决策树的剪枝
目录
一、何为剪枝及剪枝的缘由
二、决策树剪枝的方法
三、剪枝的实现
四、实验总结
一、何为剪枝及剪枝的缘由
首先让我们回顾决策树的形成过程,决策树算法是为了尽可能的拟合数据样本,根据训练集样本数据的特征,不停的分出节点,使得分类结果能够正确匹配数据类别,但是这样会导致树的分支节点过多,过于精确的分类会导致过拟合,为了防止过拟合导致分类的偏差,我们需要对决策树进行剪枝。
剪枝顾名思义,是对一棵树减去不必要的枝桠。对于决策树而言,则是需要剪去不必要的分支,让决策树的分类结果不需那么复杂也能很精确。
二、决策树剪枝的方法
目前,决策树的基本剪枝策略分为:预剪枝和后剪枝
预剪枝:预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛华性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
后剪枝:后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。
之前提到,决策树分支的决定条件是以当前哪个特征的信息增益最大为主要、计算信息增益的过程之前已经提到不在赘述,没有剪枝过的树是会对每一个特征通过计算信息增益来选取最优特征作为分支、但是有些时候即使是选取最大信息增益的特征继续分支,结果也不会比不分支更精细,所以预剪枝就是在分支前比较分支前后的分类精度,若分类后的精度小于分类前,则该节点不在进行分支。后剪枝则相反,是在已经构造出完整的决策树的前提下,先对最后一个节点进行剪枝,比较剪枝前后的分类精度,若剪枝后的分类精度大于剪枝前的分类精度,则对该节点进行剪枝。
三、剪枝的实现
首先数据集和之前一篇博客相同:
def createDataSet():
dataSet = [[0, 0, 0, 0,'canteen'], #数据集
[0, 0, 0, 1,'canteen'],
[0, 0, 1, 0, 'canteen'],
[0, 0, 1, 1, 'restaurant'],
[0, 1, 0, 0,'canteen'],
[0, 1, 0, 1,'buffer'],
[0, 1, 1, 0,'canteen'],
[0, 1, 1, 1,'restaurant'],
[1, 0, 0, 0, 'canteen'],
[1, 0, 0, 1,'canteen'],
[1, 0, 1, 0, 'canteen'],
[1, 0, 1, 1,'restaurant'],
[1, 1, 0, 0, 'restaurant'],
[1, 1, 0, 1, 'buffer'],
[1, 1, 1, 0, 'restaurant'],
[1, 1, 1, 1, 'restaurant']]
labels = ['外出意愿', '生活费是否充足', '饱腹程度','时间是否充足'] #分类属性
return dataSet, labels
预剪枝构造决策树:
def createTree(dataSet,labels,depth):
classList=[example[-1] for example in dataSet]
#达到指定深度停止划分
if depth==0:
return majorityCnt(classList)
#类别完全相同则停止划分
if classList.count(classList[0])==len(classList):
return classList[0]
#遍历完所有特征时返回出现次数最多的类别
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat,bestData=chooseBestData(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
#分支的多少和循环次数有关
listJudge=["<="+str(bestData),">"+str(bestData)]
subLabels=labels[:] #复制一份
print(bestFeat,bestData)
newDataSet_font=splitDataSet_bydata_font(dataSet,bestFeat,bestData)
newDataSet_back=splitDataSet_bydata_back(dataSet,bestFeat,bestData)
print(newDataSet_font)
if(newDataSet_font!=[] and bestFeat!=-1):
newDepth=depth-1
myTree[bestFeatLabel][listJudge[0]]=createTree(newDataSet_font,subLabels,newDepth)
if(newDataSet_back!=[] and bestFeat!=-1):
newDepth=depth-1
myTree[bestFeatLabel][listJudge[1]]=createTree(newDataSet_back,subLabels,newDepth)
return myTree
通过上述代码在构造树的过程中对是否拓展分支进行考虑,达到预剪枝的效果。
树的可视化代码与上一次博客相同
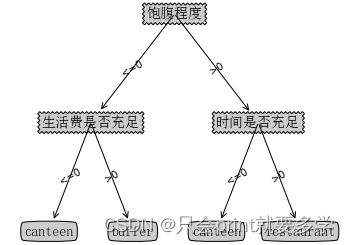
剪枝前的树:

剪枝后的树:
四、实验总结
预剪枝的优缺点:预剪枝使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。但是,另一方面,因为预剪枝是基于“贪心”的,所以,虽然当前划分不能提升泛华性能,但是基于该划分的后续划分却有可能导致性能提升,因此预剪枝决策树有可能带来欠拟合的风险。
本次实验未用到后剪枝,故不对后剪枝进行评价。