数据分析之Numpy模块详解
文章目录
-
- 1. 数组的创建
-
- 1. 根据 Python 中的列表生成
- 2. 使用 np.arange 生成
- 3. np.random.random来创建一个N行N列的数组
- 4. np.random.randint来创建一个N行N列的数组
- 5. 使用函数生成特殊的数组
- 2. Numpy数组和Python列表性能对比
- 3. 数组数据类型dtype
- 4. 多维数组的几个常用属性
-
- 1. ndarray.size
- 2. ndarray.ndim
- 3. ndarray.shape
- 4. ndarray.reshape
- 5. ndarray.itemsize
- 小结
- 5. 数组索引和切片
-
- 1. 一维数组的索引和切片
- 2. 多维数组的索引和切片
- 3.数组索引小结
- 4. 布尔索引
- 5. 值的替换
- 6. 练习
- 6. 数组操作
-
- 1. 数组与数的计算
- 2. 数组与数组的计算
-
- 1. 结构相同的数组之间的运算
- 2. 与行数相同并且只有1列的数组之间的运算
- 3. 与列数相同并且只有1行的数组之间的运算
- 3. 数组广播机制
- 4.数组形状的操作
-
- 1. reshape和resize方法
- 2. flatten和ravel方法
- 5. 数组(矩阵)转置和轴对换
- 6. 不同数组的组合
- 7.数组的切割
- 8. 常用的统计函数
- 7. numpy数组的深浅拷贝
- 8. 文件操作
-
- 1.文件保存
- 2.读取文件
- 3. numpy独有的存储解决方案
- 9. 数组操作综合小练习
- 10. NAN和INF值处理
NumPy 是一个功能强大的 Python 库,主要用于对多维数组执行计算。 NumPy 这个词来源于两个单词-- Numerical 和 Python 。 NumPy 提供了大量的库函数和操作,可以帮助程序员轻松地进行数值计算。在数据分析和机器学习领域被广泛使用。它有以下几个特点:
- numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算。
- Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。
- 有一个强大的N维数组对象Array(一种类似于列表的东西)。
- 实用的线性代数、傅里叶变换和随机数生成函数。
中文文档
通过 pip install numpy 即可安装。
Numpy 中的数组的使用跟 Python 中的列表非常类似。他们之间的区别如下:
- 一个列表中可以存储多种数据类型。比如 a = [1,‘sss’] 是允许的,而数组只能存储同种数据类型。
- 数组可以是多维的,当多维数组中所有的数据都是数值类型的时候,相当于线性代数中的矩阵,是可以进行相互间的运算的。
1. 数组的创建
Numpy 经常和数组打交道,因此首先第一步是要学会创建数组。在 Numpy 中的数组的数据类型叫做 ndarray 。数组中的数据类型都是一致的,要么都是整形,要么都是浮点类型,要么都是字符串类型,不能同时出现多种数据类型。
1. 根据 Python 中的列表生成
import numpy as np
a1 = np.array([1,2,3,4])
print(a1) # [1 2 3 4]
print(type(a1)) # 2. 使用 np.arange 生成
np.arange 的用法类似于 Python 中的 range :
a2 = np.arange(2,21,2)
# [ 2 4 6 8 10 12 14 16 18 20]
3. np.random.random来创建一个N行N列的数组
np.random模块用法也挺多的,想多了解的参考
np.random模块用法
其中里面的值是0-1之间的随机数
a1 = np.random.random(2,3) # 生成2行3列的随机数的数组
'''
array([[0.97161017, 0.76910216, 0.19023732],
[0.42920713, 0.85226437, 0.13957804]])
'''
4. np.random.randint来创建一个N行N列的数组
其中值的范围可以通过前面2个参数来指定
d = np.random.randint(0,9,size=(4,4,))
'''
array([[1, 5, 8, 5],
[7, 6, 1, 2],
[3, 7, 8, 7],
[6, 7, 0, 7]])
'''
5. 使用函数生成特殊的数组
- zeros
array_zeros = np.zeros((3,3))
# 生成一个所有元素都是0的3行3列的数组
'''
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
'''
- ones
array_ones = np.ones((4,4))
#生成一个所有元素都是1的4行4列的数组
'''
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
'''
- full
array_full = np.full((2,3),9)
#生成一个所有元素都是9的2行3列的数组
'''
array([[9, 9, 9],
[9, 9, 9]])
'''
4.eye
array_eye = np.eye(4)
#生成一个在斜方形上元素为1,其他元素都为0的4x4的矩阵
'''
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
'''
2. Numpy数组和Python列表性能对比
我们可以测试一下Numpy数组和Python列表性能,比如我们想要对一个Numpy数组和Python列表中的每个数进行求平方:
import numpy as np
import time
# 列表
t1 = time.time()
a = []
for x in range(1000000):
a.append(x**2)
t2 = time.time()
print(t2-t1) # 0.41788268089294434
# numpy数组
t3 = time.time()
b = np.arange(1000000)**2
t4 = time.time()
