多维线性拟合回归问题 python
新冠肺炎–球重大公共卫生事件,美国是当前疫情最严重的国家,其感染人数与死亡人数居世界首位。目前以获取从2020.1.28-2020.9.9之间的数据,请利用所学知识,采用2020.1.28-2020.8.31的数据建立模型,并用9.1-9.9数据进行模型测试。
完成时间:约2020年10月25日
数据格式如下:
2020.1.28 0 5 0 0
2020.1.29 0 5 0 0
2020.1.30 1 6 0 0
2020.1.31 0 6 0 0



本图为预测2020年365天的回归曲线的预测值图形,今天写报告时,为10月25日,美国实际总确诊人数接近850万,print(linear_reg2.predict(poly_reg.fit_transform(predictarr0))[298],predictdaysdata[298]) 输出为[10264119.70637152] 2020.10.25,也即预测为1002万,相比较有着一定的差距。
使用较高阶数进行拟合,则短期内数据精准度较高,长期预测发生极大的数据波动:如下图
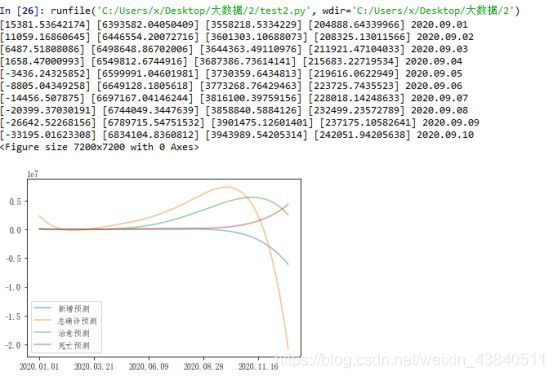
使用较低阶数进行拟合,则长期内数据精准度较高:如下图

源代码
#(1)
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
#import sys
if __name__ == "__main__":
io = r'C:\Users\x\Desktop\大数据\2\02.美国新冠肺炎疫情历史总数据9.9.xlsx'
data = pd.read_excel(io, sheet_name = 0)
lenofdata = len(data)
arr0 = []
arr1 = []
arr2 = []
arr3 = []
arr4 = []
daysdata = []
predictdaysdata = []
startdate = datetime.strptime("2020.1.01","%Y.%m.%d")
for num in range(0,lenofdata-1):
nowline = data.loc[num].values
dateintext = datetime.strptime(nowline[0], '%Y.%m.%d')
days = (dateintext-startdate).days#得出数据集中的日期距离2020.1.1的天数作为预测的因变量
daysdata.append(nowline[0])
arr0.append([days])
arr1.append([nowline[1]])
arr2.append([nowline[2]])
arr3.append([nowline[3]])
arr4.append([nowline[4]])
predictarr0 = []
for i in range(0,365):
predictdaysdata.append((startdate+timedelta(days=i)).strftime("%Y.%m.%d"))
predictarr0.append([i])
poly_reg = PolynomialFeatures(degree=3)
xarr = poly_reg.fit_transform(arr0)
predictxarr = poly_reg.fit_transform(predictarr0)
linear_reg1 = LinearRegression()
linear_reg1.fit(xarr, arr1)
linear_reg2 = LinearRegression()
linear_reg2.fit(xarr, arr2)
linear_reg3 = LinearRegression()
linear_reg3.fit(xarr, arr3)
linear_reg4 = LinearRegression()
linear_reg4.fit(xarr, arr4)
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(100,100))
fig = plt.figure()
ax0 = fig.add_subplot(1,1,1)
ax0.plot(daysdata, arr1, "o", label="新增",markersize =0.3 )
ax0.plot(daysdata, linear_reg1.predict(poly_reg.fit_transform(arr0)), label="新增预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax1 = fig.add_subplot(4,1,2)
ax0.plot(daysdata, arr2,"o", label="总确诊",markersize =0.3 )
ax0.plot(daysdata, linear_reg2.predict(poly_reg.fit_transform(arr0)), label="总确诊预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax2 = fig.add_subplot(4,1,3)
ax0.plot(daysdata, arr3,"o", label="治愈",markersize =0.3 )
ax0.plot(daysdata, linear_reg3.predict(poly_reg.fit_transform(arr0)), label="治愈预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax3 = fig.add_subplot(4,1,4)
ax0.plot(daysdata, arr4,"o", label="死亡",markersize =0.3 )
ax0.plot(daysdata, linear_reg4.predict(poly_reg.fit_transform(arr0)), label="死亡预测",alpha=0.5)
plt.xticks(arr0[::50])
plt.legend()
#ax.plot(arr0,arr3,label="治愈")
#ax.plot(arr0,arr4,label="死亡")
plt.xticks(arr0[::50])
plt.legend()
plt.savefig('2.png',dpi=1500)
#(2)
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
#import sys
if __name__ == "__main__":
io = r'C:\Users\x\Desktop\大数据\2\02.美国新冠肺炎疫情历史总数据9.9.xlsx'
data = pd.read_excel(io, sheet_name = 0)
lenofdata = len(data)
arr0 = []
arr1 = []
arr2 = []
arr3 = []
arr4 = []
daysdata = []
predictdaysdata = []
startdate = datetime.strptime("2020.1.01","%Y.%m.%d")
for num in range(0,lenofdata-1):
nowline = data.loc[num].values
dateintext = datetime.strptime(nowline[0], '%Y.%m.%d')
days = (dateintext-startdate).days#得出数据集中的日期距离2020.1.1的天数作为预测的因变量
daysdata.append(nowline[0])
arr0.append([days])
arr1.append([nowline[1]])
arr2.append([nowline[2]])
arr3.append([nowline[3]])
arr4.append([nowline[4]])
predictarr0 = []
for i in range(0,365):
predictdaysdata.append((startdate+timedelta(days=i)).strftime("%Y.%m.%d"))
predictarr0.append([i])
poly_reg = PolynomialFeatures(degree=3)
