R:热图解释 | pheatmap包参数及详细聚类图绘制流程(一篇解决热图绘制问题)
热图解释及pheatmap绘制热图
- 一、热图绘制原理
-
- 1.1 热图介绍
- 1.2 热图绘制准备——均一化
- 1.3 热图绘制方式
- 1.4 热图数据查看示例
- 二、pheatmap包简介
-
- 2.1 pheatmap介绍
- 2.2 pheatmap详细参数解释
- 2.3 pheatmap安装及加载
- 三、pheatmap包绘制热图示例
-
- 3.1 数据准备
- 3.2 数据导入及绘图
-
- 3.2.1 数据导入及列名调整
- 3.2.2 热图绘制
-
- 3.2.2.1 基础热图及其标准化
- 3.2.2.2 热图聚类及聚类树高和聚类热图划分隔断
- 3.2.2.3 热图单元格显示参数设置
-
- 3.2.2.3.1 热图单元格高度及宽度的设置
- 3.2.2.3.2 热图单元格数值的显示
- 3.2.2.3.3 热图单元格数值大小颜色等参数设置
- 3.2.2.4 热图单元格区分标记
- 3.2.2.5 热图美化
-
- 3.2.2.5.1 标题及行列标签
- 3.2.2.5.2 单元格边框及热图图例
- 3.2.2.5.3 字体及标签角度
- 3.3 特殊绘图——构建分组(注释功能)
-
- 3.3.1 简单分组展示
- 3.3.2 简单纵向分组列及颜色设置
- 3.3.3 多参数——纵向分组列
- 3.3.4 多参数——纵向分组列并修改分组颜色
- 3.4 图片导出
一、热图绘制原理
1.1 热图介绍
通常情况下,热图用来对采集的因子响应强度或其他的一些因素进行归一化,从而利用颜色条的变化来直观地表示不同样本之间的含量变化情况。
其本质是由一个个用预设颜色表示数值大小的小方格组成的一个数据矩阵,并通过对因子或样本进行聚类,从而观察不同样品数据间的相似性。
1.2 热图绘制准备——均一化
绘制热图前,通常会对数据进行归一化操作,以使响应差别较大的因子处于同一个数量级,从而便于观察不同因子在不同样本之间的变化规律。
一般来说,一个因子在不同样本间的分布会在热图的行方向上进行展示,所以为了展示一个因子在不同样本间的分布,均一化处理会按 “row”进行。
详细的热图均一化及聚类参数解释可参考:
用R包中heatmap画热图
1.3 热图绘制方式
常用的绘图软件:origin,excel,Tbtools,GraphPadPrism
在线绘图:metaboanalyst ,云图图,Hiplot
R包绘制热图:pheatmap,heatmap,corrplot,complexHeatmap
满足绘图需求的方式多种多样,关键是选取自己用的顺手,绘图效果满意的那一种并多加练习!
1.4 热图数据查看示例
- 数据排布:横行为对应的化合物数据,纵轴对应的样本数据
图1 数据输入准备 - 按行进行标准化,即对每个样本中的因子分别进行标准化,突出该因子在哪个样本中更占优势
图2 按行进行标准化 - 按列进行标准化,即对每个化合物对应的样本进行标准化。

图3 按列进行标准化
二、pheatmap包简介
2.1 pheatmap介绍
pheatmap:A function to draw clustered heatmaps where one has better control over some graphical parameters such as cell size, etc.