print(t4-t3)# 0.0029921531677246094
3. 数组数据类型dtype
因为数组中只能存储同一种数据类型,因此可以通过 dtype 获取数组中的元素的数据类型。以下是 ndarray.dtype 的常用的数据类型:
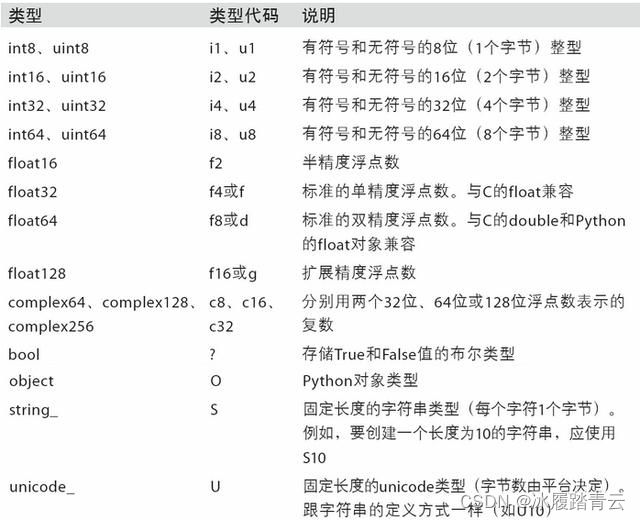
详尽的描述,请看下表:
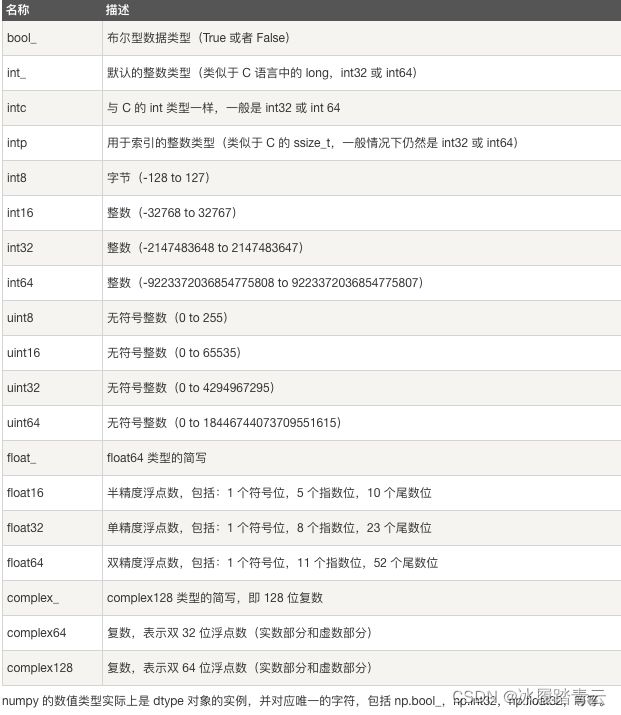
我们可以看到, Numpy 中关于数值的类型比 Python 内置的多得多,那为什么Numpy的数组中有这么多的数据类型呢?因为Numpy本身是基于C语言编写的,C语言中本身就是有很多数据类型,所以直接引用过来了。
Numpy为了考虑到处理海量数据的性能,针对不同的数据给不同的数据类型,来节省内存空间,所以有不同的数据类型。这是 Numpy 为了能高效处理处理海量数据而设计的。举个例子,比如现在想要存储上百亿的数字,并且这些数字都不超过254(一个字节内),我们就可以将 dtype 设置为 int8 ,这样就比默认使用 int64 更能节省内存空间了。类型相关的操作如下:
- 默认的数据类型:
import numpy as np
a1 = np.array([1,2,3])
print(a1.dtype)
# 如果是windows系统,默认是int32
# 如果是mac或者linux系统,则根据系统来
- 指定 dtype :
import numpy as np
a1 = np.array([1,2,3],dtype=np.int64)
print(a1.dtype) # int64
- 修改 dtype :
import numpy as np
a1 = np.array([1,2,3])
print(a1.dtype) # window系统下默认是int32
# 以下修改dtype
a2 = a1.astype(np.int64) # astype不会修改数组本身,而是会将修改后的结果返回
print(a2.dtype)
4. 多维数组的几个常用属性
1. ndarray.size
获取数组中总的元素的个数。比如有个二维数组:
import numpy as np
a1 = np.array([[1,2,3],[4,5,6]])
print(a1.size) #打印的是6,因为总共有6个元素
2. ndarray.ndim
数组的维数。比如:
a1 = np.array([1,2,3])
print(a1.ndim) # 维度为1
a2 = np.array([[1,2,3],[4,5,6]])
print(a2.ndim) # 维度为2
a3 = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(a3.ndim) # 维度为3
3. ndarray.shape
数组的维度的元组。比如以下代码:
import numpy as np
a1 = np.array([1,2,3])
print(a1.shape) # 输出(3,),意思是一维数组,有3个数据
a2 = np.array([[1,2,3],[4,5,6]])
print(a2.shape) # 输出(2,3),意思是二位数组,2行3列
a3 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[7,8,9],
[10,11,12]
]
])
print(a3.shape) # 输出(2,2,3),意思是三维数组,总共有2个元素,每个元素是2行3列的
a4 = np.array([[1,2,3],[4,5]])
print(a4.shape) # 输出(2,),意思是a4是一个一维数组,总共有2列
print(a4) # 输出[list([1, 2, 3]) list([4, 5])],其中最外面层是数组,里面是Python列表
4. ndarray.reshape
我们还可以通过 ndarray.reshape 来重新修改数组的维数。示例代码如下:
import numpy as np
a1 = np.arange(12) # 生成一个有12个数据的一维数组
print(a1) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
a2 = a1.reshape((3, 4)) # 变成一个2维数组,是3行4列的
print(a2)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
'''
a3 = a1.reshape((2, 3, 2)) # 变成一个3维数组,总共有2块,每一块是3行2列的
print(a3)
'''
[[[ 0 1]
[ 2 3]
[ 4 5]]
[[ 6 7]
[ 8 9]
[10 11]]]
'''
a4 = a2.reshape((12,)) # 将a2的二维数组重新变成一个12列的1维数组
print(a4) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
a5 = a2.flatten() # 不管a2是几维数组,都将他变成一个一维数组
print(a5) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
注意, reshape 并不会修改原来数组本身,而是会将修改后的结果返回。如果想要直接修改数组本身,那么可以使用 resize 来替代 reshape 。
5. ndarray.itemsize
ndarray.itemsize表示数组中每个元素占的大小,单位是字节。比如以下代码:
a1 = np.array([1,2,3],dtype=np.int32)
print(a1.itemsize) # 打印4,因为每个字节是8位,32位/8=4个字节
小结
- 数组一般达到3维就已经很复杂了,不太方便计算了,所以我们一般都会把3维以上的数组转换成2维数组来计算。
- 通过ndarray.ndim可以看到数组的维度。
- 通过ndarray.shape可以看到数组的形状(几行几列),shape是一个元组,里面有几个元素代表是几维数组。
