yolov5实践
目录
一、环境搭建
1、安装pychram
2、下载yolov5项目
3、安装Anaconda
4、安装GPU驱动CUDA
二、项目运行
1、运行测试文件
2、检测自己的图片
3、训练数据获得模型
4、训练自己的数据集获得模型
(1) 图片准备
(2)标签集的准备
(3)数据集更换路径
(4)修改训练数据的配置文件
5、使用自己的模型检测数据
一、环境搭建
1、安装pychram
官网下载:https://www.jetbrains.com/pycharm/download/#section=windows

安装可默认安装也可以根据网上的教程安装
安装教程(可以不安装python):
Python以及Pychram安装教程(2022)_冷巷(✘_✘)的博客-CSDN博客
汉化教程:
2021 Pycharm汉化教程,两种方法,带图讲解,简洁明了_愿你笑的博客-CSDN博客_pycharm汉化
2、下载yolov5项目
官网下载:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite

直接下载为最新版yolov5的项目,想要其它版本的点击网页右侧的Releases进入页面并往下翻可以找到不同版本及其参数
下载完成后解压在任意路径下,再打开pychram

打开项目文件后双击打开requirements.txt文件,记录下环境要求中的"torch"的版本要求,然后去打开Anaconda创建虚拟环境(不关闭pychram)

3、安装Anaconda
官网下载:https://www.anaconda.com/products/distribution#macos
Anaconda为免费软件,没有特殊版本
最好根据网上教程安装,教程地址:
史上最全最详细的Anaconda安装教程_OSurer的博客-CSDN博客_anaconda清华镜像下载安装教程
安装好后打开Anaconda的可视化窗口(更方便创建虚拟环境,并会在创建时下载一些基础的库,不用自己在命令行一行一行的输入下载)

打开后点击窗口左侧的Environments,然后点击窗口下方Create创建新的虚拟环境


选好后点击Create,等待Anaconda自行安装python基础环境,安装好后切换到pychram窗口,点击页面右下角,添加新的解释器


配好后窗口下方有进度条显示加载环境配置
![]()
加载完后找到窗口上方提示信息,点击安装要求,然后会有弹窗提示安装(不止图片上显示的这些),直接点击安装
![]()
等待各个库安装,一般会有库不能直接安装,等待其提示
安装完成后会有pytorch的一系列库不能直接安装,进入pytorch官网
官网地址:https://pytorch.org/get-started/locally/#windows-package-manager

然后打开Anaconda的命令行窗口,输入"activate (name)"转到先前创建的虚拟环境

粘贴在pytorch官网复制的命令,执行等待下载安装完成
其它未被pychram自动安装好的库使用"conda install (name)"或"pip install (name)"安装
如果下载速度很慢,可以配置镜像源下载:
Anaconda配置国内镜像源_run_success的博客-CSDN博客_conda添加镜像源
4、安装GPU驱动CUDA
yolov5为深度学习算法,而深度学习获得模型需要训练大量数据集,电脑CPU训练速度很慢,需要使用GPU训练,CPU训练官方coco数据集可能要用几个小时甚至几天(具体时间没试过),而GPU只需要几十分钟
官网下载:CUDA Toolkit Archive | NVIDIA Developer
前面选择pytorch时,其选项中有cuda的对应版本,不要安错版本

CUDA安装教程:
CUDA安装教程(超详细)_Billie使劲学的博客-CSDN博客_cuda安装
二、项目运行
1、运行测试文件
测试文件名字:detect.py
如果前面的环境搭建好了,就可以直接运行测试文件了
运行时会自动下载模型yolov5s.pt到项目集中
结果被保存在项目文件runs/detect/下,每运行一次生成一个文件夹,结果为检测并画框过后的图片

2、检测自己的图片
查看detect.py中的代码,约200+行处的"parse_opt"函数

图中第219行"default=ROOT / 'data/images'"为要测试的图片的路径,可以更改为自己的图片路径或将自己的图片放到该路径下
第222行"default=0.25"为置信度(当检测到图中某块是需要检测物体的可能性大于等于这个值时,将该块标注为检测出的物体),可以适当调高一些,也就是检测到较大概率才标注出来
网上有详细注释:
yolov5——detect.py代码【注释、详解、使用教程】_Charms@的博客-CSDN博客_detect.py
因为使用的是官方模型,所以效果应该还是可以的
3、训练数据获得模型
主要的训练文件名字:train.py
训练文件的程序需要完整的环境配置,运行时可能会报错,如果是找不到模块就说明环境配置没有完全搭建好,缺少哪个包就安装哪个。
同时,项目的默认要求电脑配置较高,自己的电脑运行时也可能报错

