python 处理EXCEL 追加写
适用场景:
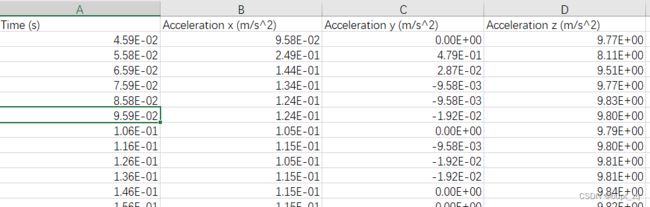
原始加速度数据长这样:Accelerometer.csv,存的都是小数,这里是表格显示为科学计数法了。
时间数据也是csv文件,time.csv

这里的START system time 对应的1652402044 加上加速度数据中Time(s) ,才是真正的开始时间戳。
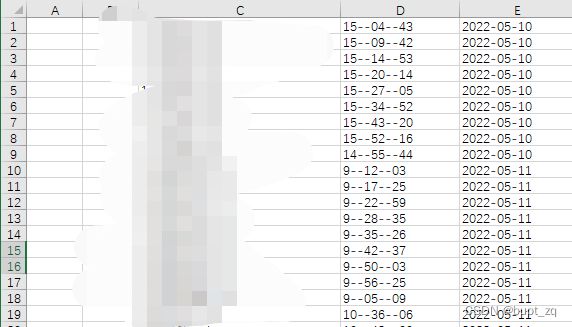
开始的时间记录在一个表格中:每9行为一组,记录了一个人的九个开始时间。需要从Accelerometer.csv中找到九个开始的时间对应的数据,然后往下截取12000条数据。将9*12000条数据写入一个新的表格,只保留三轴加速度。
根据
1、先做一些预处理工作。将需要截取的开始时间转换为时间戳形式,方便下面查询。
记录开始时间的表格长这样:E列为日期、D列为时间,时间这一列使用了--作为分隔符是因为如果使用:作为分隔符,表格里存的其实还是一个小数,不是文本格式,这样python在读取的时候,就会将时间读为小数。
代码中的 timeArray1 = time.strptime(tss, "%Y-%m-%d %H--%M--%S") 中规定了分隔符的格式,与表格中存储的一致。
timeTransform.py
import time
import xlrd
#将开始的日期、时间存下来
import os
fp =r"C:\Users\11941\Desktop\开始时间记录.xls"
worksheet = xlrd.open_workbook(fp)
sheet_names = worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
time_val= sheet.col_values(3) # 获取第四列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
# print(time_val)
date_val = sheet.col_values(4) # 获取第五列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
# print(time_val)
# print(cols[23])
# print(type(cols[23])) # 查看数据类型
i=0
for i in range(0,len(time_val)):
date_time = date_val[i] + time_val[i]
tss = date_time
timeArray1 = time.strptime(tss, "%Y-%m-%d %H--%M--%S")
timeStamp1 = int(time.mktime(timeArray1))
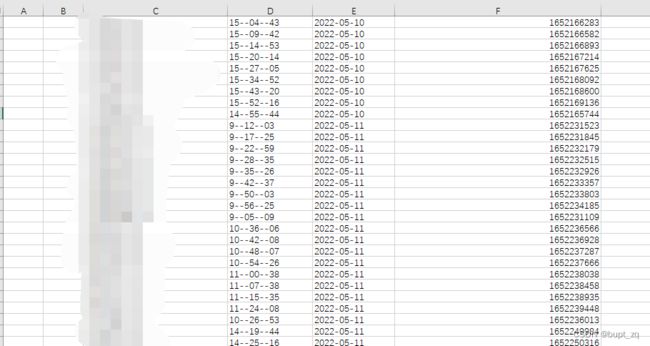
print(timeStamp1)将打印出来的时间戳粘贴在表格里,如图所示
2、根据时间戳列表,返回开始截取的行号列表。
传入id,代表第几个人,就从记录时间戳的第几组取得时间戳。传入fp为加速度文件的地址。
searchTimestamp.py
import time
import xlrd
import pandas as pd
# 将开始的日期、时间存下来
import os
def startTimeStamp(id, fp):
startTimeStampList = []
# 导入时间戳
start_time = r"C:\Users\11941\Desktop\开始时间记录.xlsx"
worksheet = xlrd.open_workbook(start_time)
sheet_names = worksheet.sheet_names()
# print(sheet_names)
timestamp = []
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
timestamp = list(map(int, sheet.col_values(5)))
timestamp = list(map(str, timestamp))
# print(timestamp)
# 寻找对应的时间戳行数。
# fp = r"C:\Users\11941\Desktop\实验室\手机实验数据\5.10\1-刘玉\time_pacing.xlsx"
worksheet = xlrd.open_workbook(fp)
sheet_names = worksheet.sheet_names()
# print(sheet_names)
time_val = []
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
time_val = sheet.col_values(0)
for j in range((id - 1) * 9, id * 9):
i = 1
print(timestamp[j])
for i in range(1, len(time_val)):
if timestamp[j] == time_val[i]:
startTimeStampList.append(i)
print(i)
break
i = i + 1
print("id:", id, " startTimeStamp:", startTimeStampList)
return startTimeStampList
#
# fp = r"C:\Users\11941\Desktop\实验室\手机实验数据\5.10\1-刘玉\time_pacing.xlsx"
# timeList = startTimeStamp(1, fp)
# print(startTimeStamp(10, "C:\\Users\\11941\\Desktop\\实验室\\processDataResult\\10-yao 2022-05-13 09-50-28.xlsx"))
返回一个时间戳对应的行号列表:
startTimeStamp: [99034, 131434, 163034, 194734, 231034, 280734, 327134, 377234, 56734]
3、表格追加写入
建议使用openxyl库,使用xlsw有行数限制,不能超过65000行,对于大量数据操作到一半崩了的感觉谁懂,我真的会气疯。openxyl使用的时候记得save ,不save 啥也没有用
add2excel.py
传入要截取的加速度数据地址fp,截取后的文件保存地址result_xlsx_path,timeList是上一步函数的返回值,行号列表。
import os.path
import openpyxl
import xlrd
from xlutils.copy import copy
import xlsxwriter as xw
# fp = r"C:\Users\11941\PycharmProjects\processData\test.xlsx"
# result_xlsx_path = r"C:\Users\11941\PycharmProjects\processData\testresult.xlsx"
# # timeList = startTimeStamp(1, new_fp)
# timeList = [2, 20, 30, 40]
# worksheet = openpyxl.load_workbook(new_fp)
# sheet = worksheet.active
####先打开一个表格,openxyl 读取指定行。追加写入另一个表格。
from openpyxl import load_workbook
def add2excel(fp,result_xlsx_path,timeList):