- 通过ndarray.reshape可以修改数组的形状。条件只有一个,就是修改后的形状的元素个数必须和原来的个数一致。比如原来是(2,6),那么修改完成后可以变成(3,4),但是不能变成(1,4)。reshape不会修改原来数组的形状,他只会将修改后的结果返回。
- 通过ndarray.size可以看到数组总共有多少个元素。
- 通过ndarray.itemsize可以看到数组中每个元素所占内存的大小,单位是字节。(1个字节=8位)。
5. 数组索引和切片
1. 一维数组的索引和切片
import numpy as np
a1 = np.arange(10)
# 1.1 进行索引操作
print(a1[4]) # 4
# 1.2 进行切片操作
print(a1[4:6])# [4 5]
# 1.3 使用步长
print(a1[::2])# [0 2 4 6 8]
# 1.4 使用负数来作为索引
print(a1[-1]) # 9
2. 多维数组的索引和切片
多维数组的索引和切片也是通过中括号来索引和切片,在中括号中,使用逗号进行分割,逗号前面的是行,逗号后面的是列,如果多维数组中只有一个值,那么这个值就是行。
import numpy as np
a2 = np.random.randint(0,10,size=(4,6))
print(a2)
print('*'*10)
print(a2[0])
print('*'*10)
print(a2[1:3])
print('*'*10)
print(a2[[0,2,3]]) # 获取不连续的几行的数据
print('--'*10)
print(a2[[1,3],[4,4]]) # 花式索引,(1,4)第1行4列,(3,4)3行4列,注意行和列的索引都是从0开始
print('--'*10)
print(a2[1:3,4:6]) # 取1-2行,4-5列之间
'''
[[4 2 0 2 4 0]
[9 5 5 5 7 9]
[2 6 3 0 1 6]
[3 6 9 0 5 4]]
**********
[4 2 0 2 4 0]
**********
[[9 5 5 5 7 9]
[2 6 3 0 1 6]]
**********
[[4 2 0 2 4 0]
[2 6 3 0 1 6]
[3 6 9 0 5 4]]
--------------------
[7 5]
--------------------
[[7 9]
[1 6]]
'''
3.数组索引小结
- 如果数组是一维的,那么索引和切片就是跟python的列表是一样的。
- 如果是多维的(这里以二维为例),那么在中括号中,给两个值,两个值是通过逗号分隔的,逗号前面的是行,逗号后面的是列。如果中括号中只有一个值,那么就是代表的是行。
- 如果是多维数组(这里以二维为例),那么行的部分和列的部分,都是遵循一维数组的方式,可以使用整形,切片,还可以使用中括号的形式,来代表不连续的。比如a[[1,2],[3,4]],那么返回的就是(1,3),(2,4)的两个值。
4. 布尔索引
布尔运算也是矢量的,比如以下代码:
import numpy as np
a1 = np.arange(0,24).reshape((4,6))
print(a1)
print(a1<10) #会返回一个新的数组,这个数组中的值全部都是bool类型
'''
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
[[ True True True True True True]
[ True True True True False False]
[False False False False False False]
[False False False False False False]]
'''
这样看上去没有什么用,假如我现在要实现一个需求,要将 a1 数组中所有小于10的数据全部都提取出来。那么可以使用以下方式实现:
a2 = a1 < 10
# [0 1 2 3 4 5 6 7 8 9]
print(a1[a2]) #这样就会在a1中把a2中为True的元素对应的位置的值提取出来
其中布尔运算可以有 != 、 == 、 > 、 < 、 >= 、 <= 以及 &(与) 和 |(或) 。示例代码如下:
a1 = np.arange(0,24).reshape((4,6))
a2 = a1[(a1 < 5) | (a1 > 10)]
print(a2)
5. 值的替换
利用索引,也可以做一些值的替换。把满足条件的位置的值替换成其他的值。比如以下代码:
a1[3] = 0 # 将第三行的所有值都替换成0
print(a1)
也可以使用条件索引来实现:
a1[a1 < 5] = 0 #将小于5的所有值全部都替换成0
print(a1)
还可以使用函数来实现:
# where函数:
import numpy as np
a1 = np.arange(0,24).reshape((4,6))
a2 = np.where(a1 < 10,1,0) #把a1中所有小于10的数全部变成1,其余的变成0
print(a2)
"""
[[1 1 1 1 1 1]
[1 1 1 1 0 0]
[0 0 0 0 0 0]
[0 0 0 0 0 0]]
"""
6. 练习
- 将 np.arange(10) 数组中的奇数全部都替换成 -1 。
import numpy as np
a1 = np.arange(10)
a1[a1%2 != 0] = -1
print(a1) # [ 0 -1 2 -1 4 -1 6 -1 8 -1]
- 有一个 4 行 4 列的数组(比如: np.random.randint(0,10,size=(4,4)) ),请将其中对角线的数取出来形成一个一维数组。提示(使用 np.eye )。
import numpy as np
a2 = np.random.randint(0,10,size=(4,4))
eye = np.eye(4,dtype=bool)
a3 = a2[eye]
print(a2)
print(a3)
'''
[[6 7 8 6]
[2 8 5 3]
[2 4 7 2]
[5 7 5 9]]
[6 8 7 9]
'''
- 有一个 4 行 4 列的数组,请取出其中 (0,0),(1,2),(3,2) 的点。
import numpy as np
a4 = np.random.randint(0,10,size=(4,4))
points = a4[[0,1,3],[0,2,2]]
