【NeRF】论文与代码综合分析及疑问解答
精读了文章《Representing Scenes as Neural Radiance Fields for View Synthesis》, 又看了一遍yen版源码,现在来再回顾一遍论文,尝试回答一些问题。
文章目录
- 论文内容回顾
-
- 摘要
- Introduction
- NeRF
- 实现细节
- 实验结果
-
- 对比的工作
- 总结
- 问题与分析
-
- 1. 如何生成一个随机的测试视角,其对应的poses 应该如何计算?
- 2. positional encoding在代码中何处,如何实现?
- 4. 为什么密度只与坐标有关而和视角方向无关,可以促进多视图一致性呢?
- 5. 代码中 , 模型的input_ch 为什么是63?这个和问题2有关,涉及到positional encoding的问题。
- 6. 文章说模型的输入需要坐标和视角相关的信息,效果才会更好, 如果只有坐标而没有视角相关的信息的话,效果会减弱。 思考:除了视角和坐标,还有什么是影响成像效果的?
- 7. 更好的理解公式1中, T ( t ) T(t) T(t)和 σ ( r ( t ) ) \sigma(r(t)) σ(r(t)) 的含义?
- 8 量化的指标PSNR↑ SSIM↑ LPIPS 是如何获得的?
论文内容回顾
摘要
方法特点
- 使用的是全连接网络,MLP,没有用到卷积网络。
- 以连续的5D坐标为输入,以volume density和 视觉相关的 radiance 做为输出
- (我们的方法克服了离散体素网格的高昂存储成本)
视角合成
- 通过沿着光束的方向查询5D的坐标,使用经典的volume rendering 技术来将输出的颜色和密度投射到图像中。
需要的数据条件
- 已知camera poses 的 图像集合。
Introduction
- 每一个点的density,就像一个不透明度差来控制通过(x, y, z)的光线所积累的亮度
- 核心部件:MLP (5D —— > 4D)
为特定视角生成渲染图
- 沿着视角方向行进的ray,采样3D点
- 用3D点和对应的2D视角方向作为输入给神经网络(MLP),计算出点对应的颜色和密度。
- 使用经典的volume rendering 技术 来将颜色和密度累计到2D图像上。
模型的学习
- 求生成的渲染图和 实际图像之间的误差。
考虑高分辨率的图像
- positional encoding
- hierarchical sampling
contribution汇总
- NeRF
- hierarchical sampling
- positional encoding
NeRF
训练全流程
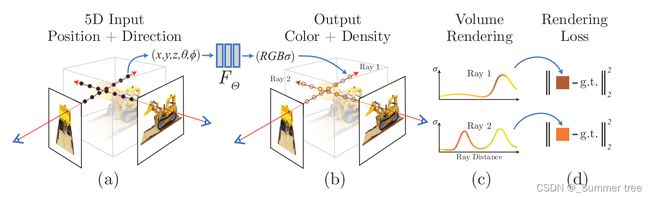
- 采样5D坐标
- MLP 计算 (5D ——4D)
- volume render (4D —— render Image)
- Loss (Render Image vs ground truth observed images)
细节描述
- 说了实现多视图一致性, 是密度只和 坐标有关,而和视角方向无关。 !!!
- 文章描述的MLP结构
- 3D坐标作为输入,经过8个全连接层(每层256通道), 输出 密度和 256维的 特征向量。
- 将特征向量和 视角方向联合起来,传入一个附加的全连接层(128通道),输出RGB。
- 代码中的MLP结构
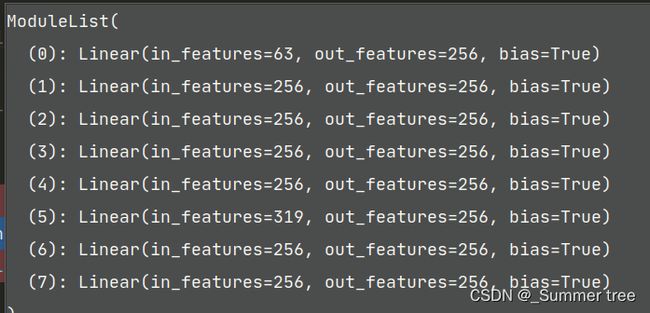
- 与论文描述不一致,但是却和下图实现的一样,也许是论文写得不够细致。
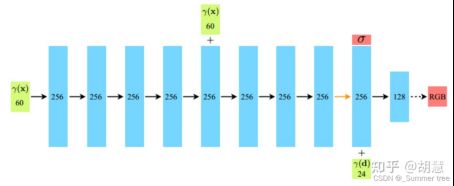
- 与论文描述不一致,但是却和下图实现的一样,也许是论文写得不够细致。