官方介绍:相对于heatmap包,pheatmap是图形绘制及参数修改更美观更严谨的一个热图包。
2.2 pheatmap详细参数解释
R中pheatmap包的参数内容如下:
pheatmap(mat, color = colorRampPalette(rev(brewer.pal(n = 7, name =
"RdYlBu")))(100), kmeans_k = NA, breaks = NA, border_color = "grey60",
cellwidth = NA, cellheight = NA, scale = "none", cluster_rows = TRUE,
cluster_cols = TRUE, clustering_distance_rows = "euclidean",
clustering_distance_cols = "euclidean", clustering_method = "complete",
clustering_callback = identity2, cutree_rows = NA, cutree_cols = NA,
treeheight_row = ifelse((class(cluster_rows) == "hclust") || cluster_rows,
50, 0), treeheight_col = ifelse((class(cluster_cols) == "hclust") ||
cluster_cols, 50, 0), legend = TRUE, legend_breaks = NA,
legend_labels = NA, annotation_row = NA, annotation_col = NA,
annotation = NA, annotation_colors = NA, annotation_legend = TRUE,
annotation_names_row = TRUE, annotation_names_col = TRUE,
drop_levels = TRUE, show_rownames = T, show_colnames = T, main = NA,
fontsize = 10, fontsize_row = fontsize, fontsize_col = fontsize,
angle_col = c("270", "0", "45", "90", "315"), display_numbers = F,
number_format = "%.2f", number_color = "grey30", fontsize_number = 0.8
* fontsize, gaps_row = NULL, gaps_col = NULL, labels_row = NULL,
labels_col = NULL, filename = NA, width = NA, height = NA,
silent = FALSE, na_col = "#DDDDDD", ...)
参数解释:
| mat | 用于绘制热图的数据集 |
|---|---|
| color | 表示热图颜色,colorRampPalette(rev(brewer.pal(n = 7, name = “RdYlBu”)))(100)表示颜色渐变调色板,“n” 的数量取决于调色板中颜色的数量,“name” 为调色板的名称,(100)表示100个等级;color = colorRampPalette(c(“blue”, “white”, “red”))(100)则是通过设置三种不同的颜色进行渐变显示 |
| scale | 表示进行均一化的方向,值为 “row”, “column” 或者"none" |
| kmeans_k | 默认为NA,即不会对行进行聚类;如果想在进行层次聚类之前,先对行特征(因子)进行 k-means 聚类,则可在此调整热图的行聚类数 |
| cluster_rows | 表示仅对行聚类,值为TRUE或FALSE |
| cluster_cols | 表示仅对列聚类,值为TRUE或FALSE |
| clustering_distance_rows | 表示行聚类使用的度量方法,默认为欧式距离“euclidean”,也可选用其他度量方法,如可选用 "correlation"表示按照 Pearson correlation方法进行聚类 |