print(a4)
print(points)
'''
[[5 7 1 9]
[5 1 1 6]
[5 8 3 5]
[4 8 0 0]]
[5 1 0]
'''
- 有一个 4 行 4 列的数组,请取出其中 2-3 行(包括第3行)的所有数据。
import numpy as np
a5 = np.random.randint(0,10,size=(4,4))
# 两种都可以
# lines = a5[2:4]
lines2 = a5[[2,3]]
print(a5)
# print(lines)
print(lines2)
'''
[[4 4 7 3]
[4 0 1 3]
[6 3 2 1]
[6 9 8 0]]
[[6 3 2 1]
[6 9 8 0]]
'''
- 有一个 8 行 9 列的数组,请将其中1-5行(包含第5行)的第8列大于3的数全部都取出来。
import numpy as np
a6 = np.random.randint(0,10,size=(8,9))
print(a6)
data = a6[1:6,8]
print(data)
ind = data>3
print(ind)
print(data[ind])
'''
[[2 1 1 8 3 3 0 4 3]
[5 9 7 8 3 6 5 3 7]
[2 3 2 8 8 0 4 0 6]
[3 4 1 7 5 3 3 8 5]
[0 2 2 0 8 8 2 9 1]
[7 6 3 3 6 3 1 9 8]
[5 2 8 0 5 3 1 4 1]
[0 5 7 9 9 3 1 8 9]]
[7 6 5 1 8]
[ True True True False True]
[7 6 5 8]
'''
6. 数组操作
1. 数组与数的计算
在 Python 列表中,想要对列表中所有的元素都加一个数,要么采用 map 函数,要么循环整个列表进行操作。但是 NumPy 中的数组可以直接在数组上进行操作。示例代码如下:
import numpy as np
a1 = np.random.random((3,4))
print(a1)
# 如果想要在a1数组上所有元素都乘以10,那么可以通过以下来实现
a2 = a1*10
print(a2)
# 也可以使用round让所有的元素只保留2位小数
a3 = a2.round(2)
print(a3)
'''
[[0.00548911 0.86000105 0.53551848 0.76743015]
[0.77023989 0.42753678 0.60471029 0.47327344]
[0.2915076 0.40588682 0.33885315 0.42230146]]
[[0.05489114 8.60001046 5.35518476 7.67430148]
[7.70239891 4.2753678 6.04710294 4.73273444]
[2.91507595 4.05886818 3.38853146 4.2230146 ]]
[[0.05 8.6 5.36 7.67]
[7.7 4.28 6.05 4.73]
[2.92 4.06 3.39 4.22]]
'''
以上例子是相乘,其实相加、相减、相除也都是类似的。
numpy.around(a,decimals) 函数返回指定数字的四舍五入值。
参数说明:
a: 数组
decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置
2. 数组与数组的计算
1. 结构相同的数组之间的运算
import numpy as np
a1 = np.arange(0,24).reshape((3,8))
a2 = np.random.randint(1,10,size=(3,8))
a3 = a1 + a2 #相减/相除/相乘都是可以的
print(a1)
print(a2)
print(a3)
"""
[[ 0 1 2 3 4 5 6 7]
[ 8 9 10 11 12 13 14 15]
[16 17 18 19 20 21 22 23]]
[[5 8 7 2 2 6 1 5]
[2 4 8 8 9 3 7 2]
[8 6 4 8 5 5 4 8]]
[[ 5 9 9 5 6 11 7 12]
[10 13 18 19 21 16 21 17]
[24 23 22 27 25 26 26 31]]
"""
2. 与行数相同并且只有1列的数组之间的运算
import numpy as np
a1 = np.random.randint(10,20,size=(3,8)) #3行8列
a2 = np.random.randint(1,10,size=(3,1)) #3行1列
a3 = a1 - a2 #行数相同,且a2只有1列,能互相运算
print(a1)
print(a2)
print(a3)
'''
[[12 16 18 16 11 11 15 17]
[11 17 19 16 13 17 15 18]
[13 16 13 11 16 18 12 11]]
[[3]
[5]
[3]]
[[ 9 13 15 13 8 8 12 14]
[ 6 12 14 11 8 12 10 13]
[10 13 10 8 13 15 9 8]]
'''
3. 与列数相同并且只有1行的数组之间的运算
import numpy as np
a1 = np.random.randint(10,20,size=(3,8)) #3行8列
a2 = np.random.randint(1,10,size=(1,8))
a3 = a1 - a2
print(a1)
print(a2)
print(a3)
'''
[[10 18 12 13 10 14 17 19]
[14 10 14 17 10 14 17 14]
[16 13 19 12 14 16 17 13]]
[[9 1 5 1 7 9 6 2]]
[[ 1 17 7 12 3 5 11 17]
[ 5 9 9 16 3 5 11 12]
[ 7 12 14 11 7 7 11 11]]
'''
3. 数组广播机制
广播原则:
如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
看以下案例分析:
- shape 为 (3,8,2) 的数组能和 (8,3) 的数组进行运算吗?