xarr = poly_reg.fit_transform(arr0)
predictxarr = poly_reg.fit_transform(predictarr0)
linear_reg1 = LinearRegression()
linear_reg1.fit(xarr, arr1)
linear_reg2 = LinearRegression()
linear_reg2.fit(xarr, arr2)
linear_reg3 = LinearRegression()
linear_reg3.fit(xarr, arr3)
linear_reg4 = LinearRegression()
linear_reg4.fit(xarr, arr4)
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(100,100))
fig = plt.figure()
ax0 = fig.add_subplot(4,1,1)
ax0.plot(daysdata, arr1, "o", label="新增",markersize =0.3 )
ax0.plot(daysdata, linear_reg1.predict(poly_reg.fit_transform(arr0)), label="新增预测",alpha=0.5)
plt.xticks("")
plt.legend()
ax1 = fig.add_subplot(4,1,2)
ax1.plot(daysdata, arr2,"o", label="总确诊",markersize =0.3 )
ax1.plot(daysdata, linear_reg2.predict(poly_reg.fit_transform(arr0)), label="总确诊预测",alpha=0.5)
plt.xticks("")
plt.legend()
ax2 = fig.add_subplot(4,1,3)
ax2.plot(daysdata, arr3,"o", label="治愈",markersize =0.3 )
ax2.plot(daysdata, linear_reg3.predict(poly_reg.fit_transform(arr0)), label="治愈预测",alpha=0.5)
plt.xticks("")
plt.legend()
ax3 = fig.add_subplot(4,1,4)
ax3.plot(daysdata, arr4,"o", label="死亡",markersize =0.3 )
ax3.plot(daysdata, linear_reg4.predict(poly_reg.fit_transform(arr0)), label="死亡预测",alpha=0.5)
plt.xticks(arr0[::50])
plt.legend()
#ax.plot(arr0,arr3,label="治愈")
#ax.plot(arr0,arr4,label="死亡")
plt.xticks(arr0[::50])
plt.legend()
plt.savefig('1.png',dpi=1500)
#(3)
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
#import sys
if __name__ == "__main__":
io = r'C:\Users\x\Desktop\大数据\2\02.美国新冠肺炎疫情历史总数据9.9.xlsx'
data = pd.read_excel(io, sheet_name = 0)
lenofdata = len(data)
arr0 = []
arr1 = []
arr2 = []
arr3 = []
arr4 = []
daysdata = []
predictdaysdata = []
startdate = datetime.strptime("2020.1.01","%Y.%m.%d")
for num in range(0,lenofdata-1):
nowline = data.loc[num].values
dateintext = datetime.strptime(nowline[0], '%Y.%m.%d')
days = (dateintext-startdate).days#得出数据集中的日期距离2020.1.1的天数作为预测的因变量
daysdata.append(nowline[0])
arr0.append([days])
arr1.append([nowline[1]])
arr2.append([nowline[2]])
arr3.append([nowline[3]])
arr4.append([nowline[4]])
predictarr0 = []
for i in range(0,365):
predictdaysdata.append((startdate+timedelta(days=i)).strftime("%Y.%m.%d"))
predictarr0.append([i])
poly_reg = PolynomialFeatures(degree=3)
xarr = poly_reg.fit_transform(arr0)
predictxarr = poly_reg.fit_transform(predictarr0)
linear_reg1 = LinearRegression()
linear_reg1.fit(xarr, arr1)
linear_reg2 = LinearRegression()
linear_reg2.fit(xarr, arr2)
linear_reg3 = LinearRegression()
linear_reg3.fit(xarr, arr3)
linear_reg4 = LinearRegression()
linear_reg4.fit(xarr, arr4)
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(100,100))
fig = plt.figure()
ax0 = fig.add_subplot(1,1,1)
#ax0.plot(daysdata, arr1, "o", label="新增",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg1.predict(poly_reg.fit_transform(predictarr0)), label="新增预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax1 = fig.add_subplot(4,1,2)
#ax0.plot(daysdata, arr2,"o", label="总确诊",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg2.predict(poly_reg.fit_transform(predictarr0)), label="总确诊预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax2 = fig.add_subplot(4,1,3)
#ax0.plot(daysdata, arr3,"o", label="治愈",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg3.predict(poly_reg.fit_transform(predictarr0)), label="治愈预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax3 = fig.add_subplot(4,1,4)
#ax0.plot(daysdata, arr4,"o", label="死亡",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg4.predict(poly_reg.fit_transform(predictarr0)), label="死亡预测",alpha=0.5)
plt.xticks(predictarr0[::50])
plt.legend()
#ax.plot(arr0,arr3,label="治愈")
#ax.plot(arr0,arr4,label="死亡")
plt.xticks(predictarr0[::80])
plt.legend()
plt.savefig('3.png',dpi=1500)
#5.
