机器学习常见算法个人笔记
人工智能是对人的意识、思维的信息过程的模拟。
机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类,更具体的说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达。需要注意的是,机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。学到的函数适用于新样本的能力,称为泛化(Generalization)能力。
机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系。
1. 决策树
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
决策树是一种机器学习的方法。决策树的生成算法有ID3, C4.5和C5.0等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
决策树是一种十分常用的分类方法,需要监管学习(有教师的Supervised Learning),监管学习就是给出一堆样本,每个样本都有一组属性和一个分类结果,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
数据集中哪一个特征在划分数据分类时起决定性的作用
基本知识:
熵:只依赖X的分布,和X的取值没有关系,熵是用来度量不确定性,当熵越大,概率说X=xi的不确定性越大,反之越小。信息熵反映了数据的复杂度,熵越高,混合的数据也越多。如果增加了某个特征导致熵值增加很大,那么这个特征的“影响力”就很大。
信息增益:在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好。
优点:计算复杂度不高,输出结果易于理解。
缺点:可能会产生过度匹配问题(输出的结果完全满足当前数据,但不具备普遍推广的价值)
适用场景:多维特征数据
2. 随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想–集成思想的体现。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
特点
-
在当前所有算法中,具有极好的准确率/It is unexcelled in accuracy among current algorithms;
-
能够有效地运行在大数据集上/It runs efficiently on large data bases;
-
能够处理具有高维特征的输入样本,而且不需要降维/It can handle thousands of input variables without variable deletion;
-
能够评估各个特征在分类问题上的重要性/It gives estimates of what variables are important in the classification;
-
在生成过程中,能够获取到内部生成误差的一种无偏估计/It generates an internal unbiased estimate of the generalization error as the forest building progresses;
-
对于缺省值问题也能够获得很好得结果/It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing
https://www.cnblogs.com/maybe2030/p/4585705.html
3.回归
Regression问题的常规步骤为:
- 寻找h函数(即hypothesis);
- 构造J函数(损失函数);
- 想办法使得J函数最小并求得回归参数(θ)
逻辑回归:
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数)。
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
