语义分割(Semantic Segmentation)之Ways
语义分割(Semantic Segmentation)方法
1. 什么是语义分割
语义分割是当今计算机视觉领域的关键问题之一。从宏观上看,语义分割是一项高层次的任务,为实现场景的完整理解铺平了道路。场景理解作为一个核心的计算机视觉问题,其重要性在于越来越多的应用程序通过从图像中推断知识来提供营养。其中一些应用包括自动驾驶汽车、人机交互、虚拟现实等,近年来随着深度学习的普及,许多语义分割问题正在采用深层次的结构来解决,最常见的是卷积神经网络,在精度上大大超过了其他方法。以及效率。
什么是语义分割?
语义分割是从粗推理到精推理的自然步骤:
原点可以定位在分类,分类包括对整个输入进行预测。
下一步是本地化/检测,它不仅提供类,还提供关于这些类的空间位置的附加信息。
最后,语义分割通过对每个像素进行密集的预测、推断标签来实现细粒度的推理,从而使每个像素都被标记为其封闭对象矿石区域的类别。

在图像语义分割领域,困扰了计算机科学家很多年的一个问题则是我们如何才能将我们感兴趣的对象和不感兴趣的对象分别分割开来呢?比如我们有一只小猫的图片,怎样才能够通过计算机自己对图像进行识别达到将小猫和图片当中的背景互相分割开来的效果呢?如下图所示:
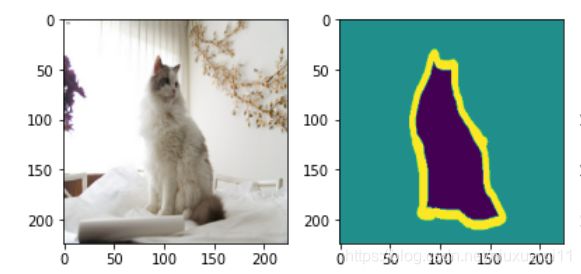
而在2015年出来的FCN,全卷积神经网络完美地解决了这个问题,将曾经mean IU(识别平均准确度)只有百分之40的成绩提升到了百分之62.2(在Pascal VOC数据集上跑的结果,FCN论文上写的),像素级别识别精确度则是90.2%。这已经是一个相当完美的结果了,几乎超越了人类对图像进行区分,分割的能力。如上图所示,小猫被分割为了背景,小猫,边缘这三个部分,因此图像当中的每一个像素最后只有三个预测值,是否为小猫,背景,或者边缘。全卷积网络要做的就是这种进行像素级别的分类任务。那么这个网络是如何设计和实现的呢?
2.语义分割的基础
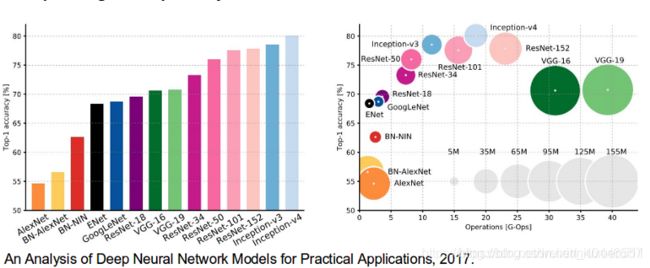
也有必要回顾一些对计算机视觉领域做出重大贡献的标准深层网络,因为它们通常被用作语义分割系统的基础:
Alexnet:Toronto首创的Deep CNN,以84.6%的测试准确率赢得了2012年Imagenet竞赛。它由5个卷积层、最大池层、作为非线性的ReLUs、3个完全卷积层和dropout组成。
VGG-16:这款牛津型号以92.7%的准确率赢得了2013年的Imagenet竞争。它使用第一层中具有小接收场的卷积层堆栈,而不是具有大接收场的少数层。
GoogLeNet:这GoogLeNet赢得了2014年Imagenet的竞争,准确率为93.3%。它由22层和一个新引入的称为初始模块的构建块组成。该模块由网络层网络、池操作、大卷积层和小卷积层组成。
Resnet:这款微软的模型以96.4%的准确率赢得了2016年的Imagenet竞争。这是众所周知的,因为它的深度(152层)和残余块的引进。剩余的块通过引入标识跳过连接来解决培训真正深层架构的问题,以便层可以将其输入复制到下一层。
3.语义分割的方法
现有的语义分割方法是什么?
