【保姆级】论文阅读与分析《Learning Heterogeneous Knowledge Base Embeddings for Explainable Recommendation》
《Learning Heterogeneous Knowledge Base Embeddings for Explainable Recommendation》-by Qingyao Ai, Vahid Azizi , Xu Chen and Yongfeng Zhang
精读的论文记录下来才不会忘呀!
摘要 Abstract
本文目的:说明基于知识的嵌入并提出可解释的推荐系统。具体而言,①提出了一个基于知识的表示学习框架,用于推荐算法的异构实体嵌入;②基于嵌入知识库,提出一种软匹配算法以生成推荐物品的个性化说明。
关键词:recommender systems; explainable recommendation; knowledge-base embedding; collaborative filtering
1. Introduction
第一段作者来回发问:我们能不能利用大规模结构化的用户行为数据来提升协同过滤算法的性能?能不能?嗯?能不能?当然,答案是肯定的!(必须能啊,否则下一句就是此文终[强颜欢笑])
基于知识的嵌入将异构信息投影到一个统一的低维嵌入空间中并获得了成功,因而作者想到,通过将多类别的用户信息和物品属性信息编码到最终的用户/物品嵌入中,可以在保留知识内部结构的基础上增强推荐系统的性能。与此同时,通过保留用户/物品/异构实体的知识结构,可以利用模糊推理为用户生成量身定制的推荐物品说明。[注释:基于知识的嵌入 knowledge-base embeddings 即 KBE;异构信息 heterogeneous information]
本文中,作者在知识图的基础上设计了一种新的可解释的协同过滤框架。该框架主要是通过结合传统协同过滤和基于知识的嵌入构建而成。作者首先定义 user-item 知识图的概念,该过程将用户行为以及物品属性相关知识编码为关系图结构。接着,作者延伸了协同过滤算法的设计理念以学习知识图,帮助形成个性化推荐。最后,对于每一个推荐物品,作者利用软匹配在知识图路径中构建模糊推理,以生成个性化说明。[注释:协同过滤 collaborative filtering]
在后续章节中,第二章描述相关工作,第三章提出问题表述,第四章介绍基于知识图的协同过滤模型,第五章介绍生成推荐说明的软匹配方法,第六章讲述实验设置,第七章进行结果讨论,第八章总结工作并展望未来的研究方向。
2. Related Work
主要介绍了知识图在推荐系统中的发展。早期的基于知识的嵌入方法主要依靠矩阵分解或是非参数贝叶斯框架。近年来神经嵌入的进步催生了许多神经知识嵌入方法,例如transE,transH 和 transR。(按道理讲trans系列模型应该归类为把尾实体作为头实体和关系的一种翻译模型,论文将其作为神经知识嵌入方法来描述,在此我仅作"neural knowledge-base embedding approaches"的直译,希望读者勿混淆)
这一部分可以参考知乎文章对知识图谱嵌入主流模型的简介,包括翻译模型、双线性模型、神经网络模型、双曲几何模型和旋转模型等:KGE主流模型简介
3. Problem Formulation
为了将问题数学化、公式化,首先构建三元组集合知识库 S={(eh,et,r)},其中 eh 代表头实体, et 代表为实体, r 代表从头实体到尾实体的关系。如此一来,目标系统的任务可表述为:1)对于每一个用户 u ,找到一个或一系列最有可能被其购买的物品 i ;2)对于每一个被检索的user-item对,基于 S 构建自然语言句子以解释用户选择该物品的理由。[注释:eh 即 head entity ,et 即 tail entity , r 即 relationship ]