- 与论文描述一致 。
volume rendering 体绘制
- 将volume density 视为射线终止于x处的微分概率
- 光束的颜色计算如下:
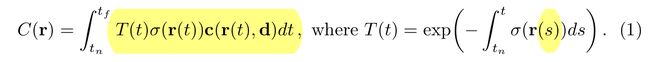
- T ( t ) T(t) T(t)表示沿着光束到t 积累的透明度。 (从公式来看,越往后面,透明度越小),可以理解光线从 t n t_n tn到 t t t的过程中没有被遮挡的概率(越靠前,不被遮挡的概率越大,也就是越往后越小)。
- stratified sampling approach: 在等区间内各随机一个点。

代码中的实现如下:
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp: # 确定采样方式
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples]) # 1024 x 64
if perturb > 0.:
# get intervals between samples 获取样本之间的间隔。
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals 这些间隔中的分层样本
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers 用numpy的固定随机数覆盖你
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
z_vals = lower + (upper - lower) * t_rand
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3]
-
真实采用的体绘制公式, 各部分的含义与公式1一致。
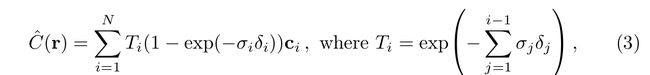
-
alpha 合成 ,这部分和体密度相关。
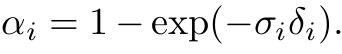
Positional encoding: 在将输入信息传递到网络之前,使用高频函数将其映射到一个更高维度的空间,这样可以更好地拟合包含高频变化的数据。
- Here γ is a mapping from R into a higher dimensional space R 2 L R^{2L} R2L
![]()
![]()
对应代码:
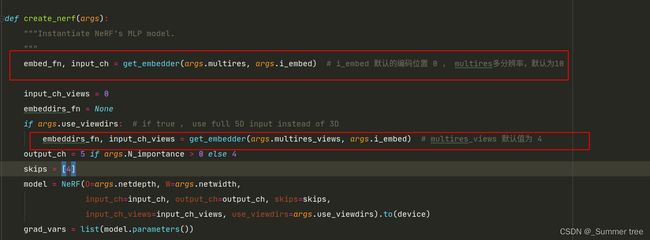
重写公式3 为公式 5, 用w表示权重。

