件夹 import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join import platform sets = [('2007', 'train'), ('2007', 'val'), ('2007', 'test')] classes = ["Bus", "Microbus", "Minivan", "Sedan", "SUV", "Truck"] # 修改为自己数据集的类别名称 def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return x, y, w, h def convert_annotation(year, image_id): in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id)) out_file = open('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): # difficult = obj.find('difficult').text cls = obj.find('name').text # if cls not in classes or int(difficult) == 1: # continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for year, image_set in sets: if not os.path.exists('VOCdevkit/VOC%s/labels/' % year): os.makedirs('VOCdevkit/VOC%s/labels/' % year) image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split() list_file = open('%s_%s.txt' % (year, image_set), 'w') for image_id in image_ids: list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id)) print("Processing image: %s" % image_id) convert_annotation(year, image_id) list_file.close() # if platform.system().lower() == 'windows': # os.system("type 2007_train.txt 2007_val.txt > train.txt") # os.system("type 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt") # elif platform.system().lower() == 'linux': # os.system("cat 2007_train.txt 2007_val.txt > train.txt") # os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt") print("done") -
复制2007_test.txt、2007_train.txt、2007_val.txt到data文件夹,搜索并复制darknet下的voc.data、voc.names到data文件夹
-
训练yolov4时,搜索并复制darknet下的yolov4.conv.137、yolov4-custom.cfg到data文件夹,若找不到,从网上下载
训练yolov4-tiny时,搜索并复制darknet下的yolov4-tiny.conv.29、yolov4-tiny-custom.cfg到data文件夹,若找不到,从网上下载
-
for
yolov4.cfg,yolov4-custom.cfg(162 MB): yolov4.conv.137 (Google drive mirror yolov4.conv.137 ) -
for
yolov4-tiny.cfg,yolov4-tiny-3l.cfg,yolov4-tiny-custom.cfg(19 MB): yolov4-tiny.conv.29
备注:关于文件放置的路径可以自己决定,只要知道对应的文件代表的意义,在后续的配置过程中,指定正确的路径即可
-
第三步:配置网络结构和训练参数
-
xxx..names文件
训练类别名称指定:voc.names
替换为自己数据集的类别名称,一行一个,不要出现空行
-
xxx.data文件
数据路径文件指定:voc.data
classes:指定类别个数
train:指定训练数据集图片路径读取txt
valid:指定验证数据集图片路径读取txt
test:指定测试数据集图片路径读取txt
names:指定了类别名称读取文件
backup:指定训练权重保存文件路径
例如:
classes= 6 train = D:\DataSet\data/2007_train.txt valid = D:\DataSet\data/2007_val.txt test = D:\DataSet\data/2007_test.txt names = D:\DataSet\data/voc.names backup = D:\DataSet\data/backup -
yoloxxx.cfg
训练网络参数配置:yolov4-tiny-custom.cfg
注意主要修改的几处:
[net]:
batch:批处理大小,显卡性能较强时此值可以设置高一点, 否则使用默认值,或适当降低,官方建议设置为64