| clustering_distance_cols | 表示列聚类使用的度量方法,与行聚类的度量方法一致 |
| clustering_method | 表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’ |
| clustering_callback | 修饰聚类的回调函数,默认为 “identity2” |
| cutree_rows | 若进行了行聚类,根据行聚类数量分隔热图行 |
| cutree_cols | 若进行了列聚类,根据列聚类数量分隔热图列 |
| treeheight_row | 若进行了行聚类,其热图行的聚类树高度,默认为 “50” |
| treeheight_col | 若进行了列聚类,其热图列的聚类树高度,默认为 “50” |
| breaks | 用来定义数值和颜色的对应关系,默认为 “NA” |
| border_color | 表示热图每个小的单元格边框的颜色,默认为 “NA” |
| cellwidth | 表示单个单元格的宽度,默认为 “NA”,即根据窗口自动调整 |
| cellheight | 表示单个单元格的高度,默认为 “NA”,即根据窗口自动调整 |
| fontsize | 表示热图中字体大小 |
| fontsize_row | 表示行名字体大小,默认与fontsize一致 |
| fontsize_col | 表示列名字体大小,默认与fontsize一致 |
| fontsize_number | 表示热图上显示数字的字体大小 |
| angle_col | 表示列标签的角度,可选择 “0”,“45”,“90”,“270”,“315” |
| display_numbers | 表示是否在单元格上显示原始数值或按照特殊条件进行区分标记 |
| number_format | 表示热图单元格上显示的数据格式,如 “%.2f” 表示两位小数; “%.1e” 表示科学计数法 |
| number_color | 表示热图单元格上显示的数据字体颜色 |
| legend | 表示是否显示图例,值为TRUE或FALSE |
| legend_breaks | 表示图例断点的设置,默认为NA |
| legend_labels | 表示图例断点的标签 |
| annotation_row | 表示是否对行进行注释 |
| annotation_col | 表示是否对列进行注释 |
| annotation_colors | 表示行注释及列注释的颜色 |
| annotation_legend | 表示是否显示注释的图例信息 |
| annotation_names_row | 表示是否显示行注释的名称 |
| annotation_names_col | 表示是否显示列注释的名称 |
| show_rownames | 表示是否显示行名 |
| show_colnames | 表示是否显示列名 |
| main | 表示热图的标题名字 |
| gaps_row | 仅在未进行行聚类时使用,表示在行方向上热图的隔断位置,如 gaps_row = c(2, 4)表示在第2与第4列进行隔断 |
| gaps_col | 仅在未进行列聚类时使用,表示在列方向上热图的隔断位置,同 gaps_row |
| labels_row | 表示使用行标签代替行名 |
| labels_col | 表示使用列标签代替列名 |
| filename | 表示保存图片的位置及命名 |
| width | 表示输出绘制热图的宽度 |
| height | 表示输出绘制热图的高度 |
| silent | 表示不绘制热图 |
| margins | 表示热图距画布的空白距离 |
注:
- colorRampPalette()需要调用R包**RColorBrewer_colors**,包括 “Blues BuGn BuPu GnBu Greens Grays Oranges OrRd PuBu PuBuGn PuRd Purples RdPu Reds YlGn YlGnBu YlOrBr YlOrRd” 连续调色板;
- 标准化解释;
- kmeans_k聚类解释;