一个通用的语义分割体系结构可以被广泛认为是一个编码器网络,然后是一个解码器网络:
编码器通常是一个预先训练的分类网络,如vgg/resnet,然后是一个解码器网络。
解码器的任务是将编码器学习到的识别特征(低分辨率)语义投影到像素空间(高分辨率)上,得到密集的分类。
与分类不同的是,深度网络的最终结果是唯一重要的,语义分割不仅需要在像素级别上进行区分,而且还需要一种机制将编码器不同阶段学习到的区分特征投影到像素空间上。不同的方法使用不同的机制作为解码机制的一部分。让我们探讨三种主要方法:
1-基于区域的语义分割
基于区域的方法通常遵循“使用识别的分割”管道,首先从图像中提取自由形式的区域并对其进行描述,然后进行基于区域的分类。在测试时,基于区域的预测转换为像素预测,通常通过根据包含该预测的最高评分区域标记像素。
R-CNN(具有CNN特征的区域)是基于区域的方法的代表性工作之一。根据目标检测结果进行语义分割。具体来说,R-CNN首先利用选择性搜索来提取大量的目标提案,然后计算每个提案的CNN特征。最后,使用类特定的线性支持向量机对每个区域进行分类。与传统的以图像分类为主要目的的CNN结构相比,R-CNN能够处理更复杂的任务,如目标检测和图像分割,甚至成为这两个领域的重要基础。此外,R-CNN可以建立在任何CNN基准结构之上,如Alexnet、VGG、Googlenet和Resnet。
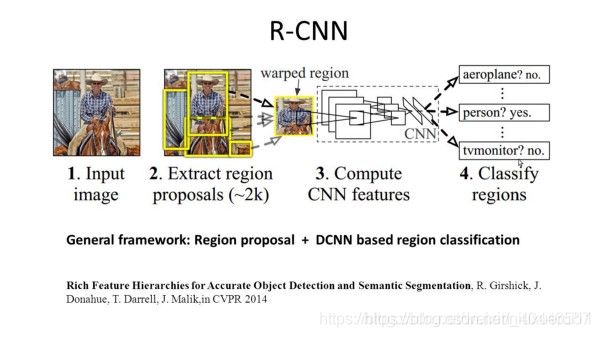
对于图像分割任务,R-CNN提取了每个区域的两种特征:全区域特征和前景特征,发现将它们作为区域特征连接在一起可以获得更好的性能。R-CNN由于使用了高度歧视性的CNN功能,取得了显著的性能改进。但是,它也面临着分割任务的一些缺点:
此功能与分段任务不兼容。
该特征包含的空间信息不足,无法精确生成边界。
生成基于分段的建议需要时间,并且会极大地影响最终性能。
由于这些瓶颈,最近的研究提出了解决这些问题,包括SDS, Hypercolumns, Mask R-CNN。
2-全卷积网络语义分割
原始的完全卷积网络(FCN)学习从像素到像素的映射,而不提取区域建议。FCN网络管道是经典CNN的延伸。其主要思想是使经典的CNN以任意大小的图像作为输入。CNN仅接受和生产特定尺寸输入的标签的限制来自完全连接的固定层。与之相反,FCN只有卷积层和池层,它们能够对任意大小的输入进行预测。
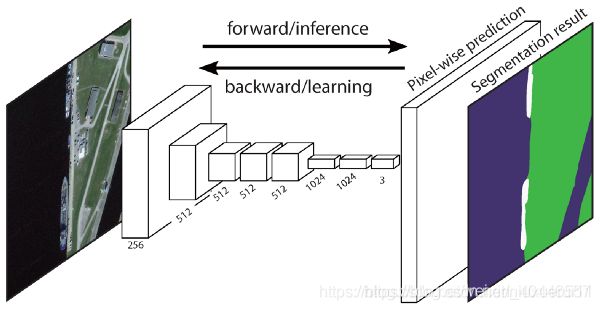