分析:不能,因为按照广播原则,从后面往前面数, (3,8,2) 和 (8,3) 中的 2 和 3 不相等,所以不能进行运算。- shape 为 (3,8,2) 的数组能和 (8,1) 的数组进行运算吗?
分析:能,因为按照广播原则,从后面往前面数, (3,8,2) 和 (8,1) 中的 2 和 1 虽然不相等,但是因为有一方的长度为 1 ,所以能参与运算。
4.数组形状的操作
1. reshape和resize方法
两个方法都是用来修改数组形状的,但是有一些不同。
- reshape 是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的。调用方式:
a1 = np.random.randint(0,10,size=(3,4))
a2 = a1.reshape((2,6)) #将修改后的结果返回,不会影响原数组本身
- resize 是将数组转换成指定的形状,会直接修改数组本身。并不会返回任何值。调用方式:
a1 = np.random.randint(0,10,size=(3,4))
a1.resize((2,6)) #a1本身发生了改变
2. flatten和ravel方法
两个方法都是将多维数组转换为一维数组,但是有以下不同:
- flatten 是将数组转换为一维数组后,然后将这个拷贝返回回去,所以后续对这个返回值进行修改不会影响之前的数组。
- ravel 是将数组转换为一维数组后,将这个视图(可以理解为引用)返回回去,所以后续对这个返回值进行修改会影响之前的数组。
比如以下代码:
import numpy as np
x = np.array([[1, 2], [3, 4]])
print(x)
x.flatten()[0] = 100 #此时的x[0]的位置元素还是1
print(x)
print('**'*10)
x.ravel()[0] = 100 #此时x[0]的位置元素是100
print(x)
'''
[[1 2]
[3 4]]
[[1 2]
[3 4]]
********************
[[100 2]
[ 3 4]]
'''
5. 数组(矩阵)转置和轴对换
numpy 中的数组其实就是线性代数中的矩阵。矩阵是可以进行转置的。
为什么要进行矩阵转置呢?有时候在做一些计算的时候需要用到。比如做矩阵的内积的时候,就必须将矩阵进行转置后再乘以之前的矩阵。
ndarray 有一个 T 属性,可以返回这个数组的转置的结果。示例代码如下:
import numpy as np
a1 = np.arange(0,24).reshape((4,6))
print(a1)
print('='*10)
a2 = a1.T
print(a2)
'''
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
==========
[[ 0 6 12 18]
[ 1 7 13 19]
[ 2 8 14 20]
[ 3 9 15 21]
[ 4 10 16 22]
[ 5 11 17 23]]
'''
另外还有一个方法叫做 transpose ,这个方法返回的是一个View,也即修改返回值,会影响到原来数组。示例代码如下:
import numpy as np
a1 = np.arange(0,24).reshape((4,6))
print(a1)
print('='*10)
a2 = a1.transpose() # 效果同a1.T
print(a2)
print('-'*10)
print(a1.dot(a2))
'''
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
==========
[[ 0 6 12 18]
[ 1 7 13 19]
[ 2 8 14 20]
[ 3 9 15 21]
[ 4 10 16 22]
[ 5 11 17 23]]
----------
[[ 55 145 235 325]
[ 145 451 757 1063]
[ 235 757 1279 1801]
[ 325 1063 1801 2539]]
'''
矩阵相关:
NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象。一个 的矩阵是一个由行(row)列(column)元素排列成的矩形阵列。
numpy.matlib.identity() 函数返回给定大小的单位矩阵(同np.eye())。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,除此以外全都为 0。
矩阵相乘:
numpy.dot(a, b, out=None)
a : ndarray 数组
b : ndarray 数组

第一个矩阵第一行的每个数字(2和1),各自乘以第二个矩阵第一列对应位置的数字(1和1),然后将乘积相加( 2 x 1 + 1 x 1),得到结果矩阵左上角的那个值3。也就是说,结果矩阵第m行与第n列交叉位置的那个值,等于第一个矩阵第m行与第二个矩阵第n列,对应位置的每个值的乘积之和。
推导参考:
理解矩阵乘法
用代码实现就比较简单了:
import numpy as np
a1 = np.array([[2,1],[4,3]])
a2 = np.array([[1,2],[1,0]])
result = np.dot(a1,a2)
print(result)
'''
[[3 4]
[7 8]]
'''
6. 不同数组的组合
如果有多个数组想要组合在一起,也可以通过其中的一些函数来实现。
- vstack :将数组按垂直方向进行叠加。数组的列数必须相同才能叠加。示例代码如下:
import numpy as np
a1 = np.random.randint(0,10,size=(3,5))
a2 = np.random.randint(0,10,size=(1,5))
a3 = np.vstack([a1,a2])
print(a1)
print('*'*10)
print(a2)
print('-'*10)
print(a3)
'''
[[4 1 9 1 0]
[4 5 8 0 9]
[1 5 9 2 4]]
**********
[[3 3 8 1 6]]
----------
[[4 1 9 1 0]
[4 5 8 0 9]
[1 5 9 2 4]
[3 3 8 1 6]]
'''
- hstack :将数组按水平方向进行叠加。数组的行必须相同才能叠加。示例代码如下:
import numpy as np
a1 = np.random.randint(0,10,size=(3,2))
a2 = np.random.randint(0,10,size=(3,1))
a3 = np.hstack([a1,a2])
print(a1)
print('*'*10)
print(a2)
print('-'*10)
print(a3)
'''
[[2 0]
[4 0]
[7 7]]
**********
[[0]