- "annotation_row"与"annotation_col"对行列进行注释时,要求数据格式为数据框,并且绘制热图时需要考虑设置颜色值的类型(连续值或离散值);
- 参数解释参考;
2.3 pheatmap安装及加载
通过以下代码安装并加载R包。
install.packages("pheatmap") # 安装包
install.packages("xlsx") # 安装包
library(pheatmap) #加载包
library(xlsx) #加载包
三、pheatmap包绘制热图示例
3.1 数据准备
随机准备数据如图4,横行代表样本,列代表因子。
存储为 “.xlsx”格式。
图4 数据准备
3.2 数据导入及绘图
3.2.1 数据导入及列名调整
按照以下代码输入数据,并赋给 “data1”:
# 数据导入
data1 <- read.xlsx("D:\\**自己的路径**\\R\\sample data.xlsx", sheetIndex = 1, check.names = F, encoding="UTF-8")
# sheetIndex表示选择.xlsx文件中的第1个sheet,可用于多个sheet的表格数据选择;check.names = F适用于表头存在一些特殊字符(_等)的情况,避免输入R后产生错误
数据输入后如图5所示,需要将第一列的列名位置进行调换,否则会因为 “NA” 而报错,报错内容如下:
Error in hclust(d, method = method) : 外接函数调用时不能有NA/NaN/Inf(arg10)
图5 数据输入
列名调整代码:
rownames(data1) = data1[,1] #给data1添加列名
data1 <- data1[,-1] #去除第一列的名称
data1 <- as.matrix(data1)
图6 列名调整后数据
3.2.2 热图绘制
3.2.2.1 基础热图及其标准化
使用以下代码绘制基础热图:
pheatmap(data1) #绘制基础热图
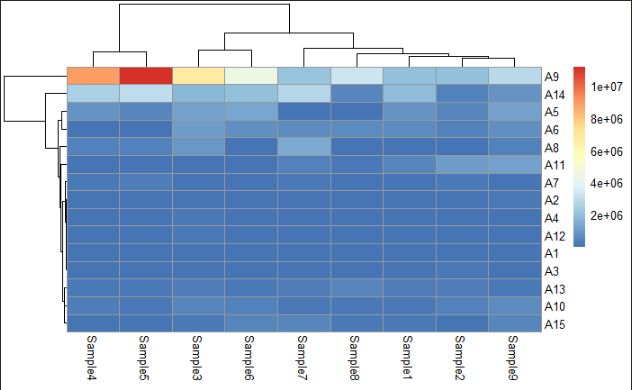
图7 基础热图
对行进行归一化化后绘图:
pheatmap(data1,
scale = "row" # 按行归一化
)
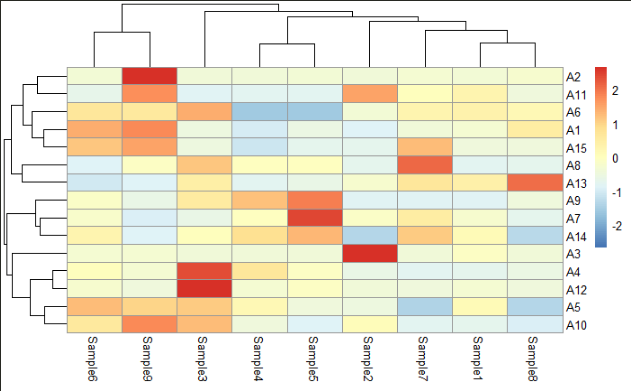
图8 标准化后热图
3.2.2.2 热图聚类及聚类树高和聚类热图划分隔断
按行选择 “correlation” 方法进行聚类绘图,并设置聚类高度以及按行隔断热图:
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3 #根据样品列聚类情况将热图的行方向隔开为3份
)
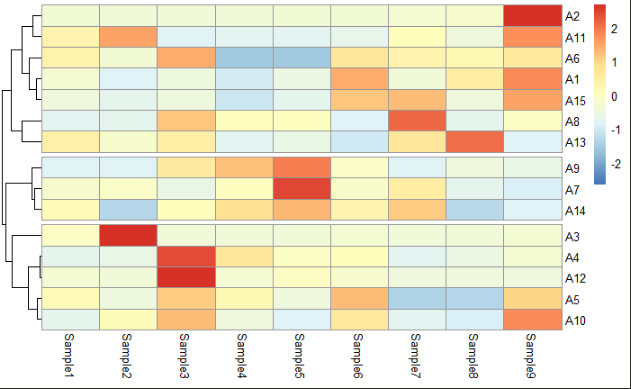
图9 聚类并调整参数后的热图
3.2.2.3 热图单元格显示参数设置
3.2.2.3.1 热图单元格高度及宽度的设置
利用 “cellwidth” 与 “cellheight” 设置热图单元格的宽度和高度:
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15 # 设置热图单元格宽度和高度
)
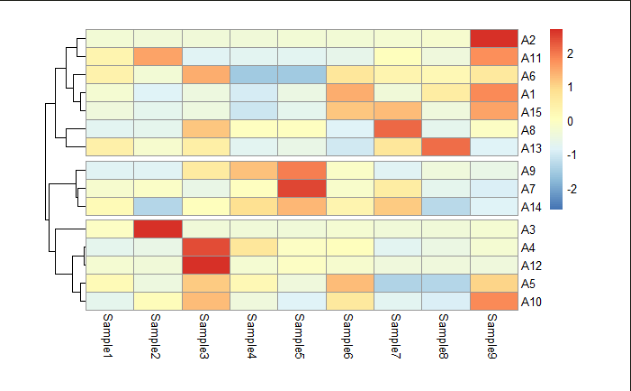
图10 设置单元格宽度与高度之后的热图
3.2.2.3.2 热图单元格数值的显示
使用 “display_numbers” 参数设定是否在单元格上显示数值。
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图单元格宽度和高度
display_numbers = T # 热图上显示数值
)
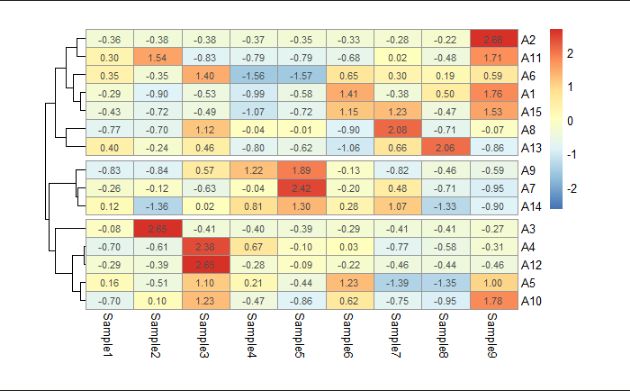
图11 设置热图单元格显示数据
3.2.2.3.3 热图单元格数值大小颜色等参数设置
使用 “fontsize_number”、“number_color”、“number_format” 等参数设置热图单元格上数值的大小及颜色等。
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图单元格宽度和高度
display_numbers = T, # 热图上显示数值
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