在这个特定的FCN中,一个问题是通过几个交替的卷积层和池层传播,输出特征映射的分辨率被降采样。因此,FCN的直接预测通常分辨率较低,导致对象边界相对模糊。为了解决这个问题,已经提出了各种更先进的基于FCN的方法,包括SegNet, DeepLab-CRF, 和 Dilated Convolutions。
3-弱监督语义分割
语义分割中的大多数相关方法都依赖于大量带有像素级分割遮罩的图像。然而,手工注释这些面具是相当费时,令人沮丧和商业成本。因此,最近提出了一些弱监督的方法,这些方法致力于通过使用带注释的边界框来实现语义分割。

例如,Boxsup使用边界框注释作为监督来训练网络,并迭代地改进用于语义分割的估计掩码。简单地说,它把弱监督限制看作输入标签噪声问题,并探讨了递归训练作为一种去噪策略。像素级标记解释了多实例学习框架中的分割任务,并添加了一个额外的层来约束模型,以将更多的权重分配给重要的像素进行图像级分类。
4. 网络的实现
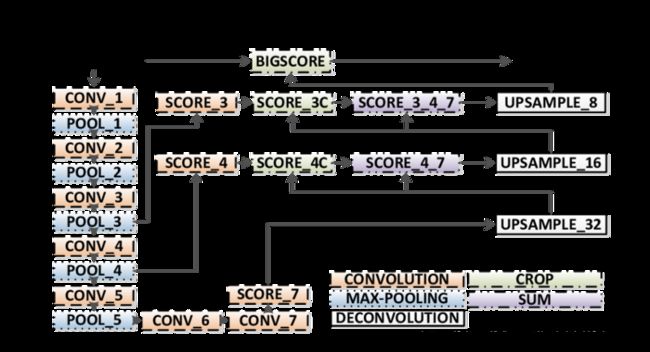
这个网络的实现虽然听名字十分霸气,全卷积神经网络。不过事实上使用这个名字无非是把卷积网络的最后几层用于分类的全连接层换成了1*1的卷积网络,所以才叫这个名字。这个网络的首先对图片进行卷积——>卷积——>池化,再卷积——>卷积——>池化,直到我们的图像缩小得够小为止。这个时候就可以进行上采样,恢复图像的大小,那么什么是上采样呢?你估计还没有听说过,等下咱们一 一道来。这个网络的结构如下所示(附上论文上的原图):
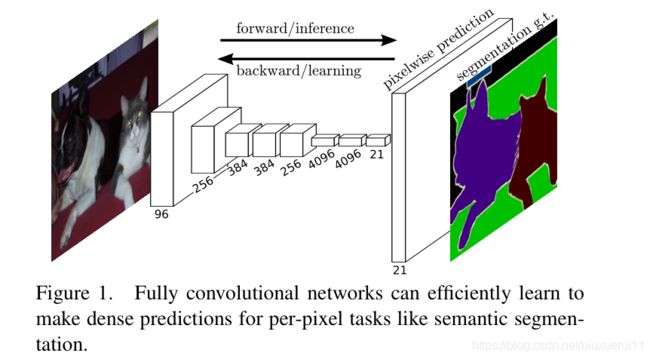
从中可以看到我们输入了一个小猫和小狗在一起时的图片,最后再前向传播,在这个前向传播网络的倒数第三层,卷积神经网络的长度就变成了NN21,因为在VOC数据集上一共有21个softmax分类的结果,因此每个类别都需要有一个相关概率(置信度)的输出。而前面这个前向传播的卷积神经网络可以是VGG16,也可以是AlexNet,Google Inception Net,甚至是ResNet,论文作者在前三个Net上都做了相应的尝试,但是因为ResNet当时还没出来,也就没有尝试过在前面的网络当中使用它。当我们的网络变成了一个NN21的输出时,我们将图像进行上采样,上采用就相当于把我们刚才得到的具有21个分类输出的结果还原成一个和原图像大小相同,channel相同的图。这个图上的每个像素点都代表了21个事物类别的概率,这样就可以得到这个图上每一个像素点应该分为哪一个类别的概率了。那么什么是图像的上采样呢?