可将这两个参数值调低
该文件在网上也有详细的注释:
yolov5——train.py代码【注释、详解、使用教程】_Charms@的博客-CSDN博客
不多修改其它参数运行时,默认加载coco128数据集,可以自己先下好在运行,也可以等运行时默认下载(最好默认下载,自己下载时要找到正确的路径程序才能识别到)
初次运行也可能出现其它错误,在此不一一举例,请自行搜索
结果被保存在项目文件runs/train/下,每运行一次生成一个文件夹
(1)生成的模型文件(weights中best.pt和last.pt)

(2)根据最好模型生成的混淆矩阵
对角线表示检测正确的数据,颜色越深表示检测越精确,可明显看出本次训练对大部分标签检测正确率较高,也有部分标签检测正确率较低

(3)根据最好模型生成的P、R、PR、F1曲线
P曲线,灰色线条为各类别的P曲线,蓝色为所有曲线的均值,纵轴为查准率(检测出的物体为正确的概率),横轴为置信度(模型认为该物体是该标签的相信程度),可以看出置信度越高时查准率越高

R曲线,纵轴为查全率(有多少物体被正确检测出,还有多少物体漏检),可以看出置信度越高会有越多物体漏检

PR曲线,可以看出全部检测正确时有部分漏检,而全部检测出时有部分检测错误
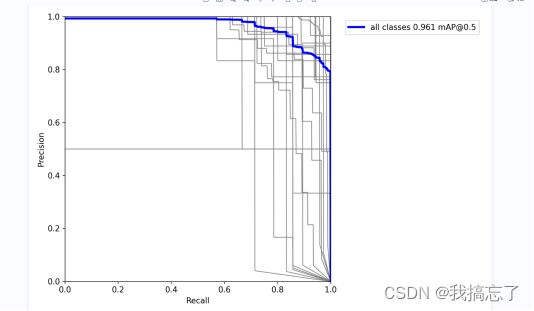
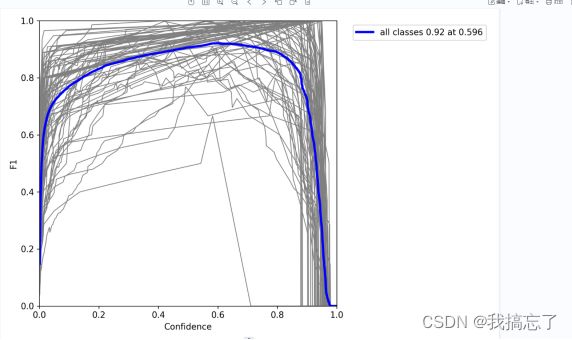
F1曲线,F1为查准率和查全率的调和平均数,及其值越高表示效果越好,图像左上角写出了F1最大值及其坐标
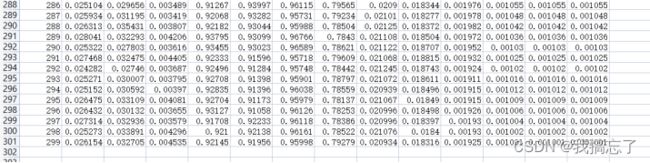
(4)results.csv表格
包含每轮训练的模型不同参数(各个损失率、查全率、查准率、查准率和查全率的调和平均数等)
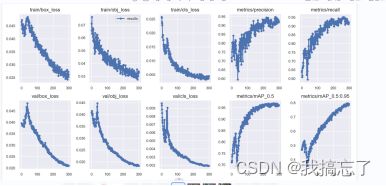
(5)results.png图片
每轮训练的各个参数在直角坐标系上的散点及连线,能较清晰的看出各参数的变化趋势(随着训练次数的增加模型各参数向更好的方向变化且变化逐渐平缓)
(6)opt.yaml和hyp.yaml模型配置文件
保留本次训练的参数配置(神经网络结构),方便后续对比不同参数下的模型。训练时可修改项目代码中的参数来获得不同的训练模型,这些参数不存在最优的设置,需要自己慢慢调试获得较为理想的模型。
(7)labels.jpg 和labels_correlogram.jpg图片

labels_correlogram.jpg是数据的多变量联合分布直方图,较为复杂,但用处不大
(8)其它图片
训练过程中的一些测试效果图,可以大致看出模型的优劣