)

图12 设置热图单元格显示数据的大小,颜色及类型
3.2.2.4 热图单元格区分标记
同样是使用 “display_numbers” 根据热图单元格的数值进行标记,若该单元格原始数值大于5000,则为 “***”,否则为 " ":
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图单元格宽度和高度
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1))
)
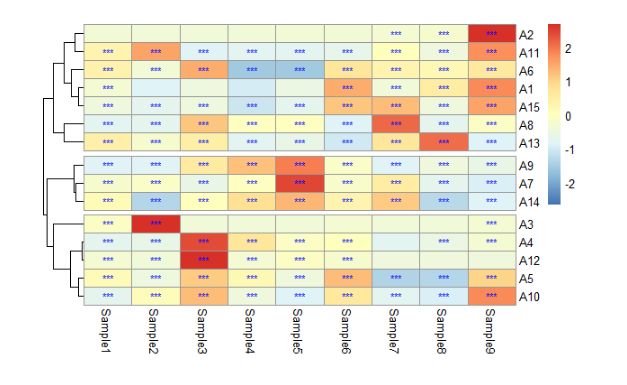
图13 设置热图单元格区分标记
3.2.2.5 热图美化
3.2.2.5.1 标题及行列标签
使用 “main” ,“show_colnames”,“show_rownames” 添加标题及设置标签的显示:
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图单元格宽度和高度
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #热图区块标记
show_colnames = FALSE, # 设置行列标签的显示
show_rownames = FALSE
)
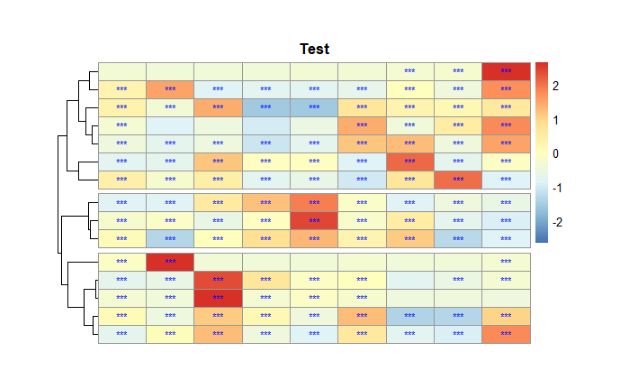
图14 设置热图标题及行列标签的显示
3.2.2.5.2 单元格边框及热图图例
使用 “border” 与 “legend” 设置热图单元格边框颜色及是否显示图例:
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图方块宽度和高度
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = FALSE, # 设置行列标签的显示
show_rownames = FALSE,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5) # 设置图例的范围
)
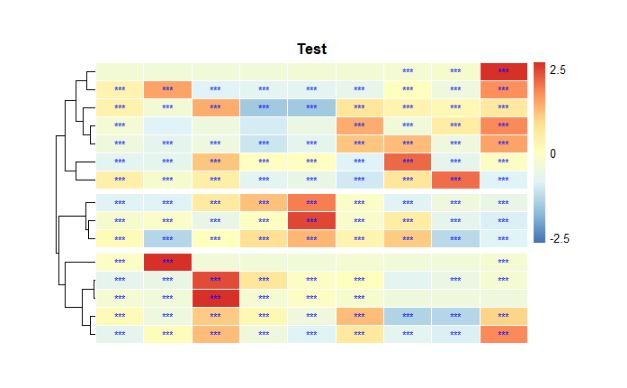
图15 设置热图单元格边框及图例的显示
3.2.2.5.3 字体及标签角度
使用 “angle_col” 设置标签的显示角度;
使用 “fondsize” 可以同一设置热图中字体的大小;
使用 “fontsize_row” 与 “fontsize_row” 可以分别设置行列标签字体的大小:
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图方块宽度和高度
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = T, # 设置行列标签的显示
show_rownames = T,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5), # 设置图例的范围
fontsize_row = 10, # 分别设置行列标签字体大小
fontsize_col = 10,
angle_col = 45, # 设置标签显示角度
)
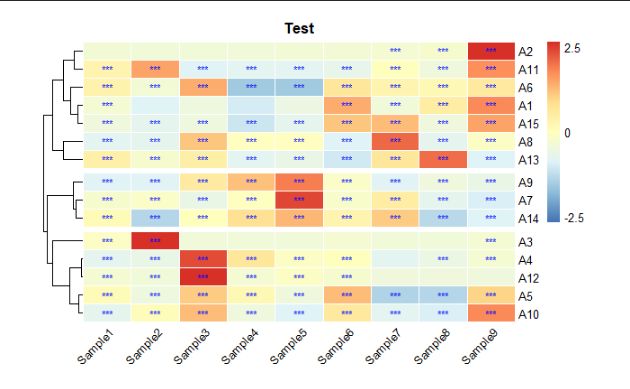
图16 设置热图字体及标签显示角度
3.3 特殊绘图——构建分组(注释功能)
在以上介绍中,只是基于 “pheatmap” 这个包的各项参数来修改绘图参数和展示方式,当需要同时在热图上显示分组情况时,可通过构建分组信息,从而以不同的颜色等方式来展现。
3.3.1 简单分组展示
按照下面代码,首先创建分组列,并定义分组的颜色,绘图结果如图17所示。
annotation_col = data.frame(Sample=factor(c(rep("M1",1),rep("M2",1),rep("M3",1),rep("M4",1),rep("M5",1),rep("M6",1),rep("M7",1),rep("M8",1),rep("M9",1))))#创建分组列
row.names(annotation_col) = colnames(data1) #这一行必须有,否则会报错:Error in check.length("fill") : 'gpar' element 'fill' must not be length 0
