PaddleDetection中一些特色模型介绍
CBNet
论文题目:CBNet: A Novel Composite Backbone Network Architecture for Object Detection
论文地址:https://arxiv.org/abs/1909.03625
骨干网络对于检测网络的模型性能至关重要,但是大部分的骨干网络设计完成之后都需要首先在imagenet数据集上训练,得到的模型作为检测网络的预训练模型,该论文中,作者基于已有的骨干网络进行组合,最终实现一种新的骨干网络,同时验证了它在目标检测任务中的性能,在coco test-dev测试集上基于多尺度测试,达到了53.3%的精度指标。
论文提出的检测网络结构如下,其中用K个相同的结构进行联结,生成新的骨干网络,以ResNet结构为例,K=2时,为Dual-ResNet,K=3时,为Triple-ResNet。
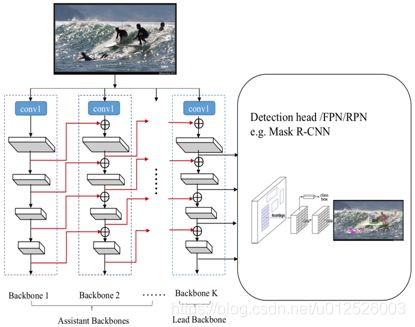
论文中验证了骨干网络的不同的联结方式及其对应的检测精度指标,如下所示。
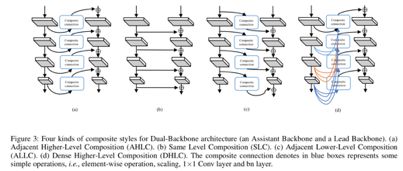
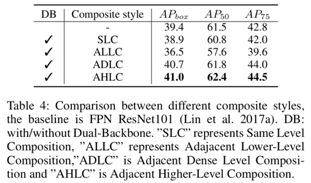
不同结构对应的精度指标如下。最终AHLC这种连接方式在CBNet被验证最为有效,通过和上图©中的ALLC的对比,也验证了单纯地通过添加网络参数并不能提升模型性能,和(d)中的ADLC对比,验证了特征图之间的信息融合方式也很重要。
论文中也验证了骨干网络权重共享、快速版CBNet、骨干网络的数量K对检测性能的影响,主要得到了以下结论
- 即使使用骨干网络权重不共享的方式,使用CBNet也能带来1%的绝对精度提升,这也验证了CBNet带来的精度提升更多地是因为网络结构而非参数量。
- 减少AHLC的连接数量,仅将C4和C5引入到下一个ResNet的骨干网络中,仍然可以带来1.4%的精度提升,这比C2~C5全部全部引入低0.2%,但是速度却快了约20%。
- 骨干网络堆叠的数量K在K>=3时,带来的收益逐渐减小,因此建议K=2或3,可以在速度和精度方面做比较好的权衡。
更加详细的实验与结论可以参考论文中的实验部分。目前Paddle已经开源基于ResNet的CBNet模型,实现代码可以参考:https://github.com/PaddlePaddle/PaddleDetection/blob/master/ppdet/modeling/backbones/cb_resnet.py
此外,基于CBNet,PaddleDetection也开源了coco val2017验证集53.3%的单模型单尺度检测模型:https://github.com/PaddlePaddle/PaddleDetection/blob/master/configs/dcn/cascade_rcnn_cbr200_vd_fpn_dcnv2_nonlocal_softnms.yml
IOU loss之GIOU/DIOU/CIOU loss
GIOU loss
论文题目:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
论文地址:https://arxiv.org/abs/1902.09630