[2]
[1]]
----------
[[2 0 0]
[4 0 2]
[7 7 1]]
'''
- concatenate([],axis) :将两个数组进行叠加,但是具体是按水平方向还是按垂直方向。则要看 axis 的参数,
如果 axis=0 ,那么代表的是往垂直方向(行)叠加,如果 axis=1 ,那么代表的是往水平方向(列)上叠加,如果 axis=None ,那么会将两个数组组合成一个一维数组。需要注意的是,如果往水平方向上叠加,那么行必须相同,如果是往垂直方向叠加,那么列必须相同。示例代码如下:
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
c = np.concatenate((a, b), axis=0)
print(c)
print('='*10)
d = np.concatenate((a, b.T), axis=1) # b.T 即b的转置
print(d)
print('*'*10)
e = np.concatenate((a, b), axis=None)
print(e)
'''
[[1 2]
[3 4]
[5 6]]
==========
[[1 2 5]
[3 4 6]]
**********
[1 2 3 4 5 6]
'''
7.数组的切割
通过 hsplit 和 vsplit 以及 array_split 可以将一个数组进行切割。
- hsplit :按照水平方向进行切割。用于指定分割成几列,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:
import numpy as np
a1 = np.arange(16).reshape(4, 4)
a2 = np.hsplit(a1,2) #分割成两部分
print(a1)
print('='*10)
print(a2)
print('*'*10)
a3 = np.hsplit(a1,[1,2]) #代表在下标为1的地方切一刀,下标为2的地方切一刀,分成三部分
print(a3)
'''
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
==========
[array([[ 0., 1.],
[ 4., 5.],
[ 8., 9.],
[12., 13.]]), array([[ 2., 3.],
[ 6., 7.],
[10., 11.],
[14., 15.]])]
**********
[array([[ 0.],
[ 4.],
[ 8.],
[12.]]), array([[ 1.],
[ 5.],
[ 9.],
[13.]]), array([[ 2., 3.],
[ 6., 7.],
[10., 11.],
[14., 15.]])]
'''
- vsplit :按照垂直方向进行切割。用于指定分割成几行,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:
import numpy as np
a1 = np.arange(16).reshape(4, 4)
a2 = np.vsplit(a1,2) #代表按照行总共分成2个数组
print(a1)
print('='*10)
print(a2)
print('*'*10)
a3 = np.vsplit(a1,(1,2)) #代表按照行进行划分,在下标为1的地方和下标为2的地方分割,[1,2] 和 (1,2)结果一样
print(a3)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
==========
[array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
**********
[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
'''
- split/array_split(array,indicate_or_seciont,axis) :用于指定切割方式,在切割的时候需要指定是按照行还是按照列, axis=1 代表按照列, axis=0 代表按照行。示例代码如下:
import numpy as np
a1 = np.arange(16).reshape(4, 4)
a2 = np.array_split(a1,2,axis=0) #按照垂直方向切割成2部分
print(a1)
print('='*10)
print(a2)
print('*'*10)
a3 = np.array_split(a1,2,axis=1) #按照水平方向切割成2部分
print(a3)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
==========
[array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
**********
[array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]), array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
'''
8. 常用的统计函数
numpy.amin()和 numpy.amax(),用于计算数组中的元素沿指定轴的最小、最大值。
numpy.ptp():计算数组中元素最大值与最小值的差(最大值 - 最小值)。
numpy.median()函数用于计算数组 a 中元素的中位数(中值)。
标准差std():标准差是一组数据平均值分散程度的一种度量。
公式:std = sqrt(mean((x - x.mean())**2))
如果数组是 [1,2,3,4],则其平均值为 2.5。 因此,差的平方是[2.25,0.25,0.25,2.25],并且其平均值的平方根除以 4,即 sqrt(5/4) ,结果为 1.118033988749895。
方差var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即 mean((x - x.mean())** 2)。换句话说,标准差是方差的平方根。
示例:
import numpy as np
arr = np.array([1,2,3,4])
print(arr) # [1 2 3 4]
print(arr.ptp()) # 3
print(arr.mean()) # 2.5
print(arr.std()) # 1.118033988749895
print(arr.var()) # 1.25
7. numpy数组的深浅拷贝
在操作数组的时候,它们的数据有时候拷贝进一个新的数组,有时候又不是,这经常使初学者感到困惑。在数组操作中分成三种拷贝:
不拷贝:直接赋值,那么栈区没有拷贝,只是用同一个栈区定义了不同的名称。
