上海AI Lab&罗格斯大学&港中文提出CLIP-Adapter,用极简方式微调CLIP中的最少参数!...
关注公众号,发现CV技术之美
本文分享论文『CLIP-Adapter: Better Vision-Language Models with Feature Adapters』,由上海AI Lab&罗格斯大学&港中文联合提出《CLIP-Adapter》,用极简方式微调CLIP中的最少参数!
详细信息如下:

论文链接:https://arxiv.org/abs/2110.04544
项目链接:https://github.com/gaopengcuhk/clip-adapter
导言:
大规模对比视觉语言预训练在视觉表征学习方面取得了显著进展。与由固定的离散标签集训练的传统视觉系统不同,最近的工作引入了一种新的范式,以直接学习在开放词汇表环境中将图像与原始文本对齐。在下游任务中,使用精心选择的文本提示进行Zero-Shot预测。为了避免prompt工程,上下文优化被提出用来学习连续向量作为任务特定的prompt,并使用few-shot训练样本。
在本文中,作者展示了除了prompt tuning之外,还有一种替代方法可以实现更好的视觉语言模型。prompt tuning用于文本输入,但作者提出CLIP-Adapter在视觉或语言分支上使用特征适配器进行微调。
具体而言,CLIP-Adapter采用额外的瓶颈层来学习新特征,并与原始预训练特征进行残差样式的特征混合。因此,CLIP-Adapter在保持简单设计的同时,能够超越上下文优化。各种视觉分类任务的实验和广泛消融研究证明了本文方法的有效性。
01
Motivation
视觉理解任务,如分类、目标检测和语义分割,在更好的架构设计和大规模高质量的数据集上得到了显著改进。然而,为每个视觉任务收集大规模高质量数据集是劳动密集型的,而且成本太高,无法扩展。为了解决这个问题,“预训练-微调”范式,即对大规模数据集(如ImageNet)进行预训练,然后对各种下游任务进行网络调整,已在视觉领域广泛采用。然而,这些方法仍然需要大量标注,以便对许多下游任务进行微调。
最近,对比语言图像预训练(CLIP)被提出用于解决视觉任务,通过利用大规模噪声图像-文本对进行对比学习。通过将视觉类别作为prompt放入合适的手工制作模板中,它在各种视觉分类任务中实现了不错的表现,而无需任何标注(即zero-shot迁移)。
尽管基于prompt的zero-shot迁移学习表现出良好的性能,但设计好的prompt仍然是一个需要大量时间和领域知识的工程问题。为了解决这个问题,上下文优化(CoOp)进一步提出学习连续的soft prompt,并使用很少的zero-shot样本来替换精心选择的hard prompt。与zero-shot CLIP和linear probe CLIP设置相比,CoOp在zero-shot分类方面带来了显著的改进,显示了在大规模预训练视觉语言模型上进行快速调整的潜力。
在本文中,作者提出了一种不同的方法,用特征适配器而不是prompt tuning来更好地适应视觉语言模型。与执行soft prompt优化的CoOp不同,本文只需对轻量级附加特征适配器进行微调。由于CLIP的过度参数化和缺乏足够的训练样本,简单的网络调整会导致对特定数据集的过拟合。
受参数有效迁移学习中适配器模块的启发,作者提出了CLIP-Adapter,它只调整少量额外权重,而不是优化CLIP的所有参数。CLIPAdapter采用了一种轻量级瓶颈架构,通过减少参数数量来防止few-shot learning的潜在过拟合问题。同时,CLIP Adapter与之前的方法在两个方面不同:
CLIP Adapter仅在视觉或语言主干的最后一层之后添加了两个额外的线性层;相反,原始适配器模块插入到语言主干的所有层中;
此外,CLIP Adapter通过残差连接将原始Zero-Shot视觉或语言嵌入与相应的网络调整特征混合。
通过这种“残差样式混合”,CLIP Adapter可以同时利用原始CLIP中存储的知识和来自Few-Shot训练样本的新学习的知识。
02
方法
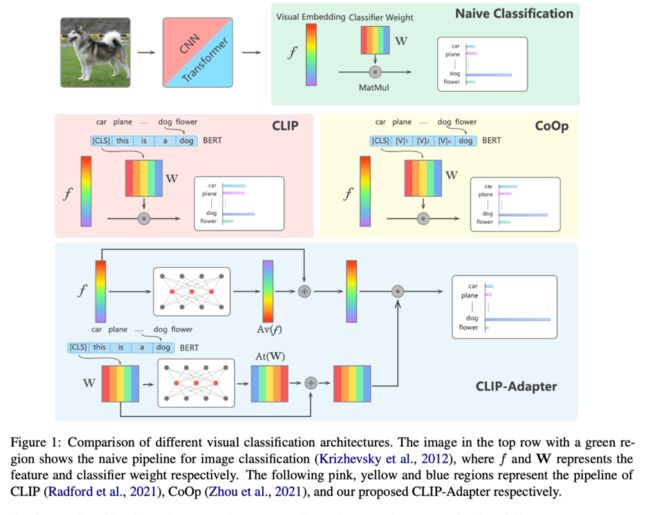
上图展示了不同视觉分类结构的对比。
2.1 Classifier Weight Generation for Few-Shot Learning
首先回顾一下使用深度神经网络进行图像分类的基本框架:给定一幅图像,其中H和W分别表示图像的高度和宽度。由基本组件(如CNN、Transformer或两者的混合)级联而成的神经网络主干输入,并将其转换为特征,其中D表示特征维度。
为了进行分类,将图像特征向量f乘以分类权重矩阵,其中K表示要分类的类别数。在矩阵相乘之后,可以得到一个K维logit。Softmax函数用于将logit转换为K个类别上概率向量,表示如下:
式中,τ表示Softmax的温度参数,表示i类的权重向量,表示i类的概率。
使用少量样本从无到有地将主干和分类器在一起训练,容易导致过拟合,并且可能会在测试集上出现严重的性能下降。
通常,few-shot learning范式是首先在大规模数据集上预训练主干,然后通过直接进行Zero-shot预测或进一步微调few-shot样本,将所学知识转移到下游任务。
CLIP遵循Zero-shot迁移风格——它首先通过对大规模噪声图像-文本对的对比学习对视觉主干和文本编码器进行预训练,然后在预训练后,CLIP直接执行图像分类,无需任何网络调整。
给定的K个类别的图像分类下游数据集,CLIP构造将每个类别名称放入预先定义的hard prompt模板H中。然后,语言特征提取器将生成的prompt编码为分类器权重,表示如下:
CoOp采用连续提示,而不是手工制作的hard prompt。CoOp创建一个随机初始化的可学习soft token列表,其中L表示soft token序列的长度。然后将soft token序列S连接到每个类名,从而形成提示。表示如下
对于CLIP和CoOp,基于生成的分类权重,其中,可以计算第i类的预测概率。
2.2 CLIP-Adapter
与CoOp的prompt tuning不同,本文提供了一个替代方法,通过微调其他特征适配器,在zero-shot图像分类上实现更好的视觉语言模型。作者认为,由于大量的参数和缺乏训练样本,以前广泛采用的“预训练-微调”范式在few-shot设置下无法调整整个CLIP主干网络。
因此,作者提出了CLIP Adapter,它只在CLIP的语言和图像分支上附加少量可学习的瓶颈线性层,同时在few-shot微调过程中保持原始片段主干冻结。然而,在少数few-shot样本中,使用附加层进行的简单微调可能仍然会陷入过拟合。为了解决过拟合问题并提高CLIP Adapter的健壮性,作者进一步采用残差连接来动态地将微调后的知识与CLIP主干中的原始知识混合。
具体而言,给定输入图像和一组类别的自然语言名称,基于上面的公式计算原始CLIP主干的图像特征f和分类权重W。然后,将两个可学习的特征适配器和分别集成到网络中用于变换f和W中,每个适配器都包含两层线性变换。