IOU是论文中十分常用的指标,它对于物体的尺度并不敏感,在之前的检测任务中,常使用smooth l1 loss计算边框loss,但是该种方法计算出来的loss一方面无法与最终的IOU指标直接对应,同时也对检测框的尺度较为敏感,因此有学者提出将IOU loss作为回归的loss;但是如果IOU为0,则loss为0,同时IOU loss也没有考虑物体方向没有对齐时的loss,该论文基于此进行改进,计算GIOU的方法如下。

最终GIOU loss为1-GIOU所得的值。具体来看,IOU可以直接反映边框与真值之间的交并比,C为能够包含A和B的最小封闭凸物体,因此即使A和B的交并比为0,GIOU也会随着A和B的相对距离而不断变化,因此模型参数可以继续得到优化。在A和B的长宽保持恒定的情况下,两者距离越远,GIOU越小,GIOU loss越大。
使用GIOU loss计算边框损失的流程图如下。

PaddleDetection也开源了基于faster rcnn的GIOU loss实现。使用GIOU loss替换传统的smooth l1 loss,基于faster rcnn的resnet50-vd-fpn 1x实验,coco val mAP能由38.3%提升到39.4%(没有带来任何预测耗时的损失):https://github.com/PaddlePaddle/PaddleDetection/blob/master/configs/iou_loss/README.md
论文题目:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
论文地址:https://arxiv.org/abs/1911.08287
GIOU loss解决了IOU loss中预测边框A与真值B的交并比为0时,模型无法给出优化方向的问题,但是仍然有2种情况难以解决,
- 当边框A和边框B处于包含关系的时候,GIOU loss退化为IOU loss,此时模型收敛较慢。
- 当A与B相交,若A和B的的x1与x2均相等或者y1与y2均相等,GIOU loss仍然会退化为IOU loss,收敛很慢。
基于此,论文提出了DIOU loss与CIOU loss,解决收敛速度慢以及部分条件下无法收敛的问题。
为加速收敛,论文在改进的loss中引入距离的概念,具体地,边框loss可以定义为如下形式:
![]()
其中![]() 是惩罚项,考虑预测边框与真值的距离损失时,惩罚项可以定义为
是惩罚项,考虑预测边框与真值的距离损失时,惩罚项可以定义为
![]()
其中![]() 表示预测框与真值边框中心点的欧式距离,c表示预测框与真值边框的最小外包边框的对角长度。因此DIOU loss可以写为
表示预测框与真值边框中心点的欧式距离,c表示预测框与真值边框的最小外包边框的对角长度。因此DIOU loss可以写为
![]()
相对于GIOU loss,DIOU loss不仅考虑了IOU,也考虑边框之间的距离,从而加快了模型收敛的速度。但是使用DIOU loss作为边框损失函数时,只考虑了边框的交并比以及中心点的距离,没有考虑到预测边框与真值的长宽比差异的情况,因此论文中提出了CIOU loss,惩罚项添加关于长宽比的约束。具体地,惩罚项定义如下
![]()
其中v为惩罚项,α为惩罚系数,定义分别如下

CIOU loss使得在边框回归时,与目标框有重叠甚至包含时能够更快更准确地收敛。
在NMS阶段,一般的阈值计算为IOU,论文使用了DIOU修正后的阈值,检测框得分的更新方法如下。
![]()
这使得模型效果有进一步的提升。
PaddleDetection已经开源了基于faster rcnn的GIOU loss、DIOU/CIOU loss实现代码以及相关模型,具体可以参考:https://github.com/PaddlePaddle/PaddleDetection/tree/master/configs/iou_loss
