贝叶斯数据分析
1.基础知识
条件概率公式:
对于任意两个事件A和B,且P(A)>0,定义在A发生的条件下,B发生的条件概率为
![]()
从而![]() ,这就是乘法公式
,这就是乘法公式
推而广之,设![]() 是任意n个随机事件,则有更一般的乘法公式
是任意n个随机事件,则有更一般的乘法公式
![]()
全概率公式:
设![]() 是样本空间
是样本空间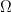 中的一个完备事件群(又称为的一个划分)。换言之,它们满足下列条件:
中的一个完备事件群(又称为的一个划分)。换言之,它们满足下列条件:
(a)两两不相交,即![]()
(b)它们的并(和)恰好是样本空间,即![]()
设A为 中的一个事件,则全概率公式为
中的一个事件,则全概率公式为
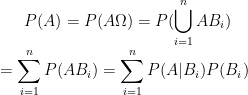
这个公式将事件A分解成一些两两不相交的事件之并。直接计算P(A)不容易,但分解后的那些事件的概率容易计算,从而使P(A)的计算变得容易了。
2.贝叶斯公式
在全概率公式的条件下,即存在样本空间的一个完备事件群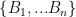 ,设A为中的一个事件,且
,设A为中的一个事件,且![]() ,
,![]() ,则按照条件概率的计算方法,有
,则按照条件概率的计算方法,有
![]()
示例:一种诊断某癌症的试剂,经临床实验有如下记录:癌症病人试验结果是阳性的概率为95%,非癌症病人试验结果是阴性的概率为95%。现用这种试剂在某社区进行癌症筛查,该社区癌症发病率为0.5%,问某人反应为阳性时,该如何判断他是否患有癌症?
解:设事件A表示“试验结果是阳性”,事件B表示“被诊断者患癌症”,则
和
构成一个完备事件群。由题意知:
现需计算
.由贝叶斯公式得
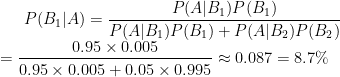
练习:用贝叶斯公式解释“幸存者偏差”现象
用X表示飞机被击中的部位,取值集合为{机头,机翼,机身,机尾}
Y=0表示飞机坠毁
我们关心的是那些坠毁飞机被击中部位的分布
即关心X为哪些部位时,
比较大,从而应该加强这些部位的防护。由于二战期间的炮弹是不长眼睛的,所以可以将P(X)视为均匀分布,从而得到
类似地,可以得到
同时注意到
我们仅能观察到返航飞机上弹痕的分布P(X|Y=1),所以当某一部位X(例如机身)的弹痕较多时,说明P(X=机身|Y=1)较大,根据上述关系得到P(Y=1|X=机身)较大,而P(Y=0|X=机身)和P(X=机身|Y=0)较小,从而说明机身不是关键部位;相反地,如果另一部位X(例如机翼)弹痕较少时,该部位往往可能是关键部位,应加强防护。
贝叶斯公式也可用于纠正一些“成功学谬误”