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
#import sys
if __name__ == "__main__":
io = r'C:\Users\x\Desktop\大数据\2\02.美国新冠肺炎疫情历史总数据9.9.xlsx'
data = pd.read_excel(io, sheet_name = 0)
lenofdata = len(data)
arr0 = []
arr1 = []
arr2 = []
arr3 = []
arr4 = []
daysdata = []
predictdaysdata = []
startdate = datetime.strptime("2020.1.01","%Y.%m.%d")
for num in range(0,lenofdata-10):
nowline = data.loc[num].values
dateintext = datetime.strptime(nowline[0], '%Y.%m.%d')
days = (dateintext-startdate).days#得出数据集中的日期距离2020.1.1的天数作为预测的因变量
daysdata.append(nowline[0])
arr0.append([days])
arr1.append([nowline[1]])
arr2.append([nowline[2]])
arr3.append([nowline[3]])
arr4.append([nowline[4]])
predictarr0 = []
for i in range(0,365):
predictdaysdata.append((startdate+timedelta(days=i)).strftime("%Y.%m.%d"))
predictarr0.append([i])
poly_reg = PolynomialFeatures(degree=3)
xarr = poly_reg.fit_transform(arr0)
predictxarr = poly_reg.fit_transform(predictarr0)
linear_reg1 = LinearRegression()
linear_reg1.fit(xarr, arr1)
linear_reg2 = LinearRegression()
linear_reg2.fit(xarr, arr2)
linear_reg3 = LinearRegression()
linear_reg3.fit(xarr, arr3)
linear_reg4 = LinearRegression()
linear_reg4.fit(xarr, arr4)
for i in range(0,10):
print(linear_reg1.predict(poly_reg.fit_transform(predictarr0))[244+i] ,
linear_reg2.predict(poly_reg.fit_transform(predictarr0))[244+i],
linear_reg3.predict(poly_reg.fit_transform(predictarr0))[244+i],
linear_reg4.predict(poly_reg.fit_transform(predictarr0))[244+i],
predictdaysdata[244+i])
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(100,100))
fig = plt.figure()
ax0 = fig.add_subplot(1,1,1)
#ax0.plot(daysdata, arr1, "o", label="新增",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg1.predict(poly_reg.fit_transform(predictarr0)), label="新增预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax1 = fig.add_subplot(4,1,2)
#ax0.plot(daysdata, arr2,"o", label="总确诊",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg2.predict(poly_reg.fit_transform(predictarr0)), label="总确诊预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax2 = fig.add_subplot(4,1,3)
#ax0.plot(daysdata, arr3,"o", label="治愈",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg3.predict(poly_reg.fit_transform(predictarr0)), label="治愈预测",alpha=0.5)
plt.xticks("")
plt.legend()
#ax3 = fig.add_subplot(4,1,4)
#ax0.plot(daysdata, arr4,"o", label="死亡",markersize =0.3 )
ax0.plot(predictdaysdata, linear_reg4.predict(poly_reg.fit_transform(predictarr0)), label="死亡预测",alpha=0.5)
plt.xticks(predictarr0[::50])
plt.legend()
#ax.plot(arr0,arr3,label="治愈")
#ax.plot(arr0,arr4,label="死亡")
plt.xticks(predictarr0[::80])
plt.legend()
plt.savefig('3.png',dpi=1500)