ann_colors = list(Sample = c(M1="#E889BD", M2="#B286D7", M3="#5189E0", M4="#0089CF", M5="#0081A1", M6="#007360", M7="#E889BD", M8="#B286D7", M9="#5189E0")) #定义分组颜色
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图方块宽度和高度
#display_numbers = T, # 热图上显示数值
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
#display_numbers = matrix(ifelse(data1 > 2, "+", "-"), nrow(data1))
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = T, # 设置行列标签的显示
show_rownames = T,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5), # 设置图例的范围
fontsize_row = 10, # 分别设置行列标签字体大小
fontsize_col = 10,
angle_col = 45, # 设置标签显示角度
annotation_col = annotation_col, #显示样品列的分组信息及图例
annotation_colors = ann_colors, #使用annotation_colors参数设定样品列分组的颜色
#filename = "text.pdf" # 自动保存到设置路径下
)
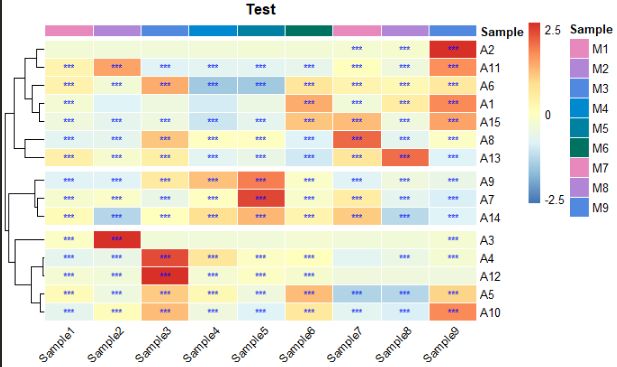
图17 简单分组列展示
3.3.2 简单纵向分组列及颜色设置
当每个样品分组包含多个样品列,并设置分组颜色时,按如下代码,结果如图18所示。
annotation_col = data.frame(Sample=factor(c(rep("group1",3),rep("group2",3),rep("group3",3))))
row.names(annotation_col) = colnames(data1) #这一行必须有,否则会报错:Error in check.length("fill") : 'gpar' element 'fill' must not be length 0
ann_color <- list(a<-c(group1="blue", group2="red", group3="green"))
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 38,cellheight = 15, # 设置热图方块宽度和高度
#display_numbers = T, # 热图上显示数值
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
#display_numbers = matrix(ifelse(data1 > 2, "+", "-"), nrow(data1))
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = T, # 设置行列标签的显示
show_rownames = T,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5), # 设置图例的范围
fontsize_row = 10, # 分别设置行列标签字体大小
fontsize_col = 10,
angle_col = 45, # 设置标签显示角度
annotation_col = annotation_col, #显示样品列的分组信息及图例
annotation_colors = ann_color, #使用annotation_colors参数设定样品列分组的颜色
#filename = "text.pdf" # 自动保存到设置路径下
)
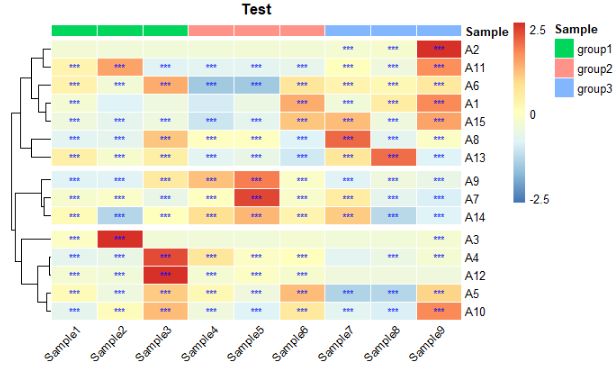