5.图像的上采样
图像的上采样正好和卷积的方式相反,我们可以通过正常的卷积让图像越来越小,而上采样则可以同样通过卷积将图像变得越来越大,最后缩放成和原图像同样大小的图片。
关于上采样的论文在这这篇论文当专门做了详解:https://arxiv.org/abs/1603.07285。上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling)。在全卷积神经网络当中我们采用了反卷积来实现了上采样。我们先来回顾一下正向卷积,也称为下采样,正向的卷积如下所示,首先我们拥有一个这样的3*3的卷积核:
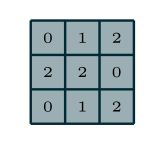
然后对一个55的特征图利用滑动窗口法进行卷积操作,padding=0,stride=1,kernel size=3,所以最后得到一个33的特征图:

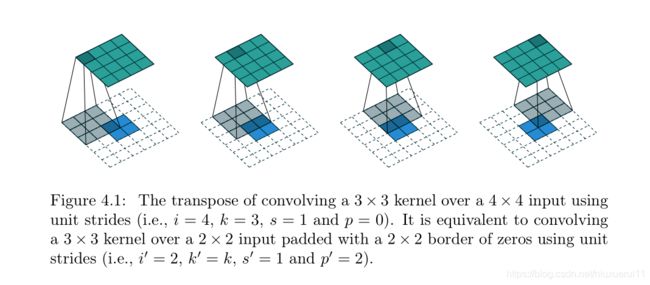
那么上采样呢?则是这样的,我们假定输入只是一个22的特征图,输出则是一个44的特征图,我们首先将原始22的map进行周围填充pading=2的操作,笔者查阅了很多资料才知道,这里周围都填充了数字0,周围的padding并不是通过神经网络训练得出来的数字。然后用一个kernel size=3,stride=1的感受野扫描这个区域,这样就可以得到一个44的特征图了!
我们甚至可以把这个22的feature map,每一个像素点隔开一个空格,空格里的数字填充为0,周围的padding填充的数字也全都为零,然后再继续上采样,得到一个55的特征图,如下所示:
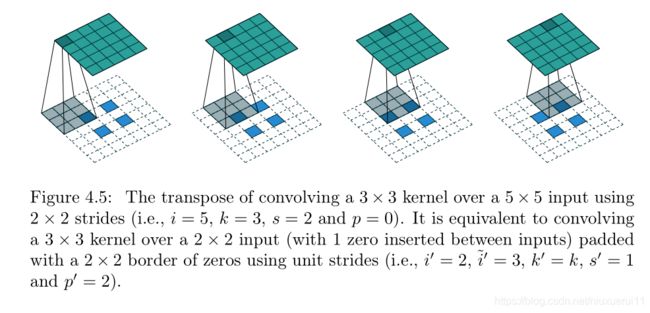
这样咱们的反卷积就完成了。那么什么是1*1卷积呢?