对于多类分类问题,可以将其看做成二类分类问题:保留其中的一类,剩下的作为另一类。对于每一个类 i 训练一个逻辑回归模型的分类器,并且预测y = i时的概率;对于一个新的输入变量x, 分别对每一个类进行预测,取概率最大的那个类作为分类结果
4.K 近邻算法
从K 近邻的计算过程可以看出,K 近邻算法虽然原理简单,但在实际应用时必须将所有数据进行存储,而且需要对数据集中的每个数据进行距离计算,非常消耗计算资源。所以k-近邻算法一般不会应用于复杂的分类问题。

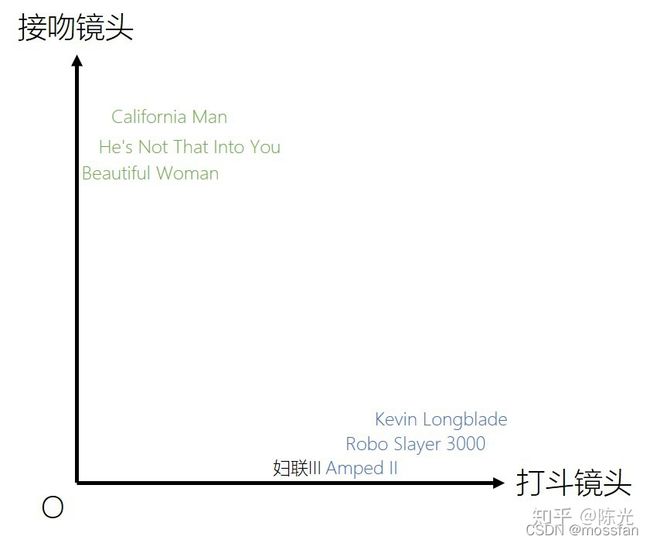
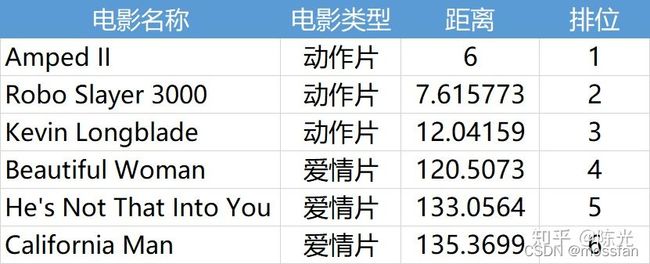
优点:精度高、不太受到异常离散值的影响
缺点:需要大量存储空间、计算复杂度高
适用场景:少量数据和大量低维数据
https://www.zhihu.com/question/26726794/answer/424154856
5.SVM(支持向量机)
SVM的核心思想就是找到不同类别之间的分界面,使得两类样本尽量落在面的两边,而且离分界面尽量远。
适用情景:SVM在很多数据集上都有优秀的表现。相对来说,SVM尽量保持与样本间距离的性质导致它抗攻击的能力更强。
6.神经网络 (Neural network)
核心思路是利用训练样本(training sample)来逐渐地完善参数。还是举个例子预测身高的例子,如果输入的特征中有一个是性别(1:男;0:女),而输出的特征是身高(1:高;0:矮)。那么当训练样本是一个个子高的男生的时候,在神经网络中,从“男”到“高”的路线就会被强化。同理,如果来了一个个子高的女生,那从“女”到“高”的路线就会被强化。最终神经网络的哪些路线比较强,就由我们的样本所决定。
7.联邦学习
联邦学习是一种带有隐私保护、安全加密技术的分布式机器学习框架,旨在让分散的各参与方在满足不向其他参与者披露隐私数据的前提下,协作进行机器学习的模型训练
经典联邦学习框架的训练过程可以简单概括为以下步骤:
- 协调方建立基本模型,并将模型的基本结构与参数告知各参与方;
- 各参与方利用本地数据进行模型训练,并将结果返回给协调方;
- 协调方汇总各参与方的模型,构建更精准的全局模型,以整体提升模型性能和效果。
联邦学习框架包含多方面的技术,比如传统机器学习的模型训练技术、协调方参数整合的算法技术、协调方与参与方高效传输的通信技术、隐私保护的加密技术等。此外,在联邦学习框架中还存在激励机制,数据持有方均可参与,收益具有普遍性。
联邦学习的架构分为两种,一种是中心化联邦(客户端/服务器)架构,一种是去中心化联邦(对等计算)架构。
针对联合多方用户的联邦学习场景,一般采用的是客户端/服务器架构,企业作为服务器,起着协调全局模型的作用;
而针对联合多家面临数据孤岛困境的企业进行模型训练的场景,一般可以采用对等架构,因为难以从多家企业中选出进行协调的服务器方。
联邦学习的优势与前景
分布式机器学习框架通过集中收集数据,再将数据进行分布式存储,将任务分散到多个CPU/GPU机器上进行处理,从而提高计算效率。与之不同的是,联邦学习强调将数据一开始就保存在参与方本地,并且在训练过程中加入隐私保护技术,拥有更好的隐私保护特性。
各参与方的数据一直保存在本地,在建模过程中,各方的数据库依然独立存在,而联合训练时进行的参数交互也是经过加密的,各方通信时采用严格的加密算法,难以泄露原始数据的相关信息,因而联邦学习保证了数据的安全与隐私。
此外,联邦学习技术可使分布式训练获得的模型效果与传统中心式训练效果相差无几,训练出的全局模型几乎是无损的,各参与方能够共同获益。
在大数据与人工智能快速发展的当下,联邦学习解决了人工智能模型训练中各方数据不可用、隐私泄露等问题,因而应用前景十分广阔。联邦学习可用于在海量数据集下的模型训练,实现部门、企业及组织之间的联动。例如:
-
在智慧金融领域中,可以根据多方数据建立更准确的业务模型,从而实现合理定价、定向业务推广、企业风控评定等;
-
在智慧城市中,实现各政府机构之间、企业与政府之间的联合,实现更准确的实时交通预测,更简化的机关办事步骤,更高效的信息内容查询,更全面的安全防控检测等;
-
在智慧医疗中,联邦学习可以综合各医院之间的数据,提高医疗影像诊断的准确性,预警病人的身体情况等。
https://blog.csdn.net/zw0Pi8G5C1x/article/details/116810484