subdivisions:每一批次分成多少等份,官方建议改为16
max_batches:最大的批次数(迭代回合数),官方建议至少classes*2000,但不少于训练图像的数量且不少于6000,如果您训练 3 个类,且训练图像数目不少于6000,则此值可以设置为6000
steps:每一次迭代回合的训练步数,官方建议设置为max_batches的80%到90% ,例如max_batches为10000,则step为8000,9000
width,height:网络输入图片的大小,官方建议设置为416,416,也可以设置为其他值,但必须是32的倍数 -
[yolo]:
classes:类别数
anchors:预选框大小
备注:yolov4共有3个yolo层,需要改三处,yolov4-tiny共有2个yolo层,需要改两处
[convolutional]
filters:每一yolo层之上对应有一个convolutional(该层最后一个convolutional,紧挨着yolo层),此值设置为:(classes + 5)x3 ,假如类别数为6,则该值为33
备注:yolov4共有3个yolo层,对应convolutional需要改三处,yolov4-tiny共有2个yolo层,对应convolutional需要改两处
当使用了 [Gaussian_yolo] 层时(即Gaussian_yolov3_BDD.cfg文件), 将对应的filters改为(classes + 9)x3 ,假如类别数为6,则该值为45
-
yoloxxx.conv.xx
yolov4的预训练权重文件:yolov4.conv.137
yolov4-tiny的预训练权重文件:yolov4-tiny.conv.29
备注:
如果想基于其他的网络模型(例如DenseNet、ResNet)训练训练Yolo,需要下载对应的预训练权重,参考链接darknet/partial.cmd at master · AlexeyAB/darknet · GitHub
如果想自己训练自己的模型,可以不指定预训练权重文件,初始将使用随机化的初始权重 -
创建backup文件夹
指定网络训练权重保存位置
第四步:训练
1、修改先验框
使用K-means算法计算最优先验框大小
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416命令中data/obj.data为指定的xxx.data文件路径,数字9表示类别数目,例如:
D:\darknet\build\darknet\x64\darknet.exe detector calc_anchors data/voc.data -num_of_clusters 6 -width 416 -height 416运行后会生成anchors.txt文件,复制文件内容,修改yoloxxx.cfg文件中的[yolo]下的anchors

2、启动训练命令
darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137命令中data/obj.data为指定的xxx.data文件路径,yolo-obj.cfg为指定的网络结构文件参数,yolov4.conv.137为预训练权重文件,例如:
D:\darknet\build\darknet\x64\darknet.exe detector train data/voc.data data/yolov4-tiny-custom.cfg data/yolov4-tiny.conv.29 -map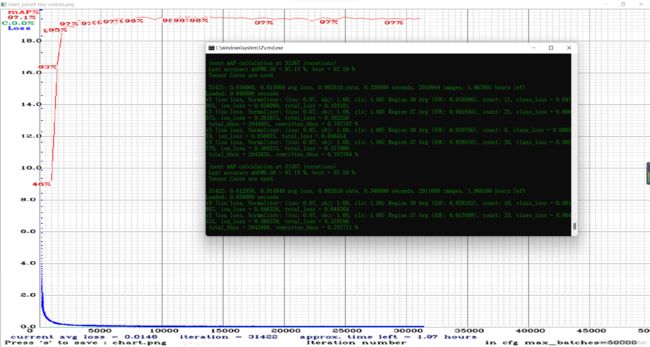
备注:
-
如果在训练期间您看到(loss) 字段的avg值为nan ,则训练出错,但如果在其他行中看到nan,则训练仍然进行得很顺利。
-
如果发生了Out of memory错误,则应该增加subdivisions的值,例如设置为16,32或者64更高
3、中断后继续训练
情景一:手动中断训练,鼠标点击正在运行的控制台窗口即可(因为长时间的连续训练可能损伤机器,可以手动暂停让GPU歇一会儿),再次点击控制台窗口即可继续运行
情景二:因为意外断电等情况,训练被中止,可以查看backup文件夹内的最新权重文件,权重文件每10000次迭代保存一次,然后使用下面命令接着训练
darknet.exe detector train data/obj.data cfg/yolo-obj.cfg backup/yolo-obj.weights例如:
D:\darknet\build\darknet\x64\darknet.exe detector train data/voc.data data/yolov4-tiny-custom.cfg data/backup/yolov4-tiny-custom_10000.weights -map4、判断是否结束训练
迭代次数:通常每个类至少需要迭代训练2000次,同时迭代总数不能少于训练集图片数量,并且训练总数不少于6000次
在训练中,你会在控制台窗口中看到以下训练信息:
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 8
9002: 0.211667, 0.60730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds9002表示:当前迭代次数,即训练到第几个batch
0.60730 avg表示:平均误差
当发现平均误差长时间不再降低时,可以提前停止训练,最终的平均误差可能停留在0.05(对于很小的模型或容易的数据集)到3.0(对于较大的模型或者困难的数据集)之间。