3.贝叶斯统计学与经典统计学的主要区别
基于总体信息、样本信息、先验信息进行统计推断的方法和理论称为贝叶斯统计学。
- 贝叶斯统计学与经典统计学的主要区别在于是否利用先验信息。
- 在使用样本上存在差别,贝叶斯方法重视已出现的样本,对尚未发生的样本值不予考虑。
- 贝叶斯学派重视先验信息的收集、挖掘和加工,使之形成先验分布而参加到统计推断中来,以提高统计推断的效果。
古典学派与贝叶斯学派的主要分歧:
(1)对于概率含义的解释:
古典学派:一个事件的概率可以用大量重复试验下的频率来解释
贝叶斯学派:将主观概率认为是认识主体对事件发生机会的相信程度,因为有些事件不可重复
(2)对于参数的理解:
古典学派:参数是一个固定值,虽然可能未知,但可以推断
贝叶斯学派:参数是随机变量,具有特定分布
4.贝叶斯参数估计
贝叶斯参数估计是基于贝叶斯公式的参数估计方法
![]()
其中,![]() 是参数
是参数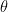 的后验分布,
的后验分布,![]() 是x关于的似然函数,
是x关于的似然函数,![]() 是参数的先验分布,p(x)是x的边缘分布,亦称归一化因子
是参数的先验分布,p(x)是x的边缘分布,亦称归一化因子
4.1先验分布是均匀分布的掷硬币试验
示例:掷硬币试验,掷出n次,设随机变量X表示正面向上的次数,因此随机变量X服从二项分布Bin(n,
),
其中x表示观测到正面向上的次数。
x关于参数
(将掷出n次硬币看做一次掷n枚,x枚朝上)
参数
x的边缘分布(归一化因子)
将上述三项代入贝叶斯公式,得到参数
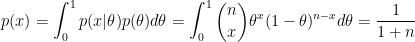
事实上,掷硬币试验的先验分布不一定为均匀分布。我们不妨将试验的先验分布设定为Beta分布,再次代入贝叶斯公式,来观察后验分布会有何变化。
4.2先验分布为Beta分布的掷硬币试验
首先对Beta分布进行简要介绍。
Beta分布是一组定义在[0,1]区间上的连续概率分布
Beta分布的概率密度函数为
![]()
其中B(a,b)是Beta函数,定义为
![]()
其中![]() 是Gamma函数,定义为
是Gamma函数,定义为
![]()
参数a和b控制着Beta分布的形式
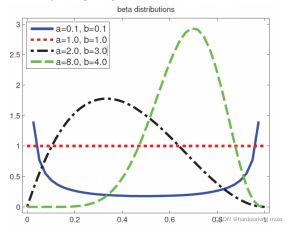
- 特别地,当a=b=1时,Beta分布就是[0,1]区间上的均匀分布
- Beta分布通常作为二项分布的参数的先验分布使用
Beta分布的期望、众数、方差
![]()
回到掷硬币试验
将参数
当a=b=1时,Beta分布就是[0,1]区间上的均匀分布
x的边缘分布(归一化因子)可以写为
将x的边缘分布p(x)代入贝叶斯公式