wb = load_workbook(fp)
wx = wb.active
# print(wx.values)
test_val = list(wx.values)
# print(test_val, end='\n\n')
# print(list(test_val[1]))
wb = load_workbook(result_xlsx_path)
# print(wb)
ws = wb.active # 获取当前活跃的worksheet对象(sheet表)
# print(ws)
cell = ws['A1'] # 获取指定位置的单元格对象
headers=['ax','ay','az']
for i, item in enumerate(headers):
ws.cell(row=1, column=i + 1, value=item)
# print(cell)
for start_time in timeList:
for num in range(start_time + 9000,start_time + 21000): #我这里加9000没有从头开始取。
test_val_num = list(test_val[num])
ws.append(test_val_num[1:4])
wb.save(filename=result_xlsx_path)
4、校准加速度数据的时间戳,写入新的加速度表格
使用searchTimestamp.py寻找行号列表,使用add2excel.py 追加写入新的结果表格。
partTheData.py
import os
import csv
import xlrd
import openpyxl
import xlsxwriter as xw
import xlwt
from add2excel import add2excel
from searchTImestamp import startTimeStamp
# fp = r"C:\Users\11941\Desktop\实验室\手机实验数据\5.10\1-刘玉\Accelerometer1.csv"
headers = ['Time (s)', 'ax', 'ay', 'az']
def partTheData(fp, result_path, filename, id):
time_path = fp + "\\meta\\time.csv"
fp = fp + '\\Accelerometer.csv'
with open(fp) as csvfile:
spamreader = csv.DictReader(csvfile)
i = 1
data = []
with open(time_path) as f:
reader = csv.reader(f)
systime = [row[2] for row in reader]
for row in spamreader:
time = row["Time (s)"]
# time = Decimal(time).quantize(Decimal("0.000000000"), ROUND_CEILING) + int(systime[1])
# time = Decimal(time).quantize(Decimal("0.000000000"), ROUND_CEILING) + Decimal(systime[1])
time = float(time) + float(systime[1])
row['Time (s)'] = str(int(time))
row['Acceleration x (m/s^2)'] = float(row['Acceleration x (m/s^2)'])
row['Acceleration y (m/s^2)'] = float(row['Acceleration y (m/s^2)'])
row['Acceleration z (m/s^2)'] = float(row['Acceleration z (m/s^2)'])
data.append(row)
workbook = xw.Workbook(result_path) # 创建工作簿
worksheet1 = workbook.add_worksheet("sheet1") # 创建子表
worksheet1.activate() # 激活表
title = headers # 设置表头
worksheet1.write_row('A1', title) # 从A1单元格开始写入表头
i = 2 # 从第二行开始写入数据
for j in range(len(data)):
insertData = [data[j]["Time (s)"], data[j]["Acceleration x (m/s^2)"], data[j]["Acceleration y (m/s^2)"],
data[j]["Acceleration z (m/s^2)"]]
row = 'A' + str(i)
worksheet1.write_row(row, insertData)
i += 1
workbook.close() # 关闭表
time_list = startTimeStamp(id, result_path)
result_xlsx_path = r"C:\Users\11941\PycharmProjects\processData\result"
result_xlsx_path = result_xlsx_path + "\\" + filename + "" + '.xlsx'
if os.path.exists(result_xlsx_path):
add2excel(result_path, result_xlsx_path, time_list)
print("数据添加一次完成!")
else:
wb_1 = openpyxl.Workbook() # 创建wb对象
wb_1.save(result_xlsx_path) # 储存数据
add2excel(result_path, result_xlsx_path, time_list)
# partTheData("C:\\Users\\11941\\Desktop\\实验室\\手机实验数据\\10-于学山\\10-yao 2022-05-13 09-50-28",
# "C:\\Users\\11941\\Desktop\\实验室\\processDataResult\\10-yao 2022-05-13 09-50-28.xlsx"
# , "10-yao 2022-05-13 09-50-28", 10)
5、最终调用:processData.py。
对文件中的所有文件依次进行处理。
import os
import xlrd
from xlrd import sheet
from partTheData import partTheData
# 获取处理文件路径
datadir = r"C:\Users\11941\Desktop\实验室\手机实验数据"
result_dir = r"C:\Users\11941\Desktop\实验室\processDataResult"
with os.scandir(datadir) as it:
for fp in it:
if fp.is_dir():
with os.scandir(fp) as it:
for i in it:
# if i.is_dir():
# with os.scandir(i) as it1:
# for j in it1:
print(i.path)
print(i.name)
id = i.name.split('-', 1)
print(id[0])
result_xlsx_path = i.path
partTheData(i.path,result_dir + '\\' +i.name+'.xlsx',i.name,int(id[0]))