Nonlocal
论文名称:Non-local Neural Networks
论文地址:https://arxiv.org/abs/1711.07971
卷积操作的感受野一般即为卷积核大小,它们只考虑局部区域,这减少了网络的计算量,但是却使得网络难以获取全局特征图信息。论文中设计了一个模块,很好地解决了局部卷积操作无法看清全局的问题,为后面的卷积计算引入更丰富的特征信息,并在视频分类与目标检测等任务中验证了其性能。
按照非局部均值的定义,卷积网络中的CNN定义如下
![]()
其中x与y表示输入与输出,f用于计算x_i与x_j的相似度,g则为点的特征计算函数,C(x)为归一化因子。为了保证Nonlocal可以作为一个组件方便地放入神经网络中,输入输出的形状是相同的。
Nonlocal结构如下图所示。
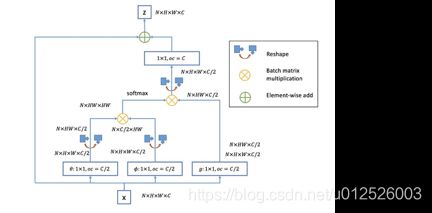
给定输入的特征图x,生成θ, ψ用于嵌入,使用1*1的卷积用于特征计算。为加快模型收敛,使Nonlocal模块参数更容易学习,在这里使用了残差块的形式,使得Nonlocal只需要去学习残差项;Nonlocal的计算量很大,为减少计算量,这里在生成θ, ψ与g时,可以进行通过减少通道数,减小Nonlocal计算量(图中是将中间层计算的通道数减少为输入输出通道数的一半)。
PaddleDetection开源了Nonlocal模块,并在ResNet骨干网络以及LibraRCNN中验证了其性能。基于PaddlePaddle的Nonlocal实现具体可以参考:https://github.com/PaddlePaddle/PaddleDetection/blob/master/ppdet/modeling/backbones/nonlocal_helper.py
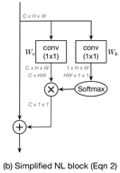
SNL的网络输出计算如下
![]()
为进一步减少计算量,将W_v提取到attention pooling计算的外面,表示为
![]()
对应结构如下所示。通过共享attention map,计算量减少为之前的1/WH。

SNL模块可以抽象为上下文建模、特征转换和特征聚合三个部分,特征转化部分有大量参数,因此在这里参考SE的结构,最终GC block的结构如下所示。使用两层降维的1*1卷积降低计算量,由于两层卷积参数较难优化,在这里加入layer normalization的正则化层降低优化难度。
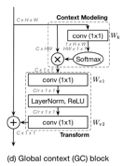
该模块可以很方便地插入到骨干网络中,提升模型的全局上下文表达能力,可以提升检测和分割任务的模型性能,PaddleDetection实现并开源了该模块,具体的模型性能与配置可以参考:https://github.com/PaddlePaddle/PaddleDetection/blob/master/configs/gcnet
Libra RCNN
论文名称:Libra R-CNN: Towards Balanced Learning for Object Detection
论文地址:https://arxiv.org/abs/1904.02701
检测模型训练大多包含3个步骤:候选区域生成与选择、特征提取、类别分类和检测框回归多任务的训练与收敛。