为简化模型,作者仅考虑5种实体:
- 用户 user :推荐系统的用户
- 物品 item :推荐系统的产品
- 词语 word :产品名称、描述或评价中的词语
- 品牌 brand :产品的品牌或制造商
- 类别 category :产品所属类别
于此同时考虑6类实体关系:
- 购买 Purchase :用户已购买该产品(from user to item)
- 提及 Mention :词语在用户评论或产品评论中被提及(from user to word / from item to word)
- 属于 Belongs to:物品所属的种类(from item to category)
- 制造商 Produced by:物品所属的品牌(from item to brand)
- 同时购买 Bought together:单次交易中,同时购买的物品(from item to item)
- 历史购买 Also bought:同一用户购买过的物品(from item to item)
- 同时浏览 Also viewed:单次浏览行为中,用户在购买产品1前后浏览了另一产品2 (from item1 to item2)
4. Collaborative Filtering on Knowledge Graghs
铺垫了这么久,终于,可以进入理论正题了!Follow Me~~~
本文推荐系统采用的是基于用户物品知识图谱的协同过滤模型,作者在本章中先介绍如何利用实体和关系建立知识图谱,然后讨论如何优化模型参数。
4.1 Relation Modeling as Entity Translations
作者借鉴论文《Translating embeddings for modeling multi-relational data -by Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O.》中的方法(即transE),将头实体和尾实体表示为潜在向量,实体关系视作实体间的翻译函数,将关系 r 建模为低维潜在空间中头实体到为实体的线性投影,公式化表示为(粗体表向量):
et = trans(eh, r) =eh + r* (1)
示意图如下:
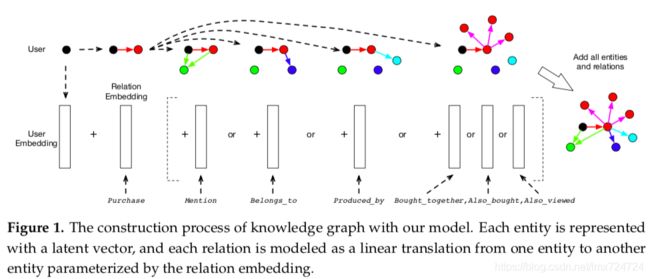
然而,求解公式(1)是不现实的。一方面,为所有类型相同的实体构造单个潜在向量会导致推荐效果不佳,因其忽略和用户和物品之间的差异;另一方面,为三元组集合中所有实体分配不同的潜在向量的解决办法在数学上行不通,因为一个实体可以被多个实体以同种关系连接。
为解决该问题,作者将公式(1)改为松弛约束:
et ≈ trans(eh, r) = eh + r*
并采用基于嵌入的生成框架来学习。算法目标是使正三元组以最大可能性出现。换句话说,在图谱中存在的三元组中(正三元组),实体所对应的嵌入向量相似;在图谱中不存在的三元组中,实体所对应的嵌入向量差异大。公式化表述为:
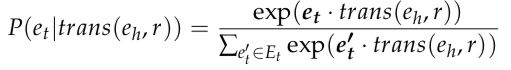 (2)
(2)
其中 Et 是所有与 et 同类型的可能出现的实体的集合。上述基于生成的框架是作者借鉴了Mikolov等人的文章《Distributed representations of words and phrases and their compositionality》,快速理解可以参考博客:Word2Vec 与《Distributed Representations of Words and Phrases and their Compositionality》学习笔记 [注释:图谱中存在的三元组 observed relation triplet]