当在训练命令后加上了 -map参数时,可以看到mAP曲线的实时显示图片,其最大的精度为18.50%。
当停止训练时,可以在backup文件中选择一个效果最好的权重文件,例如你在9000个回合后结束了训练,但是最优的训练结果可能是前面训练的权重,训练的权重有可能会发生过拟合。
过拟合是指随着迭代训练次数的增加,你的训练结果在训练集上表现效果很好,但是在其他数据集上却检测不到目标,你应该选择一个在早停点处的权重文件
挑选权重文件原则:选择一个mAP或IoU更高的权重
使用以下命令可以检测指定权重文件的mAP
darknet.exe detector map data/obj.data cfg/yolo-obj.cfg backup/yolo-obj.weights5、训练过程中查看最新的网络模型检测效果
训练时间较长,若希望在训练过程中看一下现在训练的网络检测效果如何,可以准备视频或图片文件,另开一个cmd窗口检测
可以新建一个bat批处理脚本文件并运行检测
根据对应要求,在bat文件中修改为正确的路径
:darknet.exe文件路径
set fdarknet=D:\darknet\build\darknet\x64
:.data文件路径
set fdata=D:\DataSet\data\voc.data
:.cfg文件路径
set fcfg=D:\DataSet\data\yolov4-tiny-custom.cfg
:backup文件夹的xx_best.weights文件路径
set fweights=D:\DataSet\data\backup\yolov4-tiny-custom_best.weights
:.mp4文件路径
set fvideo=D:\Users\lishan\Desktop\video\test.mp4
%fdarknet%/darknet.exe detector map %fdata% %fcfg% %fweights%
%fdarknet%/darknet.exe detector demo %fdata% %fcfg% %fweights% -ext_output %fvideo%
pause修改为.bat文件,双击文件运行即可
备注:此方法的前提是.data文件中的所有文件路径均为绝对路径
6、训练结束后测试
训练结束时,会自动统计训练结果的MAP

也可以使用以下命令手动检测MAP
darknet.exe detector map data/obj.data cfg/yolo-obj.cfg backup/yolo-obj.weights例如:
D:\darknet\build\darknet\x64/darknet.exe detector map D:\DataSet\data\voc.data D:\DataSet\data\yolov4-tiny-custom.cfg D:\DataSet\data\backup\yolov4-tiny-custom_best.weights训练结束后,使用以下命令测试检测效果
darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights例如:
D:\darknet\build\darknet\x64\darknet.exe detector test D:\DataSet\data/voc.data D:\DataSet\data/yolov4-tiny-custom.cfg D:\DataSet\data/backup/yolov4-tiny-custom_best.weights备注:测试时,将xx.cfg文件中的bach和subdivisions均改为1
提示输入检测图片路径:Enter Image Path:
例如输入:D:\DataSet\VOCdevkit\VOC2007\JPEGImages\vehicle_0000162.jpg
检测效果如下:

7、如何提高检测效果
训练前
-
在xx.cfg文件中设置random=1,它将通过针对不同分辨率训练 Yolo 来提高精度
-
增加.cfg-file 中的网络分辨率(height=608,width=608或任何 32 的倍数) - 它会提高精度
-
检查您要检测的每个对象是否在您的数据集中被强制标记 ,数据集中的任何一个对象都不应该没有标签
https : //github.com/AlexeyAB/Yolo_mark
-
在训练命令结束时使用-show_imgs标志运行训练,您是否看到正确的对象边界框(在窗口或文件中aug_...jpg)如果不是 - 您的训练数据集是错误的。
-
对于您要检测的每个对象 -,训练数据集中必须至少有 1 个类似的对象,它们大致相同:形状、对象侧面、相对大小、旋转角度、倾斜度、照明度。非常理想的是,您的训练数据集包含具有不同对象的图像:比例、旋转、照明、来自不同侧面、不同背景的图像 - 您最好为每个类别拥有 2000 个或更多不同的图像,并且您应该训练2000*classes迭代或更多
-
希望您的训练数据集包含您不想检测的带有未标记对象的图像 - 没有边界框的负样本(空.txt文件) - 使用与包含对象的图像一样多的负样本图像
-
标记对象的最佳方法是什么:只标记对象的可见部分,或标记对象的可见部分和重叠部分,或标记比整个对象多一点(有一点间隙)
-
要在每个图像中使用大量对象进行训练,请在 cfg 文件max=200的最后一个[yolo]-layer 或[region]-layer添加参数或更高的值(YoloV3 可以检测到的全局最大对象数是0,0615234375(widthheight)其中的宽度和高度是来自[net]cfg 文件中的部分的参数)
-
加速训练(降低检测精度)stopbackward=1在 cfg 文件中为 layer-136设置参数
未完待续~~