DOTA数据集应用于Yolo-v4(-Tiny)系列3——使用Darknet框架的Yolov4(-Tiny)训练与推测
文章目录
- 前言
- 一、Darknet框架源码
- 二、调整数据集存放位置
-
- 2.1 按照VOC格式存放数据集
- 2.2 生成存有图片路径的.txt文件
- 三、使用Yolov4训练与推断
-
- 3.1 训练
-
- 3.1.1 voc.data的调整
- 3.1.2 yolov4-custom.cfg的调整
- 3.1.3 yolov4.conv.137下载
- 3.2 推断
- 四、使用Yolov4-Tiny训练与推断
-
- 4.1 训练
-
- 4.1.1 voc.data的调整
- 4.1.2 yolov4-tiny-custom.cfg的调整
- 4.1.3 yolov4-tiny.conv.29下载
- 4.2 推断
- 总结
前言
因为项目需要在Zynq开发板上实现深度网络的部署,采用Yolo-v4(-Tiny)两种目标检测模型,并使用武汉大学开源的DOTA数据集来训练和推断。因为此前使用计算机视觉相关的代码都是直接用已经处理好的数据集比如Pascal VOC、COCO、ImageNet等,DOTA数据集由于图片分辨率比较高,(2K-3K) * (2K-3K)分辨率,如果直接用于训练,效果不如将图片分割为多张图片,这样反而可以增加一张图片的目标框数量,对于提高模型精度十分有帮助。其次,DOTA数据集的标签格式不同于YOLO,所以需要在两种之间实现转换。此外,之前从未处理过raw的图片来制作数据集,所以也趁着这个机会对raw图做VOC或者YOLO格式的标签。另外在Darknet框架和Pytorch框架下都实现了Yolov4和Yolov4-Tiny框架的训练和推断。
趁着在部署到板子上之前,记录总结这一周多的工作。
由于篇幅较长,所以将分为几篇文章来记录。
本文在系列1数据集准备的基础上,使用Darknet框架源码训练和推断,本文是系列文章中的第3篇。仅依赖系列文章1和2就可以实现基于Pytorch框架下Yolov4和Yolov4-Tiny对DOTA数据集的训练和推断。而系列文章3和系列文章1实现基于Darknet框架下Yolov4和Yolov4-Tiny对DOTA数据集的训练和推断。
一、Darknet框架源码
环境:恒源云
源码:https://github.com/AlexeyAB/darknet
其中对恒源云的存储要求比较高,我在训练到尾声时的情况

二、调整数据集存放位置
2.1 按照VOC格式存放数据集
仿真VOC格式创建了多级文件夹
darknet-master下VOCdevkit/VOC2007
VOC2007/Annotations,VOC2007/ImageSets, VOC2007/JPEGImages
实际上Annotations下无文件,ImageSets下也无文件
而JPEGImages下有三个文件夹, JPEGImages/testexamplesplit, JPEGImages/trainexamplesplit, JPEGImages/valexamplesplit
每个xxxsplit下都有images文件夹(和labelYolo),并存放切割好的图片(和转换后的YOLO标注文件)
事实上,根据我得到的结果,只需要关注JPEGImages文件夹即可,其中labelTxt就是原来的DOTA风格的标签文件,可以不放。



2.2 生成存有图片路径的.txt文件
生成的.txt文件的路径建议如下
darknet-master/dota_train.txt
darknet-master/dota_val.txt
darknet-master/dota_test.val
其中三个文件都是存有图片的路径,类似,我各给出文件的部分内容
dota_train.txt的部分内容
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/trainexamplesplit/images/P0280__1__0___0.png
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/trainexamplesplit/images/P0074__1__0___0.png
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/trainexamplesplit/images/P0226__1__0___0.png
dota_test.txt的部分内容
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/testexamplesplit/images/P0006__1__0___0.png
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/testexamplesplit/images/P0006__1__0___505.png
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/testexamplesplit/images/P0006__1__30___0.png
dota_val.txt的部分内容
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/valexamplesplit/images/P0150__1__0___0.png
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/valexamplesplit/images/P0228__1__0___0.png
/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/valexamplesplit/images/P0414__1__0___0.png
因此需要导出各个图片文件的路径并写入到.txt文件中,提供如下代码:
import os
import sys
def str2int(strnum):
strlen=len(strnum)
numtmp = 0
for i in range(strlen):
numtmp += pow(10,strlen-1-i) * int(strnum[i])
def listfiles(rootDir, txtfile, label=0):
ftxtfile = open(txtfile, 'w')
list_dirs = os.walk(rootDir)
count = 0
dircount = 0
for root,dirs,files in list_dirs:
#for d in dirs:
# print(os.path.join(root, d))
# dircount += 1
## 调整文件名顺序用以更新files
#files_tmp = []
for f in files:
#print(os.path.join(root, f))
#print(f.split('_'))
#First = f.split('_')[0][1:]
#First_num = int(First)
#Second = f.split('_')[2]
#Second_num = int(Second)
#Third = f.split('_')[4]
#Third_num = int(Third)
#Fourth = f.split('_')[7].strip('.png')
#Fourth_num = int(Fourth)
#print("First is ",First, " Second is ", Second, " Third is ", Third, " Fourth is ",Fourth)
#print("First_num is ",First_num, " Second_num is ", Second_num, " Third_num is ", Third_num, " Fourth_num is ",Fourth_num)
ftxtfile.write(os.path.join(root, f) + '\n')
count += 1
print(rootDir + ' has ' + str(count) + ' files')
#print('50 is ',int('50'))
listfiles('/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/testexamplesplit/images', '/hy-tmp/darknet-master/VOCdevkit/VOC2007/ImageSets/Main/test.txt')
listfiles('/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/trainexamplesplit/images', '/hy-tmp/darknet-master/VOCdevkit/VOC2007/ImageSets/Main/train.txt')
listfiles('/hy-tmp/darknet-master/VOCdevkit/VOC2007/JPEGImages/valexamplesplit/images', '/hy-tmp/darknet-master/VOCdevkit/VOC2007/ImageSets/Main/val.txt')
三、使用Yolov4训练与推断
3.1 训练
使用下述命令进行训练
./darknet detector train cfg/voc.data cfg/yolov4-custom.cfg yolov4.conv.137 -map
但是在使用之前,先比对一下下述几项:
3.1.1 voc.data的调整
voc.data内容需要调整为:
classes= 15
train = /hy-tmp/darknet-master/dota_train.txt
valid = /hy-tmp/darknet-master/dota_val.txt
names = data/dota.names
backup = /hy-tmp/darknet-master/backup
其中classes是指DOTA数据的分类数
其中train提供dota_train.txt的路径,其中valid提供dota_val.txt的路径,这两者都是在第2节中得到的。
其中backup提供最终得到的权重应该存放到/hy-tmp/darknet-master/backup路径下。
其中names提供dota.names的路径,dota.names内容如下:
plane
baseball-diamond
bridge
ground-track-field
small-vehicle
large-vehicle
ship
tennis-court
basketball-court
storage-tank
soccer-ball-field
roundabout
harbor
swimming-pool
helicopter
3.1.2 yolov4-custom.cfg的调整
yolov4-custom.cfg内容主要是注意两块,第一是
batch=64
subdivisions=16
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.00261
burn_in=1000
max_batches = 30000
policy=steps
steps=24000,27000
scales=.1,.1
第二是[yolo]前后的filters和classes。
[convolutional]
size=1
stride=1
pad=1
filters=60
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=15
3.1.3 yolov4.conv.137下载
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137
3.2 推断
使用以下命令即可推测
./darknet detector test cfg/voc.data cfg/yolov4-custom.cfg backup/yolov4-custom_best.weights inference/test/P0006.png
其中backup中存放着.weights文件,inference中存放test用的图片。
测试之前的原图
不做切割直接做推测的结果如下:

使用切割后的图,结果如下:


四、使用Yolov4-Tiny训练与推断
4.1 训练
使用下述命令训练
./darknet detector train cfg/voc.data cfg/yolov4-tiny-custom.cfg yolov4-tiny.conv.29 -map
4.1.1 voc.data的调整
同3.1.1
4.1.2 yolov4-tiny-custom.cfg的调整
修改重点同3.1.2
4.1.3 yolov4-tiny.conv.29下载
https://github.com/GotG/yolotinyv3_medmask_demo/blob/master/yolov4-tiny.conv.29
4.2 推断
使用以下命令即可推测
./darknet detector test cfg/voc.data cfg/yolov4-tiny-custom.cfg backup/yolov4-tiny-custom_best.weights inference/test/P0006.png
其中backup中存放着.weights文件,inference中存放test用的图片。
测试之前的原图
不做切割直接做推测的结果如下:
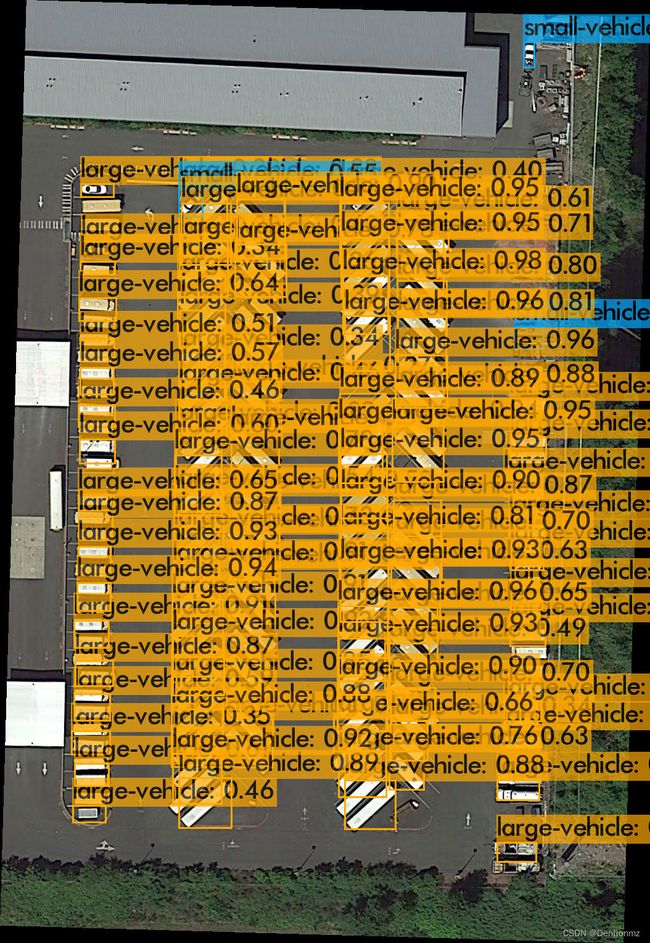
使用切割后的图,结果如下:


总结
从DOTA数据切割图片、标注风格转换再到使用两类框架下的Yolov4和Yolov4-Tiny目标检测训练和推测,就到此结束了。后续在Zynq Ultrascale+ MPSoC上部署,会对模型做量化等优化措施,同时会深入研究Xilinx提供的DPU工具链,欢迎关注。