由于公式(2)是softmax函数,最大化条件概率 P 无疑会增加 trans(eh, r) 与 et 的相似度并降低 trans(eh, r) 与非 et 实体的相似度。如此一来,作者将公式(1)转化为可通过迭代算法(如梯度下降)解决的最优化问题。该模型的另一个优势在于提供了尾实体和翻译模型的软匹配理论指导,而这对于提取物品的推荐说明意义重大。[注释:softmax函数相关说明可参见博客:一分钟理解softmax函数 ]
4.2 Optimization Algorithm
令 S 为训练集中观察到的三元组的集合,计算其可能性,定义如下:
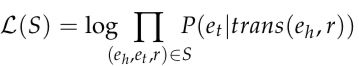 (3)
(3)
其中 P 为公式(2)中获得的后验概率[注释:后验概率可参见知乎回答:什么是后验概率 ]。然而实践中,公式(3)的计算成本很高。为了有效地进行训练,作者利用负采样来近似计算 P 。具体而言,对于每一个观察到的三元组,随机采样一系列与 et 相同类型的“负实体”,再计算其对数似然:
![]() (4)
(4)
其中 k 是负样本的个数,Pt 是预先定义好的与 et 同类实体的噪声分布,σ 则是sigmoid函数(σ = 1/ (1 + e-x) )。因此,L(S) 可以改写为正三元组的对数似然之和:
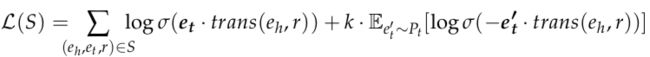
(5)
作者还测试了 TransE 中的 L2 范数损失函数,发现其相比于本文的基于对数似然损失的内部乘积模型无任何提升,并且 L2 范数损失函数很难生成扩展,因此作者使用公式(5)的损失函数进行嵌入、推荐和解释说明。关于L2 范数损失函数可参见博客:L1、L2损失函数、Huber损失函数 [注释:此处 E [∙]应指期望]
为了展示文章模型和传统的基于矩阵分解的协同过滤模型之间的关系,作者受文章《Neural word embedding as implicit matrix factorization. -by Levy, O.; Goldberg, Y.》的启发,在特定关系三元组 ( eh, et, r ) 上得到方程(5)最大化的局部目标:
![]() (6)
(6)
其中,#(eh, et, r) 和 #(eh, r) 分别是 (eh, et, r) 和 (eh, r) 在训练集中的频率。如果进一步计算 l(eh, et, r) 关于 x = et ∙ trans(eh,r) 的偏导数,可得:
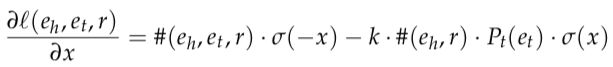 (7)
(7)
当训练过程收敛,偏导数等于0,则可得:
 (8)
(8)
可以看到,等式左边是潜在向量 et 和 trans(eh, r) 的乘积,等式右边则是 et 与 (eh,r) 逐点互信息的转换。因此,最大化正三元组的对数似然(基于负采样)实际上是分解关系 r 的头尾实体对 (eh, et) 的互信息矩阵。从这个意义上讲,本文模型是分解方法的变体,可在产品知识图谱上共同分解多元关系矩阵。[注释:头尾实体对 head-tail entity pairs]
由公式(8)可见,提出的模型的最终目标由噪声分布 Pt 控制。和前人的研究相似,作者发现集合中尾实体频率高的关系 r,其揭露的头实体属性信息少。因此,作者将每个关系 r(除“购买”以外)的噪声概率 Pt 定义为集合 S 中 (eh, et, r) 的频率分布,以使频繁尾实体的互信息在优化过程中被惩罚。而对于“购买”,则将 Pt 定义为统一的分布,以避免对某些项目产生不必要的偏差。
5. Recommendation Explanation with Knowledge Reasoning
这一节中,作者讲述如何利用提出的模型形成推荐说明。首先,介绍说明路径的概念并描述如何生成自然语言解释。接着,提出了软匹配算法以寻找潜在空间中用户-物品对的说明路径。