图18 分组展示并修改颜色
3.3.3 多参数——纵向分组列
以本例数据进行参考说明,sample 1-9 共9列样品,其中每3列划分为1组,构建分组信息(包含3个处理,分别是:group1 (sample1-3)、group2 (sample4-6)和group3 (sample7-9)),以及对应的采样时间:Time1, Time2, Time3。,绘图结果如图19所示。
annotation_cols = data.frame(Sample=factor(rep(c("group1","group2","group3"),3)), Time=factor(rep(c("March","July","December"),3)))#创建纵向分组列
row.names(annotation_col) = colnames(data1) #这一行必须有,否则会报错:Error in check.length("fill") : 'gpar' element 'fill' must not be length 0
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 38,cellheight = 15, # 设置热图方块宽度和高度
#display_numbers = T, # 热图上显示数值
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
#display_numbers = matrix(ifelse(data1 > 2, "+", "-"), nrow(data1))
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = T, # 设置行列标签的显示
show_rownames = T,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5), # 设置图例的范围
fontsize_row = 10, # 分别设置行列标签字体大小
fontsize_col = 10,
angle_col = 45, # 设置标签显示角度
annotation_col = annotation_cols, #显示样品列的分组信息及图例
#filename = "text.pdf" # 自动保存到设置路径下
)

图19 纵向分组列
3.3.4 多参数——纵向分组列并修改分组颜色
如图19所示,分组会按默认的颜色进行显示,当需要设定具体的分组颜色时,可按下代码进行,如图20所示。
annotation_col = data.frame(Sample=factor(rep(c("group1","group2","group3"),3)),Time=factor(rep(c("March","July","December"),3)))
row.names(annotation_col) = colnames(data1) #这一行必须有,否则会报错:Error in check.length("fill") : 'gpar' element 'fill' must not be length 0
ann_colors <- list(
Sample = c(group1 = "blue", group2 = "red", group3 = "green"),
Time = c(March = "orange", July = "purple", December = "yellow")
)
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 38,cellheight = 15, # 设置热图方块宽度和高度
#display_numbers = T, # 热图上显示数值
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
#display_numbers = matrix(ifelse(data1 > 2, "+", "-"), nrow(data1))
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = T, # 设置行列标签的显示