浅拷贝:只拷贝栈区,栈区指定的堆区并没有拷贝。
深拷贝:栈区和堆区都拷贝了。
- 不拷贝
如果只是简单的赋值,那么不会进行拷贝。示例代码如下:
import numpy as np
a = np.arange(6)
b = a #这种情况不会进行拷贝
print(b is a) #返回True,说明b和a是相同的
- View或者浅拷贝
有些情况,会进行变量的拷贝,但是他们所指向的内存空间都是一样的,那么这种情况叫做浅拷贝,或者叫做 View(视图) 。比如以下代码:
import numpy as np
a = np.arange(6)
c = a.view()
print(c is a) #返回False,说明c和a是两个不同的变量
c[0] = 100
print(a[0]) #打印100,说明对c上的改变,会影响a上面的值,说明他们指向的内存空间还是一样的,这种叫做浅拷贝,或者说是view
- 深拷贝
将之前数据完完整整的拷贝一份放到另外一块内存空间中,这样就是两个完全不同的值了。示例代码如下:
import numpy as np
a = np.arange(6)
d = a.copy()
print(d is a) #返回False,说明d和a是两个不同的变量
d[0] = 100
print(a[0]) #打印0,说明d和a指向的内存空间完全不同了。
像之前讲到的 flatten 和 ravel 就是这种情况, ravel 返回的就是View,而 flatten 返回的就是深拷贝。
注意:这里和python list中的区别是copy直接是深拷贝,两者互不影响
8. 文件操作
如果想专门的操作CSV文件,python内置的有一个模块叫做csv,不需要安装,这里不作过多介绍。接下来我们主要讲numpy操作文件。
1.文件保存
有时候我们有了一个数组,需要保存到文件中,那么可以使用 np.savetxt 来实现。相关的函数描述如下:
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
* frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
* array : 存入文件的数组
* fmt : 写入文件的格式,例如:%d %.2f %.18e
* delimiter : 分割字符串,默认是任何空格
以下是使用的例子:
import numpy as np
a = np.arange(100).reshape(5,20)
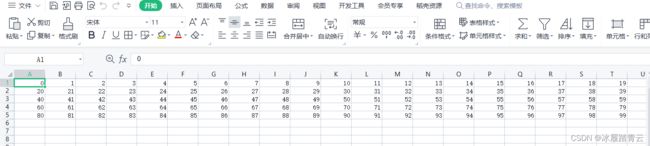
np.savetxt("a.csv",a,fmt="%d",delimiter=",")
效果:
2.读取文件
有时候我们的数据是需要从文件中读取出来的,那么可以使用 np.loadtxt 来实现。相关的函数描述如下:
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
* frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件。
* dtype:数据类型,可选。
* delimiter:分割字符串,默认是任何空格。
* skiprows:跳过前面x行。
* usecols:读取指定的列,用元组组合。
* unpack:如果True,读取出来的数组是转置后的。
用上面创建好的csv文件a.csv作为要读取的文件,代码示例:
import numpy as np
s = np.loadtxt("a.csv",dtype=np.int,delimiter=",")
print(s)
'''
[[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99]]
'''
小示例:我们本地有一个stock.csv文件,格式是这样的:

现有一需求:
使用numpy自带的csv方法读取出stock.csv文件中preClosePrice、openPrice、highestPrice、lowestPrice的数据(提示:使用skiprows和usecols参数)。
没啥难的,跳过第一行的列头,直接数出需要第几列数据加入到,usecols,代码示例:
import numpy as np
stocks=np.loadtxt("stock.csv",dtype=np.float,delimiter=",",skiprows=1,usecols=[6,7,8,9])
print(stocks)
3. numpy独有的存储解决方案
numpy 中还有一种独有的存储解决方案。文件名是以 .npy 或者 npz 结尾的。以下是存储和加载的函数。
- 存储: np.save(fname,array) 或 np.savez(fname,array) 。其中,前者函数的扩展名是 .npy ,后者的扩展名是 .npz ,后者是经过压缩的。
- 加载: np.load(fname) 。
代码示例:
import numpy as np
b = np.arange(10).reshape(2,5)
np.save('b',b) # 创建一个名为b.npy的文件
s = np.load('b.npy')
print(s)
'''
[[0 1 2 3 4]
[5 6 7 8 9]]
'''
9. 数组操作综合小练习
- 数组
a = np.random.rand(3,2,3)能和b = np.random.rand(3,2,2)进行运算吗?能和c = np.random.rand(3,1,1)进行运算吗?请说明结果的原因。
答案:a和b不能参与运算,因为不满足广播的机制(对应形状的值不相等,并且没有等于1的值)。a和c可以参与运算,因为满足广播机制(a和b的形状值虽然不相等,但是不相等的地方都是等于1)
- 想要将数组
a = np.arange(15).reshape(3,5)和b=np.arange(100,124).reshape(6,4)叠加在一起,其中a在b的上面,并且在b的第1列后面(下标从0开始)新增一列,用0来填充。
import numpy as np
# 1. 准备好数据
a = np.arange(15).reshape(3,5)
b = np.arange(100,124).reshape(6,4)
# 2. 因为b只有4列,无法直接和a堆叠,并且题目要求要在第1列后面添加一列
# 所以先将b数组在下标为1的地方切割,然后添加完0数组后再进行拼接
bsplits = np.hsplit(b,[2])
# 3. 创建一个全0的6行1列的数组
bzero = np.zeros((6,1))
# 4. 将b的前半部分,0,b的后半部分组合在一起形成一个新的数组
c = np.hstack([bsplits[0],bzero,bsplits[1]])
# 5. 将a和新生成的数组进行堆叠得到结果
result = np.vstack([a,c])
print(result)
'''
[[ 0. 1. 2. 3. 4.]