6. 1*1卷积
在我们的卷积神经网络前向传播的过程当中,最后是一个NN21的输出,这个21是可以我们进行人为通过11卷积定义出来的,这样我们才能够得到一个21个类别,每个类别出现的概率,最后输出和原图图像大小一致的那个特征图,每个像素点上都有21个channel,表示这个像素点所具有的某个类别输出的概率值。吴恩达教授在讲解卷积神经网络的时候,用到了一张十分经典的图像来表示11卷积:
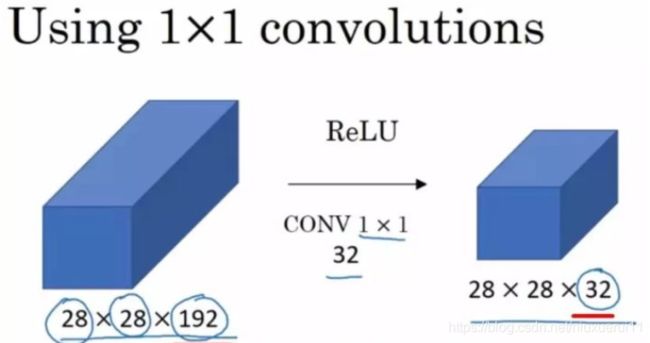
原本的特征图长宽为28,channel为192,我们可以通过这种卷积,使用32个卷积核将2828192变成一个282832的特征图。在使用1*1卷积时,得到的输出长款保持不变,channel数量和卷积核的数量相同。可以用抽象的3d立体图来表示这个过程:
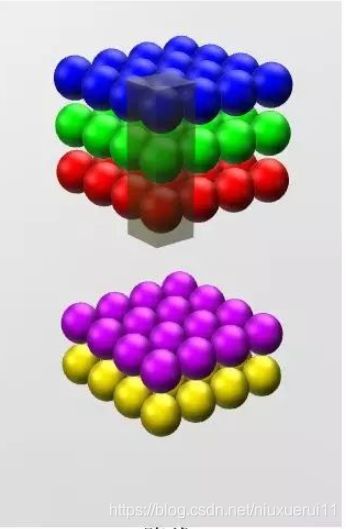
因此我们可以通过控制卷积核的数量,将数据进行降维或者升维。增加或者减少channel,但是feature map的长和宽是不会改变的。我们在全卷积神经网络(FCN)正向传播,下采样的最后一步(可以查看本博客的第一张图片)就是将一个NN4096的特征图变成了一个NN21的特征图.
7. 全卷积神经网络的跳级实现(skip)
我们如果直接采用首先卷积,然后上采样得到与原图尺寸相同特征图的方法的话,进行语义分割的效果经过实验是不太好的。因为在进行卷积的时候,在特征图还比较大的时候,我们提取到的图像信息非常丰富,越到后面图像的信息丢失得就越明显。我们可以发现经过最前面的五次卷积和池化之后,原图的分别率分别缩小了2,4,8,16,32倍。对于最后一层的的图像,需要进行32倍的上采样才能够得到和原图一样的大小,但仅依靠最后一层图像做上采样,得到的结果还是不太准确,一些细节依然很不准确。因此作者采用了跳级连接的方法,即将在卷积的前几层提取到的特征图分别和后面的上采样层相连,然后再相加继续网上往上上采样,上采样多次之后就可以得到和原图大小一致的特征图了,这样也可以在还原图像的时候能够得到更多原图所拥有的信息。如下图所示:
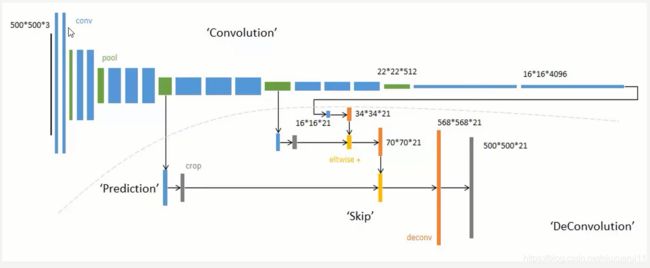
作者最先提出的跳级连接是把第五层的输出进行上采样,然后和池化层4的预测相结合起来,最后得到原图的策略,这个策略叫做FCN-16S,之后又尝试了和所有池化层结合起来预测的方法叫做FCN-8S,发现这个方法准确率是最高的。如下图所示:
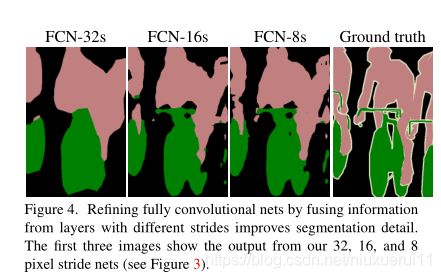
Ground Truth表示原始图像的人为标注,前面的都是神经网络做出的预测。跳级连接,我们这类给出的原图的大小是5005003,这个尺寸无所谓,因为全卷积神经网络可接受任意尺寸大小的图片。我们首先从前面绿色刚刚从池化层做完maxpool的特征图上做一次卷积然后,然后再把下一个绿色的特征图做卷积,最后把161621,已经做完11卷积的输出,把这个三个输出相加在一起,这样就实现了跳级(skip)输入的实现,再把这几个输入融合之后的结果进行上采样,得到一个56856821的图,将这个图通过一个softmax层变成500500*21的特征图,因此图像的长宽和原图一模一样了,每一个像素点都有21个概率值,表示这个像素点属于某个类别的概率,除了和原图的channel不同之外没啥不同的。
5.用全卷积网络进行语义分割
在本节中,我们将逐步介绍最流行的语义分割体系结构-完全卷积网(FCN)的实现。我们将使用Python3中的TensorFlow库以及其他依赖项(如numpy和scipy)来实现它。
在本练习中,我们将使用fcn在图像中标记道路的像素。我们将使用Kitti道路数据集进行道路/车道检测。这是Udacity的自动驾驶汽车纳米学位计划中的一个简单练习,您可以了解有关此Github回购中设置的更多信息。
以下是FCN体系结构的主要特点:
FCN将知识从VGG16传输到执行语义分割。
VGG16的全连接层使用1X1卷积转换为全卷积层。这个过程产生一个低分辨率的类存在热图。
使用转置卷积(用双线性内插滤波器初始化)对这些低分辨率语义特征图进行上采样。
在每个阶段,通过在VGG16中添加来自较粗但分辨率较高的底层特征图的特征,进一步细化了上采样过程。
跳过连接在每个卷积块之后引入,以使后续块能够从以前的集合特性中提取更抽象、类显著的特性。
FCN有3个版本(FCN-32、FCN-16、FCN-8)。我们将实施FCN-8,具体步骤如下:
Encoder:使用预先培训过的VGG16作为编码器。解码器从VGG16的第7层开始。
FCN Layer-8:最后一个完全连接的VGG16层被1x1卷积替换。
FCN Layer-9:fcn layer-8升序2次,与VGG16的layer 4匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding=‘same’)。之后,在VGG16的第4层和fcn的第9层之间添加了一个跳过连接。
FCN Layer-10:fcn layer-9被放大2倍,以便与VGG16第3层的尺寸匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding=(相同))。之后,在VGG16的第3层和fcn第10层之间添加了一个跳过连接。
FCN Layer-11:fcn layer-10被放大4倍以匹配输入图像大小的尺寸,因此我们得到实际图像,深度等于类数,使用带参数的转置卷积:(kernel=(16,16),step=(8,8),padding=‘same’)。