show_rownames = T,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5), # 设置图例的范围
fontsize_row = 10, # 分别设置行列标签字体大小
fontsize_col = 10,
angle_col = 45, # 设置标签显示角度
annotation_col = annotation_col, #显示样品列的分组信息及图例
annotation_colors = ann_colors, #使用annotation_colors参数设定样品列分组的颜色
#filename = "text.pdf" # 自动保存到设置路径下
)
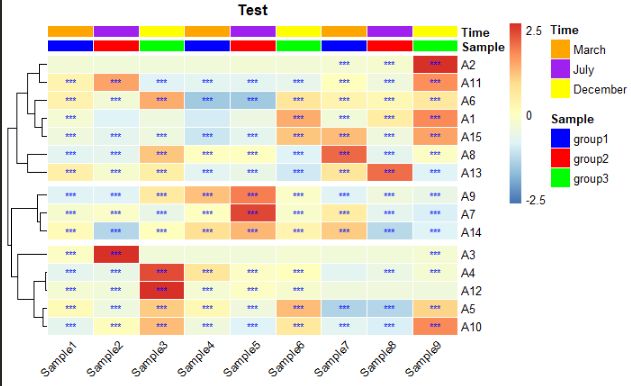
图20 多参数分组及颜色设置
基于以上四组分组创建情况,可利用 “annotation_row”添加横向分组,并设置颜色。
3.4 图片导出
保存格式包括pdf/jpeg/png格式,通过改变后缀的形式实现;
建议保存为pdf/jpeg格式,因为二者清晰度较高;
笔者喜欢pdf格式,便于利用AI等软件进行修饰。
pheatmap(data1,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", #取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =3, #根据样品列聚类情况将热图的行方向隔开为3份
cellwidth = 40,cellheight = 15, # 设置热图方块宽度和高度
#display_numbers = T, # 热图上显示数值
fontsize_number = 8, #热图上数值的字体大小
number_color="blue", #热图上数值的字体颜色
number_format="%.1e", #热图上数值的字体类型
#display_numbers = matrix(ifelse(data1 > 2, "+", "-"), nrow(data1))
display_numbers = matrix(ifelse(data1 > 5000, "***", ""), nrow(data1)), #设置热图区分标记
main="Test", # 设置图形标题
show_colnames = T, # 设置行列标签的显示
show_rownames = T,
border="white", # 设置边框为白色
legend = T, # FALSE去除图例; T显示图例
legend_breaks=c(-2.5,0,2.5), # 设置图例的范围
fontsize_row = 10, # 分别设置行列标签字体大小
fontsize_col = 10,
angle_col = 45, # 设置标签显示角度
filename = "text.pdf" # 自动保存到设置路径下
)
图21 保存图片
以上为关于 “pheatmap” 整理的全部内容,希望对大家有所帮助!
报错内容:
使用下列方式输入代码命名颜色时,利用pheatmap包是不会变更颜色的。
ann_color <- list(a<-c(DRY="yellow", WET="firebrick"))
正确的书写方式:
ann_colors = list(Sample = c(M1="#E889BD", M2="#B286D7", M3="#5189E0", M4="#0089CF", M5="#0081A1", M6="#007360" ))
使用以下代码时,只有行可以划分为3部分,而列不能,大概是因为未对列进行聚类,使用gaps_col可对为聚类列进行隔断显示。
cutree_rows=3,
cutree_cols=6,
gaps_col = 3,
关于分组的报错内容可参考:Error in convert_annotations(annotation_col, annotation_colors) :
Factor levels on variable Time do not match with annotation_colors
其他参考内容:
R语言绘制热图实践(一)pheatmap包
超详细的热图绘制教程(5000余字),真正的保姆级教程
pheatmap热图技巧合集
pheatmap()条件分组中的故障以及其他混淆点