后验概率密度最大的点(众数mode)是
称之为极大后验估计
考虑到极大似然估计(MLE)的结果为
,因此,后验众数可以看成极大似然估计结果和先验众数的加权组合。
其中,
当n变大,w趋向于1,后验众数趋向于极大似然估计结果
当a=b=1时,w=1,后验众数等于极大似然估计结果,极大后验估计结果与极大似然估计结果相同。
同理,若取后验均值作为贝叶斯参数估计的结果,
在小样本情形下比
更合理
- 当试验次数n增加时,
- 使用先验原因:因为有些试验不能大量重复进行
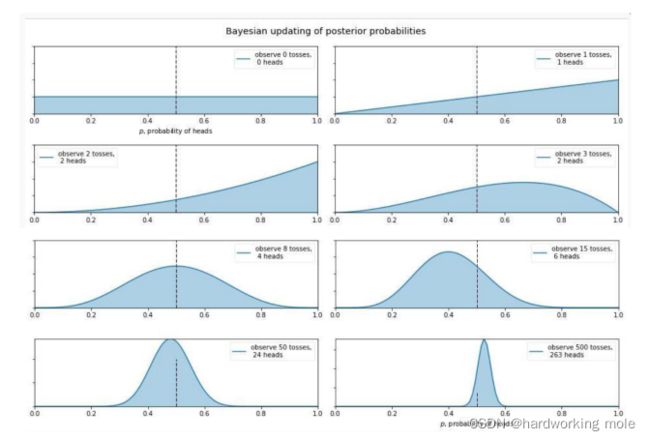
贝叶斯原理符合人们认知事物的模式:先验+数据=后验
4.3后验预测分布
在已经掷出n次硬币并观测到x次正面向上的试验结果上,预测重新掷出![]() 次硬币正面向上的次数y
次硬币正面向上的次数y
后验预测分布:
首先,利用![]() ,第一次掷硬币与第二次结果无关两个条件,
,第一次掷硬币与第二次结果无关两个条件,
![]()
那么,后验预测分布为
期望和方差分别为:
5.共轭先验
在硬币实验中,参数的先验分布![]() 和后验分布
和后验分布![]() 都是Beta分布,称Beta分布是二项分布的共轭先验分布。
都是Beta分布,称Beta分布是二项分布的共轭先验分布。
当先验分布和后验分布是同一种分布,称先验分布是似然函数的共轭先验分布。
只有给定似然函数,才能确定其共轭先验分布。也就是说,必须根据问题的性质选取其共轭先验分布。常见的共轭先验分布如下:
| 似然函数 | 参数 | 共轭先验分布 |
|---|---|---|
| 二项分布 | 成功概率 | 贝塔分布(Beta) |
| 多项分布 | 成功概率 | 狄利克雷分布(Dirichlet) |
| 泊松分布 | 参数 |
伽马分布(Gamma) |
| 指数分布 | 参数 |
伽马分布(Gamma) |
| 正态分布-方差已知 | 均值 | 正态分布(Normal,Gaussian) |
| 正态分布-均值已知 | 方差 | 逆伽马分布(Inverse Gamma) |
对于一般形式的似然函数,共轭先验分布可能不存在
若选取某种分布作为参数的先验分布,x的边缘分布(归一化因子)很可能没有解析表达式
![]()
这将导致参数的后验分布没有解析表达式。解决方法:(1)Markov Chain Monte Carlo(MCMC)(2)Variational Inference(VI)
6.贝叶斯方法的应用
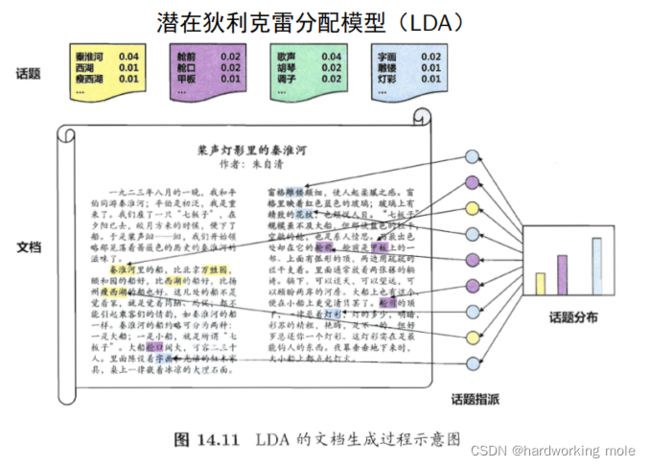
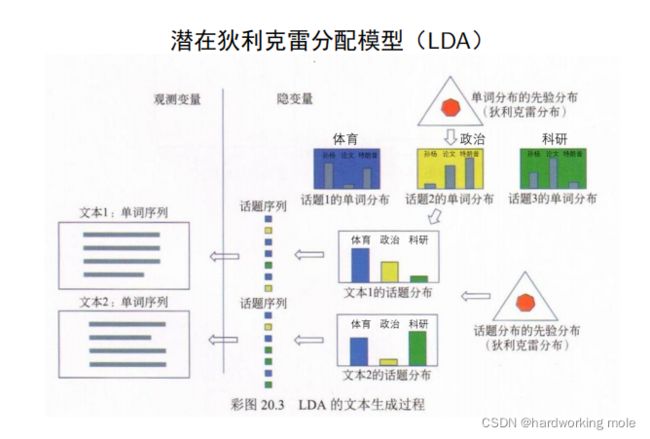
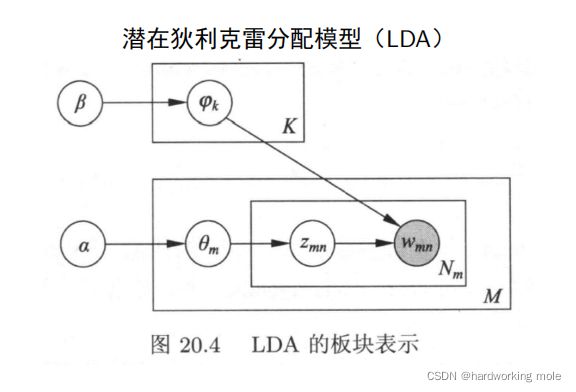
潜在狄利克雷的分配模型(LDA)