目标检测SSD算法(新手入门)
SSD分析
- SSD背景
- SSD Framework
- CNN-based detector
- SSD的backbone:VGG16
- SSD Model
- L2Norm
- 先验框
- 多尺度对SSD的影响
- 定位、分类
- 小结
- 问题
SSD算法是比较经典的目标检测算法,讲解SSD的博客有很多,比如目标检测之SSD就讲的非常好。
本篇博客的不同之处在于,我当时整理学习SSD的时候相对小白一点,遇到什么不太清楚的查阅的东西比较多一些。除了讲解SSD,也分析了一些SSD和YOLO等算法的差别,以及从实际应用、部署的角度来看SSD。
在此把当时记录的东西整理出来分享给大家。文中参考了很多人的博客、知乎、帖子,很惭愧当时没有记录下来。
SSD背景
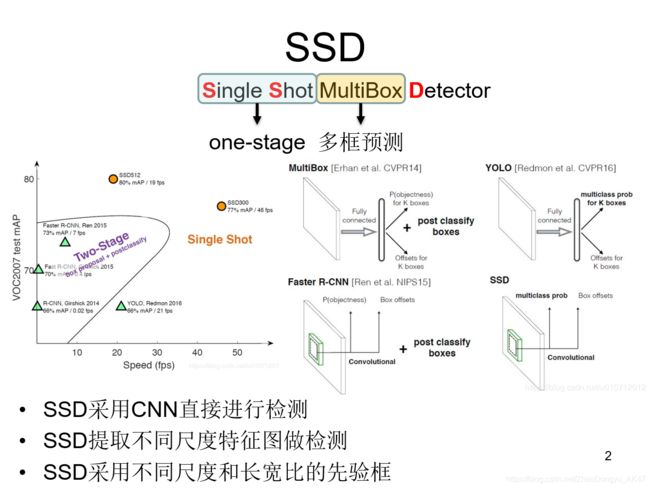
SSD算法,其英文全名是Single Shot MultiBox Detector,名字取得不错,Single shot指明了SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测。
-
看左图,SSD算法在准确度和速度(除了SSD512)上都比Yolo要好很多(当时)
-
右图是不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。
相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,
- 一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;
- 二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。
SSD Framework
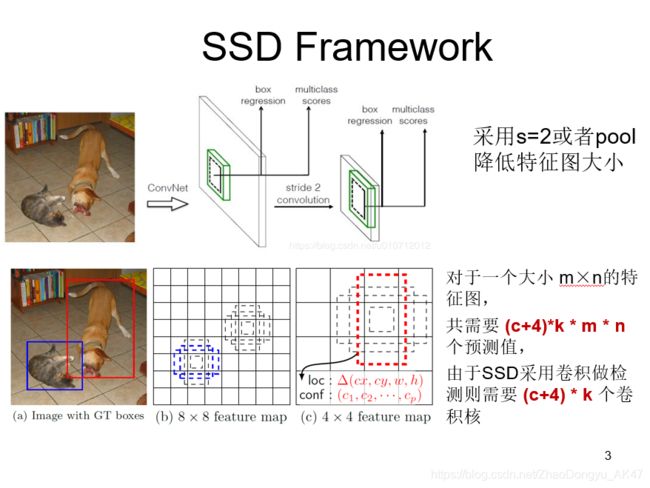
CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小(比如YOLOV3不用pool,全部用stride=2的卷积)
这正如上图所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标。
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。
而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练。
值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 c 个类别,SSD其实需要预测 c+1 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 c 个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 c-1 个。
CNN-based detector

从网络结构的角度,基于cnn的检测器可以分为主干部分和检测部分。