然后我们来看基于Tensorflow的代码实现。
步骤1
我们首先将预先培训过的VGG-16模型加载到TensorFlow中。以TensorFlow session和vgg文件夹的路径(可在此处下载)为例,我们返回vgg模型中的张量元组,包括图像输入、keep-prob(控制辍学率)、第3层、第4层和第7层。
def load_vgg(sess, vgg_path):
# load the model and weights
model = tf.saved_model.loader.load(sess, ['vgg16'], vgg_path)
# Get Tensors to be returned from graph
graph = tf.get_default_graph()
image_input = graph.get_tensor_by_name('image_input:0')
keep_prob = graph.get_tensor_by_name('keep_prob:0')
layer3 = graph.get_tensor_by_name('layer3_out:0')
layer4 = graph.get_tensor_by_name('layer4_out:0')
layer7 = graph.get_tensor_by_name('layer7_out:0')
return image_input, keep_prob, layer3, layer4, layer7
步骤2
现在,我们主要使用vgg模型中的张量为fcn创建层。给定vgg层输出的张量和要分类的类数,我们返回该输出最后一层的张量。特别地,我们将1X1卷积应用于编码器层,然后将解码器层添加到具有跳过连接和升序采样的网络中。
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes):
# Use a shorter variable name for simplicity
layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out
# Apply 1x1 convolution in place of fully connected layer
fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8")
# Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer
fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list()[-1],
kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9")
# Add a skip connection between current final layer fcn8 and 4th layer
fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4")
# Upsample again
fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list()[-1],
kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d")
# Add skip connection
fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3")
# Upsample again
fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes,
kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11")
return fcn11
步骤3
下一步是优化我们的神经网络,也就是建立TensorFlow损失函数和优化器操作。这里我们使用交叉熵作为损失函数,使用Adam作为优化算法。
def optimize(nn_last_layer, correct_label, learning_rate, num_classes):
# Reshape 4D tensors to 2D, each row represents a pixel, each column a class
logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits")
correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes))
# Calculate distance from actual labels using cross entropy
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped[:])
# Take mean for total loss
loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss")