为寻找可能链接用户和物品的解释路径,算法首先以最大深度 z ( 从用户 eu 到物品 ei )构建广度优先搜索。接着,记录路径并利用软匹配(公式(10)和公式(11))计算路径概率。最后,对路径概率排名并返回最佳路径以创建自然语言解释。在这项工作中,作者利用 z 作为超参数并通过增加实验值来调整参数以寻找非空交点。[注释:广度优先搜索 BFS 即 Breath First Search,简单理解可参见博客:BFS(广度优先搜索) ,超参数 hyper-parameter]
5.1 Explanation Path
先声明一下,上文中的"解释路径"和"说明路径"意思相同,都是Explanation Path的翻译。
找到推荐的说明就是在知识图谱中找到合理的逻辑推理序列。为此,作者通过构建用户与物品在潜在知识空间中的解释路径来寻找合理说明。公式化表示为:
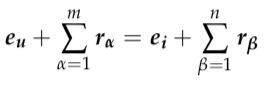 (9)
(9)
作者对公式中的各参数变量作了许多约束和说明,为便于理解,我画了张图:

换句话说,当存在实体能被 eu 和 ei 以知识图谱中的正三元组推理出来,则存在合理的解释路径。下图是作者绘制的基于实际案例的算法图解:

其中,iPad被推荐给用户Bob。为了生成推荐说明,作者基于关系的类型创建简单的模板,并将其应用到解释路径中。就上图为例,我们之所以认为Bob会对iPad感兴趣,是因为他经常在评论中提到“IOS”,而“IOS”也经常在iPad的评论中被提到。或者,我们认为Bob会对iPad感兴趣的原因是他经常购买苹果公司的产品,而iPad是苹果公司生产的。
5.2 Entity Soft Matching
上一节的例子十分清晰地展示了解释路径生成的方法,然而大家有没有想过,当正三元组中不存在用户和被推荐物品的关联路径时时,如何生成解释说明?[举个例子:假如Bob被推荐的是华为的平板,该物品类别和品牌等信息都与Bob以前买过的东西没有关联,这种情况下要如何寻找解释路径] 作者认为,这种情况在实际推荐中是很常见的,因为产品知识图谱稀疏性高,就亚马逊评论数据来说,用户-物品矩阵密度常常低于0.1% [简而言之就是用户和物品数量不在一个数量级] 因此作者提出在潜在空间构建实体软匹配以寻找解释路径。该方法的关键是找到一个中间实体 ex 来连接头尾实体。由于公式和思路与第四章类似,看到这里的小伙伴们可以尝试自己推导一下,我就不详述了~
6. 实验设置
略
7. 结果分析
7.2 解释路径的案例学习
结合作者本节的案例,可以很好地理解第五节提出的算法。选择编号为A1P27BGF8NAI29的并且购买了手机的用户为测试案例,系统首推物品为高速壁式充电器,该推荐经数据集验证,是正确的。下图是翻译过程关于用户和其他实体的子空间:
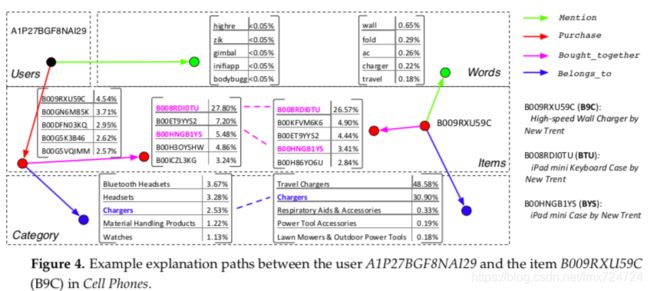
图中可以看出,可选路径实际上有三条(经过第一轮筛选后),分别为:
- B9C被推荐的原因是用户经常购买和BTU同时购买的物品,而B9C经常会和BTU同时被购买,关联概率为(27.8% * 26.57% = 7.39%);
- B9C被推荐的原因是用户经常购买和BYS同时购买的物品,而B9C经常会和BYS同时被购买,关联概率为(5.48% * 3.41% = 0.19%);
- B9C被推荐的原因是用户经常购买和和充电器类别相同的物品,而B9C属于充电器类别,关联概率为(2.53% * 30.90% = 0.78%);
按照软匹配的思路,BTU和BYS就是被筛选出来的 ex,由于第一条解释的关联概率最高,因此被选为推荐物品的合理说明。
8. 结论与展望
略
--------写在最后-------
欢迎大家一起讨论和学习!如有错误或者疑问,可以评论留言,欢迎指正~
我们一起进步:)