- 在主干部分,最先进的检测器(state-of-the-art detectors)倾向于大型分类网络和大型图像输入,这样精度高,但是这需要大量的计算成本。
- 检测部分分两种,two-stage和one-stage,一般情况下,two-stage算法在准确度上有优势,而one-stage算法在速度上有优势。
然而,图像分类与目标检测之间存在着一些差异,如:目标检测需要较大的感受野和低层次特征来提高定位能力,但这对于图像分类来说不是很重要。
这种差距限制了backbone在目标检测方面的性能,并且阻碍了进一步的压缩(在不影响检测精度的前提下)。
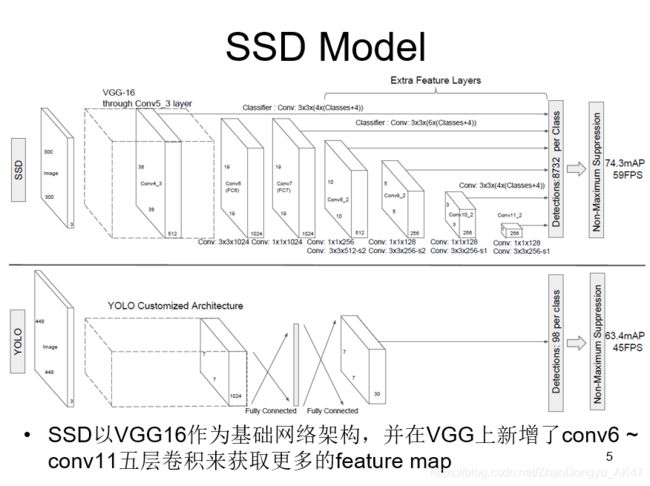
A comparison between two single shot detection models: SSD and YOLO [5].
Our SSD model adds several feature layers to the end of a base network, which predict the offsets to default boxes of different scales and aspect ratios and their associated confidences. SSD with a 300 300 input size significantly outperforms its 448 448 YOLO counterpart in accuracy on VOC2007 test while also improving the speed
SSD的backbone:VGG16


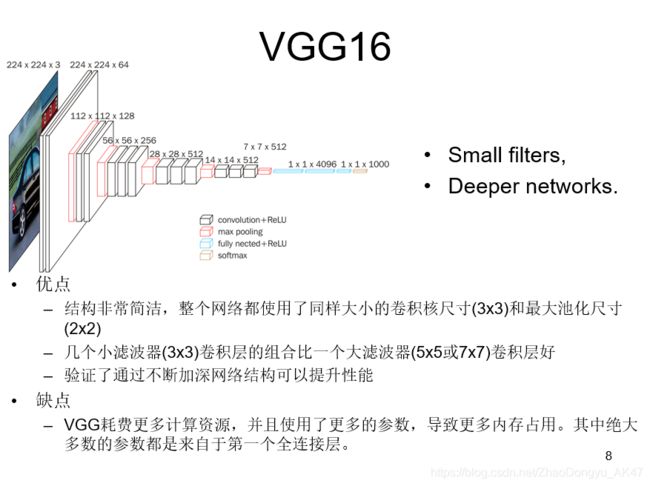
VGG中根据卷积核大小和卷积层数目的不同,可分为A,A-LRN,B,C,D,E共6个配置(ConvNet Configuration),其中以D,E两种配置较为常用,分别称为VGG16和VGG19。
我们针对VGG16进行具体分析发现,VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)
每一个block内包含若干卷积层和一个池化层。并且同一块内,卷积层的通道(channel)数是相同的,例如:
- block2中包含2个卷积层,每个卷积层用conv3-128表示,即卷积核为:3x3x3,通道数都是128
VGG的输入图像是 224x224x3 的图像张量(tensor),随着层数的增加,后一个块内的张量相比于前一个块内的张量:
- 通道数翻倍,由64依次增加到128,再到256,直至512保持不变,不再翻倍
- 高和宽变减半,由 224→112→56→28→14→7
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。

图中蓝色是计算权重参数数量的部分;红色是计算所需存储容量的部分。
可以看到,全连接层是它的硬伤。
那么,SSD做了哪些改进呢?
