论文阅读:RoadMap: A Light-Weight Semantic Map for Visual Localizationtowards Autonomous Driving轻量语义自动驾驶
题目:A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving
中文:用于自动驾驶的视觉定位的轻量级语义图
来源: ICRA 2021
链接:https://arxiv.org/abs/2106.02527
可以去看下作者秦通(华为天才少年年薪200w那一档,华为车bu好想去这啊)的原文知乎链接,写的很简洁的介绍不用高精地图行不行?RoadMap:自动驾驶轻量化视觉众包地图 - 知乎
个人觉得有用的和自己理解加粗和()内表示,尽量翻译的比较全,有一些官方话就没有翻译了,一些疑惑的地方欢迎大家探讨。
如果对整个领域比较了解 建议只用看一下 引言最后一段 + 3456章即可。可以打开右侧目录跳转~
0、摘要
准确的定位对于自动驾驶任务至关重要。如今,我们已经看到很多传感器丰富的车辆 (例如机器人出租车) 在街上自主行驶,这些车辆依靠高精度的传感器 (例如激光雷达和RTK GPS) 和高分辨率地图。但是,低成本的生产汽车无法负担如此高的传感器和地图费用。如何降低成本?传感器丰富的汽车如何使低成本汽车受益?在本文中,我们提出了一种轻量级的定位解决方案,该解决方案依赖于低成本摄像机和压缩的视觉语义图。该地图很容易由传感器丰富的车辆以众包方式制作和更新。具体来说,地图由几个语义元素组成,例如车道线,人行横道,地面标志和路面上的停车线。我们介绍了车载映射,云上维护和用户端本地化的整个框架。在车辆上收集并预处理地图数据。然后,将众包数据上传到云服务器。来自多个车辆的海量数据在云上合并,以便语义图及时更新。最后,语义图被压缩并分发到汽车,汽车使用此图进行定位。我们在实际实验中验证了所提出地图的性能,并将其与其他算法进行了比较。语义图的平均大小为36 kb/km,该框架是用于自动驾驶的可靠且实用的定位方案。
1、引言 INTRODUCTION
近年来,对自动驾驶的需求日益增长。为了实现自主能力,车辆上配备了各种传感器,例如GPS,IMU,摄像头,激光雷达,雷达,车轮里程表等。定位是自动驾驶系统的基本功能。高精度定位依赖于高精度传感器和高清地图 (高清地图)。如今,rtk-gps和激光雷达是两种常见的传感器,广泛用于厘米级定位。Rtk-gps通过接收来自卫星和地面站的信号,在开放区域提供准确的全球姿态。激光雷达捕获周围环境的点云。通过点云匹配,可以将车辆定位在GPS拒绝环境中的高清地图中。这些方法已经在许多城市的机器人出租车应用中使用。
基于激光雷达和高清地图的解决方案非常适合机器人出租车应用。然而,有几个缺点限制了它在一般量产汽车上的使用。首先,量产车不能负担激光雷达和高清地图的高昂成本。再者,点云地图消耗大量内存,对于量产来说也是难以承受的。高清地图制作耗费巨量人力。很难保证及时更新。为了克服这些挑战,应该利用依赖低成本传感器和压缩地图的方法。
在这项工作中,我们提出了一种轻量级的定位解决方案,该解决方案依赖于相机和紧凑的视觉语义图。地图包含道路上的几个语义元素,例如车道线,人行横道,地面标志和停车线。这张地图紧凑,易于由传感器丰富车辆 (例如机器人出租车) 以众包方式制作。配备摄像头的低成本车辆可以使用此语义图进行定位。具体来说,基于学习的语义分割用于提取有用的地标。接下来,将语义地标从2D恢复到3D,并将其注册到本地地图中。本地地图上传到云服务器。云服务器合并不同车辆捕获的数据,并压缩全局语义图。最后,将紧凑的地图分发到量产车中,以用于本地化目的。所提出的语义映射和定位方法适用于大规模自动驾驶应用。本文的贡献总结如下:
- 我们提出了一种新的框架,用于自动驾驶任务中的轻量级本地化,其中包含车辆建图,云上地图维护和用户端定位。
- 我们提出了一种新颖的想法,该想法使用传感器丰富的车辆 (例如机器人出租车) 来使低成本生产汽车受益,传感器丰富的车辆每天自动收集数据并更新地图。
- 我们进行真实世界的实验来验证所提出系统的实用性。
(个人理解,传感器多的高级车分布式建图===>低级的车低成本匹配完成定位,比如跑的无人出租车因为要保证绝对安全所以一般都配备了激光雷达,但是普通家用车用几个摄像头就够了)
2. 文献回顾 LITERATURE REVIEW
在过去的几十年中,视觉建图和定位的研究变得越来越流行。传统的基于视觉的方法专注于在小规模室内环境中同时进行定位和映射 (SLAM)。在自动驾驶任务中,更加关注大型室外环境。
2.1 传统视觉slam Traditional Visual SLAM
视觉里程计(VO)是视觉SLAM领域中的一个典型主题,广泛应用于机器人应用中。流行的方法包括仅相机方法 [1]-[5] 和视觉惯性方法 [6]-[9]。提取自然环境中的稀疏点、线、稠密面等几何特征。在这些方法中,角点特征点用于[1, 4, 7, 8, 10]。相机姿态和特征位置,同时被估计。特征可以通过描述符进一步区分。恩格尔等人 [3] 利用半密集边缘来定位相机姿势并构建环境结构。
通过添加先验地图扩展的视觉里程计,它变成了固定坐标的定位问题。方法 [4、11]–[14] 预先构建视觉地图,然后在该地图内重新定位相机姿势。具体而言,基于视觉的方法 [11、13] 通过描述符匹配针对视觉特征图定位相机姿势。该地图包含数以千计的 3D 视觉特征及其描述符。 MurArtal 等人。 [4] 利用 ORB 特征 [15] 构建环境地图。然后该地图可用于通过 ORB 描述符匹配重新定位相机。此外,方法 [12、14] 可以自动将多个序列合并到一个全局框架中。对于自动驾驶任务,Burki 等人[13] 证明了车辆是通过道路上的稀疏特征图定位的。从本质上讲,传统的基于外观的方法,从长远来看会受到光线、视角和时间变化的影响。(因为传统方法是提取特征点,而传统的特征点的描述子通常是根据该点周围的亮度、色彩进行固定运算得到的)
2.2 基于道路的定位 Road-based Localization
基于道路的定位方法充分利用了自动驾驶场景中的道路特征。道路特征包含路面上的各种标记,例如车道线,路边和地面标志。道路特征还包含3D元素,例如交通信号灯和交通标志。与传统特征相比,这些标记在道路上丰富且稳定,并且对时间和光照变化具有鲁棒性。一般来说,准确的先验地图 (高清地图) 是必要的。此先验地图通常由高精度传感器设置 (激光雷达,RTK GNSS等) 构建。通过将视觉检测与该地图匹配来定位车辆。具体来说,Schreiber等人 [16] 通过检测路边和车道,并将这些元素的结构与高度精确的地图相匹配来定位相机。此外,Ranganathan等人[17] 利用道路标记并检测到道路标记上的拐角点。这些关键点用于定位。Yan等人 [18] 制定了非线性优化方法,以使道路标记与地图匹配。还考虑了车辆里程计和极线几何形状,以估计6自由度的相机姿势。
