独家 | 一文带你熟悉贝叶斯统计

作者:Matthew Ward
翻译:陈之炎
校对:陈丹
本文约5000字,建议阅读10+分钟
本文为你带来贝叶斯统计的基础示例及全面解释。
标签:贝叶斯统计

图:Unsplash,Chris Liverani
贝叶斯统计这个术语最近被广泛使用。它常用于社交场合、游戏和日常生活中,如棒球、扑克、天气预报、总统选举投票等。
在许多科学领域,可以用贝叶斯统计来确定粒子物理和药物有效性实验的结果,它还可用于机器学习和人工智能,以预测你想看什么新闻故事或观看什么Netflix节目。
不管是否对它有充分的理解,贝叶斯统计已融入了我们的日常生活当中,为此,笔者想通过本文对贝叶斯统计做全面的解读,通过一个详尽的例子来展示这个术语的含义。一旦你理解了这个例子,那么便基本上理解了贝叶斯统计。
首先,在读本文之前,假设读者事先对Bayes定理有所熟悉,愿意把公式当成一个黑匣子的读者,也不成问题。如果需要复习一下贝叶斯定理的话,可以到 Medium resources(https://towardsdatascience.com/bayes-theorem-the-holy-grail-of-data-science-55d93315defb)中查找相关资源。
示例和原始观察
这是教科书中经常用到的一个经典例子,我是十多年前在John Kruschke的《DoingBayesian Data Analysis: A Tutorial Introduction with R》中首次了解到它的,现在已经找不到当时的副本拷贝了,所以这里的任何内容重复纯属偶然。
还是从抛硬币实验开始,把一个硬币翻转N次,每次出现正面时记录一个1,每次出现背面时记录一个0,这便构成了一个数据集。利用这个数据集和Bayes定理,我们想弄清楚抛硬币的结果是否有偏差,以及这个实验的置信度。
技术含量的内容来了:首先定义θ是出现正面的偏差——即硬币落地时出现正面的概率。
这意味着,如果θ=0.5,那么没有偏差,正反面出现的概率完全均等。如果θ=1,那么硬币就永远不会出现反面。如果θ=0.75,那么如果翻转硬币的次数足够大的话,将看到大约每4次翻转中有3次出现正面。
为此,定义 y为硬币是否落在正面或背面的特征。这意味着y只能是0(反面)或1(正面),可以用P(y=1|θ)=θ对这些信息进行数学编码。
打开天窗说亮话:如果硬币为正面的概率是θ,那么出现正面的偏差便是θ。
同理: P(y=0|θ)=1 - θ
现在,把多次硬币实验串起来,当抛掷N 次硬币时,出现a 次正面(虽然,重复使用a 不太应该,但这样却使得后续符号标注更为便捷)。
由于硬币翻转相互独立,只需将概率相乘,于是:
![]()
为了避免使用总数N和减法 ,通常定义b为出现反面的次数,写成:
![]()
让我们举两种特例来做一个快速的合理性检查,以确保上述表达式的正确性。
假设: a,b≥ 1. 则:
当偏差趋于零时,概率也趋于零。这是预料中的,因为我们观察到α个正面 (a≥1),所以完全偏向反面是非常不可能的。
同样,当θ接近1时,概率趋近于0,因为观察到至少有一次翻转出现了反面。
如果你已经目瞪口呆了,那么我鼓励你停下来,再真正地思考一下这个问题,从而获得一些关于符号的直觉。它只涉及基础概率和变量的数目。
另一种特殊情况是:当a=0或b=0时。在b=0的情况下,将连续获得a次正面的概率定义为:θα。
接下来,离得出正确的结论还有一定的距离,因为在这个示例中,有一个固定的数据集(正面和反面的集合)需要分析。
因此,从现在开始,应该考虑a和b固定的数据集的情况。
贝叶斯统计
随着θ在[0,1]之间的变化,获得一个分布函数P(a,b|θ)。接下来,要做的是将它乘以一个常数,把它当作是概率分布。
其实,这就称之为beta分布(注意:我在此处省略了它的表达式),只将它记作β(a,b)。
我们乘的数是下面这个式子的倒数 :
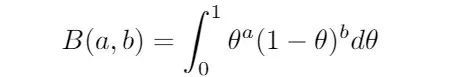
称为(移位)β函数。再说一遍,如果没有理解的话,可以忽略它。它只是将分布转换为概率分布。如果我不提的话会有人打电话给我。
似乎不需要这么复杂地把它看作是Θ的概率分布 ,但这实际上正是我们要求的。来看以下三个例子:

红色的表示,如果观察到2个正面和8个背面,那么硬币偏向背面的概率就更大,均值出现在0.20,由于没有足够的数据,在其他地方出现正面的可能性或许更高,存在真正的偏差。
中间曲线说明:如果观察到5个正面和5个背面,那么最有可能的是偏差是0.5,同样还有很大的误差空间。如果试验次数足够多,获得了更多的数据,猜测则更有信心,这种情况也是我们所期望的:

当观察到50个正面和50个背面时,可以说置信度95%,真实偏差在0.40到0.60之间。
此时,你可能会反驳道:这只是普通的统计,哪里是贝叶斯定理?说得对。因为现在不是在真空中建立统计模型,所以才会有贝叶斯定理,偏差存在先验概率。
先写下该案例中的Bayes定理:想通过观察到的数据求出偏差的概率θ,用到了Bayes定理的连续形式:
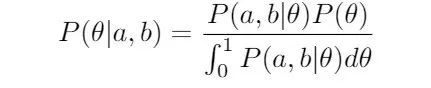
我只是想让大家对贝叶斯统计有一个感觉,所以我不会详细地去推导这个简化的式子。只需注意“后验概率”(方程的左边)即:在已知数据后得到的分布,似然度乘以先验概率再除以标准化常量。
现在,如果你的分母是B(a,b),那么并计算出的结果将会是另一个β分布!如果你们能理解这些定义,那这并不是太难的练习,但如果你相信了这一点,那么你会看出这样做多么美妙 。
如果先验偏差具有分布β(x,y),数据出现a个正面和b个反面,得到:
P(θ|a,b)=β(a+x, b+y).
根据这个模型中的数据来更新置信度的方式真是无比简单!
现在来检查一下它是否真的有意义 。假设偏差未知,将可以导出先验概率分布β(0,0)是一条平直的线,即所有的偏差都有同样的可能。
来做一个这样的实验,翻转4次硬币,观察到3个正面和1个背面。贝叶斯分析告诉我们,后验概率分布是β (3,1):

哎呀!不确定性太大了,看起来这种偏差在很大程度上是针对正面的。
危险:这是因为我们使用了一个错误的先验概率。在现实世界中,将偏差0.99与0.45等同起来是不合理的。
来看看,如果使用一个更为温和的先验概率分布β(2,2),此时假设偏差最有可能接近0.5,无论数据说明了什么,它依然是对的。
在这种情况下, 3个正面和1个背面的结果更新为概率分布是β(5,3):
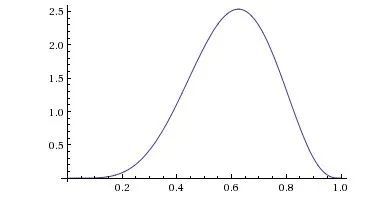
啊,好多了,可以观察到3次正面和1次背面,不要忽略这些数据,新的概率受到了先验概率的影响。
这就是贝叶斯统计的伟大之处!如果我们有大量的数据,那么即便观察到一些偏离点也无伤大雅。
另一方面,只要数据足够充分,即使我们99%肯定某件事也可以接受。这只是一句口头禅的数学形式化:非凡的主张需要非凡的证据支持。
因为只有大量的数据才能够证明硬币偏差是0.90,所以需要有大量的数据,这也是非贝叶斯分析的部分缺陷。如果我们没有大量的数据,并且偶尔抽到了一些异常值,那么就更容易相信这种偏差了。
现在应该了解贝叶斯统计的工作原理了吧,如果理解了这个示例,那么其余的大部分工作只是添加参数和更新版本,实际上,通过上述内容已经对这个术语的含义有了一个非常到位的了解。
得出结论
接下来,需要解释的主要问题是如何处理数据,在对数据进行分析之后,如何得出结论?
你可能经常听到做统计的人谈论“95%的置信度”。几乎在每一堂统计课程中都会提到置信区间,同样需要找出贝叶斯统计的相应概念。
标准的术语称之为最高密度区间(HDI):95%的HDI意味着一个区间,其分布下的面积为0.95(即:分布的95%的区间),该区间中的每个点都比区间以外的任何点具有更高的概率:

虽然看起来不像,但是应该是完全对称的

首先要正确地画出间隔,注意,阴影区域的曲线上的点的概率都高于区域外曲线上的点的概率 (即:可能性更大)。
注:依然有很多置信度为95%的间隔为非HDI。第二幅图便是这样一个例子,即使曲线下的面积是0.95,大紫点也不在区间内,而且高于左边一些包含在该区间内的点。
最后,如果这个值的一些小邻域完全位于95%的HDI内,则称偏差θ₀是可信的,这个小阈值通常称为实际等价区(ROPE),它是必须设置的一个值。
将其设为0.02,如果从0.48到0.52的整个间隔均在95%的HDI内,那么这是一个可信的假设。
注意,由于函数本身的复杂性,计算beta分布的HDI实际上非常难。没有完美的解决方案,所以通常情况下,可以通过查表来得出计算结果,或者以某种方式取它的近似值。
均值为μ=a/(ab),标准差为:

确实有对应的表格。
在本文中,我使用“两个标准差”规则来近似,该规则为均值两边的两个标准差的区间内的置信度约为95%。
注意,如果分布曲线比较陡,例如,概率分布为β(3,25),那么这种近似会产生偏差。
回到以上相同例子,添加这一新术语,看看它是如何工作的。假设偏差未知,令先验概率分布β(0,0)为平坦直线。
这表明,所有的偏差都同样有可能发生。现在来做一个实验,观察到3个正面和1个背面。贝叶斯分析告诉我们,新分布是β(3,1)。
此时,置信度95%的HDI约为0.49~0.84。为此,可以肯定地说,真正的偏差发生在这个区间。请注意,猜测硬币正反面是等概率的(偏差为0.5),而不是一个假设,区间[0.48,0.52]不完全在HDI 之内。
这个例子说明了选择不同阈值的重要性,因为如果选择间隔为0.01而不是0.02,那么抛掷硬币是等概率的假设是可信的(因为[0.49,0.51]完全在HDI之内)。
让我们来看一下,如果使用一个稍微合理的先验概率分布β(2,2),假设:抛掷硬币是等概率事件,根据数据得出的结论是显而易见的。
此时, 3个正面和1个背面告诉我们,后验分布函数是β(5,3)。置信区间为 95%的HDI为0.45~0.75。使用相同的数据,得到了更窄的间隔,尤为重要的是,我们对硬币是等概率时间的说法更为信服,所以这是一个可信的假设。
从而可以推导出一种“统计不确定性原则”,如果要获取大的确定性,那么会使间隔变得越来越宽。直观地说,如果给定一个范围, 99.999999%确定的偏差均在这个范围之内,那么几乎给出了所有的可能性。
如果想要找出精确的偏差点,那么必须放弃确定性(除非处于一种极端的情况下,分布是一个非常尖锐的尖峰)。你会得到这样的结果:可以用1%的确定性说,真实偏差在0.59999999到0.60000001之间。
如果已经锁定了一个小范围,则必须放弃确定性。这与海森堡不确定性原理相类似,海森堡不确定性原理表明:越精确地知道一个粒子的动量或位置,就越无法准确地知道另一个粒子的动量或位置。
总结
总结一下,准确地搭建统计模型需要注意的几个要点。对贝叶斯模型持反对意见的人认为,可以通过主观地选择先验概率,从而得出任何你想要的答案。
抽象地说,这种反对意见本质上是正确的,但在现实实践中,可以绕开它。下面对如何进行贝叶斯统计做一下总结。
第一步是写出似然函数P(θ|a,b),在上述例子中,为β (a,b),直接从收集的数据中得出,这完全由数据来决定。
第二步是确定先验分布,在这一步可以有所选择,但同时也是一种约束。在现实生活统计中,可能会有很多先验信息,根据这些信息决定如何选择。
回想一下,我们对认为可能是真实的事实进行了先验编码,并定义了它的置信度。假设根据投票数据来预测谁将赢得选举,需要建立了一个模型,给定有前一年的数据,收集的数据经过测试后,便知道它有多准确!
因此,在已有数据基础上计算先验概率,是一个明智的选择,因为在这里只有一种选择,这并不意味着,可以任意选择你想得出的结论。
在此不再赘述了,在上述例子中,如果随机选择一个硬币的先验概率分布β(100,1),并希望它出现偏差,那么有权视模型为无用的。
先验概率必须已知,并且必须是合理的。如无法证明先验概率,那么就不可能得出一个好的模型。先验概率的选择是一个特性,而不是一个bug。如果说贝叶斯模型比所有其他模型都精确得多,那是因为它没有忽略先验知识。
当贝叶斯统计的反对者使用“先验的任意性”作为理由时,它的失效的确令人沮丧。另一方面,学者们应该在的科学论文中对先验概率做更为深入的研究,以避免出现任何不必要的偏差。
第三步是设置一个ROPE,以明确特定的假设是否可信。这只里规定了在置信区间为95%的HDI边缘考虑正确的猜测是否可信。
诚然,这一步确实相当武断,但每个统计模型都存在这个问题,它非贝叶斯统计所独有,在现实生活中也不是一个典型的问题。如果某件事离HDI太近,那么可能需要更多的数据。
如果你是一名科学家,那么就应重新做实验,或者你得承认,这可能会得出另一种结果。
原文标题:
What is Bayesian Statistics?
原文链接:
https://medium.com/cantors-paradise/what-is-bayesian-statistics-3bc39b19c45f
offrey-hinton-deep-learning-will-do-everything/
编辑:黄继彦
校对:杨学俊
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织