SSD Model
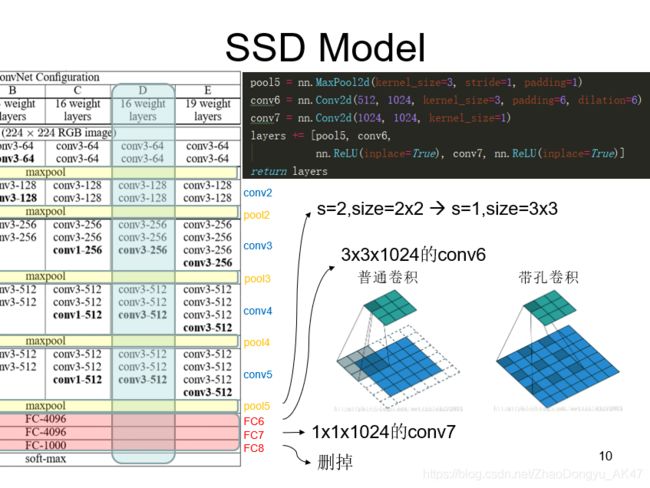
- pool5为了不减少feature map size,由s=2,size=2x2变为s=1,size=3x3。
- 为了配合变化,conv6采用带孔卷积,扩张率是6x6
- 去掉block6后的dropout
带孔卷积就是在不增加参数量和model复杂度的情况下扩大卷积的感受域
在不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息
带孔卷积并不是卷积核里带孔,而是在卷积的时候,跳着的去卷积map
L2Norm

SSD其中有一层用到了L2Norm。该层比较靠前,norm较大。
如果只是单纯地对所有输入层进行归一化,不仅会减慢网络的训练速度,同时也会改变该层的尺度。因此,还需要对其增加一个尺度参数gamma,将归一化的结果进行尺度缩放
这一过程增加的参数量等于所有的通道数之和,因此在反向传播过程中是可以忽略的。
这个L2Norm在作者的ParseNet里面有介绍——
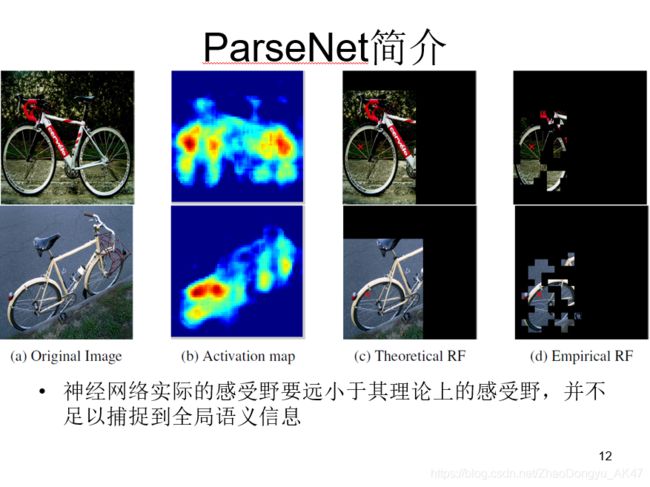
这是一个做语义分割的卷积神经网络。其中最重要的一个操作就是加入全局信息就改善了分割结果
对于CNN来说,由于池化层的存在,卷积核的感受野(Receptive Field)可以迅速地扩大,对于最顶层的神经元,其感受野通常能够覆盖整个图片。
例如对于VGG的fc7层,其理论上的感受野有404404大小,而输入的图像也不过224224,似乎底层的神经元是完全有能力去感知到整个图像的全部信息。但事实却并不是这样的。
上图分别为 图像、热图、理论感受野和实际感受野