论文主要分析了在检测任务中,三个层面的不均衡现象限制了模型的性能,分别是样本(sample level)、特征(feature level)以及目标级别(objective level)的不均衡,提出了3种方案,用于解决上述三个不均衡的现象。三个解决方法如下。
IoU-balanced Sampling
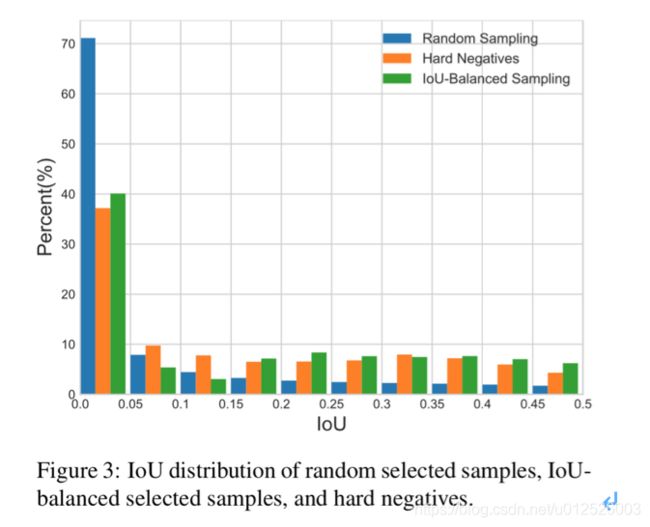
Faster RCNN中生成许多候选框之后,使用随机的方法挑选正负样本,但是这导致了一个问题:负样本中有70%的候选框与真值的IOU都在0~0.05之间,分布如下图所示。使用在线难负样本挖掘(OHEM)的方法可以缓解这种情况,但是不同IOU区间的采样样本仍然差距仍然比较大,而且流程复杂。作者提出了均衡的负样本采样策略,即将IOU阈值区间分为K份,在每个子区间都采样相同数量的负样本(如果达不到平均数量,则取所有在该子区间的样本),最终可以保证采样得到的负样本在不同的IOU子区间达到尽量均衡的状态。这种方法思路简单,效果也比OHEM要更好一些。
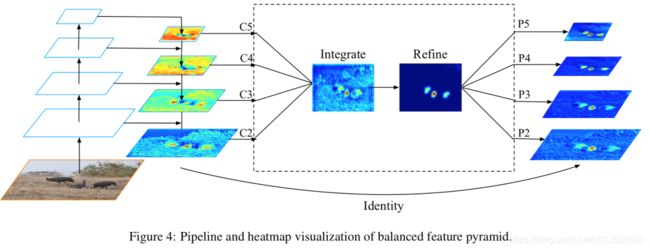
Balanced Feature Pyramid(BFP)
之前的FPN结构中使用横向连接的操作融合骨干网络的特征,论文中提出了一个如下图,主要包括rescaling, integrating, refining and strengthening,共4个部分。首先将不同层级的特征图缩放到同一尺度,之后对特征图进行加权平均,使用Nonlocal模块进一步提炼特征,最终将提炼后的特征图进行缩放,作为残差项与不同层级的特征图相加,得到最终输出的特征图。这种平衡的特征图金字塔结构相对于标准的FPN在coco数据集上可以带来0.8%左右的精度提升。
Balanced L1 Loss
物体检测任务中,需要同时优化分类loss与边框的回归loss,当分类得分很高时,即使回归效果很差,也会使得模型有比较高的精度,因此可以考虑增加回归loss的权重。假设bbox loss<=1的边框为inliers(可以被视为简单的样本),bbox loss>1的边框为outliers(可以被视为难样本),假设直接调整所有边框的回归loss,这会导致模型对outliers更加敏感,而且基于smooth l1 loss的边框loss计算方法有以下缺点,当边框为inliers时,其梯度很小,当边框为outliers时,梯度幅值为1。smooth l1 loss的梯度计算方法定义如下。
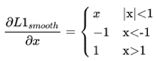
因此论文考虑增加inliers的梯度值,尽量平衡inliers与outliers的loss梯度比例。最终Libra loss的梯度计算方法如下所示。

在不同的超参数下,梯度可视化如下图所示。
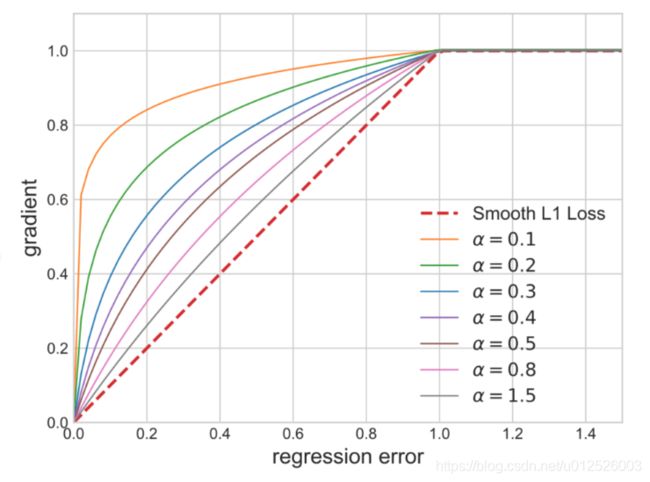
可以看出Libra loss与smooth l1 loss对于outliers的梯度是相同的,但是在inliers中,Libra loss的梯度更大一些,从而增大了不同情况下的边框回归loss,平衡了难易边框学习的loss,同时也提升了边框回归效果对检测模型性能的影响。
论文将3个部分融合在一起,在coco两阶段目标检测任务中有1.1%~2.5%的绝对精度提升,效果十分明显。PaddleDetection也实现并开源了Libra RCNN,配置与相关模型可以参考:https://github.com/PaddlePaddle/PaddleDetection/tree/master/configs/libra_rcnn