同时,一些研究 [19]-[22] 集中在道路地图的构建上。Regder等人 [19] 在图像上检测到车道,并使用里程计生成局部网格图。通过本地地图拼接进一步优化了位置。此外,Jeong等人 [20] 对道路标记进行了分类。信息类被用来避免歧义。回环检测和位姿图优化用于消除漂移并保持全局一致性。秦等 [21] 通过道路标记构建了地下停车场的语义图。基于此语义图执行了自动停车应用程序。(这个也是他自己论文,他在自引哈哈哈哈哈)Herb等人 [22] 提出了一种众包测试(原文应该少打了一个d,crowd-sourced)生成语义图的方法。但是,由于会话间功能匹配消耗了大量计算量,因此很难应用。
在本文中,我们专注于一个完整的系统,该系统包含车载建图,云上地图合并/更新以及最终用户定位。所提出的系统是用于大规模自动驾驶的可靠且实用的本地化解决方案。
3. 系统总览 SYSTEM OVERVIEW
该系统由三部分组成,如图2所示。
第一部分是车载建图。使用配备前视摄像头,rtk-gps和基本导航传感器 (IMU和车轮编码器) 的车辆。这些车辆广泛用于机器人-出租车应用程序,每天收集大量实时数据。通过分割网络从前视图像中提取语义特征。然后,根据优化后的车辆位置,将语义特征投影到世界框架。在车辆上构建了本地语义图。此本地地图上传到云地图服务器。
第二部分是云上建图。云服务器从多个车辆收集本地地图。多个本地地图合并为全局地图。然后通过轮廓提取压缩全局地图。最后,将压缩的语义图发布给最终用户。
第三部分是用户定位。最终用户是量产车,它们配备了低成本的传感器,例如摄像头,低精度GPS,IMU和车轮编码器。最终用户从云服务器下载语义图后对其进行解码。与车载建图部分相同,量产车通过分割从前视图像中提取语义特征。通过语义特征匹配将车辆定位在地图上。
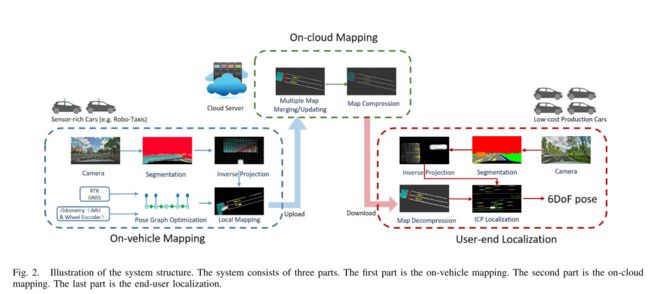
4. 车载建图 ON-VEHICLE MAPPING
4.1 图像分割 Image Segmentation
我们利用基于CNN的方法,如 [23]-[25],进行场景分割。本文将前视图像分为多个类别,例如地面,车道线,停车线,道路标记,路缘,车辆,自行车和人。在这些类别中,地面,车道线,停车线和道路标记用于语义映射。其他类可用于其他自动驾驶任务。图像分割的示例如图3所示。图3(a) 显示了由前视摄像头捕获的原始图像。图3(b) 显示了相应的分割结果。
4.2 反透视变换 Inverse Perspective Transformation
分割后,语义像素在车辆坐标下从图像平面反向投影到地面平面。此过程也称为逆透视映射 (IPM)。对摄像机的内在参数和从摄像机到车辆中心的外在参数变换进行离线标定校准。由于透视噪声,场景越远,误差越大。我们仅选择感兴趣区域 (ROI) 中的像素,其中靠近相机中心,如图3(a) 所示。此ROI表示车辆前方的12m × 8m矩形区域。假设地面是一个平面,每个像素 [u,v] 在车辆的坐标下投影到地平面 (z等于0) 中,如下所示,
其中 ![]() 是相机的失真和投影模型。
是相机的失真和投影模型。![]() 是逆投影,将像素提升到空间。[Rc tc] 是每个摄像机相对于车辆中心的外部矩阵。[u v] 是图像坐标中的像素位置。
是逆投影,将像素提升到空间。[Rc tc] 是每个摄像机相对于车辆中心的外部矩阵。[u v] 是图像坐标中的像素位置。![]() 是特征在车辆中心坐标中的位置。
是特征在车辆中心坐标中的位置。  是一个标量。()col意思是取这个矩阵的第i列。逆透视变换的示例结果如图3(c) 所示。ROI中的每个标记像素都投影在车辆前方的地面上。