作者做了这样一个实验,即破坏图像中一个随机区域中的信息,以此来观察网络的输出结果是否依赖于这个区域。
- (a)是原图,(b)是某个神经元输出的Activation map,文章对原图上滑动一个窗口,对这个窗口内部的图像加入随机噪声并观察加噪声后该神经元的输出是否有较大的变化,当产生较大变化时,代表这个神经元可以感受到这部分图像,并由此得到实际的感受野,如图(d)所示。经过实验发现,实际感受野只有原图的约1*/4大小。
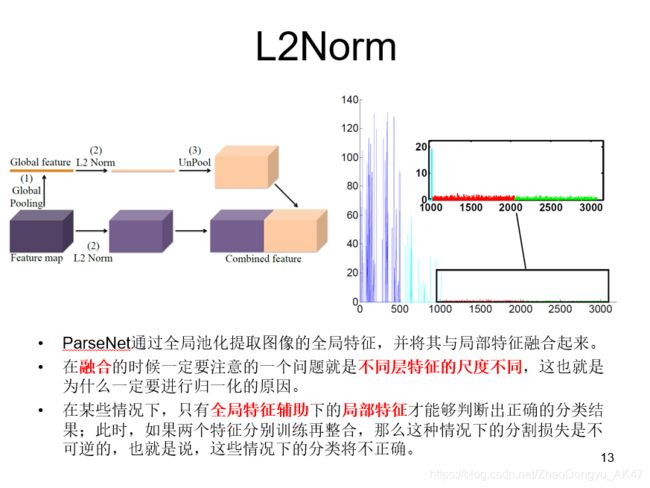
来自4个不同层的特性具有非常不同的激活规模。
每种颜色对应于不同的层的特征。
当蓝色和青色在一个可比较的尺度上时,红色和绿色的特征在一个数量级上要小2个数量级。
这张图的四种颜色代表了从四个不同深度的卷积层中提取出的特征向量,可以看到底层和顶层特征向量的尺度会有很大的差别,如果不进行归一化,高层的特征几乎都会被底层的大尺度特征向量所覆盖,无法对分类造成影响。
所以,SSD在conv4-3做了一个L2Norm以便于高效的融合。
先验框
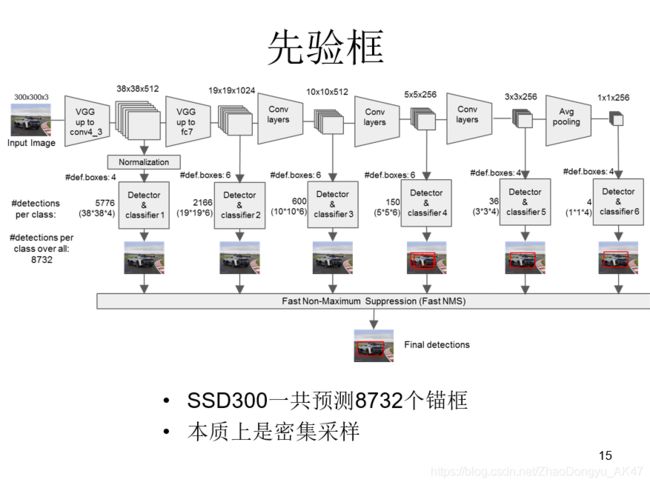
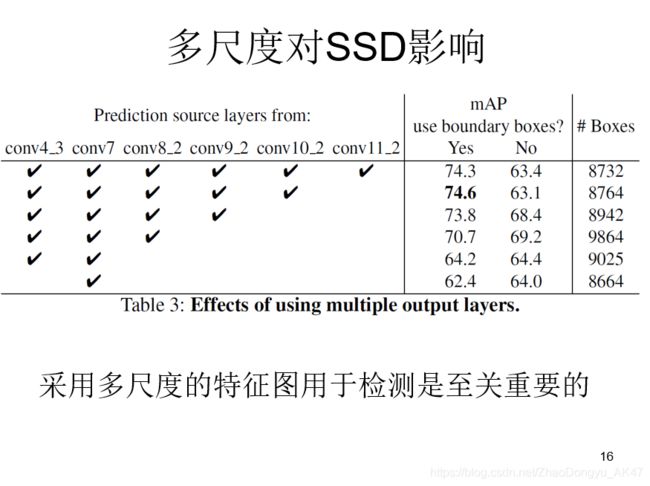
提取的feature map分别为(38,38)(19,19)(10,10)(5,5)(3,3)(1,1) 4,6,6,6,4,4
conv4feature map 38x38 每个像素点生成4个锚框,38x38x4
这么算下来,一共8732个锚框,所以SSD其实也是一个密集采样。
在这里,注意到SSD的特征来源,可以考虑一个问题——yolov3为什么比ssd好?