然后对权重进行正则化。 沿射线产生分段常数的PDF。 !!! 这里的PDF是什么含义
实现细节
- 每个场景单独优化。
- 原始数据是某一个场景的图像集合, 利用COLMAP 生成对应的相机poses、内在参数以及场景边界。
- 在每个优化迭代过程中, 我们从所有的像素中, 随机采样一个batch的 光束,然后采用hierarchical sampling 在fine网络中查询 N c + N f N_c+N_f Nc+Nf个采样点 。 然后在使用体绘制技术来渲染每个光束的颜色。
- 损失函数采用的是均方误差函数
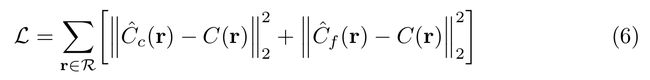
实验参数情况 - 实验中使用的batch_size= 4096个光束(1024 x 4) 为什么我之前看代码里面是1024呢
- N c 、 N f N_c、N_f Nc、Nf 分别为 64 和128
- 单个场景的优化在100-300k, 用NVIDIA V100 GPU 要花1-2天。
到目前位置,我觉得需要探究是实验有
- 光束上采样数量对 性能的影响
- 训练 图像数据对性能的影响。
- 图像分别率对性能的影响。
实验结果
- 测试样本 200个? 输出图像100个?
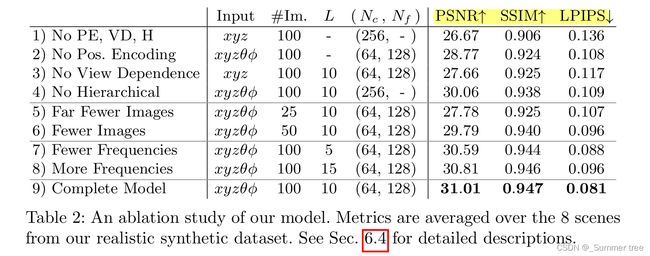
消融研究
- 没有视角信息
- 没有positional encoding, 以及高低频的位置编码。 为什么频率过高或过低都不好? 文章的解释是,超过了输入图像中存在的最大频率也不行。
- 没有分层采样
- 使用了更少的训练样本
对比的工作
Neural volumes(NV)
- 背景独立
- 深度3D卷积网络来进行预测 voxel grid。
- 需要进行 1283次采样
Scene Representation Network (SRN)
local Light Field Fusion (LLFF)
- 3D 卷积网络来预测RGB 和 alpha 网格
- 产生3D体素网格,存储开销很大。
以前的方式,只使用了单一的深度和颜色
总结
- 解决了之前工作的不足之处: 使用MLP将对象和场景表示为连续函数。
- 不需要输出离散化的体素表示。
- 未来工作的研究方向:
可解释性:
诸如体素网格和网格之类的采样表示可以对渲染视图的预期质量和故障模式进行推理,但是当我们在深度神经网络的权重中编码场景时,如何分析这些问题尚不清楚。 我们相信这项工作在基于现实世界图像的图形管道方面取得了进展,其中复杂的场景可以由从实际对象和场景的图像优化的神经辐射场组成。
问题与分析
1. 如何生成一个随机的测试视角,其对应的poses 应该如何计算?
2. positional encoding在代码中何处,如何实现?
【分析】
- 发现之间自己遗漏了create_nerf 中的一些细节。 比如里面的
get_embedder(),run_network()等,找时间再过一遍。 - 大概是在这个位置
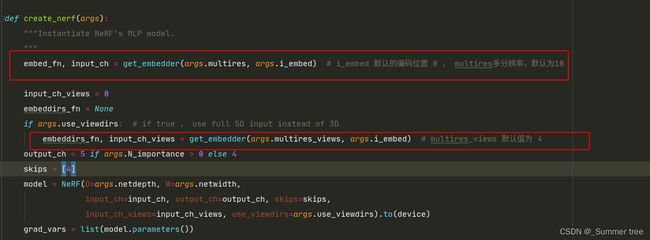
- 这部分是负责位置编码的

4. 为什么密度只与坐标有关而和视角方向无关,可以促进多视图一致性呢?
5. 代码中 , 模型的input_ch 为什么是63?这个和问题2有关,涉及到positional encoding的问题。
6. 文章说模型的输入需要坐标和视角相关的信息,效果才会更好, 如果只有坐标而没有视角相关的信息的话,效果会减弱。 思考:除了视角和坐标,还有什么是影响成像效果的?

7. 更好的理解公式1中, T ( t ) T(t) T(t)和 σ ( r ( t ) ) \sigma(r(t)) σ(r(t)) 的含义?
把体密度理解过 该点的不透明度,不透明度越高,其颜色占的比重越大。 T ( t ) T(t) T(t)表示不被遮挡的概率,是点前所有点不透明度的和, 前面的点不透明度越高,则当前点被遮挡的概率越大,所以 T ( t ) T(t) T(t) 随着t 的增加,前面积累的不透明度越多,则不被遮挡的概率越小。
8 量化的指标PSNR↑ SSIM↑ LPIPS 是如何获得的?
PSNR 在代码中有给出,psnr = mse2psnr(img_loss) 根据loss来进行计算, 具体地,mse2psnr = lambda x : -10. * torch.log(x) / torch.log(torch.Tensor([10.])) 。 但是SSIM,LPIPS 却没有说明。
- 尝试在NeRF tensorflow的实现版本中去找找。[没有找到]
- 网络查找 : https://zhuanlan.zhihu.com/p/309892873
结构相似性指数(structural similarity index,SSIM)
from skimage.metrics import structural_similarity as ssim
ssim_score = ssim(img1, img2, data_range=255)
峰值信噪比(Peak Signal to Noise Ratio, PSNR)
from skimage.metrics import peak_signal_noise_ratio as psnr
psnr(img1, img2, data_range=255)
学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)
import lpips
class util_of_lpips():
dist01 = self.loss_fn.forward(img0, img1) # RGB image from [-1,1]
- 按照上述提示,在代码中添加相关运算,后续做运行测试。
部分问题还没有完全解决,后续再陆续更新……