是一个标量。()col意思是取这个矩阵的第i列。逆透视变换的示例结果如图3(c) 所示。ROI中的每个标记像素都投影在车辆前方的地面上。

4.3 位姿图优化Pose Graph Optimization
要构建地图,车辆的准确姿势是必要的。尽管使用了rtk-gnss,但它不能保证始终保持可靠的姿势。Rtk-gnss只能在开放区域提供厘米级的位置。在城市场景中,它的信号很容易被高楼挡住。导航传感器 (IMU和车轮) 可以在GNSS阻塞区域提供里程计。但是,里程计长期遭受累积漂移的困扰。该问题的图示如图4所示。蓝线是GNSS-good区域中的轨迹,由于高精度RTK GNSS,该轨迹是准确的。在GNSS阻塞区域,里程计轨迹以绿色绘制,漂移很多。为了缓解漂移,执行了位姿图优化。优化后的轨迹用红色绘制,平滑无漂移。
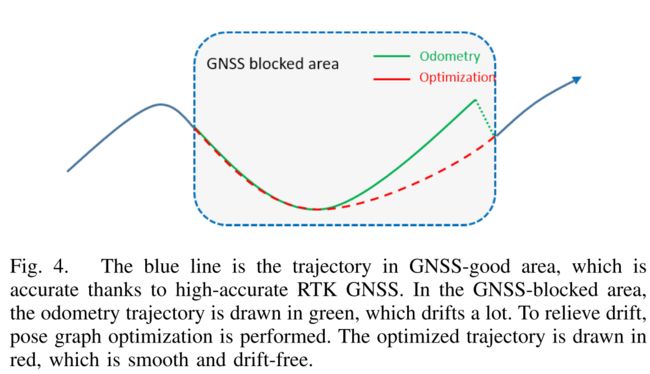
图5是位姿图优化的解释说明。蓝色节点是车辆在特定时间的状态s,其中包含位置p和方向q。我们使用四元数q来表示方向。运算R(q) 将一个四元数转换为旋转矩阵。有两种边。蓝色边表示GNSS约束,仅存在于GNSS-good时刻。它只影响一个节点。绿色边缘是里程计约束,它在任意时候存在。它约束两个相邻的节点。可以将姿势图优化公式化为以下等式
其中 s 是位姿状态(位置+方向)。
![]() 是里程计因子的残差。
是里程计因子的残差。
![]() 是里程计测量,它包含两个相邻状态之间的位置增量
是里程计测量,它包含两个相邻状态之间的位置增量![]() 和方向增量
和方向增量![]()
![]() 是 GNSS 因子的残差。
是 GNSS 因子的残差。
![]() 是 GNSS良好地区中的状态集。
是 GNSS良好地区中的状态集。
![]() 是 GNSS 测量值,它是全局坐标系中的位置
是 GNSS 测量值,它是全局坐标系中的位置![]() 。
。
残差因子![]() 和
和![]() 定义如下:
定义如下:
其中,[·]xyz取四元数的前三个元素,大约等于流形上的误差扰动。
(这里是图优化知识,一时半会也讲不清楚(主要是自己也没太看懂),可以推荐看看高翔视觉slam十四讲,个人理解是当有两个或者两个以上的观测量的时候,此时就可以融合两者的信息。比如这里是GNSS能测出自己位置,而里程计测量的是两次位置之间的变化值。这里就是两个约束,可以进行图优化。里程计有很多比如视觉里程计、惯导里程计、轮式里程计,是用来记录两次位置的差值。回到这个公式,这个公式是优化我们现在的位置的公式,也就是![]() 。优化的过程就是求这个min最小值。第二项很好理解,就是在GNSS良好的情况下,我的s要贴近gnss的结果,这个贴近的误差就GNSS 因子的残差
。优化的过程就是求这个min最小值。第二项很好理解,就是在GNSS良好的情况下,我的s要贴近gnss的结果,这个贴近的误差就GNSS 因子的残差![]() 。第一项可以简单理解为,我的两次
。第一项可以简单理解为,我的两次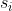 ,
,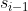 之间的关系应该符合我们的里程计测量
之间的关系应该符合我们的里程计测量![]() ,这个同样也不可能完全符合,因此误差用里程计因子
,这个同样也不可能完全符合,因此误差用里程计因子![]() 来衡量。最后我们通过最小化