# The model implements this operation to find the weights/parameters that would yield correct pixel labels
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op")
return logits, train_op, loss_op
步骤4
这里我们定义了train-nn函数,它接受重要的参数,包括epoch数、批大小、丢失函数、优化器操作和输入图像的占位符、标签图像、学习速率。对于培训过程,我们还将保持概率设置为0.5,学习率设置为0.001。为了跟踪进度,我们还打印出培训期间的损失。
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op,
cross_entropy_loss, input_image,
correct_label, keep_prob, learning_rate):
keep_prob_value = 0.5
learning_rate_value = 0.001
for epoch in range(epochs):
# Create function to get batches
total_loss = 0
for X_batch, gt_batch in get_batches_fn(batch_size):
loss, _ = sess.run([cross_entropy_loss, train_op],
feed_dict={input_image: X_batch, correct_label: gt_batch,
keep_prob: keep_prob_value, learning_rate:learning_rate_value})
total_loss += loss;
print("EPOCH {} ...".format(epoch + 1))
print("Loss = {:.3f}".format(total_loss))
print()
步骤5
最后,是时候训练我们的网络了!在这个run函数中,我们首先使用load_vgg、layers和optimize函数构建网络。然后,我们使用train_nn函数对网络进行训练,并保存推理数据以备记录。
def run():
# Download pretrained vgg model
helper.maybe_download_pretrained_vgg(data_dir)
# A function to get batches
get_batches_fn = helper.gen_batch_function(training_dir, image_shape)
with tf.Session() as session:
# Returns the three layers, keep probability and input layer from the vgg architecture
image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path)
# The resulting network architecture from adding a decoder on top of the given vgg model
model_output = layers(layer3, layer4, layer7, num_classes)
# Returns the output logits, training operation and cost operation to be used
# - logits: each row represents a pixel, each column a class
# - train_op: function used to get the right parameters to the model to correctly label the pixels
# - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy
logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes)
# Initialize all variables
session.run(tf.global_variables_initializer())
session.run(tf.local_variables_initializer())
print("Model build successful, starting training")
# Train the neural network
train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn,
train_op, cross_entropy_loss, image_input,
correct_label, keep_prob, learning_rate)
# Run the model with the test images and save each painted output image (roads painted green)
helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)
print("All done!")