为了避免忘记由预训练CLIP编码的原始知识,作者对特征适配器采用了残差连接。使用两个常量值α和β作为“残差比”,以帮助调整保持原始知识的程度,从而获得更好的性能。特征适配器可以表示如下:
通过网络微调获取的新知识通过残差连接与原始特征加在一起:
获得新的图像特征和分类器权重,然后使用之前的公式可以计算出新的类别概率向量,并通过选择概率最高的类来预测图像类别:。
在few-shot训练中,使用交叉熵损失优化和的权重:
其中N是训练样本的总数;如果i等于ground-truth类别标签,则,否则;是第i类的预测概率;表示所有可学习的参数。
2.3 Variants of CLIP-Adapter
本文的CLIP适配器有三种结构变体:
仅微调图像分支的特征适配器,而保持文本分支冻结;
仅微调文本分支的特征适配器,同时保持图像分支冻结;
同时微调CLIP主干的图像和文本分支。
在超参数α和β方面,作者观察到不同的数据集具有不同的最优α和β值。手动选择超参数既耗时又费力。因此,作者还通过将α和β设置为可学习的参数,以可微分的方式探索它们的学习。通过这种方式,可以通过超网络Q:,从视觉特征或分类权重动态预测α和β。
03
实验
3.1 Few-Shot Learning
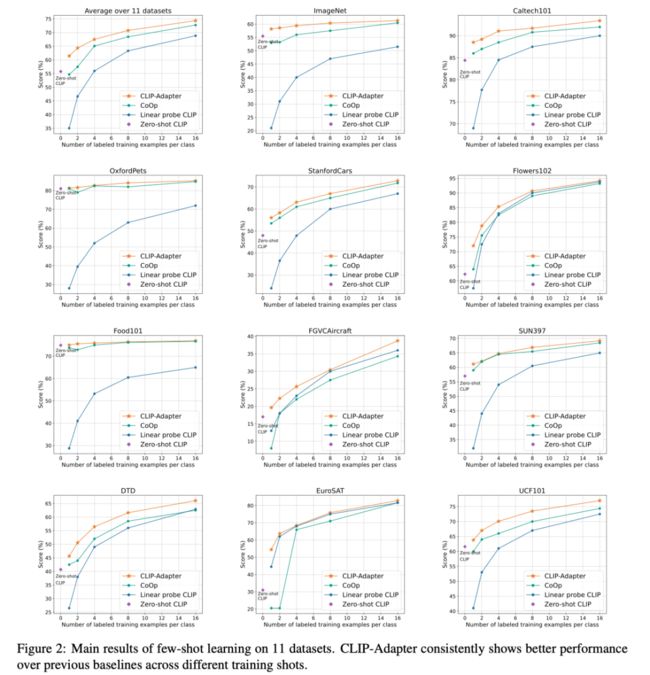
上图展示了在11个数据集上few-shot的实验结果,可以看出,CLIP-Adapter明显优于其他baseline方法。
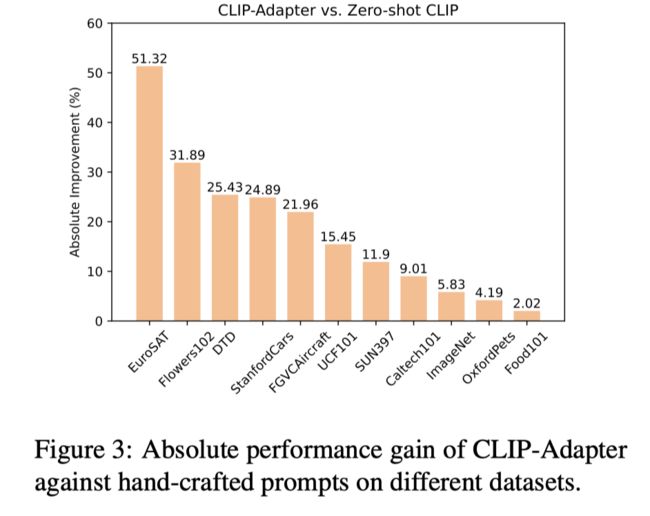
上图展示了本文方法相比于zero-shot CLIP的性能提升幅度。
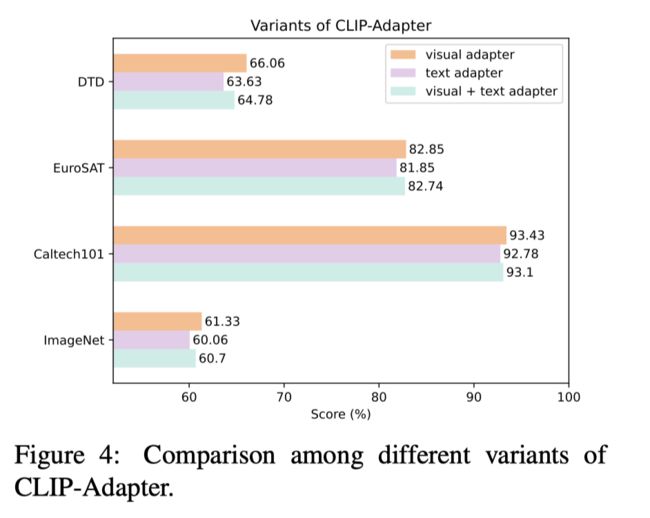
上表展示了不同CLIP Adapter变体的性能对比。
3.2 Visualization of Manifold

上图展示了在EuroSAT数据集上对CLIP、CoOp、CLIP Adapter(无残差连接)和CLIP Adapter(有残差连接)进行训练后,使用t-SNE对其manifold进行可视化的结果。可以看出,CLIP Adapter更有效地检测来自同一类的图像manifold之间的相似性。
3.3 Ablation Studies
3.3.1 Dimension of Bottleneck Layer

上表展示了DTD和ImageNet两个数据集上,不同bottleneck layers隐藏层维度的实验结果。
3.3.2 Residual Ratio α
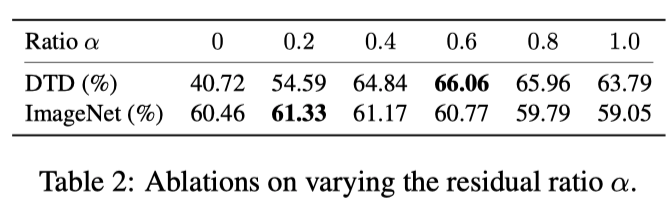
上表展示了不同残差比的实验结果。
04
总结
作者将CLIP Adapter作为基于prompt的方法的一种替代方法,用于few-shot图像分类。CLIP Adapter仅通过微调少量额外的瓶颈层,就恢复了“预训练-微调”范式。为了进一步提高泛化能力,作者采用了由残差比率参数化的残差连接,将zero-shot知识与新的自适应特征动态融合。
根据实验结果,在不同的few-shot设置下,CLIP Adapter在11个图像分类数据集上的表现优于baseline。广泛的消融实验研究证实了本文方法的设计,并证明了CLIP Adapter学习了更好的特征。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
加入「计算机视觉」交流群备注:CV