来衡量。最后我们通过最小化![]() 和
和![]() ,当
,当![]() 和
和![]() 取得最小的时候,s 所处位置就是我们优化后的位置。换句话说只有这组
取得最小的时候,s 所处位置就是我们优化后的位置。换句话说只有这组![]() 才能让整体误差最小)
才能让整体误差最小)
4.4 局部建图 Local Mapping
位姿图优化每时每刻都提供可靠的车辆姿态。基于这个优化的姿势,第 i 帧中捕获的语义特征从车辆坐标转换为全局坐标,
![\left[\begin{array}{l} x^{w} \\ y^{w} \\ z^{w} \end{array}\right]=\mathbf{R}\left(\mathbf{q}_{i}\right)\left[\begin{array}{l} x^{v} \\ y^{v} \\ 0 \end{array}\right]+\mathbf{p}_{i}](http://img.e-com-net.com/image/info8/ed7d826494614414a6868236ec65b4c1.gif)
从图像分割来看,每个点都包含一个类标签(地面、车道线、路标和人行横道)。每个点代表世界框架中的一个小区域。车辆在行驶过程中,可以对一个区域进行多次观察。然而,由于分割噪声,这个区域可能被分为不同的类别。为了克服这个问题,我们使用统计数据来过滤噪音。地图分为小格子,分辨率为0.1×0.1×0.1m。每个网格的信息包含位置、语义标签和每个语义标签的计数。语义标签包括地面、车道线、停止线、地面标志和人行横道。一开始,每个标签的分数都是零。当一个语义点被插入到一个网格中时,相应标签的分数增加 1。因此,得分最高的语义标签代表网格的类别。通过这种方法,语义图变得准确并且对分割噪声具有鲁棒性。全局映射结果的示例如图 6(a)所示。
(大概就是说把相机平面的语义分割结果映射到地面平面,可能会有疑问,单目相机不是缺少一个维度深度吗,为什么还可以映射到世界坐标系(二维到三维的映射)?因为这里的假设是地面、车道线、路标和人行横道,这些东西本来就是在地面,因此实际上也是二维到二维的映射。针对于噪声情况,可以多次观察,得分最高被保留)
5. 云上建图 V. ON-CLOUD MAPPING
5.1地图合并/更新A. Map Merging / Updating
云地图服务器用于聚合多辆车捕获的海量数据。它及时合并本地地图,以便全局语义地图是最新的。为了节省带宽,只将本地地图占用的网格上传到云端。与车载建图过程相同,云服务器上的语义地图也被划分为分辨率为0.1×0.1×0.1m的网格。局部地图的网格根据其位置添加到全局地图。具体来说,将局部地图网格中的分数添加到全局地图上的相应网格中。这个过程是并行进行的。最后,得分最高的标签是网格的标签。地图更新的详细示例如图 9 所示。

5.2. 地图压缩 Map Compression
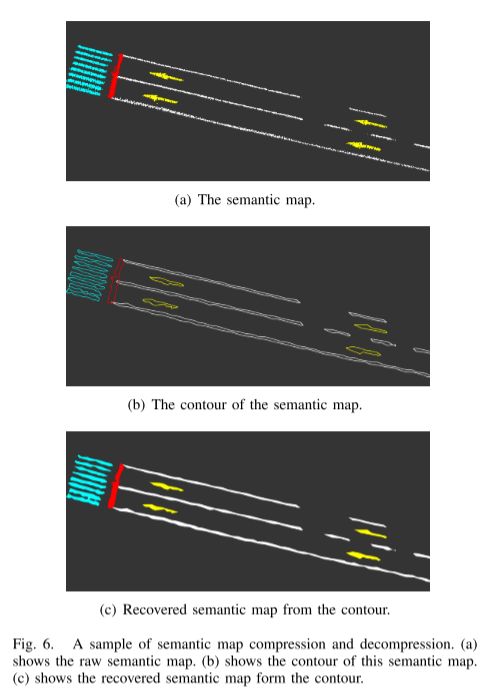
云服务器中生成的语义图将用于大量量产车的本地化。但是,传输带宽和车载存储在量产车上受到限制。为此,语义图在云上进一步压缩。由于轮廓可以有效地呈现语义图,因此我们使用轮廓提取来压缩地图。首先,我们生成语义图的俯视图图像。每个像素呈现一个网格。其次,提取每个语义组的轮廓。最后,将轮廓点保存并分配到生产车上。如图6所示,(a) 示出了原始语义图。图6(b) 显示了该语义图的轮廓。
6. 用户端定位USER-END LOCALIZATION