4、训练自己的数据集获得模型
(1) 图片准备
图片最好不要选择png格式的图片,因为从网上下载的png格式图片有部分是没有底色的(在训练时无底色的图片的底色为黑色,而使用普通的图片查看器其底色为白色)
图片一般有两种方法获得:网上下载、自己拍照
拍照最好是使用录像+视频逐帧裁剪图片,这样训练需要不同角度的图片时更方便获得连续变化角度的图片
视频逐帧裁剪图片的python代码(环境可直接使用项目环境),该程序为"input"式程序,可直接运行,不需要修改其它参数:
import cv2
import os
f = 30 # 截图速率默认为每30帧一张
def transfer(): # 定义转换过程(核心代码)
try:
os.makedirs(pic_path) # 自动在视频文件同一路径生成以视频文件名为名字的新文件夹
except FileExistsError:
print('————已存在与视频同名文件夹,请删除后再操作!————')
quit() # 存在同名文件夹系统报错,退出程序
cap = cv2.VideoCapture(video) # 导入视频文件
num = 1 # 可在此处修改图片文件名起始序号
print('————设置完成,即将开始导出图片!————')
while True:
if cap.grab():
num += 1
if num % f == 1: # 每f帧截取一个图片
flag, frame = cap.retrieve() # 解码并返回一个帧
if not flag:
continue
else:
# cv2.imshow('video', frame)
new = pic_path + "/" + pic_name + str(int(num / f)) + ".jpg" # 定义图片的输出路径以及名字
print('正在导出:' + pic_name + str(int(num / f)) + ".jpg (按Esc停止运行)")
cv2.imencode('.jpg', frame)[1].tofile(new) # 将生成的截图输出到新文件夹并命名
else: # 运行完毕自动退出
break
if cv2.waitKey(10) == 27: # 检测到按下Esc时退出
quit()
print("程序已开始循环")
while True:
password = input('输入0退出程序:')
if password == '0':
break
while True: # 用户设置阶段
try:
video_path = input('请输入你的视频文件所在路径(如:F:/新建文件夹,注意是/斜杠和英文冒号):') # 获取视频文件路径
if not os.path.exists(video_path): # 判断文件路径是否存在
print('你输入的文件路径有误,请重新输入!')
else:
print('————文件路径匹配成功!————')
break
except NameError:
print('你输入的文件路径有误,请重新输入!')
while True:
try:
video_name = input('请输入你的mp4视频文件名(不需要加后缀,如:我的视频):') # 获取视频文件名
video = video_path + "/" + video_name + ".mp4" # 格式默认为mp4,如果你要转换别的格式,请在此处更改
if not os.path.exists(video) or video_name == '': # 判断文件是否存在
print('你输入的文件名有误,请重新输入!')
if os.path.exists(video) and video_name != '':
print('————视频文件匹配成功!————')
break
except ValueError:
print('你输入的文件名有误,请重新输入!')
while True:
try:
f = int(input('请输入你想要的帧数(即每多少帧截一张图,如:最小间隔逐帧截图,则输入2,不输入则默认设置为30):')) # 获取用户的帧率需求,只限数字
if f < 0:
print('帧数不能为负!')
elif f == 0:
print('帧数不能为0!')
elif f == 1:
f += 1
print('————帧数不支持设为1,截图速率已设置为' + str(f) + '帧一张!————') # 帧数为1时,系统不运作,这个是bug
break
else:
print('————截图速率已成功设置为' + str(f) + '帧一张!————')
break
except ValueError:
print('————截图速率已自动设置为默认的' + str(f) + '帧一张!————')
break
pic_name = input('请输入你要生成的图片名称(不输入则默认为纯数字,推荐不输入名字直接回车键,因为生成PPT需要纯数字的文件名):') # 获取用户的图片文件名需求,文件名为:输入的名字+数字
if not pic_name:
pic_name = "" # 不输入则默认为空名字+数字
pic_path = video[:-4] + "/" # 根据用户输入的视频文件路径来定义图片存放路径
transfer() # 主程序启动
print('运行完毕!图片已全部保存在:' + pic_pat
(2)标签集的准备
标签集的准备需要使用打标工具,这里推荐使用可以安装在anaconda虚拟环境中的labelimg,就不需要安装其它软件,也可以使用labelme,不过labelme生成的标签文件是json格式的,而labelimg生成的是txt格式的,项目训练需要使用的是txt格式的标签文件,使用labelme打标还需要解析json文件将其转换为txt文件。
打标工具的下载和使用都较为简单,下载和使用教程:
labelImg的使用教程,快捷键,用于标注voc或者yolo格式的数据_嗨,紫玉灵神熊的博客-CSDN博客_labelimg使用教程
(3)数据集更换路径
这里先不去更改项目程序中的路径,先将图片文件与对应标签文件放到指定路径下——(任意位置,最好是项目文件外同级或之中)新建文件夹(命名随意),进入其中新建两个文件夹images和labels(名字必须是这个,项目代码中很多地方都是写的这两个名字,与其修改代码不如修改文件夹名),然后将图片放进images,标签文件放进labels
(4)修改训练数据的配置文件


未改前为此(版本不同参数不一定相同)

修改为自己的数据集(一般修改最好是注释掉以前的代码,重新写自己的代码,不然出错了就改不回来了)

改完后就可以运行train.py文件开始训练了
5、使用自己的模型检测数据
前面说了检测自己的图片,此处操作与其一致,但还需要修改一下检测模型的路径
在detect.py文件中修改这一行

修改完后运行detect.py文件即可得到检测结果
至此,yolov5的基础实践就结束了,而yolov5的功能不止于此,后续需要更多的学习理解yolov5的其它功能与其逻辑