不仅仅因为YOLO V3引入FPN结构,同时它的检测层由三级feature layers融合,而SSD的六个特征金字塔层全部来自于FCN的最后一层,其实也就是一级特征再做细化,明显一级feature map的特征容量肯定要弱于三级,尤其是浅层包含的大量小物体特征。
多尺度对SSD的影响
定位、分类
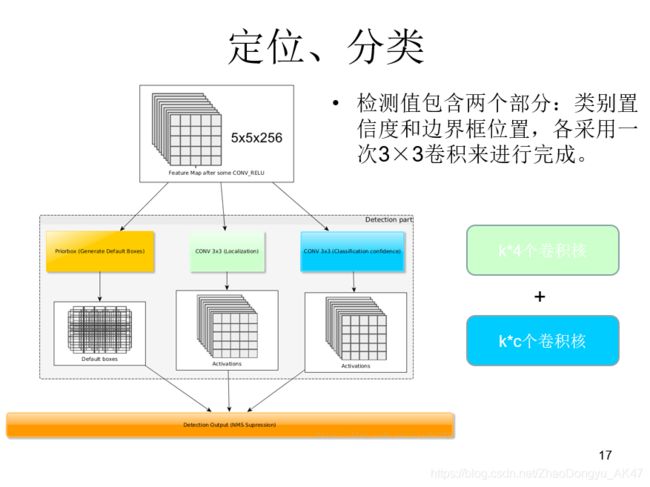
检测值包含两个部分:类别置信度和边界框位置,各采用一次卷积来进行完成。
令 n_k 为该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为 nk×c,而边界框位置需要的卷积核数量为 nk×4。
SSD使用3x3卷积核进行分类和回归,而MTCNN使用1x1卷积核进行分类和回归,3x3的卷积核覆盖了该像素点的感受野以及它的领域,加入了局部信息,使得模型更加鲁棒。
小结
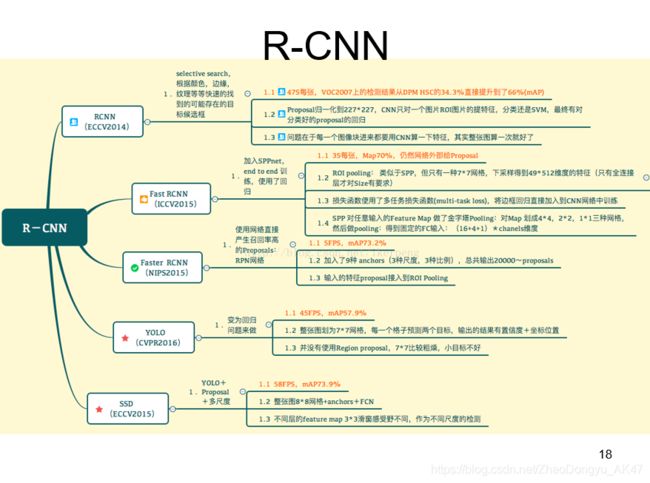
SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster-RCNN一样比较精准。
问题



但是SSD因为结构简单,部署起来应该更友好一些


实线框是ground truth的目标物体框,可见SNIPER试图把ground truth都圈围在重点关注区域的合适尺度下。此外,SNIPER还在重点关注区域中加入了重点排除区域,在许多背景中,许多目标是无须识别的
其中红色框就是重点排除区域,与FPN不同的是,SNIPER不再需要处理每一层特征图的像素进行上采样,计算量下降了不少,据说只比普通的类似yolo的one shot模型多处理30%的像素。
有问题多交流,可留言可发邮件,我的邮箱是zhaodongyu艾特pku(这里换成点)edu.cn。