用户终端指的是量产车,它们配备了低成本传感器,例如摄像头、低精度 GPS、IMU 和车轮编码器。
6.1. 地图解压Map Decompression
用户终端接收到压缩图时,语义图将从轮廓点解压缩。在俯视图图像平面中,我们使用相同的语义标签填充轮廓内的点。然后,每个标记的像素都从图像平面恢复到世界协调中。解压缩的语义图的示例如图6(c) 所示。将图6(a) 中的原始映射与图6(c) 中的恢复映射进行比较,解码器方法有效地恢复了语义信息。
6.2.定位 ICP Localization
此语义图进一步用于定位。与建图过程类似,语义点是从前视图像分割生成的,并投影到车辆坐标系。然后通过将当前特征点与地图匹配来估计车辆的当前姿态,如图7所示。该估计采用ICP方法,该方法可以写为以下等式,

其中 q 和 p 是四元数和当前帧的位置。 S是当前特征点的集合。![]() 是车辆坐标下的当前特征。
是车辆坐标下的当前特征。![]() 是全局坐标下该特征在地图中的最近点。
是全局坐标下该特征在地图中的最近点。
最后采用 EKF(扩展卡尔曼) 框架,将里程计与视觉定位结果融合在一起。该滤波器不仅增加了定位的鲁棒性,而且平滑了估计的轨迹。
(定位使用当前视野里的图像,语义分割后和云上下载下来的数据库对比,结果进行卡尔曼滤波)

7.实验结果 EXPERIMENTAL RESULTS
我们通过真实世界的实验验证了所提出的语义图。第一个实验侧重于建图能力。第二个实验侧重于定位精度。
7.1建图Map Production
配备rtk-gps,前视摄像头,IMU和车轮编码器的车辆用于地图制作。多辆车同时在市区行驶。车辆地图通过网络上传到云服务器。最终的语义图如图8所示。该地图覆盖了上海浦东新区的一个城市街区。我们将语义地图与谷歌地图对齐。该地区公路网的总长度为22公里。原始语义图的整体大小为16.7 MB。压缩语义图的大小为0.786 MB。压缩语义图的平均大小为36 KB/KM。
图 9 显示了地图更新进度的详细示例。该区域重新绘制了车道线。图 9(a)显示了原始车道线。图 9(b)显示了重新绘制后的车道线。重绘区域以红色圆圈突出显示。图 9(c) 显示了原始语义图。图 9(d)显示语义地图正在更新。新车道线正在逐渐取代旧车道线。随着合并越来越多的最新数据,语义地图被完全更新,如图 9(e) 所示。

7.2. 定位精度Localization Accuracy
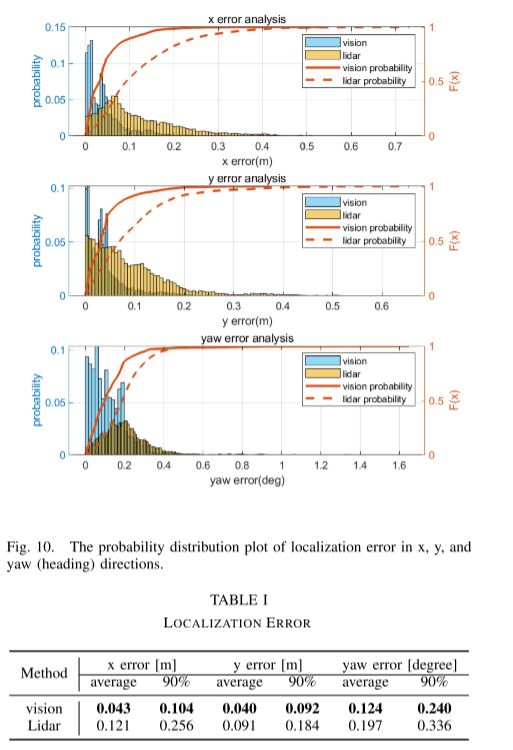
在这一部分中,我们评估了与基于激光雷达的方法相比的度量定位精度。该车辆配备了摄像头、激光雷达和 RTK GPS。 RTK GPS 被视为地面实况。使用了第一个实验中生成的语义图。车辆在该市区行驶。对于自动驾驶任务,我们关注 x、y 方向和偏航(航向)角的定位精度。与激光雷达的详细对比结果如图 10 和表 1 所示。可以看出,所提出的基于视觉的定位优于基于激光雷达的解决方案。
8.结论和未来工作 CONCLUSION & FUTURE WORK
我们提出了一种新颖的语义定位系统,它充分利用了传感器丰富的车辆(例如机器人出租车)来使低成本量产汽车受益。整个框架由车载映射、云端更新和用户端本地化程序组成。我们强调它是一种可靠且实用的自动驾驶本地化解决方案。
系统利用了路面上的标记。事实上,更多的3D空间交通元素可以用于定位,比如红绿灯、交通标志、电线杆等。未来,我们会将更多的 3D 语义特征扩展到地图中。
整理不易,求点赞!