[ 5. 6. 7. 8. 9.]
[ 10. 11. 12. 13. 14.]
[100. 101. 0. 102. 103.]
[104. 105. 0. 106. 107.]
[108. 109. 0. 110. 111.]
[112. 113. 0. 114. 115.]
[116. 117. 0. 118. 119.]
[120. 121. 0. 122. 123.]]
'''
- 将数组a = np.random.rand(4,5)扁平化成一维数组,可以使用flatten和ravel,对两者的返回值进行操作,哪个会影响到数组a?对会影响到a数组的那个函数,请说明原因。
参考答案:ravel会影响原来的数组。原因是因为ravel返回的是一个浅拷贝(视图),虽然在栈中的内存不一样,但是指向的堆区的内存地址还是一样,所以操作其返回值,会影响到原来堆区的值。但是flatten返回的却是一个深拷贝,也即栈区和堆区都进行了拷贝,所以操作其返回值,不会影响到原来堆区的值。
10. NAN和INF值处理
首先我们要知道这两个英文单词代表的什么意思:
- NAN : Not A number ,不是一个数字的意思,但是他是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型。
- INF : Infinity ,代表的是无穷大的意思,也是属于浮点类型。 np.inf 表示正无穷大, -np.inf 表示负无穷大,一般在出现除数为0的时候为无穷大。比如 2/0 。
NAN一些特点:
1 . NAN和NAN不相等。比如 np.NAN != np.NAN 这个条件是成立的。
2 . NAN和任何值做运算,结果都是NAN。
有些时候,特别是从文件中读取数据的时候,经常会出现一些缺失值。缺失值的出现会影响数据的处理。因此我们在做数据分析之前,先要对缺失值进行一些处理。处理的方式有多种,需要根据实际情况来做。一般有两种处理方式:一种是删除缺失值,另外一种就是用其他值进行替代。
- 删除缺失值
有时候,我们想要将数组中的 NAN 删掉,那么我们可以换一种思路,就是只提取不为 NAN 的值。
示例代码如下:
import numpy as np
# 1. 删除所有NAN的值,因为删除了值后数组将不知道该怎么变化,所以会被变成一维数组
data = np.random.randint(0,10,size=(3,5)).astype(np.float)
data[0,1] = np.nan
data = data[~np.isnan(data)] # 此时的data会没有nan,并且变成一个1维数组
print(data)
# 2. 删除NAN所在的行
data = np.random.randint(0,10,size=(3,5)).astype(np.float)
# 将第(0,1)和(1,2)两个值设置为NAN
data[[0,1],[1,2]] = np.NAN
# 获取哪些行有NAN
lines = np.where(np.isnan(data))[0]
# 使用delete方法删除指定的行,axis=0表示删除行,lines表示删除的行号
data1 = np.delete(data,lines,axis=0)
print(data1)
- 用其他值进行替代
有些时候我们不想直接删掉,比如有一个成绩表,分别是数学和英语,但是因为某个人在某个科目上没有成绩,那么此时就会出现NAN的情况,这时候就不能直接删掉了,就可以使用某些值进行替代。假如有以下表格:

如果想要求每门成绩的总分,以及每门成绩的平均分,那么就可以采用某些值替代。比如求总分,那么就可以把NAN替换成0,如果想要求平均分,那么就可以把NAN替换成其他值的平均值。
示例代码如下:
scores=np.loadtxt("nan_scores.csv",delimiter=",",skiprows=1,encoding="utf-8",dtype=np.str)
scores[scores == "NAN"] = np.NAN
scores1 = scores.astype(np.float)
scores1[np.isnan(scores1)] = 0
# 除了delete用axis=0表示行以外,其他的大部分函数都是axis=1来表示行。
# 1. 求出学生成绩的总分
print(scores1.sum(axis=1)
# 2. 求出每门成绩的平均分
scores2 = scores.astype(np.float)
for x in range(scores2.shape[1]):
col = scores2[:,x]
non_nan_col = col[~np.isnan(col)]
mean = non_nan_col.mean()
col[np.isnan(col)] = mean
print(scores2.mean(axis=0))
小结:
- NAN:Not A Number的简写,不是一个数字,但是他是属于浮点类型。
- INF:无穷大,在除数为0的情况下会出现INF。
- NAN和所有的值进行计算结果都是等于NAN
- NAN != NAN
- 可以通过np.isnan来判断某个值是不是NAN。
- 处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换进行处理。
- np.delete比较特殊,他通过axis=0来代表行,而其他大部分函数是通过axis=1来代表行。
好了,到这里,这篇两万多字的博客也该跟大家说再见了,创作不易,如果本文对你有用,欢迎收藏点赞,虽然我并不会因此获利,但这真的是对我的肯定与鼓舞。
刚开始写博客的时候我都会写一句话激励自己,这次也写一句:你所做的事情,也许暂时看不到结果,但不要灰心或焦虑,你不是没有成长,而是在扎根,继续加油啊。